

java高并发核心要点|系列6|LMAX-Disruptor核心原理
说完了java的cacheline的原理,
那现在来进一步讨论下怎么在现实项目中,实现更高性能高并发程序。
所以,今天我们可以介绍一下著名的高并发框架:disruptor.原项目:https://github.com/LMAX-Exchange/disruptor
Disruptor是一个高性能的异步处理框架,或者可以认为是线程间通信的高效低延时的内存消息组件,它最大特点是高性能,其LMAX架构可以获得每秒6百万订单,用1微秒的延迟获得吞吐量为100K+。
LMAX需要搭建高性能的交易平台, 所以需要基于并发编程模型 (并发编程模型和访问控制:https://www.cnblogs.com/fxjwind/p/3170032.html)
当然他们也关注类似Actor或SEDA模型, 并进行了测试, 从而发现了性能瓶颈-- 对于队列的管理
如图这样比较简单的处理流程, 就需要4个queue和大量的message发送, disruptor设计了一种高效的替代方案
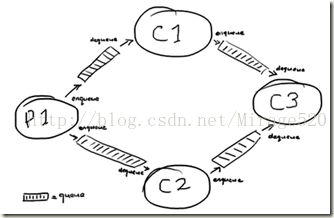
一般来说,线程间的异步通讯,我们会用java内置的队列。
介绍Disruptor之前,我们先来看一看常用的线程安全的内置队列有什么问题。Java的内置队列如下表所示。
队列 有界性 锁 数据结构
ArrayBlockingQueue bounded 加锁 arraylist
LinkedBlockingQueue optionally-bounded 加锁 linkedlist
ConcurrentLinkedQueue unbounded 无锁 linkedlist
LinkedTransferQueue unbounded 无锁 linkedlist
PriorityBlockingQueue unbounded 加锁 heap
DelayQueue unbounded 加锁 heap
队列的底层一般分成三种:数组、链表和堆。其中,堆一般情况下是为了实现带有优先级特性的队列,暂且不考虑。
我们就从数组和链表两种数据结构来看,基于数组线程安全的队列,比较典型的是ArrayBlockingQueue,它主要通过加锁的方式来保证线程安全;基于链表的线程安全队列分成LinkedBlockingQueue和ConcurrentLinkedQueue两大类,前者也通过锁的方式来实现线程安全,而后者以及上面表格中的LinkedTransferQueue都是通过原子变量compare and swap(以下简称“CAS”)这种不加锁的方式来实现的。
通过不加锁的方式实现的队列都是无界的(无法保证队列的长度在确定的范围内);而加锁的方式,可以实现有界队列。在稳定性要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列;同时,为了减少Java的垃圾回收对系统性能的影响,会尽量选择array/heap格式的数据结构。这样筛选下来,符合条件的队列就只有ArrayBlockingQueue。
ArrayBlockingQueue在实际使用过程中,会因为加锁和伪共享等出现严重的性能问题,我们下面来分析一下。
加锁
现实编程过程中,加锁通常会严重地影响性能。线程会因为竞争不到锁而被挂起,等锁被释放的时候,线程又会被恢复,这个过程中存在着很大的开销,并且通常会有较长时间的中断,因为当一个线程正在等待锁时,它不能做任何其他事情。如果一个线程在持有锁的情况下被延迟执行,例如发生了缺页错误、调度延迟或者其它类似情况,那么所有需要这个锁的线程都无法执行下去。如果被阻塞线程的优先级较高,而持有锁的线程优先级较低,就会发生优先级反转。
Disruptor论文中讲述了一个实验:
这个测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次。
机器环境:2.4G 6核
运算: 64位的计数器累加5亿次
Method Time (ms)
Single thread 300
Single thread with CAS 5,700
Single thread with lock 10,000
Single thread with volatile write 4,700
Two threads with CAS 30,000
Two threads with lock 224,000
CAS操作比单线程无锁慢了1个数量级;有锁且多线程并发的情况下,速度比单线程无锁慢3个数量级。可见无锁速度最快。
单线程情况下,不加锁的性能 > CAS操作的性能 > 加锁的性能。
在多线程情况下,为了保证线程安全,必须使用CAS或锁,这种情况下,CAS的性能超过锁的性能,CAS大约是锁的8倍。
Disruptor采用特殊的ring buffer来作为queue实现的数据结构。
ring buffer有什么过人之处呢?
1, 用何种数据机构来实现Queue
如何使用Disruptor(一)Ringbuffer的特别之处
实现queue首先想到链表, 但使用链表有下列问题,
- 节点分散, 不利于cache预读
- 节点每次需要分配和释放, 需要大量的垃圾回收, 低效
- 不利于批量读取
- 竞争点较多, head指针, tail指针, size
由于producer和consumer很难同步, 所以大部分queue都是满或空状态, 这样会导致大量的竞争, 比较低效 - 而且习惯的编程方式导致head指针, tail指针, size常常在一个cacheline中, 造成伪共享问题
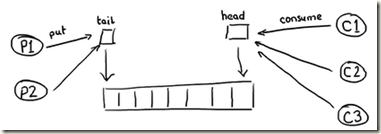
那么用数组实现, 可以部分解决前3点问题, 但仍然无法解决竞争点问题, 以及由于数组的fix size, 带来扩展性问题
Disruptor采用特殊的ring buffer来作为queue实现的数据结构, 解决了上述的问题
并且这种ring buffer只用了一个标志指针, 即标志下一个写入位置
求余操作本身也是一种高耗费的操作, 所以ringbuffer的size设成2的n次方, 可以利用位操作来高效实现求余
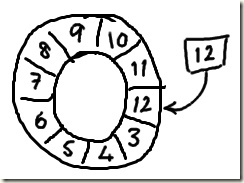
2, 减少竞争点, 分离关注
对于传统的3个竞争点, Disruptor成功的通过ring buffer将其降低到1个, 提高了效率
只有producer需要关注这个写入标志位, 如果只有一个producer的话, 那么完全就不需要lock, 当然如果有多个producer的时候, 就需要通过ProducerBarrier在写入标志位上做互斥
对于consumer, 每个consumer各自记录读入标志位, 并且通过ConsumerBarrier不停的侦听当前最大可读标志位, 即写入标志位
这样的设计成功的将关注点分离
3, Lock-free
前面说了disruptor减少竞争点, 但是不可能完全消除竞争, 对于写入标志位, 当多个producer的时候仍然存在竞争, 竞争就需要加锁.
剖析Disruptor:为什么会这么快?(一)锁的缺点 :http://ifeve.com/locks-are-bad/
锁是很低效的, 论文中的3.1讲的比较清晰, 并通过实验数据证明了这点, 使用锁会慢1000倍
- 系统态的锁会导致线程cache丢失. 锁竞争的时候需要进行仲裁. 这个仲裁会涉及到操作系统的内核切换, 并且在此过程中操作系统需要做一系列操作, 导致原有线程的指令缓存和数据缓很可能被丢掉
- 用户态的锁往往是通过自旋锁来实现(自旋即忙等), 而自旋在竞争激烈的时候开销是很大的(一直在消耗CPU资源)
那么disruptor的怎么做? lock-free, 不使用锁, 使用CAS(Compare And Swap/Set)
严格意义上说仍然是使用锁, 因为CAS本质上也是一种乐观锁, 只不过是CPU级别指令, 不涉及到操作系统, 所以效率很高
Java提供CAS操作的支持, AtomicLong
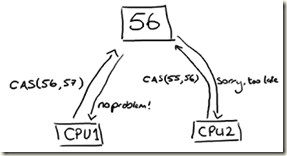
CAS依赖于处理器的支持, 当然大部分现代处理器都支持.
CAS相对于锁是非常高效的, 因为它不需要涉及内核上下文切换进行仲裁.
但CAS并不是免费的, 它会涉及到对指令pipeline加锁, 并且会用到内存barrier(用来刷新内存状态,简单理解就是把缓存中,寄存器中的数据同步到内存中去)
CAS的问题就是更为复杂, 比使用lock更难于理解, 并且虽然相对于lock已经很高效, 但是由于上面提到的耗费, 仍然比不使用任何锁机制要慢的多
所以对于disruptor, 如果能保证只有一个producer就可以完全不使用lock, 甚至CAS, 是很高效的方案
当然在不得不使用多个producer的情况下, 只能使用CAS
4, 解决伪共享(False Sharing)
前面文章讲到解决False Sharing,我们一般用:缓存行填充, 来保证这个cache-line只存储这一个数据, 从而避免其他数据的更改对该cache-line的影响
当然显而易见, 这种缓存行填充是非常浪费的, cache本身就是很昂贵的资源, 所以必须慎用
在Disruptor里我们对RingBuffer的cursor和BatchEventProcessor的序列进行了缓存行填充
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding
private volatile long cursor = INITIAL_CURSOR_VALUE;
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding
以cursor为例, 本身是独立的变量, 和其他的数据没有关联关系, 并且cursor会频繁的被所有线程读取, 所以如果由于其他不相关的变量的更改而导致cursor所在的cache-line被频繁reload, 是非常低效的.
所以, disruptor在cursor前后都pading了7个long, 从而避免cursor和任意其他的变量在同一个cache-line。
使用缓存行填充的准则:
1.独立变量;
2.变量被大量线程touch, 会被频繁使用和读取。
5, 使用内存屏障
http://ifeve.com/linux-memory-barriers/, 非常详细的介绍了内存屏障的原理
剖析Disruptor:为什么会这么快?(四)揭秘内存屏障:http://ifeve.com/disruptor-memory-barrier/
聊聊并发(一)深入分析Volatile的实现原理:http://ifeve.com/volatile/
首先, 内存屏障本身不是一种优化方式, 而是你使用lock-free(CAS)的时候, 必须要配合使用内存屏障。java中用volatile关键字来实现。
6,如何使用Disruptor替代Queue
解析Disruptor关系组装:http://ifeve.com/dissecting-disruptor-wiring-up-cn/
实际项目中是用一个ringbuffer替代所有的queue, 怎么实现的?如下图:
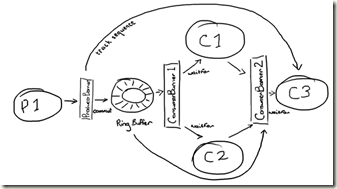
如图, 所有consumer都是从RingBuffer里面读数据
而C3, 依赖于C1和C2的执行结果, 那么通过设置ConsumerBarrier2来监控C1和C2的执行序号
那么有个问题是C3, 如何获得C1和C2的执行结果?
答案是, C1和C2执行完后, 会把结果写回Ringbuffer中原来的entry中
image
如图, 当C3拿到Entry时, 里面有3个值, 本来的value, C1处理的结果, C2处理的结果, 并且不同的consumer写的字段不一样来避免冲突
而Producer在监控consumer消费序号时, 只需要监控最后一层的, 即C3的, 因为只有C3处理完, 这个entry才能被覆盖.
看起来非常的复杂, 但是在使用时, 对用户很多机制其实是透明的, 比如上面的workflow的代码如下
ConsumerBarrier consumerBarrier1 =
ringBuffer.createConsumerBarrier();
BatchConsumer consumer1 =
new BatchConsumer(consumerBarrier1, handler1);
BatchConsumer consumer2 =
new BatchConsumer(consumerBarrier1, handler2);
ConsumerBarrier consumerBarrier2 =
ringBuffer.createConsumerBarrier(consumer1, consumer2);
BatchConsumer consumer3 =
new BatchConsumer(consumerBarrier2, handler3);
ProducerBarrier producerBarrier =
ringBuffer.createProducerBarrier(consumer3);
对用户而言, 只需要知道ConsumerBarrier, Consumer, ProducerBarrier
总结
总体来说, disprutor从两个方面来对Actor模式的queue做了优化
最重要的是, Mechanical Sympathy(机械的共鸣), 了解硬件的工作方式来编写和硬件完美结合的软件, 很高的境界
通过利用CAS+内存屏障实现lock-free, 并使用缓存行填充来解决伪共享, 可见虽然编程语言已经发展到很高级的地步, 但是如果要追求效率的机制, 必须要具有Mechanical Sympathy, 人剑合一
其次, 是通过ringbuffer来实现queue来替代链表的实现, 尤其当场景比较复杂需要很多queue的时候, 效率应该会得到很大的提高。
总之,我们看到disruptor的设计哲学,就是读写分离,关注点分离。
这个哲学,也是实现高性能高可用程序的关键。
参与文章:
https://www.cnblogs.com/fxjwind/p/3180073.html
https://tech.meituan.com/2016/11/18/disruptor.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异