


云原生实践
CRD

上图是从 Kubernetes 官网上摘抄下来的关于 CRD 的说明。这个大家应该都比较熟悉了。Kubernetes 里最重要的概念就是资源,它里面所有的东西都是一个资源或者对象。右图是相关的无状态服务的例子,里面包含了服务的版本、类型、标签以及镜像版本和容器对外提供的端口。在 Kubernetes 里创建无状态服务,你只需要完成定义即可,而 CRD 则可以帮助我们自定义 spec 内的内容。郑州看心理医生多少钱http://www.hyde8025.com/
需要注意的是,定制资源本身只能⽤来存取结构化的数据。只有与定制控制器(Custom Controller)相结合时,才能提供真正的声明式 API (Declarative API)。通过使用声明式 API, 你可以声明或者设定资源的期望状态,并让 Kubernetes 对象的当前状态同步到其期望状态。也就是控制器负责将结构化的数据解释为⽤户所期望状态的记录,并持续地维护该状态。
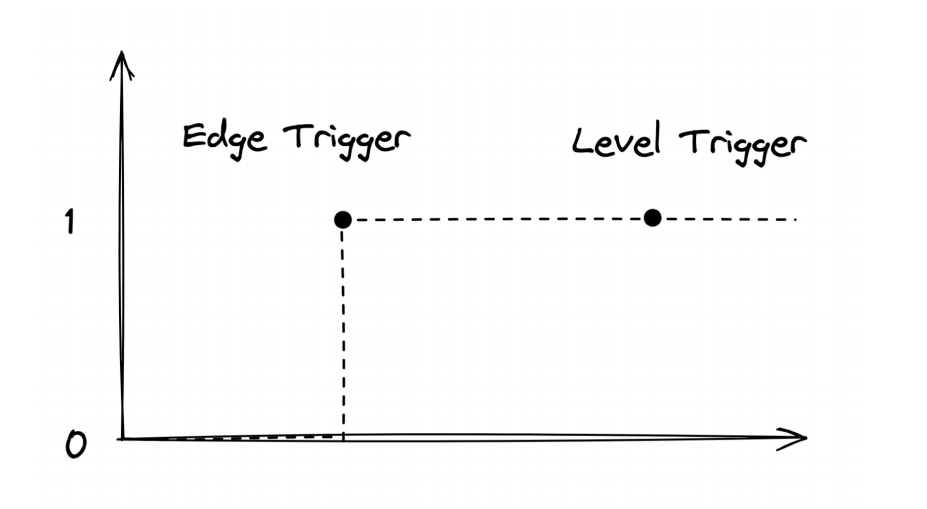
上图是关于声明式 API 的相关实践,采用水平触发的方式。简单举例,电视使用的遥控器是边缘触发,只要你按了更改频道就会立即触发更改。而闹钟则是水平触发,无论在闹钟响动之前更改了多少次,它只会在你最后定好的时间点触发。总结来说就是边缘触发更注重时效性,在更改时会立即反馈。而水平触发则只关注最终的一致性,无论前面如何,只保证最后状态和我们设置的一样就好。
Luffy3.0 CRD
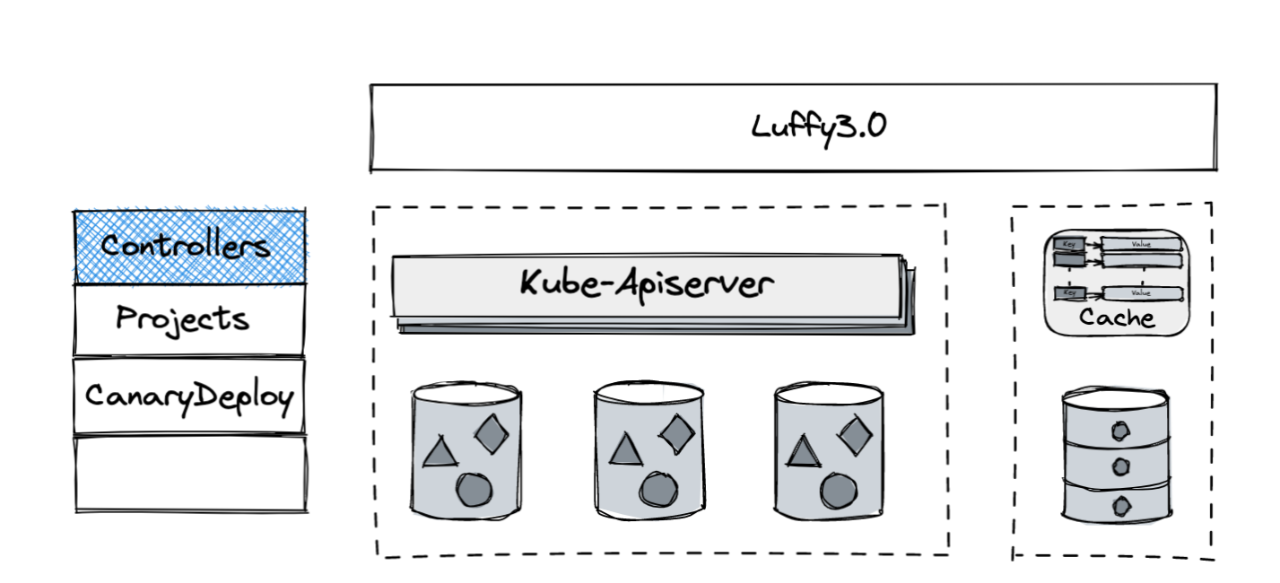
上图是又拍云使用 luffy3.0 做的整体结构,它是架在 Kubernetes 上的,其中和 Kubernetes 的服务相关交互都由 apiserver 完成。
图中右下角的是关系式数据库,关系相关比如用户关系、从属关系,都在这里面。它上面带一层 redis 缓存,来提高热点数据查询效率。左图是我们实现的几个自己的 CRD。第二个 projects 就是相关项目。当年在创立项目时,就是背靠 CRD 的。首先在数据库里写了,然后在 Kubernetes 创建了 projects 这个 CRD 对象。
Kubernetes client-go informer 机制
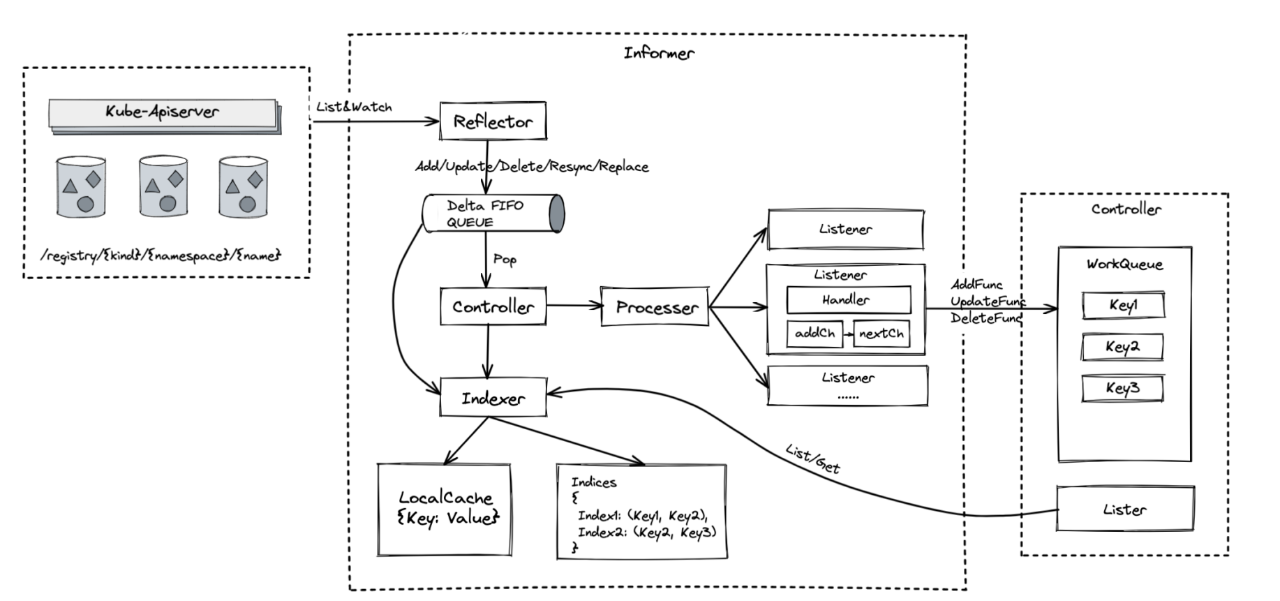
接下来和,大家谈一下 informer 的实现逻辑,informer 是 Kubernetes 官方提供的,方便大家和 Apiserver 做交互的一套 SDK,它比较依赖水平触发的机制。
上图左边是我们的 apiserver,所有的数据都存在 Key-value 的数据库 ETCD 里。在存储时它使用以下结构:
/registry/{kind}/{namespace}/{name}
这之中前缀 registry 是可以修改的,用于防止冲突,kind 是类型,namespace 为命名空间或者说项目名,对应 Luffy3。再后面的 name 是服务名称。在通过 apiserver 对这个对象进行了创建、更新、删除等操作时,ETCD 都会将这个事件反馈给 apiserver。然后 apiserver 会将更改对象开放给 informer。而 informer 是基于单个类型 {kind} 的,这也就说如果你有多个类型,那么你必须对应每一个类型起一个对应的 informer,当然这个可以通过代码来生成。
回到 informer 实现逻辑,当 informer 运行起来后,它会先去 Kubernetes 中获取全量数据,比如当前 informer 对应的类型是无状态服务,那它会获取全部的无状态服务。然后持续 watch apiserver,一旦 apiserver 有新的无状态服务,它都会收到对应事件。收到新事件后,informer 会将时间放入先进先出的队列,让 controller 进行消费。而 controller 会将事件交递给模块 Processer 进行特殊处理。在模块 Processer 上有很多监听器,这些监听器是对特定类型设置的回调函数。
然后来看一下为什么 controller 中的 lister 和 indexer 关联。因为 namespace 和目录很像,在这个目录下会有很多的无状态服务,如果想根据某一规则进行处理,在原生服务上处理肯定是最差的选择,而这就是 lister 所要做的。它会将这部分进行缓存,并做一个索引,也就是 inderxer,这个索引和数据库很像,是由一些 key 组成的。

