正则表达式和re模块
1.正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先约定好的一些具有特殊意义的字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
然后借助re模块,把字符串中满足此"规则字符串"的子字符串全部找出来,正则表达式是一个不可分割的整体.
用来做字符串匹配的,快速的匹配你想要的信息,是一门独立的语言是对一种匹配字符串规则的描述,与python没有关系,可以应用到所有语言中.
python中用re模块来操作正则表达式
如果一个字符串一个位置的字符不会变化,那么没有必要使用正则,就用不变的字符本身就可以匹配上.
例如:规则是三条腿,找出世界上所有三条腿的事物,三条腿就是规则
结果:桌子,椅子,蛤蟆~。~
再例如:高帅富
结果:你~。~当然还有我~,~
有了正则表达式,可以让你的变成更加简洁,不用写大量的python来判断用户输入的信息是否合法
接下来就是学习一堆特殊符号的含义


while True: phone_number = input('please input your phone number : ') if len(phone_number) == 11 \ and phone_number.isdigit()\ and (phone_number.startswith('13') \ or phone_number.startswith('14') \ or phone_number.startswith('15') \ or phone_number.startswith('18')): print('是合法的手机号码') else: print('不是合法的手机号码')
有了正则表达式
import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|18)[0-9]{9}$',phone_number): print('是合法的手机号码') else: print('不是合法的手机号码')
1.1字符组[]
同一个位置上可以出现的字符的范围
字符组里面描述的规则如果满足一个,那么就是匹配上了
放到字符组里面现原形的有 . | [ ] ( )
.放[]外面表示任何字符,除了换行符,放到[]里面就是.不用加\来转义,其他一样
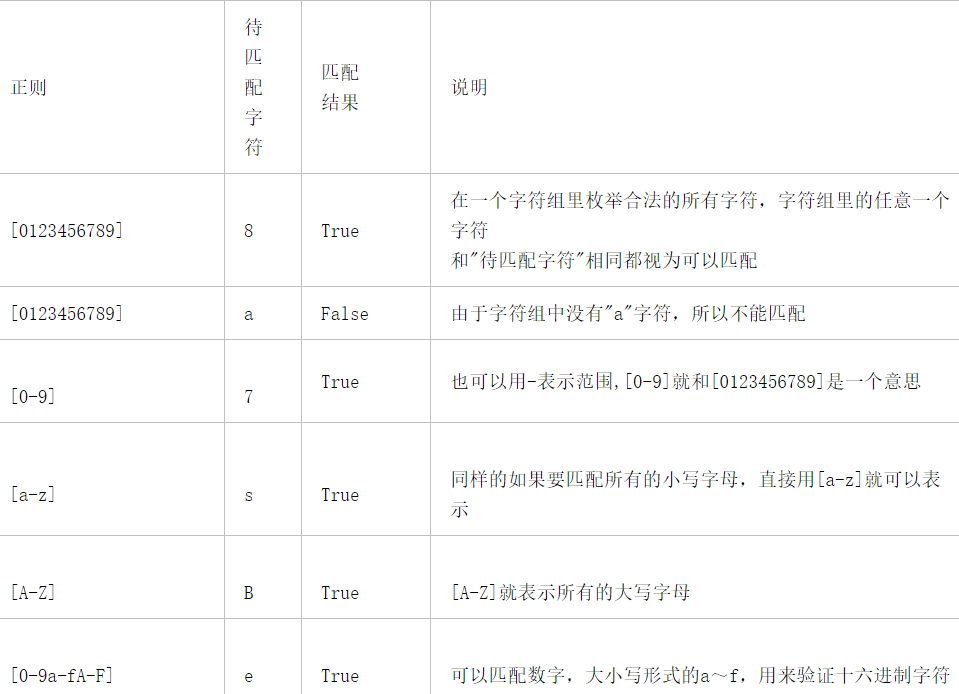
[^]除了字符组里面的字符范围都可以,^必须放在字符组的最开头
1.2元字符
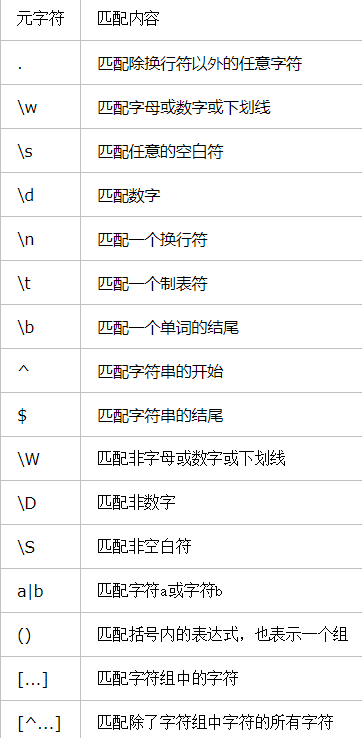
\b 匹配一个单词的边界 ing\b以ing结尾的单词 \babs以abs开头的单词
1.3量词
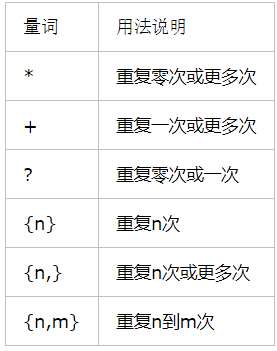
1.4 $ ^ |
$:表示必须从头开始
^:表示必须以此结尾
|表示或,是种短路运算,只要前面规则满足了,就不会走后面的规则,即前真则停,前假找后
因此要把复杂的规则放在前面
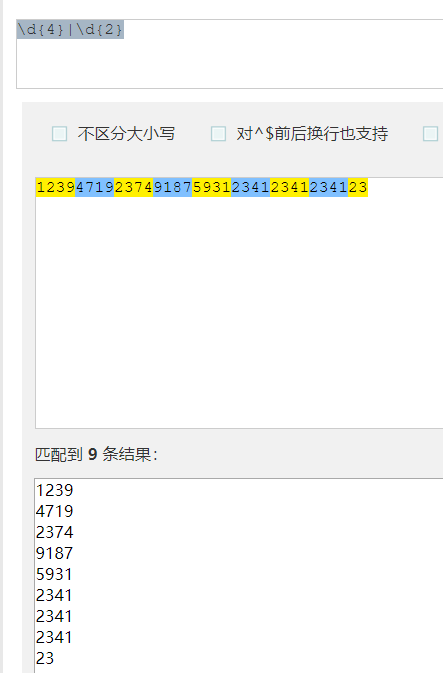
1.5实例
| 正则 | 待匹配 | 匹配结果 |
| 李.? | 李杰和李莲英和李二棍子李 |
李杰 |
李后面的字符串可以是任意的可有可无,但是会尽量多的去匹配,只有李后面没有了才只匹配李,
因为正则表达式默认是贪婪模式,尽可能去匹配多的字符串
1.6贪婪匹配
使用的是回溯算法,先尽可能远的往后走,直到不匹配之后才回头
量词后面加?取消贪婪匹配
| 正则 | 待匹配 | 匹配结果 |
| 李.?? | 李杰和李莲英和李二棍子李 |
李 |
1.7分组
正则里面的分组:为了把多个匹配规则连在一起用量词约束.
re模块里面的分组:是为了更好的获取数据,并且可以给一个分组起名字.
1.8 .*?x这个组合用的很多,尤其爬虫里面用的更多
. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
亮点1:就在?取消了贪婪匹配和后面的x,如果没有x那么只会尽可能少的匹配,只有0
亮点2:?x的连用,充分利用了回溯算法,没有?取消贪婪模式,就会无限的向后匹配字符,有了?取消了贪婪匹配,尽管尽可能少的匹配,但是后面有个x,
那么就会先无限向后找,直到找到x,那么就到x停止,向回告诉前面*匹配到了x之前
亮点3:*的目的其实是把不想要的数据过滤掉,需要的数据加上分组,借助re模块就可以把想要的数据获取到
看十遍不如自己写一遍!巩固基础,纵横开拓!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号