关于通过flink 接入带ssl验证的kafka数据的相关问题总结。
场景描述:之前是做kafka不是通过ssl验证的方式进行接入的,所以就是正常的接受数据。发现我们通过aws服务器去访问阿里云服务器上的kafka的时候,我们服务器要把全部的网关
开放给阿里云服务器的kafka这样的话数据就很不安全。所以就从阿里买了kafka服务器这样就能通过公网去访问服务器,然后带验证的kafka集群。
下面是flink连接kafka不用验证的代码:
不用验证的kafka,flink 读取数据
public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(500L, CheckpointingMode.EXACTLY_ONCE); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "IP:9093"); properties.setProperty("group.id", "tests-consumer-ssgroup20200922"); properties.setProperty("auto.offset.reset", "latest"); System.out.println("11111111111"); FlinkKafkaConsumer010<String> myConsumer = new FlinkKafkaConsumer010("binlog", new SimpleStringSchema(), properties); DataStream<String> keyedStream = env.addSource(myConsumer).setParallelism(1); System.out.println("2222222222222"); System.out.println("3333333333333"); keyedStream.addSink(new MysqlSink()).setParallelism(1).name("数据插入mysql").disableChaining(); env.execute("Flink Streaming Java binlog data"); }
需要验证的kafka,flink读取数据
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(500L, CheckpointingMode.EXACTLY_ONCE);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
Properties props = new Properties();
//设置接入点,请通过控制台获取对应Topic的接入点
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:9093");
//设置SSL根证书的路径,请记得将XXX修改为自己的路径
//与sasl路径类似,该文件也不能被打包到jar中
props.put(SslConfigs.SSL_TRUSTSTORE_LOCATION_CONFIG, "/home/hadoop/kafka.client.truststore.jks");
//根证书store的密码,保持不变
props.put(SslConfigs.SSL_TRUSTSTORE_PASSWORD_CONFIG, "KafkaOnsClient");
//接入协议,目前支持使用SASL_SSL协议接入
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SASL_SSL");
//SASL鉴权方式,保持不变
props.put(SaslConfigs.SASL_MECHANISM, "PLAIN");
//两次poll之间的最大允许间隔
//可更加实际拉去数据和客户的版本等设置此值,默认30s
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 30000);
//设置单次拉取的量,走公网访问时,该参数会有较大影响
props.put(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, 32000);
props.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, 32000);
//每次poll的最大数量
//注意该值不要改得太大,如果poll太多数据,而不能在下次poll之前消费完,则会触发一次负载均衡,产生卡顿
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 30);
//消息的反序列化方式
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
//当前消费实例所属的消费组,请在控制台申请之后填写
//属于同一个组的消费实例,会负载消费消息
props.put(ConsumerConfig.GROUP_ID_CONFIG, "bi-binlog");
//hostname校验改成空
props.put(SslConfigs.SSL_ENDPOINT_IDENTIFICATION_ALGORITHM_CONFIG, "");
//props.put("auto.offset.reset", "earliest");
props.put("sasl.jaas.config",
"org.apache.kafka.common.security.scram.ScramLoginModule required username='username' password='password';"); //这里的分号一定要注意
FlinkKafkaConsumer010<String> myConsumer = new FlinkKafkaConsumer010("binlog", new SimpleStringSchema(), props);
DataStream<String> keyedStream = env.addSource(myConsumer).setParallelism(1);
System.out.println("2222222222222");
System.out.println("3333333333333");
// System.out.println(keyedStream.print());
keyedStream.addSink(new MysqlSink()).setParallelism(1).name("数据插入mysql").disableChaining();
// keyedStream.addSink(new S3Sink()).setParallelism(2).name("数据插入s3");
env.execute("Flink Streaming Java binlog data");
}
因为kafka是要经过ssl验证的,因为我们这里是使用的阿里的kafka所以他有一个验证文件kafka.client.truststore.jks,这个文件是kafka的验证文件。必须放在服务器的本地。他不能通过读取hdfs上的文件。
所以在这里一定要注意将这个文件放在你flink 集群的各个节点上面都放一份。要不然他就会报下面的错误。

flink的相关环境bubu部署好之后就将代码打包提交到服务器上。提交的命令如下:
flink run -m yarn-cluster -yjm 1024 -ytm 1024 -c WordCount /mnt/flinkjar/mysqlflink.jar
我们的代码是提交到yarn上面去的,这里给jobmanager和taskmanager各自分配了一个G的内存。
然后我将代码提交之后就开始报错报错的内容如下:
2020-09-27 11:35:40,927 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint
- Shutting YarnJobClusterEntrypoint down with application status FAILED.
Diagnostics java.lang.NoSuchMethodError:
org.apache.flink.configuration.ConfigOptions$OptionBuilder.stringType()Lorg/apache/flink/configuration/ConfigOptions$TypedConfigOptionBuilder; at org.apache.flink.yarn.configuration.YarnConfigOptions.<clinit>(YarnConfigOptions.java:214) at org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint.getRPCPortRange(YarnJobClusterEntrypoint.java:63) at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.initializeServices(ClusterEntrypoint.java:246) at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runCluster(ClusterEntrypoint.java:202) at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.lambda$startCluster$0(ClusterEntrypoint.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1844) at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:163) at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runClusterEntrypoint(ClusterEntrypoint.java:501) at org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint.main(YarnJobClusterEntrypoint.java:119) . 2020-09-27 11:35:40,937 ERROR org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Could not start cluster entrypoint YarnJobClusterEntrypoint. org.apache.flink.runtime.entrypoint.ClusterEntrypointException: Failed to initialize the cluster entrypoint YarnJobClusterEntrypoint. at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:182) at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runClusterEntrypoint(ClusterEntrypoint.java:501) at org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint.main(Y
看到这里的错误搜索了半天也没有。也没找到答案。最后发现我们新做的emr集群当中的flink的版本是1.10.0但是原来那个emr集群当中的版本是1.9.0。然后去找pom文件将版本修改正确
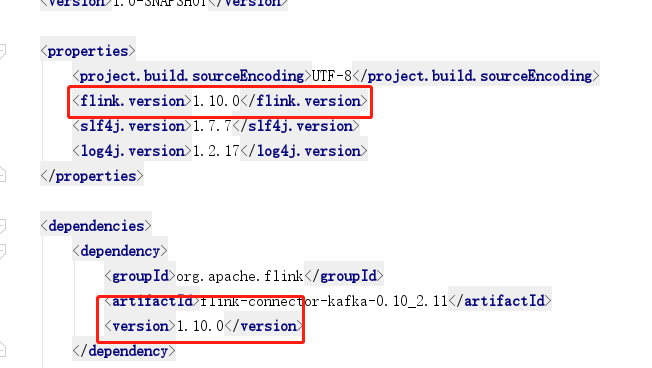
然后执行一下代码发现可以了,至此问题得到解决了。

从这个错误当中可以看出遇到 NoSuchMethodError 一般都是出现了组件的版本和代码的版本不同造成的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号