
HBase
1.HBase是什么
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Apache Hadoop中的一个子项目,Hbase依托于Hadoop的HDFS作为最基本存储基础单元,通过使用hadoop的DFS工具就可以看到这些这些数据 存储文件夹的结构,还可以通过Map/Reduce的框架(算法)对HBase进行操作,如下图所示:
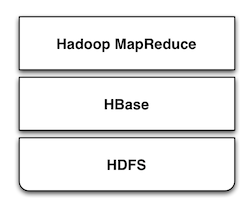
HBase在产品中还包含了Jetty,在HBase启动时采用嵌入式的方式来启动Jetty,因此可以通过web界面对HBase进行管理和查看当前运行的一些状态,非常轻巧。
2.HBase数据模型


下面分别说说几个关键概念:
3.HBase物理模型
每个column family存储在HDFS上的一个单独文件中,空值不会被保存。
Key 和 Version number(即时间戳,timestamp)在每个 column family中均有一份;
HBase 为每个值维护了多级索引,即:<key, column family, column name, timestamp>
物理存储:
1、Table中所有行都按照row key的字典序排列;
2、Table在行的方向上分割为多个Region;
3、Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;
4、Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。

5、Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个store保存一个columns family;每个Strore又由一个memStore和0至多个StoreFile组成,StoreFile包含HFile;memStore存储在内存中,StoreFile存储在HDFS上。

