kafka面试题整理 1-31
目录
- 1.kafka数据可靠性怎么保证?ack
- 2.Kafka 中的 ISR是什么?AR是什么?
- 3.Kafka中数据一致性怎么保证?HW、LEO 等分别代表什么?
- 4.Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
- 5.Kafka生产者客户端的整体结构是什么样子的?使用了几个线程来处理?分别是什么?
- 6.“消费者组中的消费者个数如果超过 topic 的分区,那么就会有消费者消费不到数据”这句话是否正确?Kafka消费能力不足怎么处理?
- 7.消费者提交消费位移时提交的是当前消费到的最新消息的 offset 还是 offset+1?
- 8.有哪些情况会造成重复消费消息?
- 9.有哪些情况会造成消息漏消费?
- 10.当你使用 kafka-topics.sh 创建(删除)了一个 topic 之后,Kafka 背后会执行什么逻辑?
- 11.topic 的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
- 12.topic 的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
- 13.Kafka 有内部的 topic 吗?如果有是什么?有什么所用?offset维护
- 14.Kafka 分区分配的概念?
- 15.简述 Kafka 的日志目录结构?
- 16.如果我指定了一个 offset,Kafka Controller 怎么查找到对应的消息?
- 17.聊一聊 Kafka Controller 的作用?
- 18.Kafka 中有那些地方需要选举?这些地方的选举策略又有哪些?
- 19.失效副本是指什么?有那些应对措施?
- 20.Kafka 的哪些设计让它有如此高的性能?
- 21.kafka可以脱离zookeeper单独使用吗?为什么?
- 22.kafka有几种数据保留的策略?
- 23.什么情况会导致kafka运行变慢?
- 24.为什么要用消息队列?
- 25.为什么选择kafka?不选择RabbitMQ?
- 26.kafka为什么要分区?
- 27.Kafka中是怎么体现消息顺序性的?
- 28.kafka如何增加单条日志传输大小?
- 29.Exactly Once(既不重复也不丢失)语义?启动幂等性?
- 30.RabbitMQ与kafka业务选型?
- 31.kafka为什么快?
1.kafka数据可靠性怎么保证?ack
topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。所以引出ack机制
生产者:发送消息ack确认机制
消费者:消费消息offset机制
acks:大白话
0:生产者不接收返回值(leader挂或不挂都可能丢失数据)
1:leader收到消息后,返回ack(leader挂了会丢失数据)
-1:等待ISR集合中全部收到数据,返回ack。(leader挂了,可能重复数据)
2.Kafka 中的 ISR是什么?AR是什么?
ISR:与leader保持同步的follower集合
AR:分区的所有副本
当ack=-1时,kafka全部完成同步才发送ack:
设想以下情景:leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ack。这个问题怎么解决呢?
Leader维护了一个动态的in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给follower发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由
replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。
3.Kafka中数据一致性怎么保证?HW、LEO 等分别代表什么?
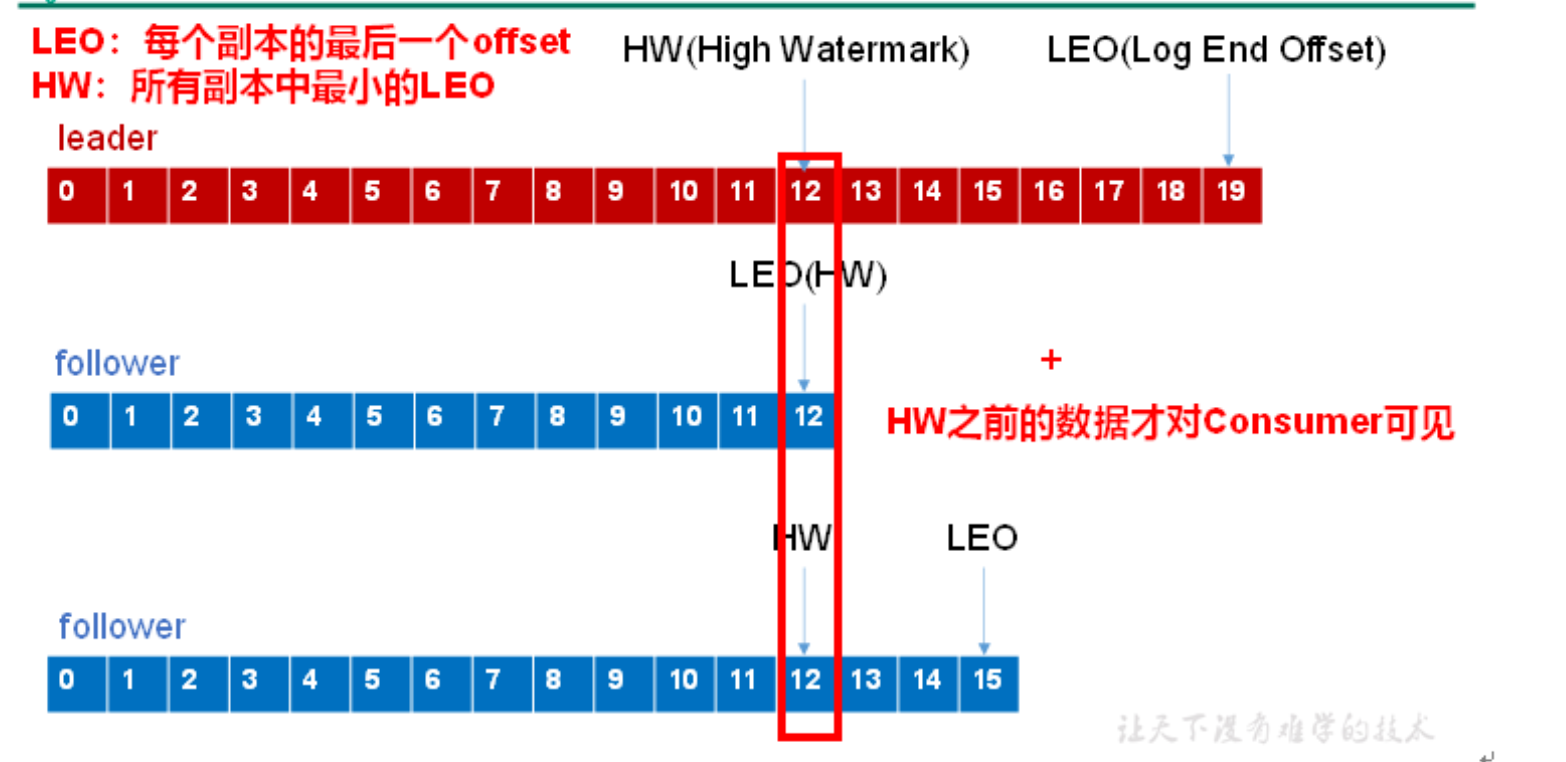
LEO:每个副本的最后条消息的offset
HW:一个分区中所有副本最小的offset
HW作用:控制所有副本数据一致性
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
eg:
比如leader挂了,此时选了其中一个follower当leader。此时hw=12,通知其他的副本以新的leader的offset开始同步,多退少补。实现所有副本数据一致性。
4.Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
处理顺序:拦截器-->序列化器-->分区器
分区器:hash计算分区分区号,决定写入的分区
序列化器:生产者把对象转换成字节数组才能通过网络发送给Kafka,消费者需要反序列化
拦截器:在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等
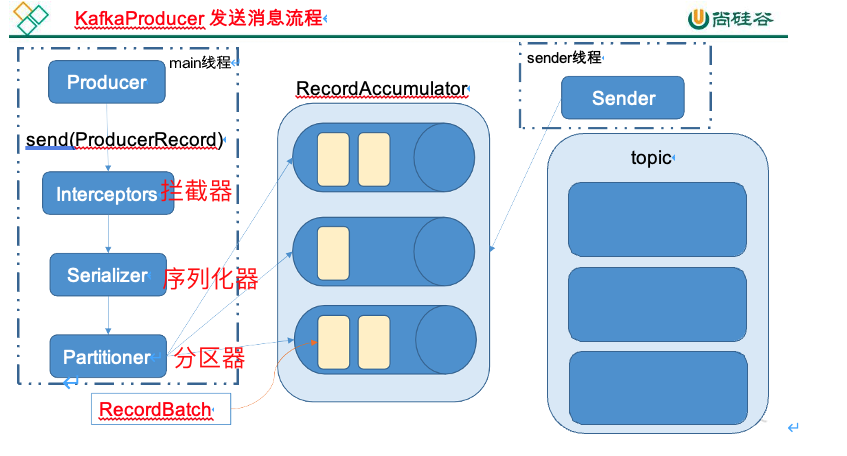
5.Kafka生产者客户端的整体结构是什么样子的?使用了几个线程来处理?分别是什么?
2个线程,一个mian线程处理数据,走拦截器,序列化器,分区器。一个send线程,真正的发送数据
6.“消费者组中的消费者个数如果超过 topic 的分区,那么就会有消费者消费不到数据”这句话是否正确?Kafka消费能力不足怎么处理?
正确。
一个分区只能被同一个消费组的一个消费者消费,如果想要一个分区被多个消费者消费,可以使用多个消费者组
经测试:一个消费者组下的消费者数量<=topic分区数
Kafka消费能力不足怎么处理:
如果是消费能力不足:
1.增加分区数,提升消费者数量。消费者数=分区数
如果是下游数据处理能力不足:
1.提高每批次拉取的数量
2.提升消息处理能力,业务优化,代码优化
7.消费者提交消费位移时提交的是当前消费到的最新消息的 offset 还是 offset+1?
offset+1
终端测试:创建一个topic,一个生产者,一个消费者。生产一条数据,查看zookeeper数据:
命令:get /consumers/console-consumer-11235/offsets/topicName/0
结果:offset=1。
结论:没有消费数据之前,分区offset都是0,消费一条数据offset变为1。说明是offset+1
8.有哪些情况会造成重复消费消息?
1.第一步先处理数据,第二步在再提交offset,有肯能重复消费。因为第一步处理完数据,第二步可能没有提交offset
2.不同消费者组的消费者,消费相同的topic。因为一个消费者组下只能1个消费者消费同一个分区,这里不同组,所以可以消费这个分区,就造成重复消费情况
处理方式:
合理分配分区与消费者,消费者组。
1.一个topic,10个分区,1个消费者组下10个消费者,一一对应一个分区消费。这种情况就不会造成重复消费,因为每一个消费者维护自己的一个offset,然后这个分区只能由这个消费者消费,物理上就与其他消费者隔离了,就不会造成重复消费的情况啦
2.控制好offset提交的时间
9.有哪些情况会造成消息漏消费?
和上面问题相反。
1.第一步先提交offset,第二步再处理数据。因为提交了offset可能未处理数据。
10.当你使用 kafka-topics.sh 创建(删除)了一个 topic 之后,Kafka 背后会执行什么逻辑?
1)会在 zookeeper 中的/brokers/topics 节点下创建一个新的 topic 节点, 如:/brokers/topics/jeffTopic
2)触发 Controller 的监听程序
3)kafka Controller 负责 topic 的创建工作,并更新 metadata cache
11.topic 的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
分区数可以增加
--alter参数修改
[root@sg-15 bin]# ./kafka-topics.sh --zookeeper 192.168.0.215:2181 --topic topic_name --alter --partitions 4
12.topic 的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
分区数不可以减少,因为产生的数据没法处理。
我们可以使用 bin/kafka-topics.sh 命令对 Kafka 增加 Kafka 的分区数据,但是 Kafka 不支持减少分区数。 Kafka 分区数据不支持减少是由很多原因的,比如减少的分区其数据放到哪里去?是删除,还是保留?删除的话,那么这些没消费的消息不就丢了。如果保留这些消息如何放到其他分区里面?追加到其他分区后面的话那么就破坏了 Kafka 单个分区的有序性。如果要保证删除分区数据插入到其他分区保证有序性,那么实现起来逻辑就会非常复杂。
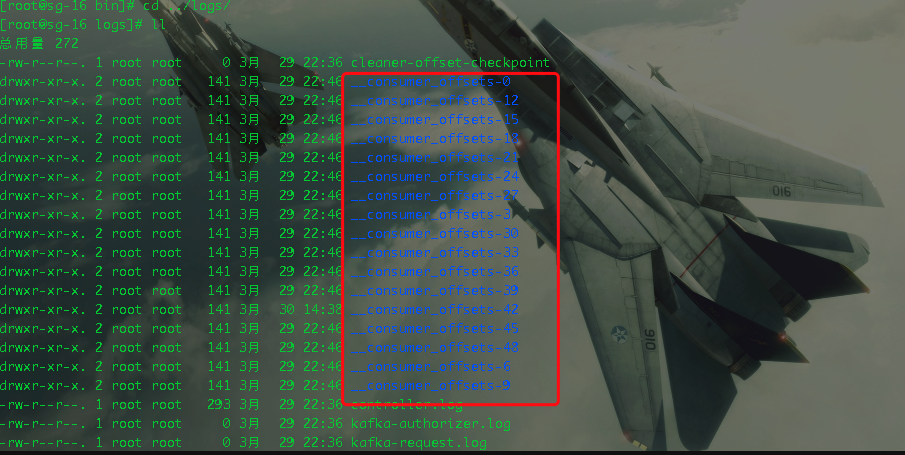
13.Kafka 有内部的 topic 吗?如果有是什么?有什么所用?offset维护
有__consumer_offsets。0.11版本之后可以不依赖于zookeeper写入offset。
作用:给消费者写入offset,写入内入的topic中
14.Kafka 分区分配的概念?
一个消费者组中有多个消费者,一个topic有多个分区,所以必然会涉及到partition的分配问题,即确定那个partition 由哪个consumer来消费。
两种方式:1)RoundRobin 2)Range
Range:面向topic处理,分配给订阅了该主题的人
RoundRobin:面向消费者组处理,分配给某个消费者组
15.简述 Kafka 的日志目录结构?

每个分区对应一个文件夹,文件夹的命名为topic-0,topic-1,内部为.log和.index文件
.log:存放数据的文件
.index:存放索引信息文件,索引文件中的元数据指向对应数据文件中message的物理偏移地址。
通过index文件快速定位到消费的位置:
第一步:通过二分查找发定位到.index文件
第二步:扫描index文件,找到数据在.log文件中具体的物理偏移量
16.如果我指定了一个 offset,Kafka Controller 怎么查找到对应的消息?
通过index文件快速定位到消费的位置:
第一步:通过二分查找发定位到.index文件
第二步:扫描index文件,找到数据在.log文件中具体的物理偏移量
17.聊一聊 Kafka Controller 的作用?
Controller:
1.负责管理集群Broker的上下线,所有Topic的分区副本分配和leader选举等工作
2.直接跟zookeeper打交道,元数据更新都由Controller获取,并通知其他的kafka节点保持一致
18.Kafka 中有那些地方需要选举?这些地方的选举策略又有哪些?
1.Controller:通过抢资源方式,谁先抢到谁就是Controller。
2.ISR中的leader:通过isr选举:
0.9版本之前(老版本):2个条件,与之前leader同步时间最短,同步消息数最多的就是新leader。
0.9版本之后(新版本):1个条件,与之前leader同步时间最短的就是新leader。
19.失效副本是指什么?有那些应对措施?
ISR中的follower长时间未向leader同步数据,则该follower将被踢出ISR。
Leader发生故障之后,就会从ISR中选举新的leader。
20.Kafka 的哪些设计让它有如此高的性能?
kafka高效的原因有:
1.分布式的(有分区概率,可以并发读写,但是单机器效率也很高)
2.顺序读写磁盘
3.零复制技术(零拷贝技术)
21.kafka可以脱离zookeeper单独使用吗?为什么?
2.8版本以后可以脱离zookeeper单独使用。
2.8版本以前kafka不能脱离zookeeper单独使用,因为kafka使用zookeeper管理和协调kafka的节点服务器。
22.kafka有几种数据保留的策略?
两种:
1.按照过期时间保留:log.retention.hours=168 //超过168小时就清理数据
2.按照存储的消息大小保留:忘记了,不常用
23.什么情况会导致kafka运行变慢?
1.cpu性能瓶颈
2.磁盘读写瓶颈
3.网络瓶颈
24.为什么要用消息队列?
消息队列主要作用:
1.解偶
2.削峰,缓冲
3.异步
4.暂存数据
25.为什么选择kafka?不选择RabbitMQ?
根据业务场景选择:
RabbitMQ:
1.交易数据,金融场景。具有较高的严谨性,数据丢失的可能性更小,同时具备更高的实时性;
2.消息应当尽可能的小,处理关键且可靠消息
kafka:
1.高吞吐量,虽然可以通过策略实现数据不丢失,但从严谨性角度来讲,大不如rabbitmq;
26.kafka为什么要分区?
方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了。
可以提高并发,因为可以以Partition为单位读写。
27.Kafka中是怎么体现消息顺序性的?
分区内消息是有序的。
每个分区内,每条消息都有一个offset,故只能保证分区内有序
28.kafka如何增加单条日志传输大小?
修改配置文件:server.properties
replica.fetch.max.bytes: 1048576 broker可复制的消息的最大字节数, 默认为1M
message.max.bytes: 1000012 kafka 会接收单个消息size的最大限制, 默认为1M左右
message.max.bytes必须小于等于replica.fetch.max.bytes,否则就会导致replica之间数据同步失败
29.Exactly Once(既不重复也不丢失)语义?启动幂等性?
acks:0 At Most Once(最多一次),生产者发送数据最多发送一次,不接受ack。可以保证数据不重复,但是不能保证数据不丢失。
acks:-1 At least Once(最少一次),生产者发送数据最少一次,接受到ack为止,可能多次发送,造成数据重复。可以保证不丢数据,但是不能保证数据不重复。
Exactly Once(既不重复也不丢失)语义:0.11版本以前kafka对此无能为力,只能保证数据不丢失,然后在下游(消费者)对数据做全局去重,对性能造成很大的影响。
0.11 版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指Producer 不论向 Server 发送多少次重复数据,Server 端都只会持久化一条。幂等性结合 At Least Once 语义,就构成了Kafka 的Exactly Once 语义。
即:At Least Once + 幂等性 = Exactly Once
启动幂等性:将 Producer 的参数中 enable.idompotence 设置为 true 即可
30.RabbitMQ与kafka业务选型?
选择 RabbitMQ 的典型业务场景:
1.需要可靠的消息传递,确保消息不会丢失,支持事务性消息。
2.需要消息的顺序性,比如消息处理需要严格按照先进先出的顺序。***
3.需要消息的实时性较强,对消息延迟比较敏感。***
4.需要支持多种消息协议,如 AMQP、MQTT、STOMP 等。
5.需要灵活的消息路由和交换机机制,支持复杂的消息分发。
6.应用规模较小到中等,消息量不太大。
选择 Kafka 的典型业务场景:
1.海量数据处理,每天需要处理数TB或PB级别的数据。**
2.需要高吞吐量和低延迟,每秒可处理数十万条消息。***
3.数据处理的实时性要求不太高,可接受几秒到几分钟的延迟。***
4.数据分析和离线计算是主要目的,而不是实时处理。***
5.需要消息的持久化和备份,保证数据不会丢失。***
6.应用规模较大,消息量巨大。***
31.kafka为什么快?
kafka为什么快:
1.高效的持久化机制,Kafka使用了顺序写磁盘的方式进行数据持久化
2.零拷贝技术:Kafka使用了零拷贝(Zero-copy)技术来减少数据在内存和网络之间的复制次数.在传统的数据传输中,数据需要从应用程序的内存复制到内核缓冲区,然后再从内核缓冲区复制到网络协议栈,而在接收端也需要进行相同的复制操作。而通过使用零拷贝技术,Kafka可以直接在内核缓冲区和网络协议栈之间传输数据,避免了不必要的数据复制,从而提高了数据传输的效率。
3.分布式架构和并行处理:Kafka采用了分布式架构,可以将消息分散到多个分区和多个服务器上进行并行处理。这种并行处理允许多个消费者并发地读取消息,并且可以水平扩展以处理更高的吞吐量。同时,Kafka还支持分区级别的并行处理,允许多个生产者并发地向不同的分区写入消息,提高了写入吞吐量。
4.高效的索引和批处理:Kafka使用了基于索引的机制来保证高效的消息查找和检索。每个分区都有一个索引文件,可以根据消息的偏移量快速定位到消息的位置。此外,Kafka还支持批量处理(batch processing),可以将多个消息一起批量处理和传输,减少了网络开销和系统调用的次数。
选择了IT,必定终身学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号