
机器学*中的交叉熵
信息量
一件事发生的概率越*,其蕴含的信息量就越少,反之,若发生的几率越小,则蕴含的信息量就越*。例如,“太阳从东方升起”:这件事发生概率极*,*家都*以为常,所以不觉得有什么不妥的地方,因此蕴含信息量很小。但“国足踢入世界杯”:这就蕴含的信息量很*了,因为这件事的发生概率很小。若某事的发生概率为,则信息量的计算公式为:
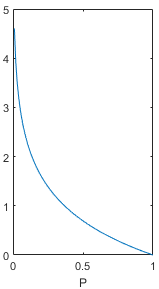
其中,log表示自然对数,底数为(也有资料使用底数为2的对数)。公式中,值落在0到1之间,画出上面函数在为时的取值,图像如下。在概率值趋向于0时,信息量趋向于正无穷,在概率值趋向于1时,信息量趋向于0,这个函数能够满足信息量的基本想法。
信息熵
信息熵又称熵,熵可以表达数据的信息量*小。其本质是所有信息量的期望。期望是试验中每次可能结果的概率乘以其结果的总和。熵的公式如下:
相对熵(KL散度)
如果我们对于同一个随机变量 有两个单独的概率分布 和 ,我们可以使用 KL 散度来衡量这两个分布的差异。相对熵的基本定义是:如果用来描述目标问题,而不是用来描述目标问题,得到的信息增量。
在机器学*中,往往用来表示样本的真实分布,用来表示模型所预测的分布,我们训练的目的就是让 和 的差异越来越小。
KL散度的计算公式如下:
其中为事件的所有可能性。的值越小,表示分布和分布越接近.
交叉熵
我们分解相对熵的公式:
为之前的信息熵,后面那一坨其实就是交叉熵了,所以可以看到:KL散度 = 交叉熵 - 信息熵。
所以交叉熵的公式如下:
从信息熵的公式我们知道,对于同一个数据集,其信息熵是不变的,所以信息熵可以看作一个常数,因此当KL散度最小时,也即是交叉熵最小时。所以在多分类任务中,KL散度(相对熵)和交叉熵是等价的,我们也就可以用交叉熵来当作损失函数。
(欢迎转载,转载请注明出处。文中如有错误,还请指出。)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人