关于flink 程序提交到yarn上面运行的相关操作和创建checkpoint和savepoint的相关操作
最近公司在做实时的东西,我们是采用的是消费kafka的数据 然后将kafka的数据接入到MySQL 数据库然后做一些简单的统计计算,伪实时的展示数据(10分钟进行一次)
(情景描述 我们公司用的是aws的服务器。所以flink 集群当中的服务有很多台)
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
问题(1)通过命令行去查看flink作业的id 使用命令 flink list 他就报下面的错误。
org.apache.flink.client.deployment.ClusterRetrieveException: Couldn't retrieve standalone cluster at org.apache.flink.client.deployment.StandaloneClusterDescriptor.retrieve(StandaloneClusterDescriptor.java:51) at org.apache.flink.client.deployment.StandaloneClusterDescriptor.retrieve(StandaloneClusterDescriptor.java:31) at org.apache.flink.client.cli.CliFrontend.runClusterAction(CliFrontend.java:942) at org.apache.flink.client.cli.CliFrontend.list(CliFrontend.java:413) at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1013) at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1083) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1844) at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1083) Caused by: org.apache.flink.util.ConfigurationException: cuoConfig parameter 'Key: 'jobmanager.rpc.address' , default: null (fallback keys: [])' is missing (hostname/address of JobManager to connect to). at org.apache.flink.runtime.highavailability.HighAvailabilityServicesUtils.getJobManagerAddress(HighAvailabilityServicesUtils.java:150) at org.apache.flink.runtime.highavailability.HighAvailabilityServicesUtils.createHighAvailabilityServices(HighAvailabilityServicesUtils.java:86) at org.apache.flink.client.program.ClusterClient.<init>(ClusterClient.java:118) at org.apache.flink.client.program.rest.RestClusterClient.<init>(RestClusterClient.java:179) at org.apache.flink.client.program.rest.RestClusterClient.<init>(RestClusterClient.java:152) at org.apache.flink.client.deployment.StandaloneClusterDescriptor.retrieve(StandaloneClusterDescriptor.java:49) ... 10 more
这个错 感觉是没有指定flink 的jobmanager 他没有办法知道他提交在哪台服务器上面。于是乎就就找这个jobmanager的地址在哪里。 这个怎么找那 我们通过命令行去找 ,因为程序是提交在yarn 上面
所以我们通过下面的命令
yarn application -list

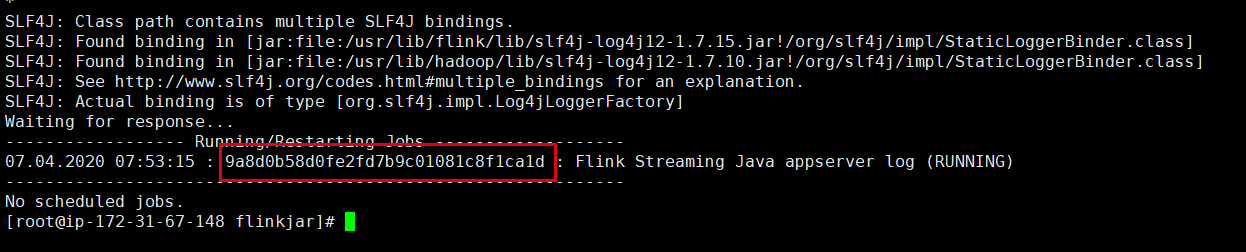
从上面的图中 我们能看到提交的flink的jobmanager 然后采用使用下面的命令 然后展示你想要的flink 的id
flink list -m 你的flink提交的jobmanager:32981 (这里需要需要机上-m )
问题 2 上面的步骤是获取到了 flink运行的id 接下来 我们要做的就是要对代码进行升级,这里我们要做的是手工保存一份savapoint 但是貌似有很多坑(采坑开始)
flink savepoint 9a8d0b58d0fe2fd7b9c01081c8f1ca1d -m 自己的IP:32981 hdfs:///tmp/tmp
这个是保存程序的savepoint
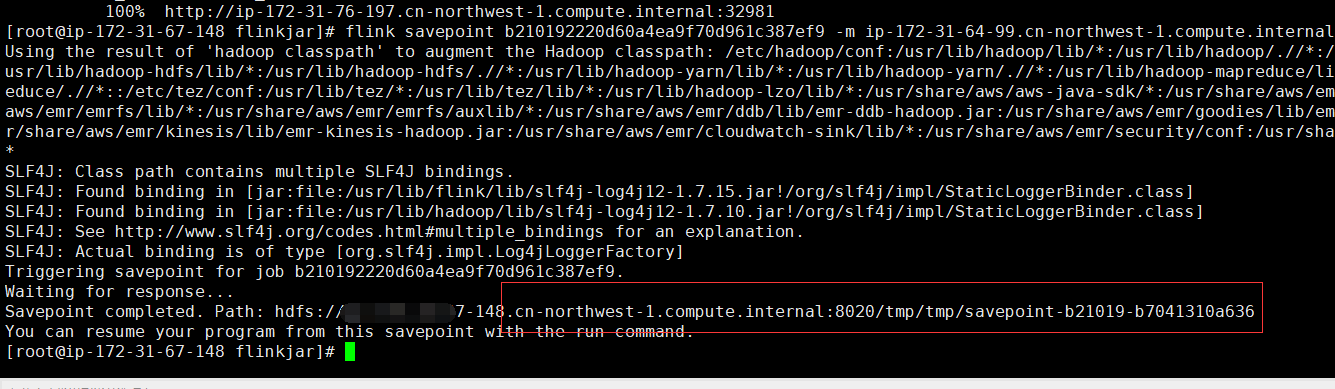
这样数据就保存到hdfs 上面去了。
除了这个方式之外 我们也可以通过在停止程序的时候将程序的savepoint 写入到hdfs 当中去。
停止程序的时候的命令:
flink cancel -s hdfs:///tmp/tmp 088d62e015adcb92e1b92171c438bc18 -m 自己的IP:36305
这个是在程序停止的时候就将savepoint 保存到hdfs的目录当中去了。
我们将程序停止掉之后,在程序再次启动的时候 我们要将我们保存的savepoint通知程序 让程序知道。启动的命令如下:
flink run -m yarn-cluster -s hdfs:///tmp/tmp/savepoint-088d62-0d3a2d53d0e9 -c WordCount /mnt/flinkjar/flinkTestConsumeKafka.jar
问题三:
我们的程序提交到集群当中,然后发现程序跑起来了,但是貌似在界面没有数据显示
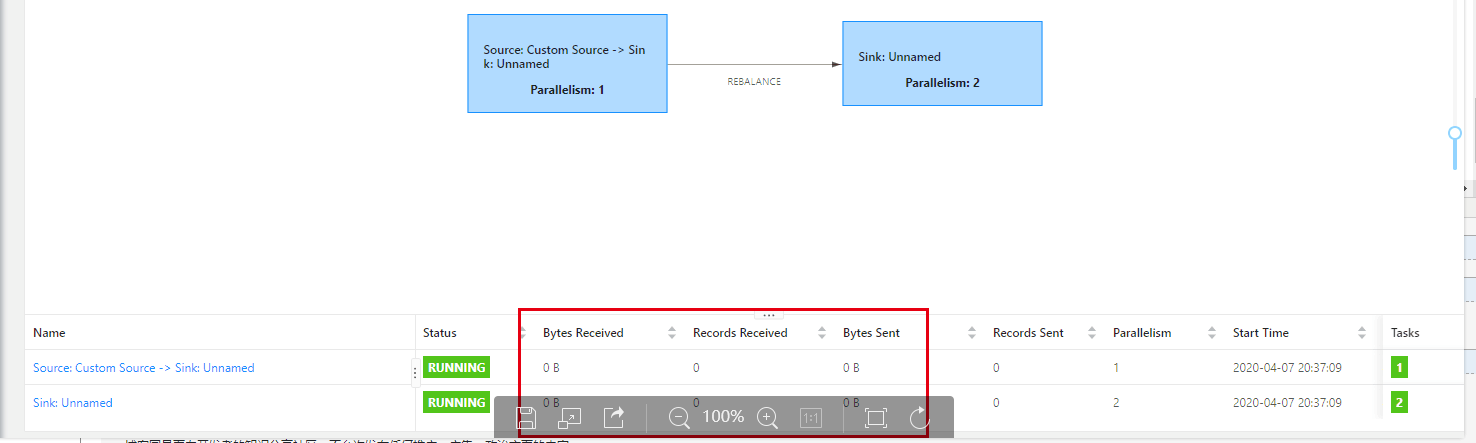
然后在网上找到一片帖子 ,我擦30大洋才能看 真是卧槽。 最后没办法还是看了一眼。好在问题得到解决(为什么我的Flink任务正常运行,UI上却不显示接收和发送的数据条数呢?)
def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) val ds = CommonUtils.getDataStream(env = env) .name("kafka-source") .filter(_.nonEmpty) .print() env.execute() }
这个是他的原代码。
def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) val ds = CommonUtils.getDataStream(env = env) .name("kafka-source") .filter(_.nonEmpty) .startNewChain() .disableChaining() .setParallelism(2) .print() env.execute() }
这是修改后的代码。这个时候就需要打断operator chain,具体有三种写法,如下代码所示 这里的操作就是将操作连打断,然后就能看到数据了。因为在一个DAG当中。
这三种写法都可以达到打断chain的目的,有什么区别呢?startNewChain和disableChaining没有实质性的区别,他俩都会打断chain,但是不会改变算子的并发度,setParallelism和前面的算子并发度,设置的不一致自然就打断chain了
当然这是别人的写法,在Java当中也有类似的写法:
keyedStream.addSink(new MysqlSink()).disableChaining().setParallelism(1);
我们是将数据sink到MySQL 当中。所以我这里这么写
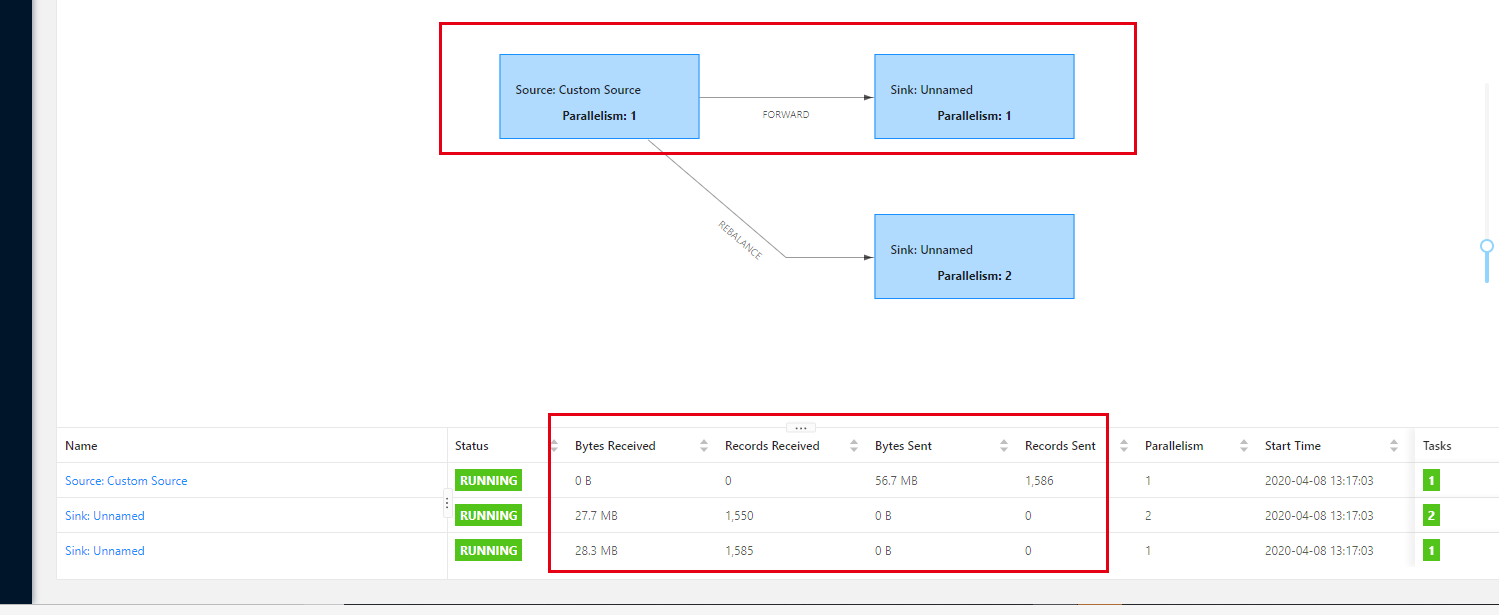
到这里我们的数据顺利的写入到数据库 在界面上 也能看到数据。这样问题就得到了解决。
问题 四 关于kafka的 问题。我们通过读取kafka 里面的数据 然后将数据写入到mysql 我只用用的私网地址 然后就各种获取不到kafka 的元数据信息 导致一直读取不到数据。
所以 大家在做kafka读数据的时候,先ping 一下地址看通不通。真是蛋疼


 浙公网安备 33010602011771号
浙公网安备 33010602011771号