

正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

-----------------------正文开始---------------------------
一、Bean的生命过程
Bean的生命过程可以借鉴Servlet的生命过程,了解其生命过程对于不管是思想还是以后的使用都很有帮助;
Bean可以通过两种方式进行加载,分别是使用BeanFactory 和 applicationContext, 下边就这两种方式进行Bean的声明周期总结:
applicationContext:
先用一种生命周期流程图来概括;
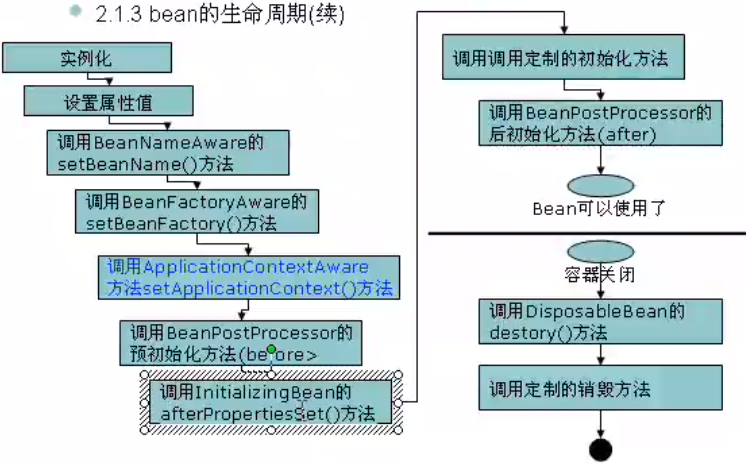
1:Bean的建立:
容器寻找Bean的定义信息并将其实例化,也就是new一个对象,。
2:属性注入:
使用依赖注入,Spring按照Bean定义信息配置Bean所有属性,相当于调用set方法进行属性set操作
3. 如果这个Bean实现了BeanNameAware接口,会调用它实现的setBeanName(String beanId)方法,此处传递的是Spring配置文件中Bean的ID
4. 如果这个Bean实现了BeanFactoryAware接口,会调用它实现的setBeanFactory(),传递的是Spring工厂本身(可以用这个方法获取到其他Bean)
5. 如果这个Bean实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文,该方式同样可以实现步骤4,但比4更好,以为ApplicationContext是BeanFactory的子接口,有更多的实现方法
6. 如果这个Bean关联了BeanPostProcessor接口,将会调用postProcessBeforeInitialization(Object obj, String s)方法,BeanPostProcessor经常被用作是Bean内容的更改,并且由于这个是在Bean初始化结束时调用After方法,也可用于内存或缓存技术
7.如果设置了initializingBean接口,则会调用实现的afterPropertiesSet()方法;
8. 如果这个Bean在Spring配置文件中配置了init-method属性会自动调用其配置的初始化方法【相当于定制方法】
9. 如果这个Bean关联了BeanPostProcessor接口,将会调用postAfterInitialization(Object obj, String s)方法
注意:以上工作完成以后就可以用这个Bean了,那这个Bean是一个single的,所以一般情况下我们调用同一个ID的Bean会是在内容地址相同的实例
10. 容器关闭,当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean接口,会调用其实现的destroy方法,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法
BeanFactory:
下边对BeanFactory的生命周期过程进行分析,BeanFactory的生命周期相对于ApplicationContext来说相对简化了一些;
下面用图进行概括:
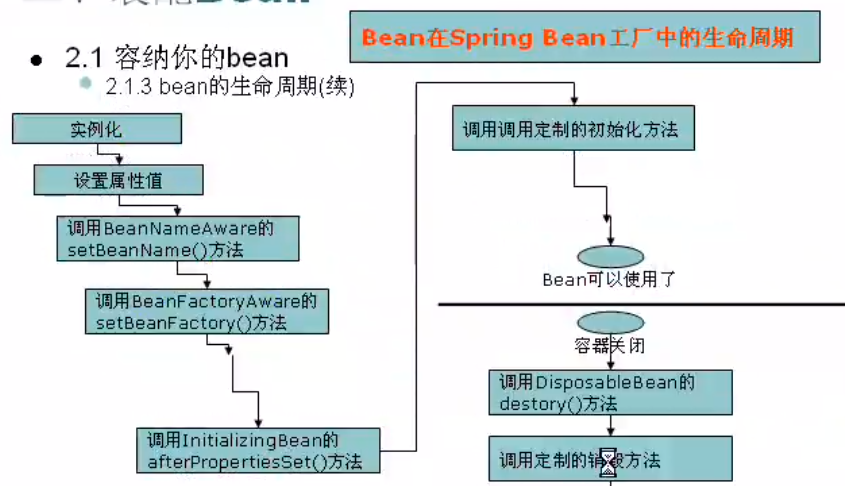
下面以BeanFactory为例,说明一个Bean的生命周期活动
- Bean的建立, 由BeanFactory读取Bean定义文件,并生成各个实例
- Setter注入,执行Bean的属性依赖注入
- BeanNameAware的setBeanName(), 如果实现该接口,则执行其setBeanName方法
- BeanFactoryAware的setBeanFactory(),如果实现该接口,则执行其setBeanFactory方法
- InitializingBean的afterPropertiesSet(),如果实现了该接口,则执行其afterPropertiesSet()方法
- Bean定义文件中定义init-method
- DisposableBean的destroy(),在容器关闭时,如果Bean类实现了该接口,则执行它的destroy()方法
- Bean定义文件中定义destroy-method,在容器关闭时,可以在Bean定义文件中使用“destory-method”定义的方法
如果使用ApplicationContext来维护一个Bean的生命周期,则基本上与上边的流程相同,只不过在执行BeanNameAware的setBeanName()后,若有Bean类实现了org.springframework.context.ApplicationContextAware接口,则执行其setApplicationContext()方法,然后再进行BeanPostProcessors的processBeforeInitialization()
实际上,ApplicationContext除了向BeanFactory那样维护容器外,还提供了更加丰富的框架功能,如Bean的消息,事件处理机制等
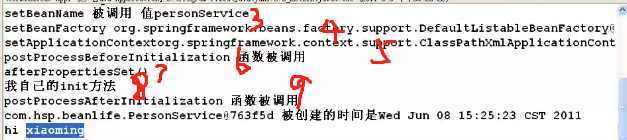
结果展示:

二、BeanFactory 接口和 ApplicationContext 接口有什么区别 ?
开发中基本都在使用ApplicationContext, web项目使用WebApplicationContext ,很少用到BeanFactory
BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("applicationContext.xml")); IHelloService helloService = (IHelloService) beanFactory.getBean("helloService"); helloService.sayHello();
三、Bean的加载方式:
1)使用类构造器实例化(默认无参数)
<bean id="bean1" class="cn.itcast.spring.b_instance.Bean1"></bean>
//下面这段配置的含义:调用Bean2Factory的getBean2方法得到bean2
<bean id="bean2" class="cn.itcast.spring.b_instance.Bean2Factory" factory-method="getBean2"></bean>
//先创建工厂实例bean3Facory,再通过工厂实例创建目标bean实例 <bean id="bean3Factory" class="cn.itcast.spring.b_instance.Bean3Factory"></bean> <bean id="bean3" factory-bean="bean3Factory" factory-method="getBean3"></bean>
1. 使用静态工厂方法创建Bean
使用静态工厂方法创建Bean实例时,class属性也必须指定,但此时class属性并不是指定Bean实例的实现类,而是静态工厂类。因为Spring需要知道是用哪个工厂来创建Bean实例。另外,还需要使用factory-method来指定静态工厂方法名,Spring将调用静态工厂方法(可能包含一组参数),来返回一个Bean实例,一旦获得了指定Bean实例,Spring后面的处理步骤与采用普通方法创建Bean实例则完全一样。需要注意的是,当使用静态工厂方法来创建Bean时,这个factory-method必须要是静态的。这段阐述听上去有点晕,话不多说,上代码:
先定义一个接口,静态方法产生的将是该接口的实例:
public interface Animal {
public void sayHello();
}
下面是接口的两个实现类:

public class Cat implements Animal {
private String msg;
//依赖注入时必须的setter方法
public void setMsg(String msg){
this.msg = msg;
}
@Override
public void sayHello(){
System.out.println(msg + ",喵~喵~");
}
}
public class Dog implements Animal {
private String msg;
//依赖注入时必须的setter方法
public void setMsg(String msg){
this.msg = msg;
}
@Override
public void sayHello(){
System.out.println(msg + ",旺~旺~");
}
}
下面的AnimalFactory工厂中包含了一个getAnimal的静态方法,该方法将根据传入的参数决定创建哪个对象。这是典型的静态工厂设计模式。
public clas AnimalFactory {
public static Animal getAnimal(String type){
if ("cat".equalsIgnoreCase(type)){
return new Cat();
} else {
return new Dog();
}
}
}
如果需要指定Spring使用AnimalFactory来产生Animal对象,则可在Spring配置文件中作如下配置:
<!-- 配置AnimalFactory的getAnimal方法,使之产生Cat -->
<bean id="cat" class="com.abc.AnimalFactory" factory-method="getAnimal">
<!-- 配置静态工厂方法的参数,getAnimal方法将产生Cat类型的对象 -->
<constructor-arg value="cat" />
<!-- 通过setter注入的普通属性 -->
<property name="msg" value="猫猫" />
</bean>
<!-- 配置AnimalFactory的getAnimal方法,使之产生Dog -->
<bean id="dog" class="com.abc.AnimalFactory" factory-method="getAnimal">
<!-- 配置静态工厂方法的参数,getAnimal方法将产生Dog类型的对象 -->
<constructor-arg value="dog" />
<!-- 通过setter注入的普通属性 -->
<property name="msg" value="狗狗" />
</bean>
从上面的配置可以看出:cat和dog两个Bean配置的class和factory-method完全相同,这是因为两个实例都使用同一个静态工厂类、同一个静态工厂方法产生得到的。只是为这个静态工厂方法指定的参数不同,使用<constructor-arg />元素来为静态工厂方法指定参数。
主程序获取cat和dog两个Bean实例的方法不变,同样只需要调用Spring容器的getBean()即可:
public class Test {
public static void main(String args[]){
ApplicationContext context =
new ClassPathXmlApplicationContext("applicationContext.xml");
Animal a1 = context.getBean("cat", Animal.class);
a1.sayHello();
Animal a2 = context.getBean("dog", Animal.class);
a2.sayHello();
}
}
使用静态工厂方法创建实例时必须提供工厂类和产生实例的静态工厂方法。通过静态工厂方法创建实例时需要对Spring配置文件做如下改变;
-
class属性不在是Bean实例的实现类,而是生成Bean实例的静态工厂类
-
使用factory-method指定生产Bean实例的静态工厂方法
-
如果静态工厂方法需要参数,使用<constructor-arg />元素为其配置
当我们指定Spring使用静态工厂方法来创建Bean实例时,Spring将先解析配置文件,并根据配置文件指定的信息,通过反射调用静态工厂类的静态工厂方法,并将该静态工厂方法的返回值作为Bean实例,在这个过程中,Spring不再负责创建Bean实例,Bean实例是由用户提供的静态工厂方法提供的。
2. 使用实例工厂方法创建Bean
实例工厂方法与静态工厂方法只有一点不同:调用静态工厂方法只需要使用工厂类即可,调用实例工厂方法则必须使用工厂实例。所以在Spring配置上也只有一点区别:配置静态工厂方法指定静态工厂类,配置实例工厂方法则指定工厂实例。同样是上面的例子将AnimalFactory修改为:
public clas AnimalFactory {
public Animal getAnimal(String type){ //这里仅仅是去掉了static关键字
if ("cat".equalsIgnoreCase(type)){
return new Cat();
} else {
return new Dog();
}
}
}
Spring文件修改为:
<!-- 先配置工厂类 --> <bean id="animalFactory" class="com.abc.AnimalFactory" /> <!-- 这里使用factory-bean指定实例工厂类对象 --> <bean id="cat" factory-bean="animalFactory" factory-method="getAnimal"> <!-- 同样指定factory-method的参数 --> <constructor-arg value="cat" /> <property name="msg" value="猫猫" /> </bean> <bean id="dog" factory-bean="animalFactory" factory-method="getAnimal"> <constructor-arg value="dog" /> <property name="msg" value="狗狗" /> </bean>
测试类不用修改,输出结果和上面相同。
四、请介绍一下Spring框架中Bean的作用域
singleton
当一个bean的作用域为singleton, 那么Spring IoC容器中只会存在一个共享的bean实例,并且所有对bean的请求,只要id与该bean定义相匹配,则只会返回bean的同一实例。
prototype
Prototype作用域的bean会导致在每次对该bean请求(将其注入到另一个bean中,或者以程序的方式调用容器的getBean() 方法)时都会创建一个新的bean实例。根据经验,对所有有状态的bean应该使用prototype作用域,而对无状态的bean则应该使用 singleton作用域
request
在一次HTTP请求中,一个bean定义对应一个实例;即每次HTTP请求将会有各自的bean实例, 它们依据某个bean定义创建而成。该作用 域仅在基于web的Spring ApplicationContext情形下有效。
session
在一个HTTP Session中,一个bean定义对应一个实例。该作用域仅在基于web的Spring ApplicationContext情形下有效。
global session
在一个全局的HTTP Session中,一个bean定义对应一个实例。典型情况下,仅在使用portlet context的时候有效。该作用域仅在基于 web的Spring ApplicationContext情形下有效。
五、Bean注入属性有哪几种方式?

六、Spring的核心类有哪些,各有什么作用?
BeanFactory:产生一个新的实例,可以实现单例模式
BeanWrapper:提供统一的get及set方法
ApplicationContext:提供框架的实现,包括BeanFactory的所有功能
七、Spring里面如何配置数据库驱动?
com.mchange.v2.c3p0.ComboPooledDataSource”数据源来配置数据库驱动。示例如下:
<!-- 配置数据库数据源 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClassName}"/>
<property name="jdbcUrl" value="${jdbc.url}"/>
<property name="user" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
<!-- 初始化连接大小 -->
<property name="initialPoolSize" value="${initialSize}"/>
<!-- 最小连接池数量 -->
<property name="minPoolSize" value="${minActive}" />
<!-- 连接池最大数量 -->
<property name="maxPoolSize" value="${maxActive}"/>
<property name="autoCommitOnClose" value="true"/>
</bean>
八、Spring里面applicationContext.xml文件能不能改成其他文件名?
ContextLoaderListener是一个ServletContextListener, 它在你的web应用启动的时候初始化。缺省情况下, 它会在WEB-INF/applicationContext.xml文件找Spring的配置。
你可以通过定义一个<context-param>元素名字为”contextConfigLocation”来改变Spring配置文件的 位置。示例如下:
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/xyz.xml</param-value>
</context-param>
</listener-class>
</listener>
九、Spring如何处理线程并发问题?
Spring使用ThreadLocal解决线程安全问题【博客有一节专门对于TreadLocal的分析】
我们知道在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,绝大部分Bean都可以声明为singleton作用域。就是因为Spring对一些Bean(如RequestContextHolder、TransactionSynchronizationManager、LocaleContextHolder等)中非线程安全状态采用ThreadLocal进行处理,让它们也成为线程安全的状态,因为有状态的Bean就可以在多线程中共享了。
ThreadLocal和线程同步机制都是为了解决多线程中相同变量的访问冲突问题。
在同步机制中,通过对象的锁机制保证同一时间只有一个线程访问变量。这时该变量是多个线程共享的,使用同步机制要求程序慎密地分析什么时候对变量进行读写,什么时候需要锁定某个对象,什么时候释放对象锁等繁杂的问题,程序设计和编写难度相对较大。
而ThreadLocal则从另一个角度来解决多线程的并发访问。ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。
由于ThreadLocal中可以持有任何类型的对象,低版本JDK所提供的get()返回的是Object对象,需要强制类型转换。但JDK5.0通过泛型很好的解决了这个问题,在一定程度地简化ThreadLocal的使用。
概括起来说,对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
十、为什么要有事物传播行为?
十一、介绍一下Spring的事物管理
事务就是对一系列的数据库操作(比如插入多条数据)进行统一的提交或回滚操作,如果插入成功,那么一起成功,如果中间有一条出现异常,那么回滚之前的所有操作。这样可以防止出现脏数据,防止数据库数据出现问题。
开发中为了避免这种情况一般都会进行事务管理。Spring中也有自己的事务管理机制,一般是使用TransactionMananger进行管 理,可以通过Spring的注入来完成此功能。spring提供了几个关于事务处理的类:
TransactionDefinition //事务属性定义
TranscationStatus //代表了当前的事务,可以提交,回滚。
PlatformTransactionManager这个是spring提供的用于管理事务的基础接口,其下有一个实现的抽象类 AbstractPlatformTransactionManager,我们使用的事务管理类例如 DataSourceTransactionManager等都是这个类的子类。
一般事务定义步骤:
TransactionDefinition td =newTransactionDefinition(); TransactionStatus ts = transactionManager.getTransaction(td); try{ //do sth transactionManager.commit(ts); }catch(Exception e){ transactionManager.rollback(ts); }
编程式主要使用transactionTemplate。省略了部分的提交,回滚,一系列的事务对象定义,需注入事务管理对象.【这里使用了模板模式】
void add(){ transactionTemplate.execute(newTransactionCallback(){ pulic Object doInTransaction(TransactionStatus ts){ //do sth } } }
使用TransactionProxyFactoryBean:PROPAGATION_REQUIRED PROPAGATION_REQUIRED PROPAGATION_REQUIRED,readOnly
围绕Poxy的动态代理 能够自动的提交和回滚事务
org.springframework.transaction.interceptor.TransactionProxyFactoryBean
PROPAGATION_REQUIRED–支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
PROPAGATION_SUPPORTS–支持当前事务,如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY–支持当前事务,如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW–新建事务,如果当前存在事务,把当前事务挂起。
PROPAGATION_NOT_SUPPORTED–以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
PROPAGATION_NEVER–以非事务方式执行,如果当前存在事务,则抛出异常。
PROPAGATION_NESTED–如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与 PROPAGATION_REQUIRED类似的操作。

