关于streamsets的相关问题总结
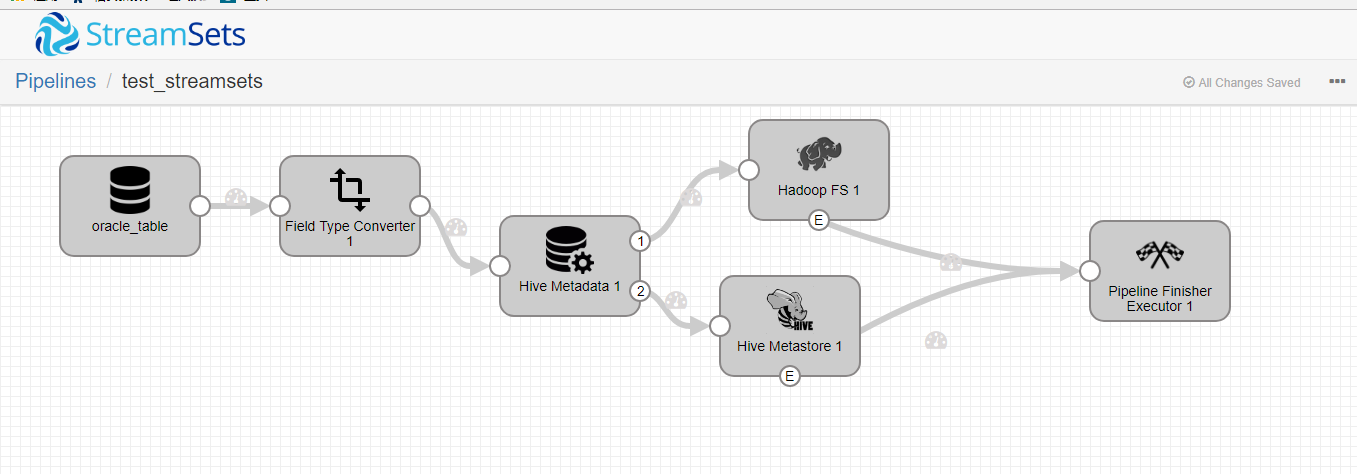
最近发现了一个很好用的工具streamsets工具。我将oracle数据库当中的数据增量的导入到hive当中。导入是按照唯一的主键ID将数据导入进来。
出现的问题如下:
(1)数据精度的问题:
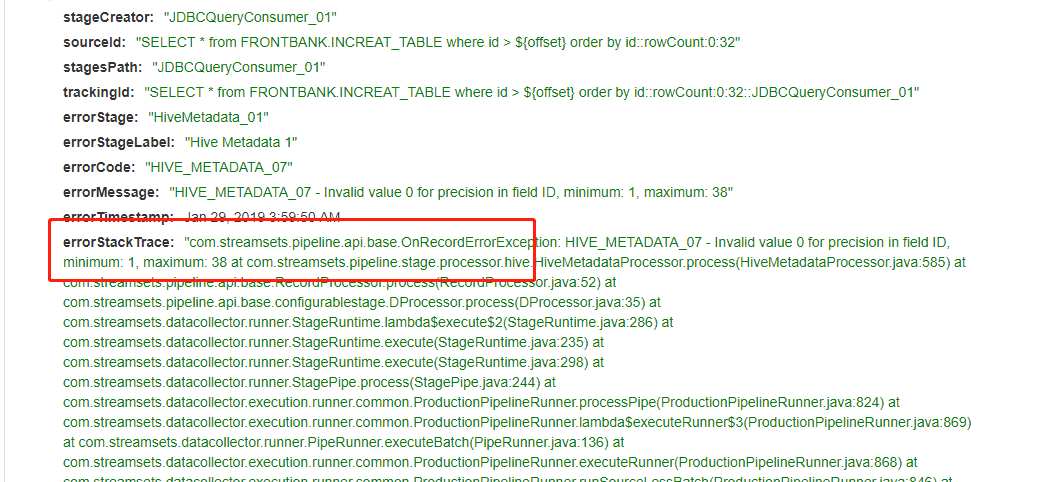
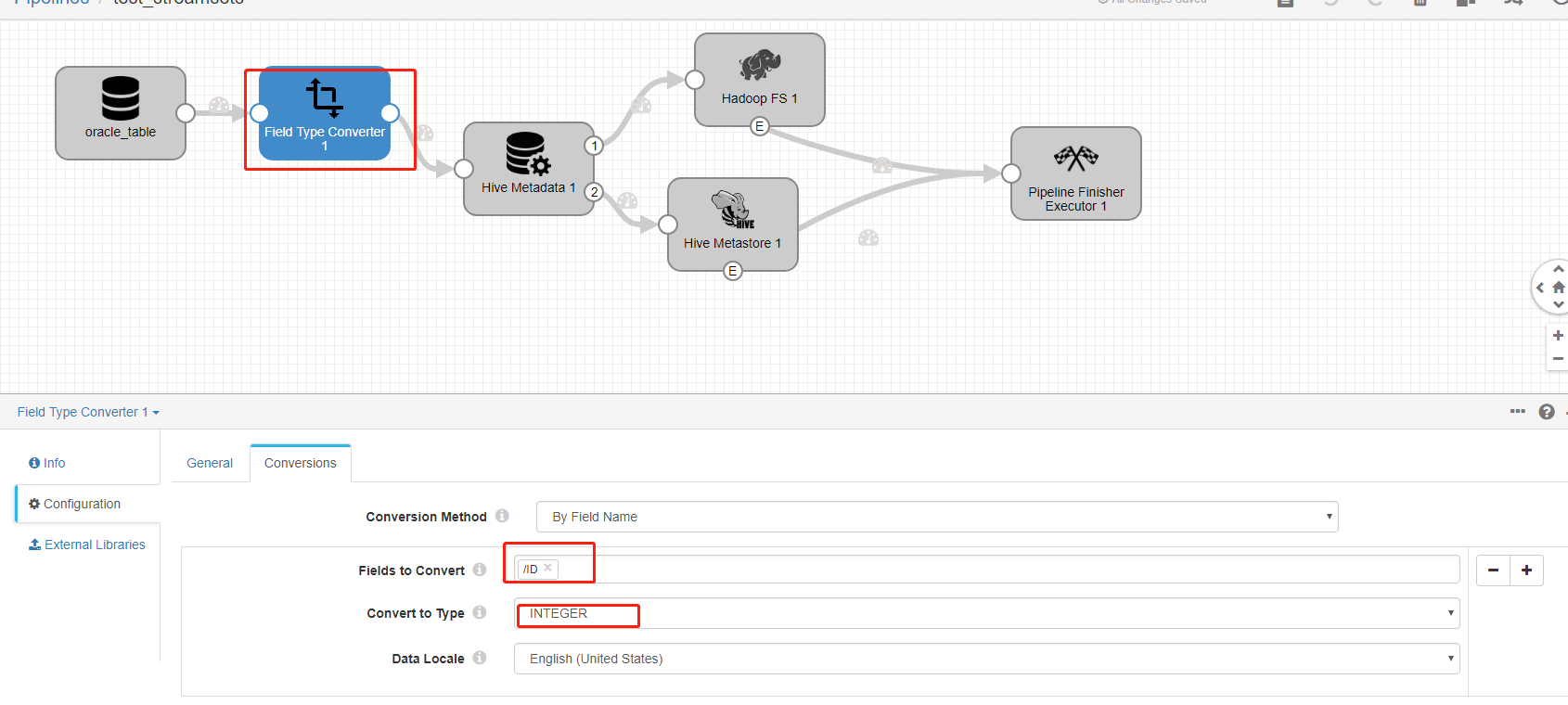
因为表是提前创建好的,我将id字段定义为int类型,但是在oracle数据库当中的数据类型是number类型。然后将number类型的数据转换为decimal类型的数据。decimal默认的精度为(1,38)位。所以这里的解决办法就是
在oracle导入数据和hive的元数据之间加上一个数据类型转化的操作。将原来的number类型转化为integer类型。这样在hive表当中定义的数据类型就不会出现数据类型转化异常的问题
(2)hive当中的表的存储格式不一致:
com.streamsets.pipeline.api.base.OnRecordErrorException: HIVE_32 - Table test_to_hive is created using Storage Format Type org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, but Avro requested instead at com.streamsets.pipeline.stage.processor.hive.HiveMetadataProcessor.process(HiveMetadataProcessor.java:585) at com.streamsets.pipeline.api.base.RecordProcessor.process(RecordProcessor.java:52) at com.streamsets.pipeline.api.base.configurablestage.DProcessor.process(DProcessor.java:35) at com.streamsets.datacollector.runner.StageRuntime.lambda$execute$2(StageRuntime.java:286) at com.streamsets.datacollector.runner.StageRuntime.execute(StageRuntime.java:235) at com.streamsets.datacollector.runner.StageRuntime.execute(StageRuntime.java:298) at com.streamsets.datacollector.runner.StagePipe.process(StagePipe.java:244) at com.streamsets.datacollector.execution.runner.common.ProductionPipelineRunner.processPipe(ProductionPipelineRunner.java:824) at com.streamsets.datacollector.execution.runner.common.ProductionPipelineRunner.lambda$executeRunner$3(ProductionPipelineRunner.java:869) at com.streamsets.datacollector.runner.PipeRunner.executeBatch(PipeRunner.java:136) at
从这报错可以看出hive表当中的数据类型呀定义为AVRO的数据类型。
(3)在增量导入数据的时候出现,形成的文件一直是tmp开头的文件。所以在hive的客户端查询不到数据效果如下:
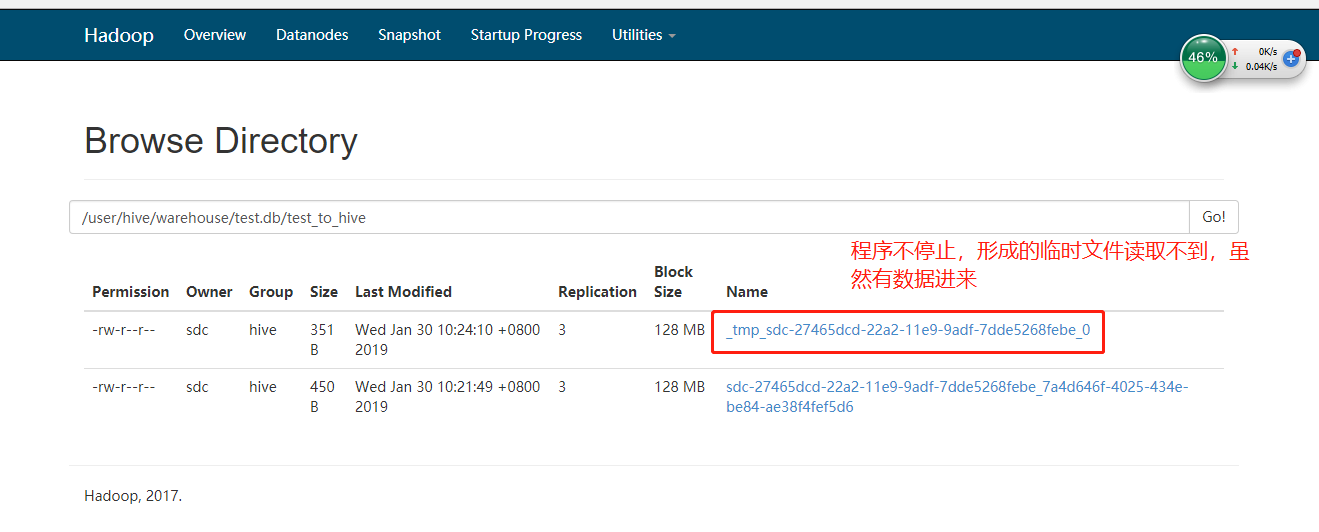
突然发现只有每次吧pipline关闭掉才能读取hive上面的文件。最后在hive的设置当中找到相关的选项:
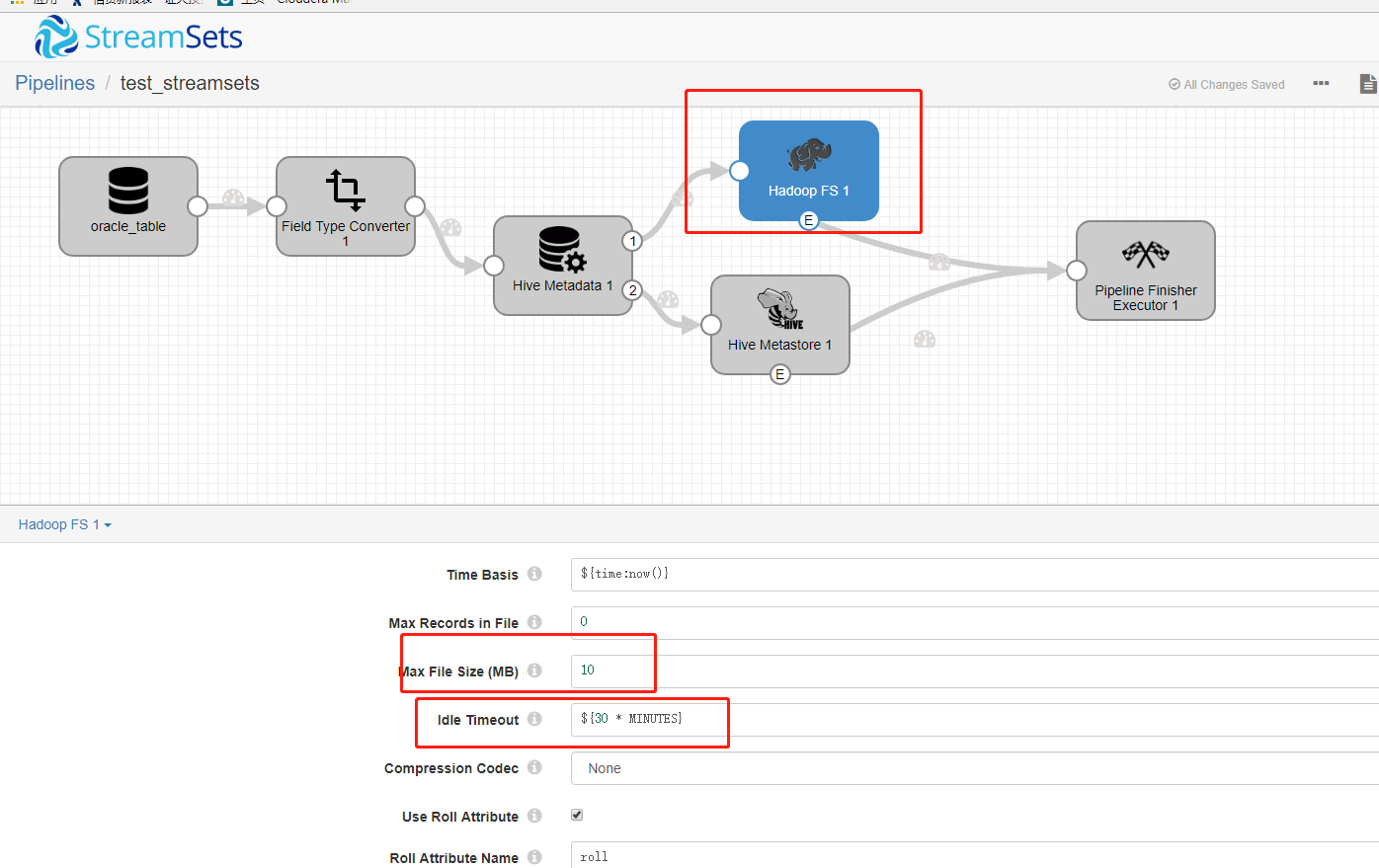
这两个选项的目的就是为了限制输出的文件的大小,和控制多长时间输出一个文件。我们会发现,当我们设置了时间之后,优先按照时间对数据进行输出形成的文件不在是tmp类型的文件。
还有就是文件大小,如果我们设置的时间够长,在一定的时间内形成了10M这样的文件就输出,不在考虑时间的限制。
总结:这个其实和flume的原理是相同的对数据进行回滚操作。然后按照时间或者文件大小的方式对形成的数据文件进行大小的限制。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号