
你分库分表的姿势对么?——详谈水平分库分表
一、背景
提起分库分表,对于大部分服务器开发来说,其实并不是一个新鲜的名词。随着业务的发展,我们表中的数据量会变的越来越大,字段也可能随着业务复杂度的升高而逐渐增多,我们为了解决单表的查询性能问题,一般会进行分表操作。
同时我们业务的用户活跃度也会越来越高,并发量级不断加大,那么可能会达到单个数据库的处理能力上限。此时我们为了解决数据库的处理性能瓶颈,一般会进行分库操作。不管是分库操作还是分表操作,我们一般都有两种方式应对,一种是垂直拆分,一种是水平拆分。
关于两种拆分方式的区别和特点,互联网上参考资料众多,很多人都写过相关内容,这里就不再进行详细赘述,有兴趣的读者可以自行检索。
此文主要详细聊一聊,我们最实用最常见的水平分库分表方式中的一些特殊细节,希望能帮助大家避免走弯路,找到最合适自身业务的分库分表设计。
【注1】本文中的案例均基于Mysql数据库,下文中的分库分表统指水平分库分表。
【注2】后文中提到到M库N表,均指共M个数据库,每个数据库共N个分表,即总表个数其实为M*N。
二、什么是一个好的分库分表方案?
2.1 方案可持续性
前期业务数据量级不大,流量较低的时候,我们无需分库分表,也不建议分库分表。但是一旦我们要对业务进行分库分表设计时,就一定要考虑到分库分表方案的可持续性。
**那何为可持续性?**其实就是:业务数据量级和业务流量未来进一步升高达到新的量级的时候,我们的分库分表方案可以持续使用。
一个通俗的案例,假定当前我们分库分表的方案为10库100表,那么未来某个时间点,若10个库仍然无法应对用户的流量压力,或者10个库的磁盘使用即将达到物理上限时,我们的方案能够进行平滑扩容。
在后文中我们将介绍下目前业界常用的翻倍扩容法和一致性Hash扩容法。
2.2 数据偏斜问题
一个良好的分库分表方案,它的数据应该是需要比较均匀的分散在各个库表中的。如果我们进行一个拍脑袋式的分库分表设计,很容易会遇到以下类似问题:
a、某个数据库实例中,部分表的数据很多,而其他表中的数据却寥寥无几,业务上的表现经常是延迟忽高忽低,飘忽不定。
b、数据库集群中,部分集群的磁盘使用增长特别块,而部分集群的磁盘增长却很缓慢。每个库的增长步调不一致,这种情况会给后续的扩容带来步调不一致,无法统一操作的问题。
这边我们定义分库分表最大数据偏斜率为 :(数据量最大样本 - 数据量最小样本)/ 数据量最小样本。一般来说,如果我们的最大数据偏斜率在5%以内是可以接受的。
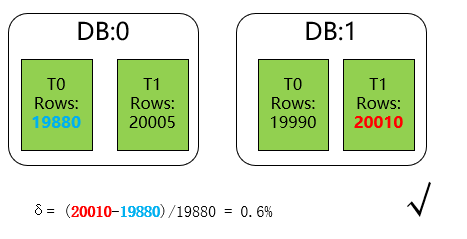
三、常见的分库分表方案
3.1 Range分库分表
顾名思义,该方案根据数据范围划分数据的存放位置。
举个最简单例子,我们可以把订单表按照年份为单位,每年的数据存放在单独的库(或者表)中。如下图所示:
/**
* 通过年份分表
*
* @param orderId
* @return
*/
public static String rangeShardByYear(String orderId) {
int year = Integer.parseInt(orderId.substring(0, 4));
return "t_order_" + year;
}
通过数据的范围进行分库分表,该方案是最朴实的一种分库方案,它也可以和其他分库分表方案灵活结合使用。时下非常流行的分布式数据库:TiDB数据库,针对TiKV中数据的打散,也是基于Range的方式进行,将不同范围内的[StartKey,EndKey)分配到不同的Region上。
下面我们看看该方案的缺点:郑州妇科医院排名http://www.zzchxbyy120.com/
a、最明显的就是数据热点问题,例如上面案例中的订单表,很明显当前年度所在的库表属于热点数据,需要承载大部分的IO和计算资源。
b、新库和新表的追加问题。一般我们线上运行的应用程序是没有数据库的建库建表权限的,故我们需要提前将新的库表提前建立,防止线上故障。
这点非常容易被遗忘,尤其是稳定跑了几年没有迭代任务,或者人员又交替频繁的模块。
c、业务上的交叉范围内数据的处理。举个例子,订单模块无法避免一些中间状态的数据补偿逻辑,即需要通过定时任务到订单表中扫描那些长时间处于待支付确认等状态的订单。
这里就需要注意了,因为是通过年份进行分库分表,那么元旦的那一天,你的定时任务很有可能会漏掉上一年的最后一天的数据扫描。
3.2 Hash分库分表
虽然分库分表的方案众多,但是Hash分库分表是最大众最普遍的方案,也是本文花最大篇幅描述的部分。
针对Hash分库分表的细节部分,相关的资料并不多。大部分都是阐述一下概念举几个示例,而细节部分并没有特别多的深入,如果未结合自身业务贸然参考引用,后期非常容易出现各种问题。
在正式介绍这种分库分表方式之前,我们先看几个常见的错误案例。
常见错误案例一:非互质关系导致的数据偏斜问题
public static ShardCfg shard(String userId) {
int hash = userId.hashCode();
// 对库数量取余结果为库序号
int dbIdx = Math.abs(hash % DB_CNT);
// 对表数量取余结果为表序号
int tblIdx = Math.abs(hash % TBL_CNT);
return new ShardCfg(dbIdx, tblIdx);
}
上述方案是初次使用者特别容易进入的误区,用Hash值分别对分库数和分表数取余,得到库序号和表序号。其实稍微思索一下,我们就会发现,以10库100表为例,如果一个Hash值对100取余为0,那么它对10取余也必然为0。
这就意味着只有0库里面的0表才可能有数据,而其他库中的0表永远为空!
类似的我们还能推导到,0库里面的共100张表,只有10张表中(个位数为0的表序号)才可能有数据。这就带来了非常严重的数据偏斜问题,因为某些表中永远不可能有数据,最大数据偏斜率达到了无穷大。
那么很明显,该方案是一个未达到预期效果的错误方案。数据的散落情况大致示意图如下:
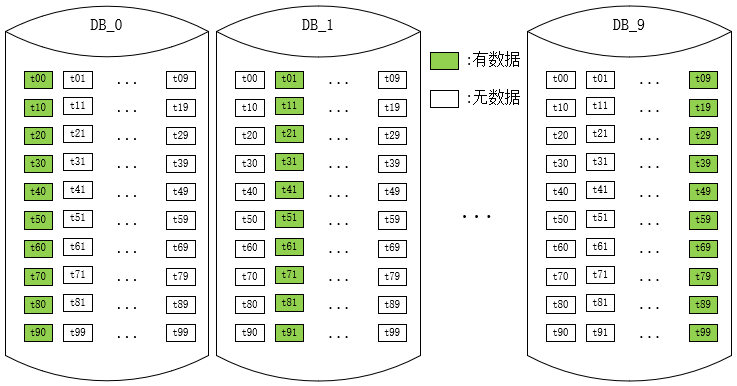
事实上,只要库数量和表数量非互质关系,都会出现某些表中无数据的问题。
证明如下:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)