关于sqoop增量导入过程中,文件合并遇到的问题。
今天在多sqoop的增量导入操作,遇到下面这个问题(报错如下):
2019-01-12 14:20:54,332 FATAL [IPC Server handler 0 on 38807] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Task: attempt_1546053074766_0445_m_000000_0 - exited :
java.lang.RuntimeException: Can't parse input data: ' sunt in culpa qu' at FRONTBANK_INCREAT_TABLE.__loadFromFields(FRONTBANK_INCREAT_TABLE.java:321) at FRONTBANK_INCREAT_TABLE.parse(FRONTBANK_INCREAT_TABLE.java:259) at org.apache.sqoop.mapreduce.MergeTextMapper.map(MergeTextMapper.java:53) at org.apache.sqoop.mapreduce.MergeTextMapper.map(MergeTextMapper.java:34) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:793) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1917) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158) Caused by: java.lang.IllegalArgumentException: Timestamp format must be yyyy-mm-dd hh:mm:ss[.fffffffff] at java.sql.Timestamp.valueOf(Timestamp.java:235) at FRONTBANK_INCREAT_TABLE.__loadFromFields(FRONTBANK_INCREAT_TABLE.java:318) ... 11 more
看到上面这个错误,一定会时间的问题,其实不然,这就牵扯到sqoop导入数据的注意事项。我们知道在sqoop导入数据的时候是按照某个特定的分割符号进行分割的。
在这里我是按照逗号去分割每一行的字段。当这一行的数据更新之后我们按照更新时间对数据进行进行新增,更新操作(这里注意不能做删除操作)这个错误是在将增量数据导入进来之后,
和原始的数据做merge操作的时候出现的,也就是说数据在更新的时候出现的(数据错位)。下面分析一下这个错误:
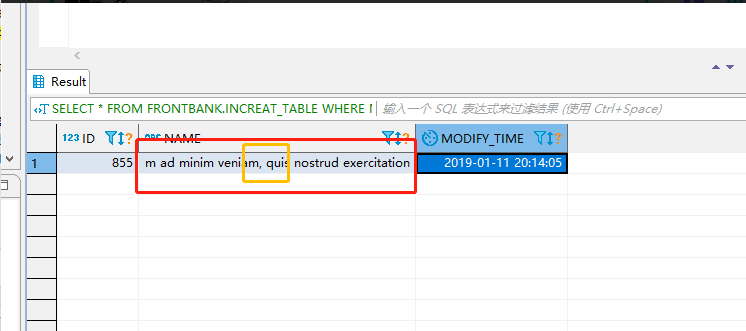
这里有一个逗号,当好我的默认分割符号是逗号,也就是在检查完这一行数据是更新的数据,然后按照一个一个字段进行匹配的时候,突然将时间赋值给这个字符串的时候就出现问题了
所以才会报 Caused by: java.lang.IllegalArgumentException: Timestamp format must be yyyy-mm-dd hh:mm:ss[.fffffffff] 也就是匹配错误的意思。
所以在sqoop导入数据的时候分割符号是很重要(sqoop的分隔符是一个头疼的事情。解决方法就是更换分隔符)
至此问题得到解决


 浙公网安备 33010602011771号
浙公网安备 33010602011771号