redis底层数据结构实现原理 1-4
redis底层数据结构实现原理
1.hash
底层数据结构:数组+单链表
数组:称为buckets,数组的每一个索引都是一个指针,指向单链表。数组大小就是hash表的容量
单链表:hash冲突,单链表就会变长。
单链表存储:key+value+next
key:hash的健
value:值
next:下一个节点指针
hash函数:根据key计算出hash值,hash值就是数组的索引
插入过程:
1.根据key使用hash函数计算hash值
2.hash值就是数据的索引
3.根据索引找到数组的指针,指针指向的是链表的头节点
4.链表中写入key,value,next。如果链表中有值(证明hash冲突),则写入链表的下一个节点
查找过程:
1.1.根据key使用hash函数计算hash值
2.hash值就是数据的索引
3.根据索引找到数组的指针,指针指向的是链表的头节点
4.从链表的头节点开始遍历,比较key是否相等。相等就返回value,不相等就链表的next比较
2.zset集合的跳表
zset原理:有序集合,上层单链表,底层双链表。
跳表查询:跳表可以当做优先队列
基础层:最下层双链表存储数据
上层链表:上层索引链表,平衡二叉搜索树,与mysql索引树类似,插入新元素时需要重新梳理索引树
重新梳理上层链表:新的元素会增加,有些元素会删除(只是标记,惰性更新)
惰性更新
Redis 不会在每次插入或删除时就立即更新上层链表。
而是采取一种"等待时机"的策略,只有在查询时才会触发上层链表的更新。
这样可以把多次小的更新合并成一次较大的更新,提高效率。
跳表查询,skiplist

在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
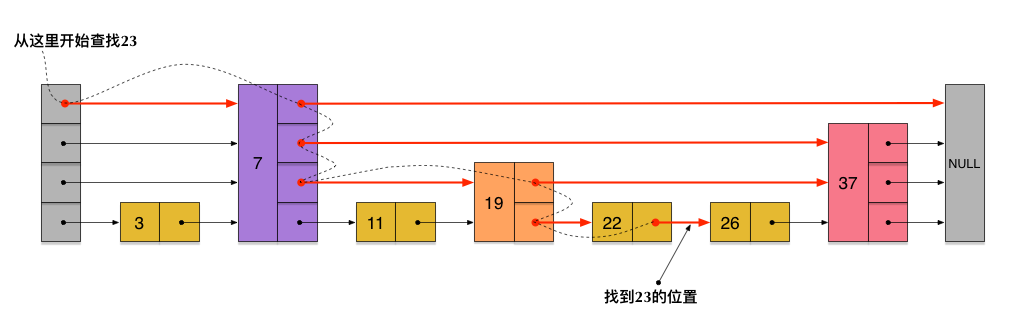
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半,(上图中是7, 19, 26),现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:见下图
查找23:

23首先和7比较,再和19比较,比它们都大,继续向后比较。
但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果我们还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
3.lru实现原理
lru:最早未使用的淘汰
底层数据结构:双向链表+hash
双向链表:链表的头部存放最近访问的元素,尾部存放最久未访问的元素。每个节点:prev、value 和 next。
hash:存数据储健值对,字典的键是 key,值是链表中对应节点的地址
lru淘汰过程:
1.当有新的元素需要加入时,会先查询字典,看该 key 是否已经存在。
2.如果存在,则将对应节点从链表中删除,然后插入到链表头部。
3.如果不存在,则创建一个新节点插入到链表头部,同时在字典中添加映射关系。
4.如果内存使用超出上限,则删除链表尾部(最久未访问)的节点,并在字典中删除对应的键值对
4.list列表
底层数据结构:双链表,每个节点prev、value 和 next
Redis 在链表的头部和尾部分别维护了两个指针,用于快速访问链表的首尾元素。
选择了IT,必定终身学习

