mysql/es/mongo/linux 优化问题
目录
mysql优化
1.mysql数据库慢查询怎么排查?
第一步:检查服务器性能有没有存在瓶颈
1.如果资源使用率比较高,cpu,硬盘使用率高,那么访问肯定慢
2.如果mysql进程占用cup比较高,说明mysql读写频率高,如果网站访问量不大,可能是mysql参数,慢sql的问题。
mysql参数方面的影响:尝试调整缓存池大小,查询缓存大小,最大连接数。
3.explan sql;分析sql,使用的索引,扫描的行数
4.没有走索引,建立索引。
5.如果还没有解决,考虑是不是数据量大,考虑分库分表,读写分离,扩展数据库的整体性能
2.满查询日志配置
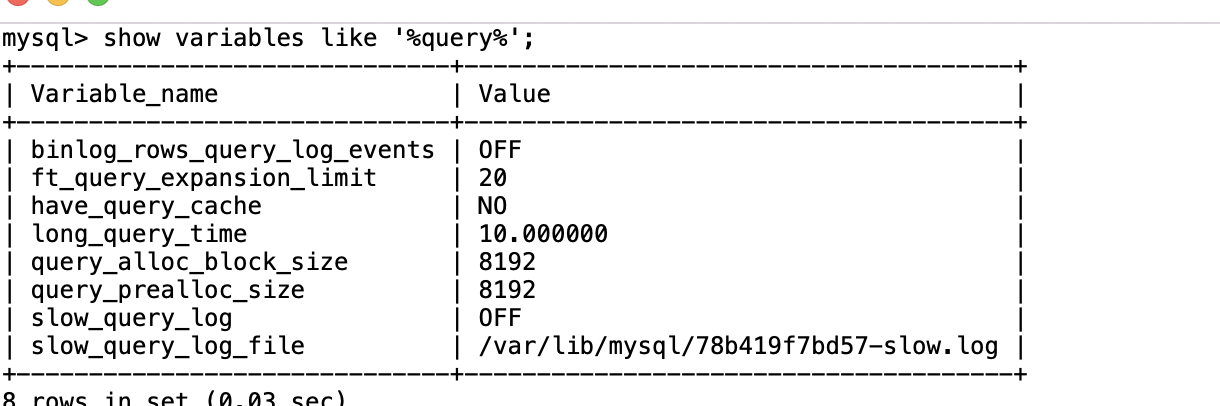
命令:
show variables like '%query%';//查看满日志配置
show processlist; //查看当前执行的sql
cat /var/lib/mysql/78b419f7bd57-slow.log //查看被记录的满日志
参数解释:
long_query_time:默认的满查询记录10秒
slow_query_log:是否启动满查询日志 OFF(默认关闭)
slow_query_log_file:满日志记录的路径
修改满日志配置:
set global slow_query_log = NO; //启动满查询日志
set long_query_time = 0.1;//满日志0.1秒
3.mysql执行sql内部过程
1.查询解析:SQL语句进行语法解析,检查语法是否正确
2.查询优化:选择最优的执行计划,优化过程包括但不限于:索引选择、表连接顺序优化、子查询优化等
3.查询执行:
1)打开需要访问的表
2)根据执行计划,访问表中的数据
3)执行各种数据操作,如扫描、索引查找、聚合计算等
4)将结果集返回给客户端
4.结果集返回:执行完成后,MySQL 会将结果集返回给客户端
ps:可能执行计划选择不是最优的,需要指定索引:FORCE INDEX force index
linux优化
1.磁盘读写慢怎么排查?
1.top命令查看硬盘是否繁忙,查看第三行 wa值,称为CPU等待IO完成的时间百分比。如果比较大(大于1),说明当前硬盘繁忙,有大量的读写操作。
2.iotop查看哪些进程占用硬盘的带宽大。
iotop:展示硬盘读写操作进程的排行
3.lsof -p PID 查看进程打开了哪些文件,定位到进程到底在读写哪个文件占用大量的磁盘带宽
4.badblocks 检查硬盘分区有没有坏道
2.内存持续飙高,怎么排查?
1.free -m:查看内存使用情况
2.top,htop:查看哪些进程占用内存高
3.进程高的排查,如果进程访问量低,内存占用率高,基本是bug,需要检查代码
4.正常访问量,内存占用过高。需要增加服务器的配置
系统所有内存占用满了会出现什么情况:
第一种:没有启动swap分区,系统触发OOM,杀掉在运行的一个或多个进程来释放内存。
第二种:启用了swap分区
swap分区作用:当物理内存不足时,将内存中的数据交换到swap分区中进行处理,swap分区本身借助硬盘实现,相比内存的性能差很多
3.CPU持续飙升怎么排查?
1.htop查看cpu,内存等指标,判断哪些进程cup使用率高
2.perf top -p PID
perf:系统性能分析工具,,分析进行有哪些系统调用,模块调用,cup占用比
3.top -H -p PID :查看进程中的线程。
程序可能情况:频繁GC,死循环调用,死锁
es优化
1.分片和副本分片作用?
一般创建索引时一起创建分片和副本,修改配置
//创建索引
PUT /my_temp_index
{
"settings": {
"number_of_shards" : 5, //每个索引的主分片数,默认值是 5。这个配置在索引创建后不能修改
"number_of_replicas" : 1 //每个主分片的副本数,默认值是 1 。对于活动的索引库,这个配置可以随时修改。
}
}
如果想要修改分片数:创建新的索引,数据然后导入
分片作用:
1.提高数据的存储容量:数据存储,将数据分散存储在集群的多个节点上。
2.提高查询性能和吞吐量:并行处理数据,每个分片可以独立搜索聚合等操作。
副本分片作用:
1.支持故障转移:是主分片的副本,可以用于数据恢复
2.提高查询效率:负载均衡分配给主分片和副本分片
2.es查询搜索过程?
数据:你今天早上吃饭了吗?(假如原数据文档id=4)
分词器分布:你(文档4),今天(文档4),早上(文档4),吃饭(文档4)
查询步骤:
1.查询词分析:转换成 Elasticsearch 可理解的形式
2.插叙倒排索引:定位到文档ID和所在分片ID
3.定位目标分片:根据文档 ID 和分片 ID,确定查询应该路由到哪些分片上执行。
4.发送查询,目标分片列表:并行地将查询请求发送到相应的分片副本上执行
5.执行查询,目标分片列表:在每个目标分片上,执行实际的查询逻辑,从文档中提取所需数据。(比如用户可能只需要文档中的某些字段,而不是整个文档,还有聚合查询)
6.合并查询结果:将来自不同分片的部分结果进行归并排序、去重等操作。
7.结果优化和返回:对合并后的结果进行进一步优化,如分页、高亮显示等,最终返回给用户。
eg查询:吃饭-->倒排索引查到为文档ID=4,分片Id=1-->找到相关分片-->多个分片内部搜索-->多个分片搜索结果合并排序-->结果优化(去重,结果截取,高亮显示等)-->结果返回(命中的文档id,相关搜索结果)
如果分片有多个副本分片内部搜索:
它会根据以下几个因素来决定选择哪个分片进行查询:
1.副本可用性,避免使用可能出现故障的分片
2.负载均衡,会考虑各个节点的当前负载情况,尽量将查询请求分散到负载较低的节点上。这样可以避免单个节点过载,提高整体查询性能
3.就近原则,如果有多个副本分片,会优先选择最近的分片。这样可以减少网络延迟,提高查询响应速度
4.一致性要求,对于需要强一致性的查询,会选择主分片进行查询,以确保读取到最新的数据
3.es写入/修改过程?
1.客户端发起写入/修改请求
2.并行写入主分片,写入倒排索引
写入倒排索引:
1.分词器工作:进行分词,词提干等操作。分析后的结果会形成倒排索引的基础数据(包含),写入倒排索引
写入主分片:
1.首先会将文档数据写入到主分片的内存缓冲区中
2.内存缓冲区定时刷新(默认1秒),将主分片的内存缓冲区中的数据刷新到磁盘上,这个过程叫做 refresh
3.复制到副本分片:副本分片会独立执行相同的写入操作,确保数据的一致性
4.什么是倒排索引?
倒排索引,是分词之后单独存储的一个索引。用于查询的索引,相当于mysql的索引文件,先查询这个索引文件。
存储的数据包含文档id,分片id。
查询时,根据文档id,分片id快速定位到原数据
5.倒排索引中的"倒排"是什么意思?
简单来说,所谓"倒排"就是将文档中的单词和该单词出现的文档 ID 对应起来,形成一个"倒过来"的索引结构。
具体来说:
1.正向索引
在正向索引中,索引结构是以文档为中心的。即索引记录了每个文档包含哪些单词。
2.倒排索引
而在倒排索引中,索引结构是以单词为中心的。即索引记录了每个单词出现在哪些文档中。
3.倒排索引的优势
这种"倒过来"的索引结构,可以更高效地支持全文搜索。当用户搜索一个单词时,只需要查找这个单词在倒排索引中的记录,就可以快速找到包含这个单词的所有文档。
6.es的慢日志查询
1.如果您正在使用 Kibana,可以在 Kibana 中查看和可视化慢日志的信息
2.也可以通过 Logstash 插件或者日志引擎来查看
7.es优化策略
1.优化查询:满日志分析,优化查询query
2.优化索引:给查询的filter增加索引
3.调整分片数、副本数,使用合适的分词器。利用索引性能分析工具 Elastic Index Explorer 诊断索引问题
4.调整硬件资源:如果查询和索引仍然很慢,可以考虑增加 CPU、内存等硬件资源。
5.优化Elasticsearch配置:调整 Elasticsearch 的各项配置参数,如线程池大小、缓存策略等,以获得最佳性能
6.监控 Elasticsearch 集群:监控各项指标,包括CPU、内存、磁盘、网络
mongo优化
1.优化
1.索引优化:建立合适的索引
2.查询优化:
1)尽量使用精确匹配查询,避免全集合扫描
2)合理使用投影控制返回字段,和限制limit
3.分片优化:
1)设置合适的分片数量,副本数量
2.mongo的分片与副本作用?
mongo的分片与副本功能与es的分片和副本类似。都是增加查询效率,和数据恢复
分片作用:
1.提高数据的存储容量:数据存储,将数据分散存储在集群的多个节点上。
2.提高查询性能和吞吐量:并行处理数据,每个分片可以独立搜索聚合等操作。
副本分片作用:
1.支持故障转移:是主分片的副本,可以用于数据恢复
2.提高查询效率:负载均衡分配给主分片和副本分片
3.如何增加/减少分片数量?
增加分片数量:当访问量增加时,可以考虑增加分片数量
命令:sh.addShard() 会在分片集群中添加新的分片服务器
ps:添加新分片后,MongoDB 会自动将部分数据迁移到新的分片上,以均衡集群负载
减少分片数量:如果数据量或访问量降低,可以考虑减少分片的数量,以节省资源和简化管理
命令:sh.removeShard() 会从分片集群中移除不需要的分片服务器
ps:在移除分片之前,需要先将该分片上的数据迁移到其他分片,以确保数据完整性
4.如何查看mongo的满日志
MongoDB 配置文件中设置 slowms 参数,表示查询执行时间超过该阈值(毫秒)的查询会被记录到日志中。
例如: slowms=100 表示记录所有执行时间超过 100 毫秒的查询。
查看慢查询日志:
可以直接查看 MongoDB 的日志文件,日志文件位置可以在配置文件中找到。
命令查询:需要权限,和开启db.setProfilingLevel(2)
db.currentOp({"ns": /\$/}).appliesToWriteOp
db.getProfilingLevel() // 查看当前的性能分析级别
db.setProfilingLevel(2) // 设置性能分析级别为"慢查询"(slowest)
db.system.profile.find().sort({$natural:-1}).limit(10) // 查看最近10条慢查询记录
选择了IT,必定终身学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号