hive的中的sql的执行顺序。
今天在测试在写hive sql的时候注意到在进行查询的时候我们把order by放在后面,前面如果没有这个字段,则执行报错。
他就会报下面的错误。其实这个时候我们就想着是不是哪里写错了。但是仔细一看。好像并没有错误。
这个时候我们就可能会想是不是因为在hive当中语句的执行顺序有问题。于是我在前面select的后面加上order by 之后的字段:
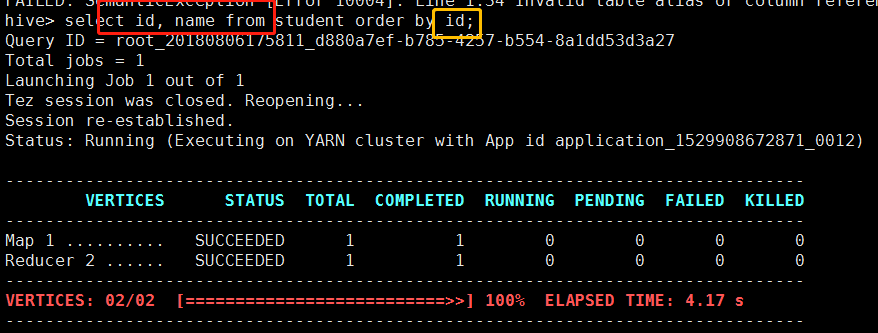
果然是加上之后,执行完全没有问题。这个时候我们就来总结一下hive语句的执行顺序。
在hive的执行语句当中的执行查询的顺序:
这是一条sql:
select … from … where … group by … having … order by …
执行顺序:
from … where … select … group by … having … order by …
其实总结hive的执行顺序也是总结mapreduce的执行顺序:
MR程序的执行顺序:
map阶段:
1.执行from加载,进行表的查找与加载
2.执行where过滤,进行条件过滤与筛选
3.执行select查询:进行输出项的筛选
4.执行group by分组:描述了分组后需要计算的函数
5.map端文件合并:map端本地溢出写文件的合并操作,每个map最终形成一个临时文件。 然后按列映射到对应的reduceReduce阶段:
Reduce阶段:
1.group by:对map端发送过来的数据进行分组并进行计算。
2.select:最后过滤列用于输出结果
3.limit排序后进行结果输出到HDFS文件
所以通过上面的例子我们可以看到,在进行selectt之后我们会形成一张表,在这张表当中做分组排序这些操作。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号