

正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

-----------------------正文开始---------------------------
最近学习了关于使用MySql数据的实现主动结构的原理,在以前的并发访问低的场景一下,一般一台性能高的服务器作为一个MySql数据,就可以满足业务的增删改查场景,但是随着网络用户的增加
当出现高并发,高QPS的情况下,一台MySql就很难支撑这种场景了,根据现在的分布式处理架构,处理在使用Redis这种高效的缓存数据库外,其实也可以针对数据库端进行分布式处理,也就是原来
和Redis相同,使用分布式主从架构,通过Master 和 Slave 实现读写分析,数据采用主从复制的原理,这种采用读写分析,同时读的Slave机器可以多台配置的架构,极大了增加的后台的稳定性和满足
高并发的情景;
下面进行原理分析:
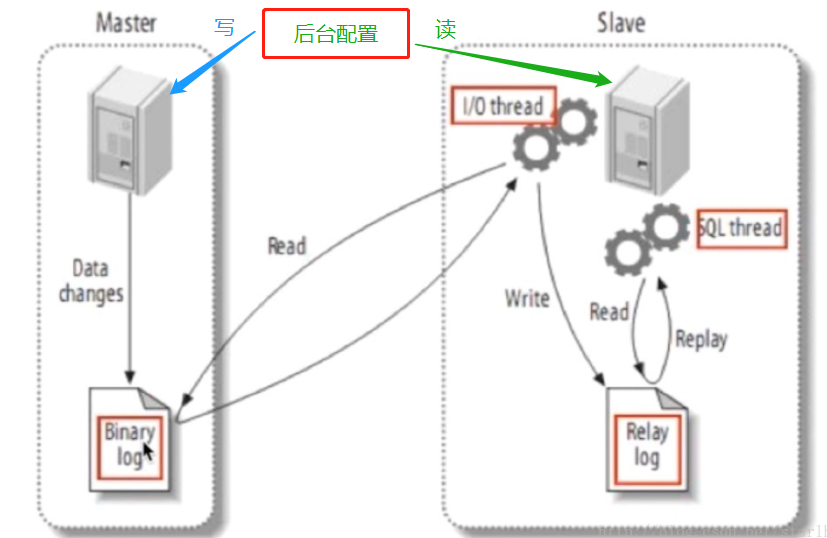
配置的简要过程说明:
Mysql的配置文件【在Spring中进行设置】
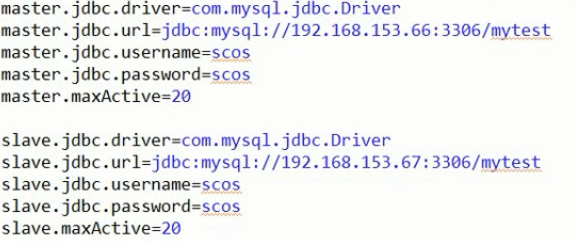
数据源的配置:
Master数据源:

Slave数据源:

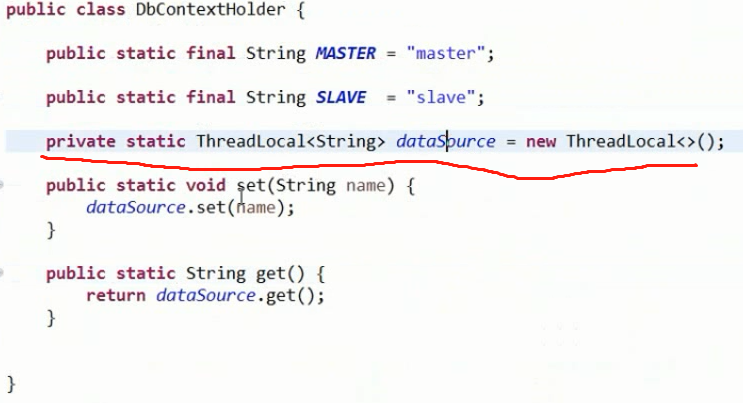
源代码的可以采用基于自定义注解的方式实现:
1、使用一个选择类,用来配置选择方式;
系统的配置需要采用一个路由配置:
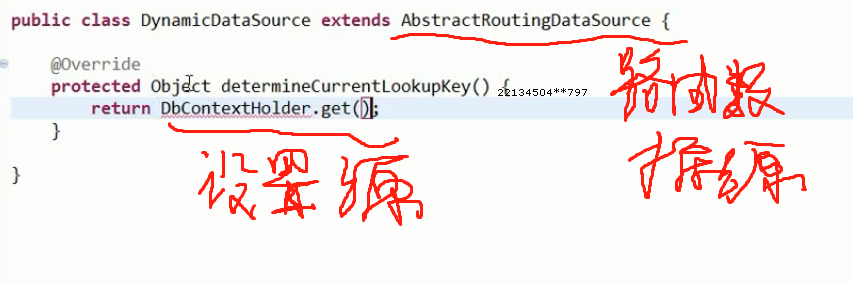
在spring中注册数据源【通过master和slave关键字匹配对应的数据源】:

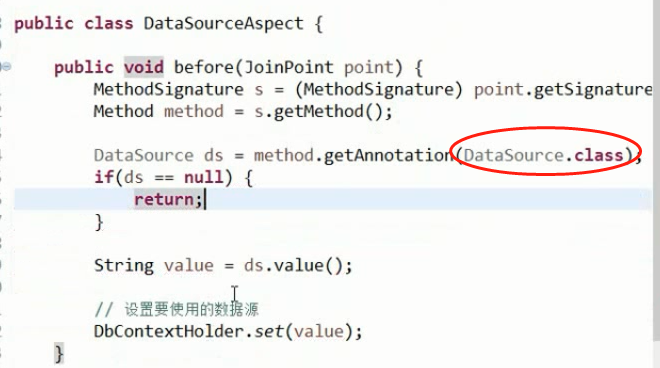
采用注解的方式实现在Mapper接口上通过注解就可以实现自动匹配,效果如下:

自定义注解的实现:使用Aspectj的代理模式 AOP原理:
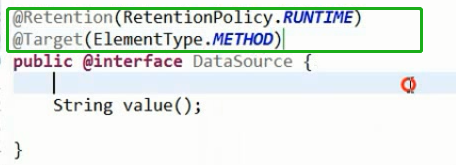
把注解匹配到具体实现:
Spring中配置注册:
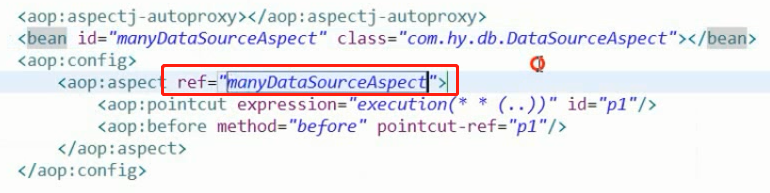
配置完成!

