

1、State概念理解
在Flink中,按照基本类型,对State做了以下两类的划分:Keyed State, Operator State。
Keyed State:和Key有关的状态类型,它只能被基于KeyedStream之上的操作,方法所使用。我们可以从逻辑上理解这种状态是一个并行度操作实例和一种Key的对应, <parallel-operator-instance, key>。
Operator State:(或者non-keyed state),它是和Key无关的一种状态类型。相应地我们从逻辑上去理解这个概念,它相当于一个并行度实例,对应一份状态数据。因为这里没有涉及Key的概念,所以在并行度(扩/缩容)发生变化的时候,这里会有状态数据的重分布的处理。
概念理解如下图:

1、如果一个job没有设置checkpoint,那么state默认是是保存在java的堆内存中,这样会导致task失败后,state存在丢失现象;
2、checkpoint在一个job中负责一份全局的状态快照,里边包含了所有的task和operator状态;
3、task指的是flink中执行的基本单位,operator指的是算子操作;
4、state可以被记录,也可以在失败的时候被恢复;
5、state存在两种,一种是 key state, 一种是 operator state;
1.1 Keyed State 应用示例:

关键点总结:
1、上述State对象,仅仅是用来与状态进行交互,包括状态的更新,状态删除,状态清空等。
2、真正的状态值可能存在内存、磁盘、或者其他分布式存储系统中。
代码示例:
public class StateManager extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> { /** * 操作 state 的句柄 * @param longLongTuple2 * @param collector * @throws Exception */ private transient ValueState<Tuple2<Long, Long>> sum; @Override public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception { //获取state值 Tuple2<Long, Long> currentSum = sum.value(); currentSum.f0 = currentSum.f0 + 1; currentSum.f1 = currentSum.f1 + value.f1; //操作state更新 sum.update(currentSum); //输出flatMap的算子结果 if(currentSum.f0 >= 2) { out.collect(new Tuple2<Long, Long>(value.f0, currentSum.f1/currentSum.f0)); } } @Override public void open(Configuration parameters) throws Exception { ValueStateDescriptor<Tuple2<Long, Long>> descriptor = new ValueStateDescriptor<Tuple2<Long, Long>>( "average", //状态的名称 TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), //状态的类型 Tuple2.of(0L, 0L) //状态的初始默认值 ); sum = getRuntimeContext().getState(descriptor); } }
1.2 Operator State 应用示例:

2、checkpoint的应用示例
基于状态的容错:
1、依靠checkpoint机制;
2、保证exactly-once;
3、只能保证flink系统内的exactly-once;
4、对source和sink需要依赖外部的组建一同保证;
state的存入:
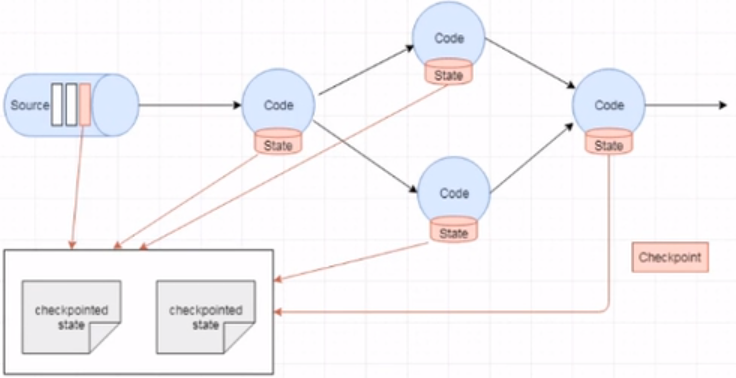
state恢复:
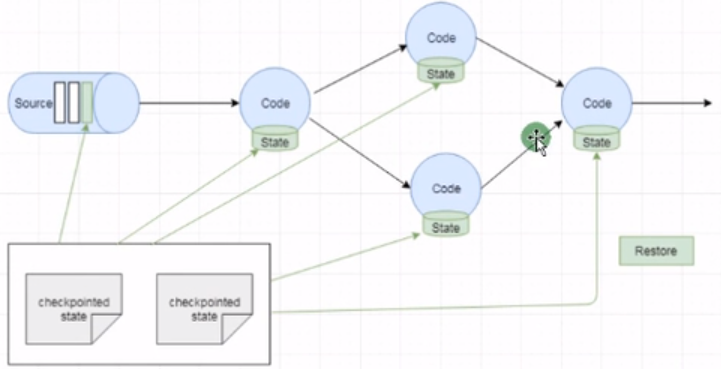
checkpoint概念:

checkpoint的配置:
1、默认是disable,需要手动开启;
2、checkpoint开启后,默认的 checkpointMode 是Exactly-once;
3、checkpointMode有两种,一种是 Exactly-once, 另一种是 At-least-once;
4、Exactly-once大多数程序是适合的, At-least-once可能用在某些延迟超低的应用程序(始终延迟几ms)
代码配置如下:
//获取flink的运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】 env.enableCheckpointing(1000); // 高级选项: // 设置模式为exactly-once (这是默认值) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); // 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】 env.getCheckpointConfig().setCheckpointTimeout(60000); // 同一时间只允许进行一个检查点 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】 //ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint //ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
3、State Backend的应用示例

三种保存方式介绍:

代码示例:
//设置statebackend //env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop100:9000/flink/checkpoints",true));


