
Redis 和 Memcached 的区别
说到redis就会联想到memcached,反之亦然。了解过两者的同学有那么个大致的印象:redis与memcached相比,比仅支持简单的key-value数据类型,同时还提供list,set,zset,hash等数据结构的存储;redis支持数据的备份,即master-slave模式的数据备份;redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用等等,这似乎看起来redis比memcached更加牛逼一些,那么事实上是不是这样的呢?存在即合理,我们来根据几个不同点来一一比较一下。
网络IO模型
memcached是多线程,非阻塞IO复用的网络模型,分为监听主线程和worker子线程,监听线程监听网络连接,接受请求后,将连接描述字pipe传递给worker线程,进行读写IO,网络层使用libevent封装的事件库,多线程模型可以发挥多核作用,但是引入了cache coherency和锁的问题,比如:memcached最常用的stats命令,实际memcached所有操作都要对这个全局变量加锁,进行技术等工作,带来了性能损耗。
redis使用单线程的IO复用模型,自己封装了一个简单的AeEvent事件处理框架,主要实现了epoll, kqueue和select,对于单存只有IO操作来说,单线程可以将速度优势发挥到最大,但是redis也提供了一些简单的计算功能,比如排序、聚合等,对于这些操作,单线程模型施加会严重影响整体吞吐量,CPU计算过程中,整个IO调度都是被阻塞的。
数据支持类型
memcached使用key-value形式存储和访问数据,在内存中维护一张巨大的HashTable,使得对数据查询的时间复杂度降低到O(1),保证了对数据的高性能访问。
正如开篇所说:redis与memcached相比,比仅支持简单的key-value数据类型,同时还提供list,set,zset,hash等数据结构的存储;详细可以翻阅《Redis内存使用优化与存储》
内存管理机制
对于像Redis和Memcached这种基于内存的数据库系统来说,内存管理的效率高低是影响系统性能的关键因素。传统C语言中的malloc/free函数是最常用的分配和释放内存的方法,但是这种方法存在着很大的缺陷:首先,对于开发人员来说不匹配的malloc和free容易造成内存泄露;其次频繁调用会造成大量内存碎片无法回收重新利用,降低内存利用率;最后作为系统调用,其系统开销远远大于一般函数调用。所以,为了提高内存的管理效率,高效的内存管理方案都不会直接使用malloc/free调用。Redis和Memcached均使用了自身设计的内存管理机制,但是实现方法存在很大的差异,下面将会对两者的内存管理机制分别进行介绍。
Memcached默认使用Slab Allocation机制管理内存,其主要思想是按照预先规定的大小,将分配的内存分割成特定长度的块以存储相应长度的key-value数据记录,以完全解决内存碎片问题。Slab Allocation机制只为存储外部数据而设计,也就是说所有的key-value数据都存储在Slab Allocation系统里,而Memcached的其它内存请求则通过普通的malloc/free来申请,因为这些请求的数量和频率决定了它们不会对整个系统的性能造成影响Slab Allocation的原理相当简单。 如图所示,它首先从操作系统申请一大块内存,并将其分割成各种尺寸的块Chunk,并把尺寸相同的块分成组Slab Class。其中,Chunk就是用来存储key-value数据的最小单位。每个Slab Class的大小,可以在Memcached启动的时候通过制定Growth Factor来控制。假定图中Growth Factor的取值为1.25,如果第一组Chunk的大小为88个字节,第二组Chunk的大小就为112个字节,依此类推。
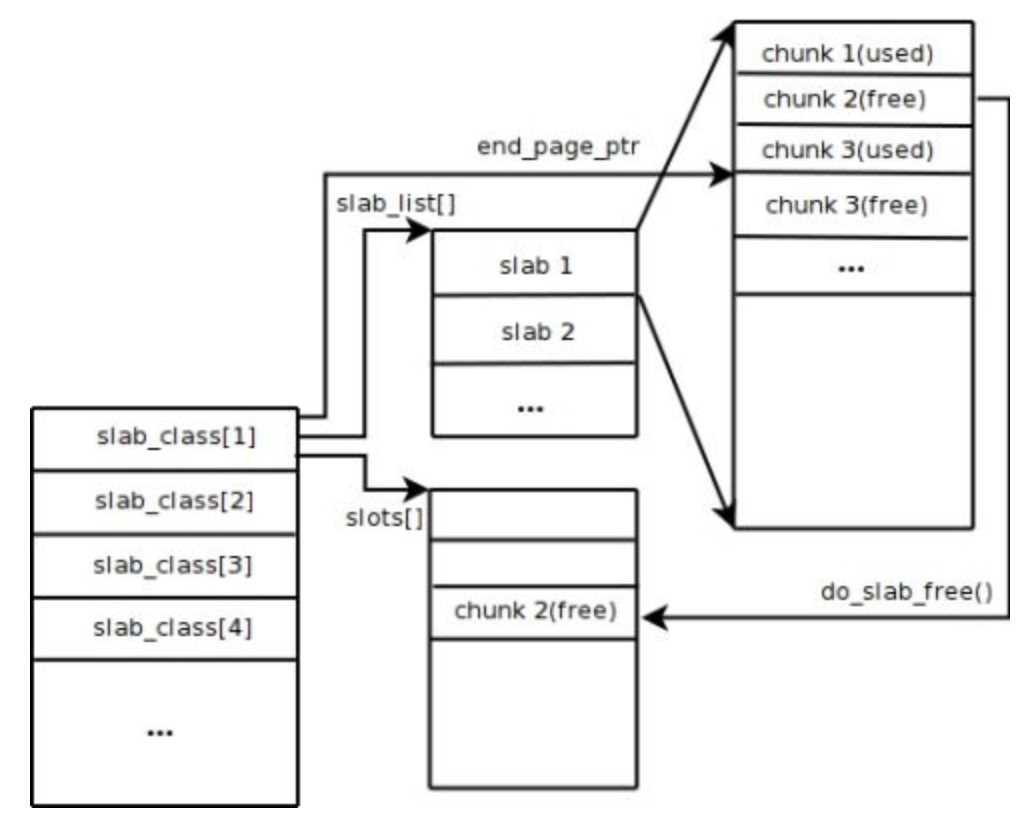
当Memcached接收到客户端发送过来的数据时首先会根据收到数据的大小选择一个最合适的Slab Class,然后通过查询Memcached保存着的该Slab Class内空闲Chunk的列表就可以找到一个可用于存储数据的Chunk。当一条数据库过期或者丢弃时,该记录所占用的Chunk就可以回收,重新添加到空闲列表中。从以上过程我们可以看出Memcached的内存管理制效率高,而且不会造成内存碎片,但是它最大的缺点就是会导致空间浪费。因为每个Chunk都分配了特定长度的内存空间,所以变长数据无法充分利用这些空间。如图 所示,将100个字节的数据缓存到128个字节的Chunk中,剩余的28个字节就浪费掉了。

Redis的内存管理主要通过源码中zmalloc.h和zmalloc.c两个文件来实现的。Redis为了方便内存的管理,在分配一块内存之后,会将这块内存的大小存入内存块的头部。如图所示,real_ptr是redis调用malloc后返回的指针。redis将内存块的大小size存入头部,size所占据的内存大小是已知的,为size_t类型的长度,然后返回ret_ptr。当需要释放内存的时候,ret_ptr被传给内存管理程序。通过ret_ptr,程序可以很容易的算出real_ptr的值,然后将real_ptr传给free释放内存。

Redis通过定义一个数组来记录所有的内存分配情况,这个数组的长度为ZMALLOC_MAX_ALLOC_STAT。数组的每一个元素代表当前程序所分配的内存块的个数,且内存块的大小为该元素的下标。在源码中,这个数组为zmalloc_allocations。zmalloc_allocations[16]代表已经分配的长度为16bytes的内存块的个数。zmalloc.c中有一个静态变量used_memory用来记录当前分配的内存总大小。所以,总的来看,Redis采用的是包装的mallc/free,相较于Memcached的内存管理方法来说,要简单很多。
在Redis中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别。当物理内存用完时,Redis可以将一些很久没用到的value交换到磁盘。Redis只会缓存所有的key的信息,如果Redis发现内存的使用量超过了某一个阀值,将触发swap的操作,Redis根据“swappability = age*log(size_in_memory)”计算出哪些key对应的value需要swap到磁盘。然后再将这些key对应的value持久化到磁盘中,同时在内存中清除。这种特性使得Redis可以保持超过其机器本身内存大小的数据。当然,机器本身的内存必须要能够保持所有的key,毕竟这些数据是不会进行swap操作的。同时由于Redis将内存中的数据swap到磁盘中的时候,提供服务的主线程和进行swap操作的子线程会共享这部分内存,所以如果更新需要swap的数据,Redis将阻塞这个操作,直到子线程完成swap操作后才可以进行修改。当从Redis中读取数据的时候,如果读取的key对应的value不在内存中,那么Redis就需要从swap文件中加载相应数据,然后再返回给请求方。 这里就存在一个I/O线程池的问题。在默认的情况下,Redis会出现阻塞,即完成所有的swap文件加载后才会相应。这种策略在客户端的数量较小,进行批量操作的时候比较合适。但是如果将Redis应用在一个大型的网站应用程序中,这显然是无法满足大并发的情况的。所以Redis运行我们设置I/O线程池的大小,对需要从swap文件中加载相应数据的读取请求进行并发操作,减少阻塞的时间。
Memcached使用预分配的内存池的方式,使用slab和大小不同的chunk来管理内存,Item根据大小选择合适的chunk存储,内存池的方式可以省去申请/释放内存的开销,并且能减小内存碎片产生,但这种方式也会带来一定程度上的空间浪费,并且在内存仍然有很大空间时,新的数据也可能会被剔除,原因可以参考Timyang的文章:http://timyang.net/data/Memcached-lru-evictions/
Redis使用现场申请内存的方式来存储数据,并且很少使用free-list等方式来优化内存分配,会在一定程度上存在内存碎片,Redis跟据存储命令参数,会把带过期时间的数据单独存放在一起,并把它们称为临时数据,非临时数据是永远不会被剔除的,即便物理内存不够,导致swap也不会剔除任何非临时数据(但会尝试剔除部分临时数据),这点上Redis更适合作为存储而不是cache。
数据存储及持久化
memcached不支持内存数据的持久化操作,所有的数据都以in-memory的形式存储。
redis支持持久化操作。redis提供了两种不同的持久化方法来讲数据存储到硬盘里面,一种是快照(snapshotting),它可以将存在于某一时刻的所有数据都写入硬盘里面。另一种方法叫只追加文件(append-only file, AOF),它会在执行写命令时,将被执行的写命令复制到硬盘里面。
数据一致性问题
Memcached提供了cas命令,可以保证多个并发访问操作同一份数据的一致性问题。 Redis没有提供cas 命令,并不能保证这点,不过Redis提供了事务的功能,可以保证一串 命令的原子性,中间不会被任何操作打断。
集群管理不同
Memcached是全内存的数据缓冲系统,Redis虽然支持数据的持久化,但是全内存毕竟才是其高性能的本质。作为基于内存的存储系统来说,机器物理内存的大小就是系统能够容纳的最大数据量。如果需要处理的数据量超过了单台机器的物理内存大小,就需要构建分布式集群来扩展存储能力。
Memcached本身并不支持分布式,因此只能在客户端通过像一致性哈希这样的分布式算法来实现Memcached的分布式存储。下图给出了Memcached的分布式存储实现架构。当客户端向Memcached集群发送数据之前,首先会通过内置的分布式算法计算出该条数据的目标节点,然后数据会直接发送到该节点上存储。但客户端查询数据时,同样要计算出查询数据所在的节点,然后直接向该节点发送查询请求以获取数据。
相较于Memcached只能采用客户端实现分布式存储,Redis更偏向于在服务器端构建分布式存储。最新版本的Redis已经支持了分布式存储功能。Redis Cluster是一个实现了分布式且允许单点故障的Redis高级版本,它没有中心节点,具有线性可伸缩的功能。Redis Cluster的分布式存储架构,节点与节点之间通过二进制协议进行通信,节点与客户端之间通过ascii协议进行通信。在数据的放置策略上,Redis Cluster将整个key的数值域分成4096个哈希槽,每个节点上可以存储一个或多个哈希槽,也就是说当前Redis Cluster支持的最大节点数就是4096。Redis Cluster使用的分布式算法也很简单:crc16( key ) % HASH_SLOTS_NUMBER。
为了保证单点故障下的数据可用性,Redis Cluster引入了Master节点和Slave节点。在Redis Cluster中,每个Master节点都会有对应的两个用于冗余的Slave节点。这样在整个集群中,任意两个节点的宕机都不会导致数据的不可用。当Master节点退出后,集群会自动选择一个Slave节点成为新的Master节点。
全文完,感谢您的耐心阅读~
欢迎大家关注我的公众号


 浙公网安备 33010602011771号
浙公网安备 33010602011771号