

接着上篇来说,TaskTracker端的transmitHeartBeat()方法通过RPC调用JobTracker端的heartbeat()方法来接收心跳并返回心跳应答。还是先看看这张图,对它的大概流程有个了解。

下面来一段一段的分析该方法。
1 public synchronized HeartbeatResponse heartbeat(TaskTrackerStatus status,
2 boolean restarted,
3 boolean initialContact,
4 boolean acceptNewTasks,
5 short responseId)
6 throws IOException {
7 if (LOG.isDebugEnabled()) {
8 LOG.debug("Got heartbeat from: " + status.getTrackerName() + " (restarted: " + restarted +
9 " initialContact: " + initialContact +
10 " acceptNewTasks: " + acceptNewTasks + ")" +
11 " with responseId: " + responseId);
12 }
13 // 检查该主机是否允许与JobTracker通信
14 if (!acceptTaskTracker(status)) {
15 throw new DisallowedTaskTrackerException(status);
16 }
上面这段代码首先检查该TaskTracker是否能与JobTracker通信。确保该TaskTracker在允许的主机列表里(即inHostsList(),由”mapred.hosts”指定),不在排除的主机列表里(即inExcludedHostsList(),由” mapred.hosts.exclude” 指定)。
1 String trackerName = status.getTrackerName();
2 long now = clock.getTime();
3 if (restarted) {
4 faultyTrackers.markTrackerHealthy(status.getHost());
5 } else {
6 faultyTrackers.checkTrackerFaultTimeout(status.getHost(), now);
7 }
上面这段代码表示:如果该TaskTracker被重启了,则将其标注为健康的,然后从黑名单和灰名单中移除,并从potentiallyFaultyTrackers(潜在有错误的Tracker。当有task运行失败时,就将其加入该队列中)集合中移除。否则,启动TaskTracker容错机制以检查它是否处于健康状态。
1 HeartbeatResponse prevHeartbeatResponse =
2 trackerToHeartbeatResponseMap.get(trackerName); //获取上次心跳应答
3 boolean addRestartInfo = false; //表示JobTracker是否重启
4
5 if (initialContact != true) { //该TaskTracker不是初次连接JobTracker
6 // If this isn't the 'initial contact' from the tasktracker,
7 // there is something seriously wrong if the JobTracker has
8 // no record of the 'previous heartbeat'; if so, ask the
9 // tasktracker to re-initialize itself.
10 if (prevHeartbeatResponse == null) { //TaskTracker不是初次连接JobTracker,并且上一次心跳应答对象为空
11 // This is the first heartbeat from the old tracker to the newly
12 // started JobTracker
13 if (hasRestarted()) { //JobTracker重启了
14 addRestartInfo = true;
15 // inform the recovery manager about this tracker joining back
16 recoveryManager.unMarkTracker(trackerName);
17 } else { //JobTracker没有重启
18 // Jobtracker might have restarted but no recovery is needed
19 // otherwise this code should not be reached
20 LOG.warn("Serious problem, cannot find record of 'previous' " +
21 "heartbeat for '" + trackerName +
22 "'; reinitializing the tasktracker");
23 return new HeartbeatResponse(responseId,
24 new TaskTrackerAction[] {new ReinitTrackerAction()}); //重新初始化该TaskTracker
25 }
26
27 } else { //该TaskTracker不是第一次连接JobTracker,并且上次心跳应答不为空
28
29 // It is completely safe to not process a 'duplicate' heartbeat from a
30 // {@link TaskTracker} since it resends the heartbeat when rpcs are
31 // lost see {@link TaskTracker.transmitHeartbeat()};
32 // acknowledge it by re-sending the previous response to let the
33 // {@link TaskTracker} go forward.
34 if (prevHeartbeatResponse.getResponseId() != responseId) {
35 LOG.info("Ignoring 'duplicate' heartbeat from '" +
36 trackerName + "'; resending the previous 'lost' response");
37 return prevHeartbeatResponse; //心跳丢失,返回上次心跳应答
38 }
39 }
40 }
上面这部分用来检测上次心跳是否结束。首先获取该TaskTracker的上次心跳应答响应。正常情况下在JobTracker中的trackerToHeartbeatResponseMap对象中会存在该TaskTracker上一次的心跳应答对象信息HeartbeatResponse,初次心跳连接则不会有该TaskTracker上一次的心跳应答对象。
当该TaskTracker与JobTracker不是初次连接时:如果JobTracker中没有上次与该TaskTracker通信的心跳应答记录(即prevHeartbeatResponse == null),那么再检查JobTracker若重启了,则(来自该TaskTracker的心跳表明与JobTracker已经重新连接了)从recoveryManager中删除这个TaskTracker;否则重新初始化该TaskTracker。如果JobTracker有与TaskTracker通信的上次心跳记录(即prevHeartbeatResponse != null),但是JobTracker记录的心跳ID与TaskTracker发送过来的心跳ID不一致,说明发生了心跳丢失,此时返回上一次的心跳应答,这样可以防止处理重复的心跳请求。
1 // Process this heartbeat
2 short newResponseId = (short)(responseId + 1);
3 status.setLastSeen(now);
4 if (!processHeartbeat(status, initialContact, now)) { //心跳处理失败
5 if (prevHeartbeatResponse != null) { //上次心跳应答不存在
6 trackerToHeartbeatResponseMap.remove(trackerName);
7 }
8 return new HeartbeatResponse(newResponseId,
9 new TaskTrackerAction[] {new ReinitTrackerAction()}); //重新初始化该TaskTracker
10 }
这一部分来处理心跳信息。首先是心跳响应的ID加1,然后将心跳发送时间设置为当前时间。processHeartbeat()方法用来处理心跳。外层if表示心跳处理失败,内层if表示如果上次心跳应答存在的话,则从trackerToHeartbeatResponseMap中移除,然后重新初始化TaskTracker。最后分析processHeartbeat()方法。
1 // Initialize the response to be sent for the heartbeat 2 HeartbeatResponse response = new HeartbeatResponse(newResponseId, null); 3 List<TaskTrackerAction> actions = new ArrayList<TaskTrackerAction>(); 4 boolean isBlacklisted = faultyTrackers.isBlacklisted(status.getHost()); //检查该结点是否在黑名单中 5 // Check for new tasks to be executed on the tasktracker 6 if (recoveryManager.shouldSchedule() && acceptNewTasks && !isBlacklisted) { 7 TaskTrackerStatus taskTrackerStatus = getTaskTrackerStatus(trackerName); 8 if (taskTrackerStatus == null) { 9 LOG.warn("Unknown task tracker polling; ignoring: " + trackerName); 10 } else { //首先执行cleanup和setup task 11 List<Task> tasks = getSetupAndCleanupTasks(taskTrackerStatus); 12 if (tasks == null ) { //如果没有cleanup和setup task,则由作业调度器分配map和reduce task 13 tasks = taskScheduler.assignTasks(taskTrackers.get(trackerName)); 14 } 15 if (tasks != null) { 16 for (Task task : tasks) { 17 expireLaunchingTasks.addNewTask(task.getTaskID()); 18 if(LOG.isDebugEnabled()) { 19 LOG.debug(trackerName + " -> LaunchTask: " + task.getTaskID()); 20 } 21 actions.add(new LaunchTaskAction(task)); 22 } 23 } 24 } 25 }
上面这部分主要用来构造心跳应答,其中包含对TaskTracker下达的命令。首先优先执行辅助型任务,其优先级为job-cleanup task、task-cleanup task(主要作用是清理失败的map或者reduce任务的部分结果数据)和job-setup task。它们由jobTracker直接调度,而且其调度的优先级比map和reduce任务都要高。从getSetupAndCleanupTasks()方法可以看出,执行时首先运行Map的辅助型任务,再执行Reduce的辅助型任务。然后将任务添加到expireLaunchingTasks队列中,监测其是否超时未汇报。最后为task构造LaunchTaskAction指令。如果没有辅助型任务,则由作业调度器TaskScheduler(默认为JobQueueTaskScheduler)来为TaskTracker分配任务。
捎带分析下getSetupAndCleanupTasks()方法,顾名思义,这个方法是用来获得setup task和cleanup task的。在JobInProgress类的initTasks()方法中,我们看到有4类task,分别是setup、map、reduce、cleanup,而setup和cleanup是针对Job的,并没有task-cleanup的task,但在getSetupAndCleanupTasks()方法中却多出了这个task,这是为什么?原来在JobInProgress中维护了两个队列:mapCleanupTasks和reduceCleanupTasks,分别用来存放map和reduce需要清理的task。当task处于FAILED_UNCLEAN或KILLED_UNCLEAN状态时,则根据task的类型将其添加到对应的队列中。getSetupAndCleanupTasks()方法的执行过程为:先检查map的job-cleanup task(对应JobInProgress中的cleanup[0])、task-cleanup task和job-setup task(对应JobInProgress中的setup[0]),再检查reduce的job-cleanup task(对应JobInProgress中的cleanup[1])、task-cleanup task和job-setup task(对应JobInProgress中的setup[1])。其对应关系如下图所示:

1 // Check for tasks to be killed
2 List<TaskTrackerAction> killTasksList = getTasksToKill(trackerName);
3 if (killTasksList != null) {
4 actions.addAll(killTasksList);
5 }
6
7 // Check for jobs to be killed/cleanedup
8 List<TaskTrackerAction> killJobsList = getJobsForCleanup(trackerName);
9 if (killJobsList != null) {
10 actions.addAll(killJobsList);
11 }
12
13 // Check for tasks whose outputs can be saved
14 List<TaskTrackerAction> commitTasksList = getTasksToSave(status);
15 if (commitTasksList != null) {
16 actions.addAll(commitTasksList);
17 }
这三段代码分别构造KillTaskAction、KillJobAction和CommitTaskAction指令。
1 // calculate next heartbeat interval and put in heartbeat response
2 int nextInterval = getNextHeartbeatInterval(); //计算下次心跳时间间隔
3 response.setHeartbeatInterval(nextInterval);
4 response.setActions( //将下达给TaskTracker的指令封装到心跳应答中
5 actions.toArray(new TaskTrackerAction[actions.size()]));
6
7 // check if the restart info is req
8 if (addRestartInfo) { //将需要恢复的Job告知放入心跳应答中
9 response.setRecoveredJobs(recoveryManager.getJobsToRecover());
10 }
11
12 // Update the trackerToHeartbeatResponseMap
13 trackerToHeartbeatResponseMap.put(trackerName, response); //将本次心跳应答更新到trackerToHeartbeatResponseMap,作为该TaskTracker最新的心跳应答
14
15 // Done processing the hearbeat, now remove 'marked' tasks
16 removeMarkedTasks(trackerName); //从trackerToMarkedTasksMap移除已被标记为完成的task
17
18 return response;
上面这段代码首先计算下次心跳间隔时间,JobTracker会根据集群规模(TaskTracker的数目)动态调整心跳时间间隔。如果JobTracker重启过的话,则将需要恢复的Job告知放入心跳应答中。然后将本次心跳应答更新到trackerToHeartbeatResponseMap,作为该TaskTracker最新的心跳应答。最后从trackerToMarkedTasksMap移除已被标记为完成的task。返回心跳应答。
心跳时间间隔的计算方法如下所示:
1 /**
2 * Calculates next heartbeat interval using cluster size.
3 * Heartbeat interval is incremented by 1 second for every 100 nodes by default.
4 * @return next heartbeat interval.
5 */
6 public int getNextHeartbeatInterval() { //默认情况下,处理每个RPC大约要10ms
7 // get the no of task trackers
8 int clusterSize = getClusterStatus().getTaskTrackers(); //
9 int heartbeatInterval = Math.max(
10 (int)(1000 * HEARTBEATS_SCALING_FACTOR *
11 ((double)clusterSize /
12 NUM_HEARTBEATS_IN_SECOND)),
13 HEARTBEAT_INTERVAL_MIN) ;
14 return heartbeatInterval;
15 }
HEARTBEATS_SCALING_FACTOR(mapreduce.jobtracker.heartbeats.scaling.factor):规模因子,默认为1,最小是0.01
NUM_HEARTBEATS_IN_SECOND(mapred.heartbeats.in.second):JobTracker每秒能处理的RPC数目,处理每个RPC约10ms时间。默认为100,最小为1。
所以这个公式表示,当集群增加了mapred.heartbeats.in.second个结点,心跳间隔增加mapreduce.jobtracker.heartbeats.scaling.factor秒。但为了防止设置不合理而对JobTracker产生较大负载,JobTracker要求心跳间隔至少为300ms。
最后分析下processHeartbeat()方法,还是先看图。
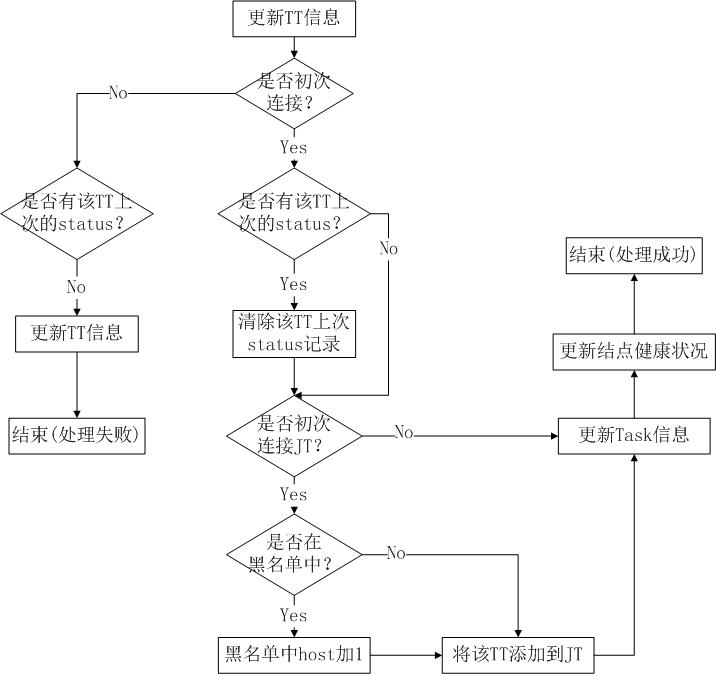
processHeartbeat()方法用来处理心跳。首先会更新TaskTracker的状态资源信息(如task、slot数目,在updateTaskTrackerStatus()方法中实现),返回值seenBefore代表JobTracker上是否存在该TaskTracker的上次status信息。然后判断该TaskTracker与JobTracker如果是初次连接并且存在上次status信息,则将其清空;如果不是初次连接并且不存在上次status信息,则更新TaskTracker的资源状态信息并返回false,表示处理心跳出错。接着再次判断如果是初次连接并且该TaskTracker在黑名单中,则黑名单中host的数目加1;然后将该TaskTracker添加JobTracker中。最后更新该TaskTracker的Task信息和健康状态。
本文基于hadoop1.2.1
如有错误,还请指正
参考文章:《Hadoop技术内幕 深入理解MapReduce架构设计与实现原理》 董西成
http://zengzhaozheng.blog.51cto.com/8219051/1359887
http://www.cnblogs.com/lxf20061900/p/3775963.html
转载请注明出处:http://www.cnblogs.com/gwgyk/p/4055133.html

