场景设计1-15
目录
- 1.如果让你设计mysql高可用方案的话,你会优先考虑哪些方面?
- 2.抖音评论系统怎么设计,如果加入好友关系呢?
- 3.怎么设计一个短链地址?要考虑跨机房部署问题
- 4.统计用户在线最大峰值和人数,要精确到秒
- 5.微博点赞设计分析
- 6.如何“扛住100亿次请求”的春晚红包系统
- 7.你怎么防止优惠券有人重复刷?
- 8.分布式系统一致性
- 9.让你设计一个web框架,你要怎么设计,说一下步骤
- 10.orm的设计思路
- 11.怎么搞一个并发服务程序?
- 12.常用的设计模式
- 13.异地灾备与异地多活了解吗?如果让你来实现的话你怎么做?说说你的实现思路
- 14.有几台机器存储着几亿淘宝搜索日志,你只有一台2G的电脑,怎么选出搜索热度最高的十个?
- 15.分库分表?使用场景?
1.如果让你设计mysql高可用方案的话,你会优先考虑哪些方面?
一、MySQL高可用架构应该考虑什么?
- 对业务的了解,需要考虑业务对数据库一致性要求的敏感程度,切换过程中是否有事务会丢失
- 对于基础设施的了解,需要了解基础设施的高可用的架构。例如 单网线,单电源等情况
- 对于数据库故障时间掌握,业务方最多能容忍时间范围,因为高可用切换导致的应用不可用时间
- 需要了解主流的高可用的优缺点:例如 MHA/PXC/MGR 等。
- 考虑多IDC多副本分布,支持IDC级别节点全部掉线后,业务可以切到另一个机房
二、你认为应该如何设计?
- 基础层 和基础运维部门配合,了解和避免网络/ 硬盘/ 电源等是否会出现单点故障
- 应用层 和应用开发同学配合,在关键业务中记录SQL日志,可以做到即使切换,出现丢事务的情况,也可以通过手工补的方式保证数据一致性,例如:交易型的业务引入状态机,事务状态,应对数据库切换后事务重做
- 业务层 了解自己的应用,根据不同的应用制定合理的高可用策略。
- 单机多实例 环境及基于虚拟机或容器的设计不能分布在同一台物理机上。
- 最终大招在数据库不可用 ,可以把已提交的事务先存储到队列或者其他位置,等数据库恢复,重新应用
三、mysql高可用方案
第一种:一对一。小型
第二种:一对多。中型。所有从master复制到node,master压力大
第三种:一对一对多。一个主对一个从,一个从对多个从。分担读压力,相对安全
2.抖音评论系统怎么设计,如果加入好友关系呢?
评论为树状结构,层层嵌套,每个评论下面挂着若干子评论
评论两种方案:
方案一:单表设计,每个评论都有一个parent_id指向父评论
方案二:分表设计,评论为一张表,子评论为一张表
人际关系可以概况成以下四种:
1.关注我的
2.我关注的
3.互相关注的
4.互不关注的
3.怎么设计一个短链地址?要考虑跨机房部署问题
考虑跨机房部署:因为雪花算法生成id,根据时间生成。可能存在机器时钟回拨的问题,导致id重复
方案一:无需考虑跨机房部署,hash算法,问题:hash冲突
利用MurmurHash非加密哈希,比md5快十几倍。
长链做 MurmurHash 计算,得到的哈希值为 3002604296,于是我们现在得到的短链为 固定短链域名+哈希值 = www.baidu/1760305916
import "fmt"
import "github.com/spaolacci/murmur3"
func main() {
b := murmur3.Sum32WithSeed([]byte("www.baidu/abcdd.xxxx.com"),0x1234ABCD)
fmt.Println(b) //3929151817
}
如何缩短域名?
MurmurHash之后的数字为10进制,可以把数字转成62进制
www.baidu/4hUjSp
方案二:发号器。来一个链接发一个号。跨机房的话,redis k-v存起来。校验。或者布隆过滤器,还是会hash冲突。
解决方法:
1.用Redis做自增id生成器,性能高,但要考虑持久性的问题;
2.雪花算法做成一个服务,调用即可
短链301和302区别?
301,代表 永久重定向,也就是说第一次请求拿到长链接后,下次浏览器再去请求短链的话,不会向短网址服务器请求了,而是直接从浏览器的缓存里拿,这样在 server 层面就无法获取到短网址的点击数了,如果这个链接刚好是某个活动的链接,也就无法分析此活动的效果。所以我们一般不采用 301。
302,代表 临时重定向,也就是说每次去请求短链都会去请求短网址服务器(除非响应中用 Cache-Control 或 Expired 暗示浏览器缓存),这样就便于 server 统计点击数,所以虽然用 302 会给 server 增加一点压力,但在数据异常重要的今天,这点代码是值得的,所以推荐使用 302。
4.统计用户在线最大峰值和人数,要精确到秒
使用redis有序集合:上线+1,下线-1
//当前在线人数
rdb.ZIncrBy("onlineUsers",1,"count") // 人数自增+1
rdb.ZIncrBy("onlineUsers",-1,"count") // 人数自减-1
整理需求:如果需要知道用户在线时间,及在线时间段人数,存时间戳
// 上线
err := rdb.Do("ZADD", "online", 1644375460, "user1")
if err != nil {
fmt.Println(err)
}
// 离线
err := rdb.Do("ZADD", "offline", 1644375460, "user1")
if err != nil {
fmt.Println(err)
}
这样可以根据工作日,及时间段来知道用户在线的情况
5.微博点赞设计分析
1.用户点赞,本地统计,先保证自己立马看到变化
2.点赞事件发送至消息中心,kafka或者mq等。user_id,给某个微博id点赞
3.事件流处理,试试增量统计到redis,定时同步到mysql,或者es。或者时序性数据库tsdb
6.如何“扛住100亿次请求”的春晚红包系统
QPS:Queries per second 每秒的请求数目。
PPS:Packets per second 每秒数据包数目。
摇红包:客户端发出一个摇红包的请求,如果系统有红包就会返回,用户获得红包。
发红包:产生一个红包里面含有一定金额,红包指定数个用户,每个用户会收到红包信息,用户可以发送拆红包的请求,获取其中的部分金额。
通过文章我们可以了解到接入服务器638台,服务上限大概是14.3亿用户, 所以单机负载的用户上限大概是14.3亿/638台=228万用户/台。
但是目前中国肯定不会有14亿用户同时在线,2016年微信用户大概是8亿,月活在5.4 亿左右。所以在2015年春节期间,虽然使用的用户会很多,但是同时在线肯定不到5.4亿。
| 服务器数量
一共有638台服务器,按照正常运维设计,我相信所有服务器不会完全上线,会有一定的硬件冗余,来防止突发硬件故障。假设一共有600台接入服务器。
| 单机需要支持的负载数
每台服务器支持的用户数:5.4亿/600 = 90万。也就是平均单机支持90万用户。如果真实情况比90万更多,则模拟的情况可能会有偏差,但是我认为QPS在这个实验中更重要。
| 单机峰值QPS
文章中明确表示为1400万QPS。这个数值是非常高的,但是因为有600台服务器存在,所以单机的QPS为 1400万/600= 约为2.3万QPS,文章曾经提及系统可以支持4000万QPS,那么系统的QPS 至少要到4000万/600 = 约为 6.6万, 这个数值大约是目前的3倍,短期来看并不会被触及。但是我相信应该做过相应的压力测试。
| 发放红包
文中提到系统以5万个每秒的下发速度,那么单机每秒下发速度50000/600=83个/秒,也就是单机系统应该保证每秒以83个的速度下发即可。
最后整体看一下 100亿次摇红包这个需求,假设它是均匀地发生在春节联欢晚会的4个小时里,那么服务器的QPS 应该是10000000000/600/3600/4.0=1157。也就是单机每秒1000多次,这个数值其实并不高。
如果完全由峰值速度1400万消化 10000000000/(1400*10000) = 714秒,也就是说只需要峰值坚持11分钟,就可以完成所有的请求。可见互联网产品的一个特点就是峰值非常高,持续时间并不会很长。
| 总结
从单台服务器看,它需要满足下面一些条件:
① 支持至少100万连接用户。
② 每秒至少能处理2.3万的QPS,这里我们把目标定得更高一些 ,分别设定到了3万和6万
③ 摇红包:支持每秒83个的速度下发放红包,也就是说每秒有2.3万次摇红包的请求,其中83个请求能摇到红包,其余的2.29万次请求会知道自己没摇到。当然客户端在收到红包以后,也需要确保客户端和服务器两边的红包数目和红包内的金额要一致。因为没有支付模块,所以我们也把要求提高一倍,达到200个红包每秒的分发速度。
7.你怎么防止优惠券有人重复刷?
领了优惠券,和用户建立token绑定关系
8.分布式系统一致性
分布式系统面临的问题:一致性。面试问到这里基本GG,很复杂。
强一致性
弱一致性
最终一致性(方案最多)
一致性理论:ACID原理,CAP原理
一致性协议:两阶段协议协议、三阶段提交协议、Paxos协议、Raft协议
说说:
1.主从同步模式
2.利用异步消息队列模式
3.补救措施
4.缓存淘汰
9.让你设计一个web框架,你要怎么设计,说一下步骤
后端:k8s,docker容器镜像,基于gin封装,contex,rpc,http,getway
运维监控:prometheus,告警睿象云(收费,提供短信,邮箱,电话,人员管理分组等服务)
前端:vue
10.orm的设计思路
orm对象关系映射,目的:操作数据库就像操作对象一样
设计步骤:
1.数据库语句的拼装(包含增删查改语句)
2.数据库查询条件的拼装
3.查询结果实体的映射
4.以上是核心部分,如多库支持,缓存语句等等都是对核心的扩展
11.怎么搞一个并发服务程序?
go从语言层面就支持并发,因为协程。
微服务模式:自定义网关转发请求,协程。数据安全的地方用锁,或者其他办法。k8s加节点机器
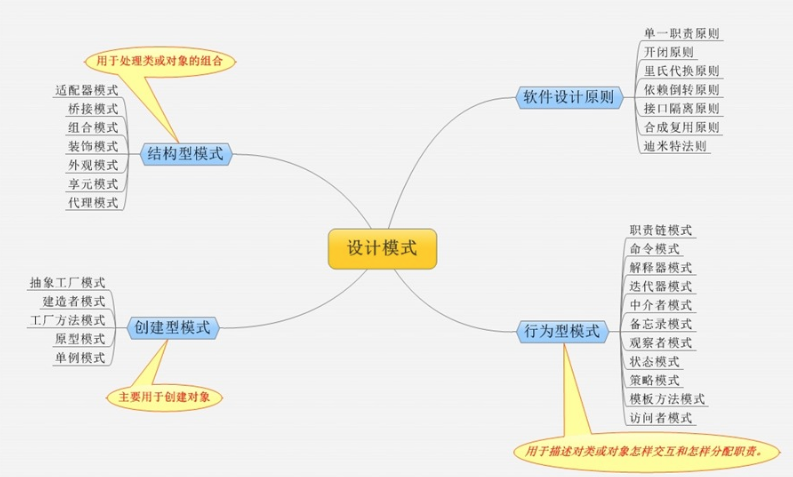
12.常用的设计模式
13.异地灾备与异地多活了解吗?如果让你来实现的话你怎么做?说说你的实现思路
异地灾备:将主数据备份到另一地,以防主数据所在低遭受灾难后无法使用。
异地多活:在不同的地点同时部署主数据,以保证系统的高可用
实现思路:使用数据同步,数据冗余技术
首先,我们可以在两个不同地点同时部署主数据,使用数据同步技术。如主从复制或异步复制,保证主从数据一致。
其次,如果主数据遭受灾害,我们可以使用数据冗余技术,如读写分离和数据镜像,在另一个地点恢复数据,以保证系统高可用性。
14.有几台机器存储着几亿淘宝搜索日志,你只有一台2G的电脑,怎么选出搜索热度最高的十个?
由于数据量极大,只有2G的内存,因此无法一次性将所有数据加载到内存中。
以下是可以考虑的解决的方案:
1.分块读取:将日志文件分成若干块,逐块读入,每块都计算出十个热度最高的搜索关键词,最终将所有关键词合并,选出热度最高的十个。
2.利用外部存储:将日志文件分割成若干份,分表存储在外部存储设备(如硬盘)上,再逐个读入,进行热度计算合并
15.分库分表?使用场景?
读写分离:读写操作不同的数据库,提高数据库的并发性
范围分库分表:将数据按照关键字的范围划分到不同的数据库表中
哈希分库分表:将数据分配到不同的数据库表中,通过哈希算法计算键值的分布情况
使用场景:
1.数据量大:数据库难以扩展时,可以使用分库分表技术提高数据库的可扩展性。
2.高并发场景
3.减少数据库单表数据大小限制
4.提高查询效率
选择了IT,必定终身学习

