
YbSoftwareFactory 代码生成插件【十八】:树形结构下的查询排序的数据库设计
树形结构的排序在中国特色下十分普遍也非常重要,例如常说的五大班子,党委>人大>政府>政协>纪委,每个班子下还有部门,岗位,人员,最终排列的顺序通常需要按权力大小、重要性等进行排列,顺序排列不好可是重大的罪过,领导很生气,后果很严重。这种排序方式本质上就是典型的树形结构深度排序,但在数据库中很难直接通过SQL语句简单高效地进行处理,更不用说还要支持不同类型数据库了。
当前解决此类问题,主要有两种方法。
1. 排序码方式
- 原理:在每个树形节点上均设置一个排序码,排序码通常是一个字符串并存入数据库,例如
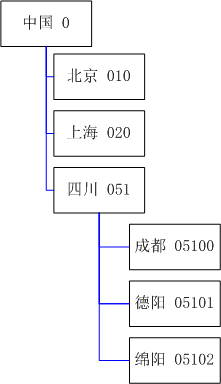
- 优点:只需一个冗余字段,数据库中存储显示直观,查询和排序既方便也高效,无需递归,只用一条查询语句即可得到某个根节点及其所有子孙节点的先序遍历。例如需要查询四川下所有地区并进行排序,使用SQL 语句“LIKE ‘0510%’ ORDER BY 地区” 即可查询并排列出结果。
- 缺点:通常在录入树形节点时需要人工指定排序码,在同层节点间插入新的节点时需要考虑编码重复导致排序失效的问题;后续如需对排序顺序进行置顶、前移、后移、置底等类似的调整则非常不方便;同时这种编码方案由于层信息位数的限制,限制了每层所能允许的最大子节点数量及最大层数。
2. 左右值编码
- 原理:请参考“采用左右值编码来存储无限分级树形结构的数据库表设计”
- 优点:无需人工设定排序编码,可交由系统计算后生成;同样无需递归,同时还能实现无限分级;查询条件基于整形数字比较的,效率很高;还能方便地进行先序列表,添加,修改,删除,同层平移等常规操作。
- 缺点:主要是显示不直观,维护不方便,需要考虑数据库的并发操作。由于这种左右值编码的方式和常见的阿拉伯数字直观排序不同,再加上节点在树中的层次,顺序不能直观显示出来,而必须通过简单的公式计算后得到,需要花费一定的时间对其数学模型进行深入理解。而且,采用该方案编写相关存储过程,新增,删除,同层平移节点需要对整个树进行查询修改,由此导致的代码复杂度,耦合度较高,修改维护的风险较高。数据库中某个节点的编码被错误修改可能就会导致整体排序失败,但很难及时方便地定位到具体的错误原因。本设计需要两个冗余字段。
本文介绍的设计方式则是前文介绍的权限模型中组织机构树所采用的排序码+排序值方式:http://www.cnblogs.com/gyche/p/3670179.html
排序码+排序值
- 原理
1)数据库表结构的设计中增加两个排序字段,其中一个字段存储排序码,类型为字符串,另一个字段存储排序值,类型为浮点型。排序码最终参与SQL语句的查询和排序结果的生成;排序值为辅助字段,主要用于同层次节点间排序顺序的比较、排序顺序的调整修改等并最终根据其值格式化生成排序码,该字段并不直接参与SQL语句的查询和排序,主要是在对排序顺序进行调整时非常有用。
2)新增节点时,查找要插入节点所在的父节点的排序码和父节点下所有直接子节点的最大排序值并加1得出实际排序值(此处假想添加的节点总是排在同层节点的最后),根据该排序值格式化出固定长度的排序码并和父节点的排序码组合,中间使用“/”字符隔开,生成实际的排序码。例如,父结点的排序码为“/000000000000000000129.”,当前计算出的排序值为320,对应的排序值则为:“000000000000000000320.”,则最终的排序码就应该是“/000000000000000000129./000000000000000000320.”。
此处需要注意的是,排序值为负数的情况下,需要使用浮点值所允许的最小值-去排序值来格式化生成排序码(因为最终排序使用的是字符串比较),否则排序值为负数的情况下使用字符串比较进行排序就会出现问题,生成排序码的程序代码如下:
/// <summary>
/// 格式化生成排序码
/// </summary>
/// <param name="parentOrderCode">父排序码</param>
/// <param name="displayOrder">排序值</param>
/// <returns>生成的排序码</returns>
internal override string FormatOrderCode(string parentOrderCode, decimal displayOrder)
{
if (displayOrder < decimal.Zero)
{
displayOrder = decimal.MinValue - displayOrder;
}
//可根据需要调整生成排序码的格式和长度
var orderCode = string.Format("{0:000000000000000000000.000000000000000000}", displayOrder).Replace('-', '#').TrimEnd(new[] { '0' });
return string.Format("{0}/{1}", parentOrderCode, orderCode); ;
}
- 优点:具有方式1的所有优点,数据库中存储显示直观,查询和排序既方便也高效,无需递归,只用一条查询语句即可得到某个根节点及其所有子孙节点的先序遍历;而且无需人工设定排序编码,可交由系统计算后生成;同时后续调整排序顺序也非常方便,只需重新计算该节点要调整后的排序值并重新生成排序码,然后使用各种数据库都普遍支持,并且语法也基本一样的“REPLACE” SQL 语句批量替换排序码字符串即可完成当前节点及下属所有子节点的排序调整任务,对排序的置顶、前移、后移、置底等实现都非常简单,例如下图的效果,乃至于实现在界面上以拖拽的方式对每个树节点进行排序顺序的调整,也是非常方便的。
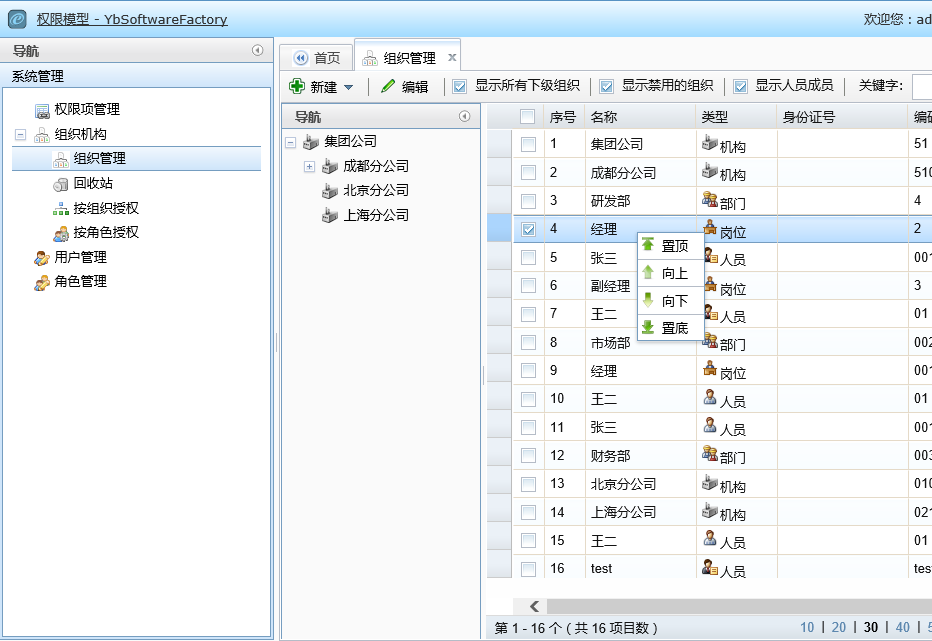
- 缺点:需要两个冗余字段,调整节点顺序后,系统需自动对当前节点即下属节点的排序码字段的值进行维护;同时也和方式1一样,这种编码方案由于层信息位数的限制,限制了每层所能允许的最大子节点数量及最大层数(例如排序码字段在数据库中设计的字符串长度为4000,每层节点固定长度为40的话,最大层数可允许为100层,但在实际应用中,超过十层的树形节点已是非常罕见的)。

附 - 排序在线演示:http://pjdemo.yellbuy.com/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号