

Redis基础篇 Redis数据结构
String
1、概念:string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
2、实例:
redis 127.0.0.1:6379> SET name "runoob" OK redis 127.0.0.1:6379> GET name "runoob"
Hash
1、概念:hash 是一个键值(key=>value)对集合。hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
2、实例:
redis> HMSET myhash field1 "Hello" field2 "World" "OK" redis> HGET myhash field1 "Hello" redis> HGET myhash field2 "World"
List
1、概念:list是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部或者尾部。
2、实例:
redis 127.0.0.1:6379> lpush runoob redis (integer) 1 redis 127.0.0.1:6379> lpush runoob mongodb (integer) 2 redis 127.0.0.1:6379> lpush runoob rabitmq (integer) 3 redis 127.0.0.1:6379> lrange runoob 0 10 1) "rabitmq" 2) "mongodb" 3) "redis"
Set
1、概念:Redis的Set是string类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
2、实例:
redis 127.0.0.1:6379> sadd runoob redis (integer) 1 redis 127.0.0.1:6379> sadd runoob mongodb (integer) 1 redis 127.0.0.1:6379> sadd runoob rabitmq (integer) 1 redis 127.0.0.1:6379> sadd runoob rabitmq (integer) 0 redis 127.0.0.1:6379> smembers runoob 1) "redis" 2) "rabitmq" 3) "mongodb"
zset
1、zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。
2、实例:
redis 127.0.0.1:6379> zadd runoob 0 redis (integer) 1 redis 127.0.0.1:6379> zadd runoob 0 mongodb (integer) 1 redis 127.0.0.1:6379> zadd runoob 0 rabitmq (integer) 1 redis 127.0.0.1:6379> zadd runoob 0 rabitmq (integer) 0 redis 127.0.0.1:6379> > ZRANGEBYSCORE runoob 0 1000 1) "mongodb" 2) "rabitmq" 3) "redis" ``
Redis基础命令
用于Key的命令
SET : 为Key设置值,实例:SET runoobkey redis
EXISTS : 查询Key是否存在,存在返回1,否则返回0。实例:EXISTS runoob-new-key
PPTL : 以毫秒为单位返回 key 的剩余过期时间。实例:PTTL KEY_NAME
TTL : 秒为单位返回 key 的剩余过期时间。 实例: TTL KEY_NAME
用于字符串的命令
SET : 设置指定key的值。实例:SET KEY_NAME value
GET : 获取指定key的值。实例:GET KEY_NAME
INCR : 把key中存储的数字值增1。实例:INCR KEY_NAME
DECR : 把key中存储的数字值减1。实例:DECR KEY_NAME
用于Hash表的命令
HGET : 获取hash表中的指定字段的值。实例:HGET KEY_NAME FIELD_NAME
HGETALL : 获取hash表中所有字段和 对应的值。实例:HGETALL KEY_NAME
HKEYS : 获取hash表中所有字段。实例:HKEYS KEY_NAME
用于List集合的命令
LRANGE : 获取集合指定范围内的元素。实例:LRANGE key start stop 获取下标从start到stop的元素
Redis进阶篇 Redis进阶指令篇
Scan
1、SCAN命令是增量的循环,每次调用只会返回一小部分的元素。所以不会有KEYS命令的坑。 SCAN命令返回的是一个游标,从0开始遍历,到0结束遍历。scan也有如下一些特设:
(1)查询复杂度为O(n),通过游标分步进行,不会阻塞线程
(2)提供limit参数,控制每次返回结果的最大条数。这里值得注意的是,limit只是一个提示,返回的结果可多可少
(3)同keys一样,它也提供模式匹配功能
(4)返回的结果可能会重复,需要客户端去重
(5)遍历过程中,如果有数据修改,改动后的数据不一定能遍历到
(6)单次返回结果是空的并不意味着遍历结束,而是看返回的游标值是否为0
2、使用实例:
(1)先插入10个key
(2)然后使用Scan进行扫描:
这时候返回key3、key5,返回的游标为744
(3)使用744游标继续查询:
返回key1、key4,返回游标为268。同理,继续查询可以查询出匹配key*的所有key,直到游标为0为止,结果如下图:
HyperLogLog
1、概念:
HyperLogLog这种数据结构用于解决去重统计问题,它提供了不精确的去重计数方案,标准误差在0.81%。
2、使用方法:
(1)pfadd:增加计数,pfadd KEY_NAME id
(2)pfcount:获取计数,pfcount KEY_NAME
(3)pfmerge:用于将多个pf计数值累加在一起形成一个新的pf值
3、原理:较为复杂,后续补充
Redis管道
1、概念:指的是客户端允许将多个请求依次发给服务器,过程中而不需要等待请求的回复,在最后再一并读取结果即可。主要作用在于提高吞吐量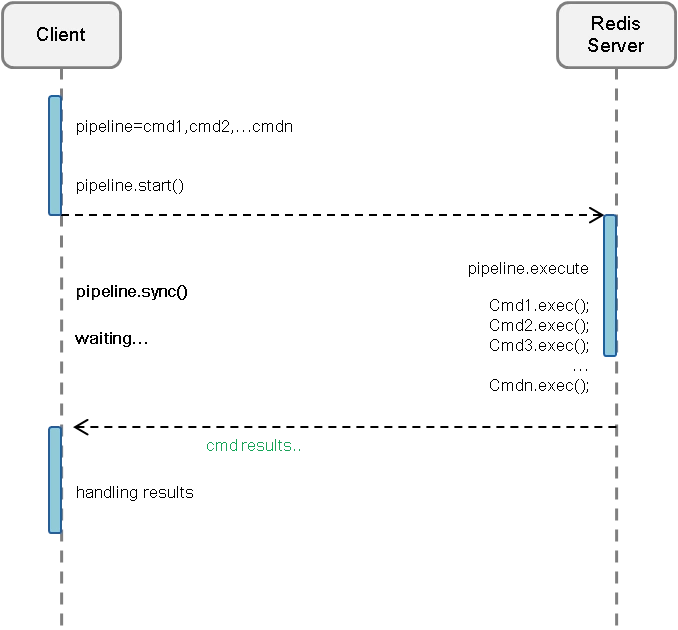
上图中可以看出,所有的请求合并为一次IO,除了时延可以降低之外,还能大幅度提升系统吞吐量。
2、实例:
package com.redis;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.Pipeline;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 管道处理实例
* @author huangy on 2018/8/5
*/
public class Piple {
private static Logger logger = LoggerFactory.getLogger(Piple.class);
private static JedisPool jedisPool;
// 总共有多少个并发任务
private static final int taskCount = 50;
// 管道大小
private static final int batchSize = 10;
// 每个任务处理的命令数
private static final int cmdCount = 1000;
// redis服务地址
private static final String host = "127.0.0.1";
// 端口
private static final int port = 6379;
// 是否使用管道
private static final boolean usePipeline = true;
// 保存执行结果
private static List<Object> results = new ArrayList<>(cmdCount);
private static void init() {
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxIdle(100);
poolConfig.setTestOnBorrow(false);
poolConfig.setTestOnReturn(false);
jedisPool = new JedisPool(poolConfig, host, port);
}
public static void main(String[] args) throws InterruptedException {
// 初始化redis
init();
long beginTime = System.currentTimeMillis();
// 使用多线程执行
ExecutorService executor = Executors.newCachedThreadPool();
// 使用CountDownLatch保证所有任务都执行完
CountDownLatch latch = new CountDownLatch(taskCount);
for (int i = 0; i < taskCount; i++) {
executor.submit(new DemoTask(i, latch));
}
latch.await();
executor.shutdownNow();
long endTime = System.currentTimeMillis();
// 耗时
logger.info("execution cost time(s)={}", (endTime - beginTime) / 1000.0);
// 所有结果
logger.info("results, size={}, all={}", results.size(), results);
}
private static Jedis get() {
return jedisPool.getResource();
}
private static class DemoTask implements Runnable {
private int id;
private CountDownLatch latch;
private DemoTask(int id, CountDownLatch latch) {
this.id = id;
this.latch = latch;
}
public void run() {
logger.info("Task[{}] start.", id);
try {
if (usePipeline) {
runWithPipeline();
} else {
runWithNonPipeline();
}
} finally {
latch.countDown();
}
logger.info("Task[{}] end.", id);
}
/**
* 不使用管道处理redis命令
*/
private void runWithNonPipeline() {
// 总共处理cmdCount个
for (int i = 0; i < cmdCount; i++) {
Jedis jedis = get();
try {
jedis.set(key(i), UUID.randomUUID().toString());
} finally {
if (jedis != null) {
jedisPool.returnResource(jedis);
}
}
if (i % batchSize == 0) {
logger.info("Task[{}] process -- {}", id, i);
}
}
}
/**
* 使用管道处理redis命令
* 总共处理cmdCount个redis命令,每次处理batchSize个
*/
private void runWithPipeline() {
for (int i = 0; i < cmdCount;) {
Jedis jedis = get();
try {
Pipeline pipeline = jedis.pipelined();
int j;
for (j = 0; j < batchSize; j++) {
if (i + j < cmdCount) {
pipeline.set(key(i + j), UUID.randomUUID().toString());
} else {
break;
}
}
// pipeline.sync();
// 查看结果,使用syncAndReturnAll
List<Object> tem = pipeline.syncAndReturnAll();
logger.info("Task thread id={} pipeline, cmd end={}, result size={}", id, i + j, tem.size());
results.addAll(tem);
i += j;
} finally {
if (jedis != null) {
jedisPool.returnResource(jedis);
}
}
}
}
private String key(int i) {
return i + "";
}
}
}
上述实例使用50个线程进行处理,每个线程分别处理了1000个redis命令(set),在不使用管道的情况下,耗时大约5秒;使用管道的情况下,耗时大约2秒。
3、缺点:
(1)pipeline机制可以优化吞吐量,但无法提供原子性/事务保障,而这个可以通过Redis-Multi等命令实现。
(2)部分读写操作存在相关依赖,无法使用pipeline实现
异步队列
1、概念:redis实现异步队列,一般使用list结构作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
2、sleep优化:
(1)原因:客户端是通过队列的pop操作来获取消息,然后进行处理,处理完了再接着获得消息。可是如果队列空了,客户端就会不停的pop,这样的操作不能获取数据,并且拉高了客户端的CPU,redis的QPS也会拉高,降低redis的查询效率。
(2)使用sleep解决这个问题,让线程睡一会,比如说1s。可以让客户端的CPU降下来。
3、blpop/brpop 优化:
(1)原因:sleep的方法可以优化,但是睡眠会导致消息延迟增大。
(2)使用blpop(阻塞读):阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。
(3)PS:blpop指队列左边出数据。brpop指队列右边出数据
(4)注意点:当线程一直sleep,服务器一般会断开连接,这时候blpop会抛出异常,所以在编写客户端消费者的时候要小心,注意捕获异常,还要重试。
4、延时队列:
(1)延时队列可以通过redis的zset(有序列表)来实现。
(2)简单的代码实例:
/**
* 延时队列案例
* @author huangy on 2018/8/26
*/
@Component
public class QueueDemo {
private static final Logger LOGGER = LoggerFactory.getLogger(QueueDemo.class);
@Resource
private Jedis jedis;
private static final String QUEUE_KEY = "queueKey";
/**
* 将任务扔到延时队列中
* 使用时间作为score
* @param msg 任务(一般使用json格式的字符串)
*/
public void delay(String msg) {
jedis.zadd(QUEUE_KEY, System.currentTimeMillis() + 5000, msg);
}
/**
* 从延时队列中获取任务,利用时间范围作为score的范围
* zrangeByScore :返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员
*/
public void loop() {
while (!Thread.interrupted()) {
Set<String> values = jedis.zrangeByScore(QUEUE_KEY,
0, 577742424, 0, 1);
if (values.isEmpty()) {
try {
Thread.sleep(500);
} catch (Exception e) {
LOGGER.error("loop sleep fail", e);
break;
}
continue;
}
String s = values.iterator().next();
// 利用zrem判断是否拿到任务
if (jedis.zrem(QUEUE_KEY, s) > 0) {
// 拿到这个任务了,进行处理
LOGGER.info("loop msg, msg={}", s);
}
}
}
}
Redis集群篇 一致性哈希
普通的HASH算法的缺点:
在使用Redis集群的时候,如果直接使用HASH算法 hash(key) % length,当缓存服务器变化时,length字段变化,导致所有缓存的数据需要重新进行HASH运算,才能使用。而这段时间如果访问量上升了,容易引起服务器雪崩。因此,引入了一致性哈希
一致性哈希:
通过对2^32取模的方式,保证了在增加/删除缓存服务器的情况下,其他缓存服务器的缓存仍然可用,从而不引起雪崩问题。
Redis Cluster(Redis官方集群方案)
Redis Cluster是一种服务器Sharding技术,3.0版本开始正式提供。Redis Cluster中,Sharding采用slot(槽)的概念,一共分成16384个槽,这有点儿类似前面讲的pre sharding思路。对于每个进入Redis的键值对,根据key进行散列,分配到这16384个slot中的某一个中。使用的hash算法也比较简单,就是CRC16后16384取模。Redis集群中的每个node(节点)负责分摊这16384个slot中的一部分,也就是说,每个slot都对应一个node负责处理。当动态添加或减少node节点时,需要将16384个槽做个再分配,槽中的键值也要迁移。当然,这一过程,在目前实现中,还处于半自动状态,需要人工介入。Redis集群,要保证16384个槽对应的node都正常工作,如果某个node发生故障,那它负责的slots也就失效,整个集群将不能工作。为了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n个slave从节点。这时,如果主节点失效,Redis Cluster会根据选举算法从slave节点中选择一个上升为主节点,整个集群继续对外提供服务。这非常类似前篇文章提到的Redis Sharding场景下服务器节点通过Sentinel监控架构成主从结构,只是Redis Cluster本身提供了故障转移容错的能力。
Redis Cluster的新节点识别能力、故障判断及故障转移能力是通过集群中的每个node都在和其它nodes进行通信,这被称为集群总线(cluster bus)。它们使用特殊的端口号,即对外服务端口号加10000。例如如果某个node的端口号是6379,那么它与其它nodes通信的端口号是16379。nodes之间的通信采用特殊的二进制协议。
对客户端来说,整个cluster被看做是一个整体,客户端可以连接任意一个node进行操作,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node,这有点儿像浏览器页面的302 redirect跳转。
Redis Cluster是Redis 3.0以后才正式推出,时间较晚,目前能证明在大规模生产环境下成功的案例还不是很多,需要时间检验。
Redis Sharding集群(客户端分片)
Redis 3正式推出了官方集群技术,解决了多Redis实例协同服务问题。Redis Cluster可以说是服务端Sharding分片技术的体现,即将键值按照一定算法合理分配到各个实例分片上,同时各个实例节点协调沟通,共同对外承担一致服务。
多Redis实例服务,比单Redis实例要复杂的多,这涉及到定位、协同、容错、扩容等技术难题。这里,我们介绍一种轻量级的客户端Redis Sharding技术。
Redis Sharding可以说是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。其主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。这样,客户端就知道该向哪个Redis节点操作数据。Sharding架构如图:

庆幸的是,java redis客户端驱动jedis,已支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool。
Jedis的Redis Sharding实现具有如下特点:
1、采用一致性哈希算法(consistent hashing),将key和节点name同时hashing,然后进行映射匹配,采用的算法是MURMUR_HASH。采用一致性哈希而不是采用简单类似哈希求模映射的主要原因是当增加或减少节点时,不会产生由于重新匹配造成的rehashing。一致性哈希只影响相邻节点key分配,影响量小。
2.为了避免一致性哈希只影响相邻节点造成节点分配压力,ShardedJedis会对每个Redis节点根据名字(没有,Jedis会赋予缺省名字)会虚拟化出160个虚拟节点进行散列。根据权重weight,也可虚拟化出160倍数的虚拟节点。用虚拟节点做映射匹配,可以在增加或减少Redis节点时,key在各Redis节点移动再分配更均匀,而不是只有相邻节点受影响。
3.ShardedJedis支持keyTagPattern模式,即抽取key的一部分keyTag做sharding,这样通过合理命名key,可以将一组相关联的key放入同一个Redis节点,这在避免跨节点访问相关数据时很重要。
扩容问题:
1、Redis Sharding采用客户端Sharding方式,服务端Redis还是一个个相对独立的Redis实例节点,没有做任何变动。同时,我们也不需要增加额外的中间处理组件,这是一种非常轻量、灵活的Redis多实例集群方法。Redis Sharding采用客户端Sharding方式,服务端Redis还是一个个相对独立的Redis实例节点,没有做任何变动。同时,我们也不需要增加额外的中间处理组件,这是一种非常轻量、灵活的Redis多实例集群方法。当然,Redis Sharding这种轻量灵活方式必然在集群其它能力方面做出妥协。比如扩容,当想要增加Redis节点时,尽管采用一致性哈希,毕竟还是会有key匹配不到而丢失,这时需要键值迁移。
2、作为轻量级客户端sharding,处理Redis键值迁移是不现实的,这就要求应用层面允许Redis中数据丢失或从后端数据库重新加载数据。但有些时候,击穿缓存层,直接访问数据库层,会对系统访问造成很大压力。有没有其它手段改善这种情况?
3、Redis作者给出了一个比较讨巧的办法–presharding,即预先根据系统规模尽量部署好多个Redis实例,这些实例占用系统资源很小,一台物理机可部署多个,让他们都参与sharding,当需要扩容时,选中一个实例作为主节点,新加入的Redis节点作为从节点进行数据复制。数据同步后,修改sharding配置,让指向原实例的Shard指向新机器上扩容后的Redis节点,同时调整新Redis节点为主节点,原实例可不再使用。这样,我们的架构模式变成一个Redis节点切片包含一个主Redis和一个备Redis。在主Redis宕机时,备Redis接管过来,上升为主Redis,继续提供服务。主备共同组成一个Redis节点,通过自动故障转移,保证了节点的高可用性。则Sharding架构演变成:

Redis Sentinel提供了主备模式下Redis监控、故障转移功能达到系统的高可用性。
高访问量下,即使采用Sharding分片,一个单独节点还是承担了很大的访问压力,这时我们还需要进一步分解。通常情况下,应用访问Redis读操作量和写操作量差异很大,读常常是写的数倍,这时我们可以将读写分离,而且读提供更多的实例数。可以利用主从模式实现读写分离,主负责写,从负责只读,同时一主挂多个从。在Sentinel监控下,还可以保障节点故障的自动监测。
Redis主从同步原理
和MySQL主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,下图为级联结构。
Redis主从结构
Redis主从复制可以根据是否是全量分为全量同步和增量同步。
1、全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
1)从服务器连接主服务器,发送SYNC命令;
2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
Redis全量同步过程
完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
2、增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
3、Redis主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
4、其他:Redis 2.8以后提供了PSYNC优化了断线重连的效率
http://blog.csdn.net/sk199048...
Redis缓存篇 缓存雪崩
案例情景
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。并且如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象
解决方法
1、使用互斥锁(这里使用redis的setnx实现分布式锁):
只有获取锁,才能去访问数据库,加载数据,保证同一时刻只有一个请求访问数据库,避免数据库崩溃。但这样子可能造成请求延时比较久的问题。
2、让缓存过期时间不那么集中:
比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件
3、做二级缓存
A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2。A1缓存失效时间设置为短期,A2设置为长期。这个在业务追求数据一致性要求不高的情况下,可以使用。
4、缓存永远不过期
这里的“永远不过期”包含两层意思:
(1) 从缓存上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期.
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。

缓存穿透
案例情景
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透
解决方法
使用Bloom filter(布隆过滤器)。当用户查询某个row时,可以先通过内存中的布隆过滤器过滤掉大量不存在的row请求,然后再到数据库进行查询。

