

hadoop网络拓扑结构在整个系统中具有很重要的作用,它会影响DataNode的启动(注册)、MapTask的分配等等。了解网络拓扑对了解整个hadoop的运行会有很大帮助。
首先通过下面两个图来了解与网络拓扑有关的类。
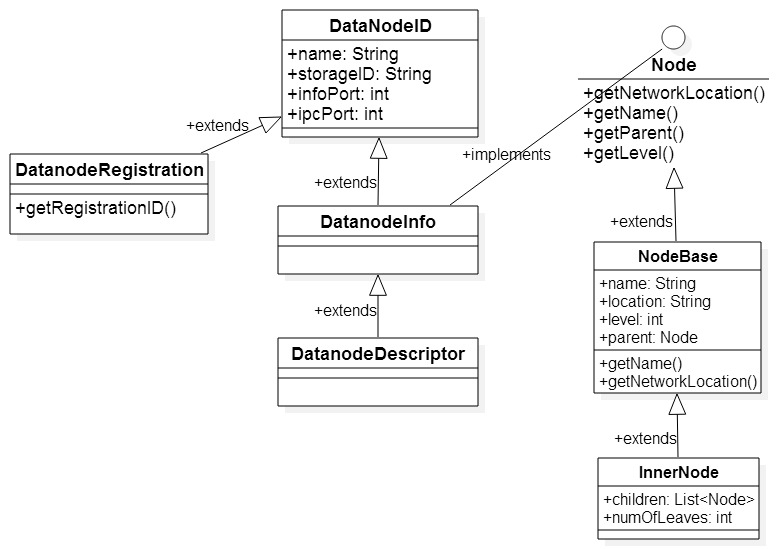
NetworkTopology用来表示hadoop集群的网络拓扑结构。hadoop将整个网络拓扑组织成树的结构(可以参考这篇文章https://issues.apache.org/jira/secure/attachment/12345251/Rack_aware_HDFS_proposal.pdf),其中Node接口代表树中的结点,既可以是树的内部结点(如data center,rack),也可以是叶子结点(就是host);而NodeBase实现了Node;NetworkTopology.InnerNode则代表树的内部结点。
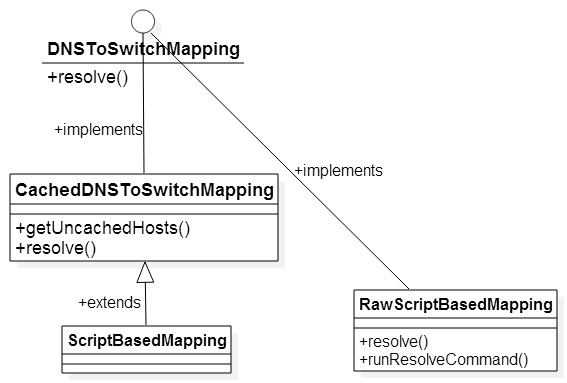
DNSToSwitchMapping用来把集群中的node转换成对应的网络位置,比如将域名/IP地址转换成集群中对应的网络位置。CachedDNSToSwitchMapping则用来缓存已经被解析出来的映射。ScriptBasedMapping主要是解析用户配置的映射脚本,并根据脚本中的转换规则进行映射;这个脚本的位置由配置文件“core-site.xml”中的参数“topology.script.file.name”来指定。RawScriptBasedMapping是ScriptBasedMapping的内部类,脚本的执行由这个类中的resolve()方法完成。
下面以DataNode启动时向NameNode注册自己的结点为例,来说明映射过程。当DataNode启动的时候以DatanodeRegistration的形式,通过RPC调用NameNode的register()方法,向NameNode来注册本结点的信息,使得NameNode通过网络拓扑确定该DataNode在网络拓扑中的位置。其具体实现过程在FSNamesystem中的registerDatanode()方法中,具体代码如下:


1 /** 2 * Register Datanode. 3 * <p> 4 * The purpose of registration is to identify whether the new datanode 5 * serves a new data storage, and will report new data block copies, 6 * which the namenode was not aware of; or the datanode is a replacement 7 * node for the data storage that was previously served by a different 8 * or the same (in terms of host:port) datanode. 9 * The data storages are distinguished by their storageIDs. When a new 10 * data storage is reported the namenode issues a new unique storageID. 11 * <p> 12 * Finally, the namenode returns its namespaceID as the registrationID 13 * for the datanodes. 14 * namespaceID is a persistent attribute of the name space. 15 * The registrationID is checked every time the datanode is communicating 16 * with the namenode. 17 * Datanodes with inappropriate registrationID are rejected. 18 * If the namenode stops, and then restarts it can restore its 19 * namespaceID and will continue serving the datanodes that has previously 20 * registered with the namenode without restarting the whole cluster. 21 * 22 * @see org.apache.hadoop.hdfs.server.datanode.DataNode#register() 23 */ 24 public synchronized void registerDatanode(DatanodeRegistration nodeReg 25 ) throws IOException { 26 String dnAddress = Server.getRemoteAddress(); 27 if (dnAddress == null) { 28 // Mostly called inside an RPC. 29 // But if not, use address passed by the data-node. 30 dnAddress = nodeReg.getHost(); 31 } 32 33 // check if the datanode is allowed to be connect to the namenode 34 if (!verifyNodeRegistration(nodeReg, dnAddress)) { 35 throw new DisallowedDatanodeException(nodeReg); 36 } 37 38 String hostName = nodeReg.getHost(); 39 40 // update the datanode's name with ip:port 41 DatanodeID dnReg = new DatanodeID(dnAddress + ":" + nodeReg.getPort(), 42 nodeReg.getStorageID(), 43 nodeReg.getInfoPort(), 44 nodeReg.getIpcPort()); 45 nodeReg.updateRegInfo(dnReg); 46 nodeReg.exportedKeys = getBlockKeys(); 47 48 NameNode.stateChangeLog.info( 49 "BLOCK* registerDatanode: " 50 + "node registration from " + nodeReg.getName() 51 + " storage " + nodeReg.getStorageID()); 52 53 //在datanodeMap与host2DataNodeMap查找该DataNode 54 //但如果该DataNode是第一次注册的话(而不是重启后的注册),nodeS与nodeN都为null 55 DatanodeDescriptor nodeS = datanodeMap.get(nodeReg.getStorageID()); 56 DatanodeDescriptor nodeN = host2DataNodeMap.getDatanodeByName(nodeReg.getName()); 57 58 if (nodeN != null && nodeN != nodeS) { 59 NameNode.LOG.info("BLOCK* registerDatanode: " 60 + "node from name: " + nodeN.getName()); 61 // nodeN previously served a different data storage, 62 // which is not served by anybody anymore. 63 removeDatanode(nodeN); 64 // physically remove node from datanodeMap 65 wipeDatanode(nodeN); 66 nodeN = null; 67 } 68 69 if (nodeS != null) { 70 if (nodeN == nodeS) { 71 // The same datanode has been just restarted to serve the same data 72 // storage. We do not need to remove old data blocks, the delta will 73 // be calculated on the next block report from the datanode 74 NameNode.stateChangeLog.debug("BLOCK* registerDatanode: " 75 + "node restarted"); 76 } else { 77 // nodeS is found 78 /* The registering datanode is a replacement node for the existing 79 data storage, which from now on will be served by a new node. 80 If this message repeats, both nodes might have same storageID 81 by (insanely rare) random chance. User needs to restart one of the 82 nodes with its data cleared (or user can just remove the StorageID 83 value in "VERSION" file under the data directory of the datanode, 84 but this is might not work if VERSION file format has changed 85 */ 86 NameNode.stateChangeLog.info( "BLOCK* registerDatanode: " 87 + "node " + nodeS.getName() 88 + " is replaced by " + nodeReg.getName() + 89 " with the same storageID " + 90 nodeReg.getStorageID()); 91 } 92 // update cluster map 93 clusterMap.remove(nodeS); 94 nodeS.updateRegInfo(nodeReg); 95 nodeS.setHostName(hostName); 96 97 // resolve network location 98 resolveNetworkLocation(nodeS); 99 clusterMap.add(nodeS); 100 101 // also treat the registration message as a heartbeat 102 synchronized(heartbeats) { 103 if( !heartbeats.contains(nodeS)) { 104 heartbeats.add(nodeS); 105 //update its timestamp 106 nodeS.updateHeartbeat(0L, 0L, 0L, 0); 107 nodeS.isAlive = true; 108 } 109 } 110 return; 111 } 112 113 // this is a new datanode serving a new data storage 114 //正常启动的DataNode,其StorageID都不会为“” 115 if (nodeReg.getStorageID().equals("")) { 116 // this data storage has never been registered 117 // it is either empty or was created by pre-storageID version of DFS 118 nodeReg.storageID = newStorageID(); 119 NameNode.stateChangeLog.debug( 120 "BLOCK* registerDatanode: " 121 + "new storageID " + nodeReg.getStorageID() + " assigned"); 122 } 123 // register new datanode 124 //NetworkTopology.DEFAULT_RACK实际上为/default-rack 125 //系统会将该DataNode的网络位置设置为默认的网络位置:/default-rack 126 //然后在后续的操作中,如果发现用户配置了映射脚本,则对该网络位置进行修正 127 DatanodeDescriptor nodeDescr 128 = new DatanodeDescriptor(nodeReg, NetworkTopology.DEFAULT_RACK, hostName); 129 //解析该node的网络位置 130 resolveNetworkLocation(nodeDescr); 131 unprotectedAddDatanode(nodeDescr); 132 //clusterMap就是NetworkTopology,将解析出来的node添加到网络拓扑中 133 clusterMap.add(nodeDescr); 134 135 // also treat the registration message as a heartbeat 136 synchronized(heartbeats) { 137 heartbeats.add(nodeDescr); 138 nodeDescr.isAlive = true; 139 // no need to update its timestamp 140 // because its is done when the descriptor is created 141 } 142 143 if (safeMode != null) { 144 safeMode.checkMode(); 145 } 146 return; 147 }
其中,网络位置的解析在resolveNetworkLocation()方法中:
1 /* Resolve a node's network location */ 2 //这个方法就开始解析某个DataNode的网络位置了 3 private void resolveNetworkLocation (DatanodeDescriptor node) { 4 List<String> names = new ArrayList<String>(1); 5 if (dnsToSwitchMapping instanceof CachedDNSToSwitchMapping) { 6 //通过getClass()方法知道,dnsToSwitchMapping是ScriptBasedMapping的实例 7 // get the node's IP address 8 names.add(node.getHost()); 9 } else { 10 // get the node's host name 11 String hostName = node.getHostName(); 12 int colon = hostName.indexOf(":"); 13 hostName = (colon==-1)?hostName:hostName.substring(0,colon); 14 names.add(hostName); 15 } 16 17 // resolve its network location 18 //因为ScriptBasedMapping继承了CachedDNSToSwitchMapping 19 //所以此处会调用CachedDNSToSwitchMapping的resolve()方法 20 //返回的是已经被解析出来的网络位置 21 List<String> rName = dnsToSwitchMapping.resolve(names); 22 String networkLocation; 23 if (rName == null) { 24 LOG.error("The resolve call returned null! Using " + 25 NetworkTopology.DEFAULT_RACK + " for host " + names); 26 networkLocation = NetworkTopology.DEFAULT_RACK; 27 } else { 28 networkLocation = rName.get(0); 29 } 30 //修正该node的网络位置 31 node.setNetworkLocation(networkLocation); 32 }
resolveNetworkLocation()方法又会调用CachedDNSToSwitchMapping的resolve()方法来解析网络位置:
1 public List<String> resolve(List<String> names) { 2 // normalize all input names to be in the form of IP addresses 3 names = NetUtils.normalizeHostNames(names); 4 5 List <String> result = new ArrayList<String>(names.size()); 6 if (names.isEmpty()) { 7 return result; 8 } 9 10 //确认该IP地址是否已经被缓存 11 List<String> uncachedHosts = this.getUncachedHosts(names); 12 13 // Resolve the uncached hosts 14 //通过getClass()知道,rawMapping是RawScriptBasedMapping的实例 15 //如果用户指定了映射脚本,则根据脚本进行转换 16 //否则返回默认的网络位置:/default-rack 17 List<String> resolvedHosts = rawMapping.resolve(uncachedHosts); 18 //将未缓存的IP地址与其对应的网络位置进行缓存 19 this.cacheResolvedHosts(uncachedHosts, resolvedHosts); 20 //返回该IP地址对应的网络位置 21 return this.getCachedHosts(names); 22 23 }
而在CachedDNSToSwitchMapping的resolve()方法中,又会调用RawScriptBasedMapping的resolve()方法来完成网络位置解析。该方法主要是两方面功能:如果用户没有指定映射脚本,那么返回默认的网络位置:/default-rack;否则根据指定脚本中国的映射规则来进行转换。
1 //SCRIPT_FILENAME_KEY的值为"topology.script.file.name" 2 this.scriptName = conf.get(SCRIPT_FILENAME_KEY); 3 4 public List<String> resolve(List<String> names) { 5 List <String> m = new ArrayList<String>(names.size()); 6 7 if (names.isEmpty()) { 8 return m; 9 } 10 11 //若没有指定脚本 12 if (scriptName == null) { 13 for (int i = 0; i < names.size(); i++) { 14 m.add(NetworkTopology.DEFAULT_RACK); 15 } 16 return m; 17 } 18 19 //若指定了脚本,则运行脚本进行解析 20 String output = runResolveCommand(names); 21 if (output != null) { 22 StringTokenizer allSwitchInfo = new StringTokenizer(output); 23 while (allSwitchInfo.hasMoreTokens()) { 24 String switchInfo = allSwitchInfo.nextToken(); 25 m.add(switchInfo); 26 } 27 28 if (m.size() != names.size()) { 29 // invalid number of entries returned by the script 30 LOG.warn("Script " + scriptName + " returned " 31 + Integer.toString(m.size()) + " values when " 32 + Integer.toString(names.size()) + " were expected."); 33 return null; 34 } 35 } else { 36 // an error occurred. return null to signify this. 37 // (exn was already logged in runResolveCommand) 38 return null; 39 } 40 41 return m; 42 }
至此,网络位置的解析工作结束。但有几点需要注意:
1、网络位置是该结点的父目录的位置,也就是说,如果集群中有一个结点node1,其在集群中所处的位置为:/d1/r1/node1,则其网络位置则为:/d1/r1,并不包含自身。
2、如果集群中没有配置映射脚本,那么默认所有的叶子结点都在同一个rack下,这个rack就是“/default-rack”,即所有叶子结点都在“/default-rack”下。
3、关于结点的Level。在Node接口中,定义了getLevel()方法,用来获取该node在网络拓扑树中的层级。其中,树的根的level为0,其孩子(也就是rack)为1,而叶子结点(就是host)为2。
但无论集群是否配置了映射脚本,所有rack的level都是1,所有叶子结点的level都是2。也就是说,在/default-rack/node结构与/d1/r1/node结构中,rack的level都是1,node的level都是2。
在本次学习源代码的过程中,更重要的是掌握了一种能够辅助阅读hadoop源代码的方法,那就是看测试类。根据测试类中的运行原理,来推测实际的运行情况,然后加以验证。事实上,这种方法有很大帮助。
本文基于hadoop1.2.1。如有错误,还请指正
参考文章:http://blog.csdn.net/shirdrn/article/details/4610578
http://caibinbupt.iteye.com/blog/298079
http://blog.csdn.net/azhao_dn/article/details/7091258
http://blog.csdn.net/xhh198781/article/details/7162270
http://blog.csdn.net/xhh198781/article/details/7106215
http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html
https://issues.apache.org/jira/secure/attachment/12345251/Rack_aware_HDFS_proposal.pdf
转载请注明出处:http://www.cnblogs.com/gwgyk/p/4525463.html
附件下载地址: UML图

