如何看待服务网格?
Service Mesh 一词最早由开发 Linkerd 的 Buoyant 公司提出,并于 2016 年 9 月29 日第一次公开使用了这一术语,并被翻译成“服务网格”,逐步在国内传播开来。William Morgan,Buoyant CEO,对 Service Mesh 这一概念定义如下:
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
翻译成中文如下:
服务网格是一个专门处理服务通讯的基础设施层。它的职责是在由云原生应用组成服务的复杂拓扑结构下进行可靠的请求传送。在实践中,它是一组和应用服务部署在一起的轻量级的网络代理,并且对应用服务透明。
Istio 是一个开源的服务网格实现产品,一经推出就备受瞩目,成为了各大厂商和开发者争相追捧的对象。Istio 官方文档是这样来定义自己的:
它是一个完全开源的服务网格,以透明的方式构建在现有的分布式应用中。它也是一个平台,拥有可以集成任何日志、遥测和策略系统的 API 接口。Istio 多样化的特性使你能够成功且高效地运行分布式微服务架构,并提供保护、连接和监控微服务的统一方法。
从官方定义我们可以看出,Istio 提供了一个完整的解决方案,可以以统一的方式去管理和监测你的微服务应用。同时,它还具有管理流量、实施访问策略、收集数据等方面的能力,而所有的这些都对应用透明,几乎不需要修改业务代码就能实现。有了 Istio,你几乎可以不再需要其他的微服务框架,也不需要自己去实现服务治理等功能。只要把网络层委托给 Istio,它就能帮你完成这一系列的功能。简单来说,Istio 就是一个提供了服务治理能力的服务网格。
Istio 是服务网格的标准吗?
好的,前面背景交代清楚了,现在可以开始正文了。
Istio 会是服务网格领域的事实标准吗?我觉得今天我可以给一个答案了,NO。
Istio 2017 年 5 月发布第一个版本 v0.1,从发布 v1.0 开始得到大规模关注,发布 v1.5 做了控制面架构的大调整,后持续迭代,每三个月发布一个大版本,截止日前,已经发布了 v1.12 了。Istio 支持丰富的流量治理策略,具有丰富的可观测性集成能力,且积极拥抱变化,迈向架构简约主义,增强易用性,提供对虚拟机的支持等。
Istio 是一款优秀的开源软件,具有极高的社区活跃度和强大的社区生态,也具备比较优秀的架构设计,这一点毋庸置疑。但是,有一个缺陷,也是比较致命的缺陷,Istio 不是从企业中大规模落地验证后开源出来的,Istio 是从出生就是一个开源软件,Istio 是一个理想型的开源软件(譬如强调流量劫持的无侵入性)。
软件架构没有银弹,往往是取舍。在设计之初,Istio 考虑的是普适性和功能的完备性,支持流量管理、安全、可观测性等多个维度的功能设计,并且随着项目的发展,这个功能不断增强,其实带来的损害就是性能,以及海量实例场景下 CPU 与 内存的巨量消耗。
流量劫持问题
我们可以看到,Istio 在很多实例规模比较小的公司或者业务团队,是可以逐步落地和推广的,但是一旦上了体量,问题就暴露出来了。早期 mixer 组件带来的性能问题尚且不谈,毕竟已经废弃了,但是 iptable 的流量劫持机制,在一定程度上来讲,就是在大规模公司落地的拦路虎。目前 Istio 使用 iptables 实现透明劫持,主要存在以下三个问题:
需要借助于 conntrack 模块实现连接跟踪,在连接数较多的情况下,会造成较大的消耗,同时可能会造成 track 表满的情况,为了避免这个问题,业内有关闭 conntrack 的做法。
iptables 属于常用模块,全局生效,不能显式的禁止相关联的修改,可管控性比较差。
iptables 重定向流量本质上是通过 loopback 交换数据,outbond 流量将两次穿越协议栈,在大并发场景下会损失转发性能。
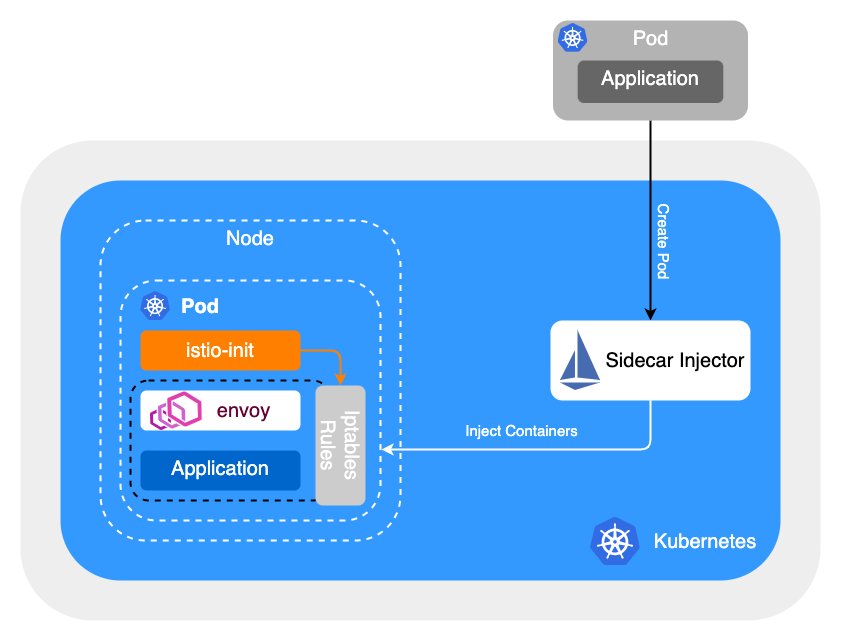
从一些公开信息如技术演讲和博客来看,蚂蚁集团、百度、字节跳动等大规模落地了服务网格的公司来看,基本上都舍弃了 iptables 的流量劫持方案,采用的是基于约定的流量劫持(接管)机制,从而优化了大规模场景下流量劫持和服务间通信的时延和性能。流量劫持方案往往是和公司内部的 Naming Service 以及 服务注册发现机制相结合的,不会一昧地追求零侵入式方案。
以字节跳动为例,采取框架和 Mesh Proxy 进行约定的方式进行接入服务网格治理体系。
入流量:Mesh Proxy 监听 MESH_INRESS_PORT,即可完成入流量劫持。
出流量:业务进程原本调用注册中心 API 进行服务发现的请求过程改为直接请求 localhost 的 MESH_EGRESS_PORT,通过 header 指定目标服务。支持 http 1.1/2.0 以及 grpc 协议。这块需要各个框架进行支持和对接,目前字节内部的服务框架都已经完成了支持。
此外,社区还有一种方案,采用 eBPF 来实现流量劫持。eBPF(extended Berkeley Packet Filter) 是一种可以在 Linux 内核中运行用户编写的程序,而不需要修改内核代码或加载内核模块的技术,目前被广泛用于网络、安全、监控等领域。在 Kubernetes 社区最早也是最有影响的基于 eBPF 项目是 Cilium,Cilium 使用 eBPF 代替 iptables 优化 Service 性能。郑州哪家医院看心理咨询好http://www.hyde8871.com/
入流量,对比 iptables 和 eBPF 对入流量的劫持,iptables 方案每个包都需要 conntrack 处理,而 eBPF 方案只有在应用程序调用 bind 时执行一次,之后不会再执行,减少了性能开销;出流量,对于 TCP 和 connected UDP,iptables 方案每个包都需要 conntrack 处理,而 eBPF 方案的开销是一次性的,只需要在 socket 建立时执行一次,降低了性能开销。
总得来说,使用 eBPF 代替 iptables 实现流量劫持,在一定程度上降低了请求时延和资源开销,但是受限于内核版本,因此短时间内很难大规模落地。
配置下发问题
再来看数据面 envoy 与控制面 istiod 的通信协议 xDS。xDS 包含多种协议的集合,比如:LDS 表示监听器,CDS 表示服务和版本,EDS 表示服务和版本有哪些实例,以及每个服务实例的特征,RDS 表示路由。可以简单的把 xDS 理解为,网格内的服务发现数据和治理规则的集合。xDS 数据量的大小和网格规模是正相关的。
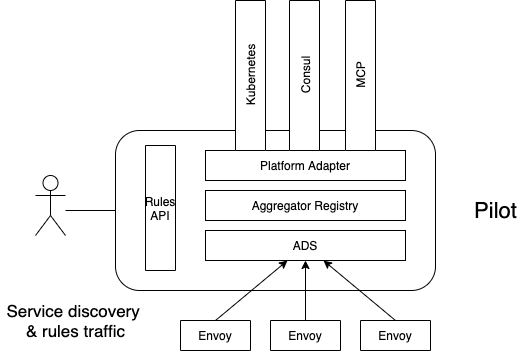
istio 下发 xDS 使用的是全量下发策略,也就是网格里的所有 sidecar,内存里都会有整个网格内所有的服务发现数据,理由是用户很难梳理清楚服务间依赖关系并且提供给 istio。按照这种模式,每个 sidecar 内存都会随着网格规模增长而增长。根据社区有团队对其做的性能测试可以看出,如果网格规模超过 1万个实例,单个 envoy 的内存超过了 250 兆,而整个网格的开销还要再乘以网格规模大小,即 2500 千兆,惊人的消耗!!!
当然,社区也提供了一些解决方案,比如通过手动配置 Sidecar 这个 CRD,可以显示地定义服务间的依赖关系,这要求用户需要手动配置梳理好每一条调用链关系,服务间才能发现彼此,这在大规模场景下也是有一定的局限性。也有社区同学开源出来了一些解决方案,但是都或多或少带来了一些其它问题,譬如单点问题、系统的复杂度提高、运维复杂性、峰值压力等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号