pandas模块
一、简介
pandas是一个强大的Python数据分析的工具包,它是基于Numpy构建的,正因pandas的出现,让Python语言也成为使用最广泛而且强大的数据分析环境之一。

Pandas的主要功能:
- 具备对其功能的数据结构DataFrame,Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
安装方法:
!pip install pandas
引用方法:
import pandas as pd
二、Series
Series是一种类似于一维数组的对象,由一组数据和一组与之相关的数据标签(索引)组成
1、创建方法
import pandas as pd
import numpy as np
# 第一种:默认索引 0-N
pd.Series([4,5,6,7,8])
执行结果:
0 4
1 5
2 6
3 7
4 8
dtype: int64
-----------------------------------------------
# 第二种:自定义索引,index是一个索引列表,里面包含的是字符串,依然可以通过默认索引取值。
pd.Series([4,5,6,7,8],index=['a','b','c','d','e'])
执行结果:
a 4
b 5
c 6
d 7
e 8
dtype: int64
-----------------------------------------------
# 第三种:指定索引
pd.Series({"a":1,"b":2})
执行结果:
a 1
b 2
dtype: int64
-----------------------------------------------
# 第四种:创建一个值都是0的数组
pd.Series(0,index=['a','b','c'])
执行结果:
a 0
b 0
c 0
dtype: int64
-----------------------------------------------
对于Series,其实我们可以认为它是一个长度固定且有序的字典,因为它的索引和数据是按位置进行匹配的,像我们会使用字典的上下文,就肯定也会使用Series
2、缺失数据
- dropna() # 过滤掉值为NaN的行
- fill() # 填充缺失数据
- isnull() # 返回布尔数组,缺失值对应为True
- notnull() # 返回布尔数组,缺失值对应为False
NaN代表缺失值
# 第一步,创建一个字典,通过Series方式创建一个Series对象
st = {"sean":18,"yang":19,"bella":20,"cloud":21}
obj = pd.Series(st)
obj
运行结果:
sean 18
yang 19
bella 20
cloud 21
dtype: int64
------------------------------------------
# 第二步
a = {'sean','yang','cloud','rocky'} # 定义一个索引变量
------------------------------------------
#第三步
obj1 = pd.Series(st,index=a)
obj1 # 将第二步定义的a变量作为索引传入
# 运行结果:
rocky NaN
cloud 21.0
sean 18.0
yang 19.0
dtype: float64
# 因为rocky没有出现在st的键中,所以返回的是缺失值
判断缺失值,处理缺失值
通过上面的代码演示,对于缺失值已经有了一个简单的了解,接下来就来看看如何判断缺失值
# 1、是缺失值返回Ture
obj1.isnull()
运行结果:
rocky True
cloud False
sean False
yang False
dtype: bool
# 2、不是缺失值返回Ture
obj1.notnull()
运行结果:
rocky False
cloud True
sean True
yang True
dtype: bool
# 3、过滤缺失值 # 布尔型索引
obj1[obj1.notnull()]
运行结果:
cloud 21.0
yang 19.0
sean 18.0
dtype: float64
# 4.直接舍弃缺失值所在行
数据:
sean 18.0
yang 20.0
rocky NaN
cloud 34.0
dtype: float64
s2.dropna(inplace=True) #inplace=True,直接影响原数据
执行结果:
sean 18.0
yang 20.0
cloud 34.0
dtype: float64
# 5.填充缺失值
s2.fillna(0, inplace=True) #### fillnan 使用某一个值进行填充
执行结果:
sean 18.0
yang 20.0
rocky 0.0
cloud 34.0
dtype: float64
3、索引取值
整数索引
pandas当中的整数索引对象可能会让初次接触它的人很懵逼,接下来通过代码演示:
s2 = pd.Series([1,2,3,4], index=['a', 'b', 'c', 'd'])
数据:
a 1
b 2
c 3
d 4
dtype: int64
dtype: int32
# 到这里会发现很正常,一点问题都没有,可是当使用整数索引取值的时候就会出现问题了。因为在pandas当中使用整数索引取值是优先以标签解释的,而不是下标
sr1[1]
解决方法:
- loc属性 # 以标签解释
- iloc属性 # 以下标解释
s2.iloc[1] # 以下标解释
结果:2
s2.loc['a'] # 以标签解释
结果:1
4、Series数据对齐计算
Series特性
- 从ndarray创建Series:Series(arr)
- 与标量(数字):sr * 2
- 两个Series运算
- 通用函数:np.ads(sr)
- 布尔值过滤:sr[sr>0]
- 统计函数:mean()、sum()、cumsum()
支持字典的特性:
- 从字典创建Series:Series(dic),
- In运算:'a'in sr、for x in sr
- 键索引:sr['a'],sr[['a','b','d']]
- 键切片:sr['a':'c']
- 其他函数:get('a',default=0)等
pandas在运算时,会按索引进行对齐然后计算。如果存在不同的索引,则结果的索引是两个操作数索引的并集。
sr1 = pd.Series([12,23,34], index=['c','a','d'])
sr2 = pd.Series([11,20,10], index=['d','c','a',])
sr1 + sr2
运行结果:
a 33
c 32
d 45
dtype: int64
# 可以通过这种索引对齐直接将两个Series对象进行运算
sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
sr1 + sr3
运行结果:
a 33.0
b NaN
c 32.0
d 45.0
dtype: float64
# sr1 和 sr3的索引不一致,所以最终的运行会发现b索引对应的值无法运算,就返回了NaN,一个缺失值
将两个Series对象相加时将缺失值设为0:
sr1 = pd.Series([1,2,3], index=['a','b','c'])
sr2 = pd.Series([4,5,6,7], index=['b','a','c','d'])
sr1.add(sr2,fill_value=0)
运行结果:
a 6.0
b 6.0
c 9.0
d 7.0
dtype: float64
# 将缺失值设为0,所以最后算出来b索引对应的结果为7
灵活的算术方法:add,sub,div,mul
三、DataFrame

DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引。
创建方式
创建一个DataFrame数组可以有多种方式,其中最为常用的方式就是利用包含等长度列表或Numpy数组的字典来形成DataFrame:
第一种:
pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
# 产生的DataFrame会自动为Series分配所索引,并且列会按照排序的顺序排列
运行结果:
one two
0 1 4
1 2 3
2 3 2
3 4 1
> 指定列
可以通过columns参数指定顺序排列
data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
pd.DataFrame(data,columns=['one','two'])
# 打印结果会按照columns参数指定顺序
第二种:
pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([1,2,3],index=['b','a','c'])})
运行结果:
one two
a 1 2
b 2 1
c 3 3
以上创建方法简单了解就可以,因为在实际应用当中更多是读数据,不需要自己手动创建
查看数据,获取列索引值索引
常用属性和方法:
- index 获取行索引
- columns 获取列索引
- T 转置
- columns 获取列索引
- values 获取值索引
- describe 获取快速统计
修改列索引行索引
# 第一种,修改行索引(每一行最上面字段名)
a1.columns = a1.loc[0] # 使用第一行的数据替换默认的横向索引
# 第二种
a1.columns=['Season', 'Nation', 'Winners', 'Score', 'Runners_up', 'Runners_up_Nation', 'Venue','Attendance'] # 设置列名
# 列索引
df.index = # 看情况修改即可
索引和切片
- DataFrame有行索引和列索引。
- DataFrame同样可以通过标签和位置两种方法进行索引和切片。
DataFrame使用索引切片:
- 方法1:两个中括号,先取列再取行。 df['A'][0]
- 方法2(推荐):使用loc/iloc属性,一个中括号,逗号隔开,先取行再取列。
- loc属性:解释为标签
- iloc属性:解释为下标
- 向DataFrame对象中写入值时只使用方法2
- 行/列索引部分可以是常规索引、切片、布尔值索引、花式索引任意搭配。(注意:两部分都是花式索引时结果可能与预料的不同)
四、时间对象处理
时间序列类型
- 时间戳:特定时刻
- 固定时期:如2019年1月
- 时间间隔:起始时间-结束时间
Python库:datatime
- date、time、datetime、timedelta
- dt.strftime()
- strptime()
灵活处理时间对象:dateutil包
- dateutil.parser.parse()
import dateutil
dateutil.parser.parse("2019 Jan 2nd") # 这中间的时间格式一定要是英文格式
运行结果:
datetime.datetime(2019, 1, 2, 0, 0)
成组处理时间对象:pandas
- pd.to_datetime(['2018-01-01', '2019-02-02'])
pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019'])
运行结果:
DatetimeIndex(['2018-03-01', '2019-02-03', '2019-08-12'], dtype='datetime64[ns]', freq=None) # 产生一个DatetimeIndex对象
# 转换时间索引
ind = pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019'])
sr = pd.Series([1,2,3],index=ind)
sr
运行结果:
2018-03-01 1
2019-02-03 2
2019-08-12 3
dtype: int64
通过以上方式就可以将索引转换为时间
补充:
pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019']).to_pydatetime()
运行结果:
array([datetime.datetime(2018, 3, 1, 0, 0),
datetime.datetime(2019, 2, 3, 0, 0),
datetime.datetime(2019, 8, 12, 0, 0)], dtype=object)
# 通过to_pydatetime()方法将其转换为array数组
产生时间对象数组:data_range
- start 开始时间
- end 结束时间
- periods 时间长度
- freq 时间频率,默认为'D',可选H(our),W(eek),B(usiness),S(emi-)M(onth),(min)T(es), S(econd), A(year),…
pd.date_range("2019-1-1","2019-2-2")
运行结果:
DatetimeIndex(['2019-01-01', '2019-01-02', '2019-01-03', '2019-01-04',
'2019-01-05', '2019-01-06', '2019-01-07', '2019-01-08',
'2019-01-09', '2019-01-10', '2019-01-11', '2019-01-12',
'2019-01-13', '2019-01-14', '2019-01-15', '2019-01-16',
'2019-01-17', '2019-01-18', '2019-01-19', '2019-01-20',
'2019-01-21', '2019-01-22', '2019-01-23', '2019-01-24',
'2019-01-25', '2019-01-26', '2019-01-27', '2019-01-28',
'2019-01-29', '2019-01-30', '2019-01-31', '2019-02-01',
'2019-02-02'],
dtype='datetime64[ns]', freq='D')
时间序列
时间序列就是以时间对象为索引的Series或DataFrame。datetime对象作为索引时是存储在DatetimeIndex对象中的。
# 转换时间索引
dt = pd.date_range("2019-01-01","2019-02-02")
a = pd.DataFrame({"num":pd.Series(random.randint(-100,100) for _ in range(30)),"date":dt})
# 先生成一个带有时间数据的DataFrame数组
a.index = pd.to_datetime(a["date"])
# 再通过index修改索引
特殊功能:
- 传入“年”或“年月”作为切片方式
- 传入日期范围作为切片方式
- 丰富的函数支持:resample(), strftime(), ……
- 批量转换为datetime对象:to_pydatetime()
a.resample("3D").mean() # 计算每三天的均值
a.resample("3D").sum() # 计算每三天的和
...
五、读取数据表
读取本地excel表或者csv表
import pandas as pd
import numpy as np
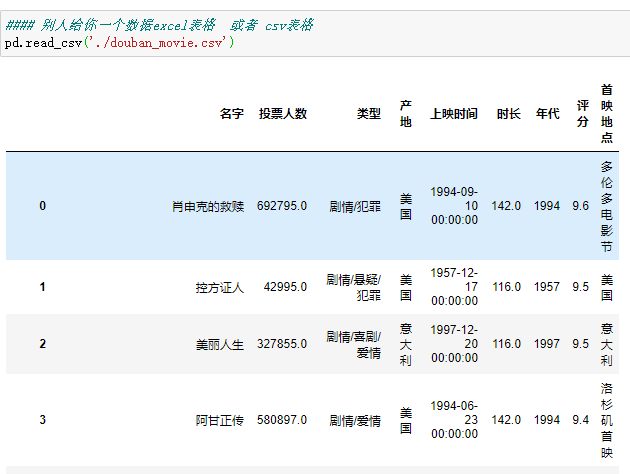
#### 别人给你一个数据excel表格 或者 csv表格
pd.read_csv('./douban_movie.csv')
爬取网络表
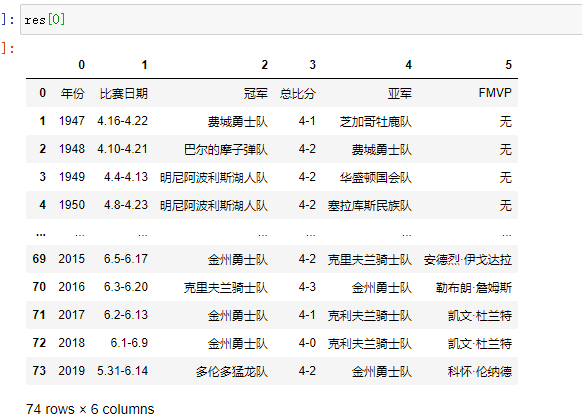
将此地址下的所有表格爬取下来
res = pd.read_html('https://baike.baidu.com/item/NBA%E6%80%BB%E5%86%A0%E5%86%9B/2173192?fr=aladdin') #### 相当于向某一个url发起请求,会将此页面下面所有的表格数据全部爬下来
res[0] # 获取爬取下来的第一张表
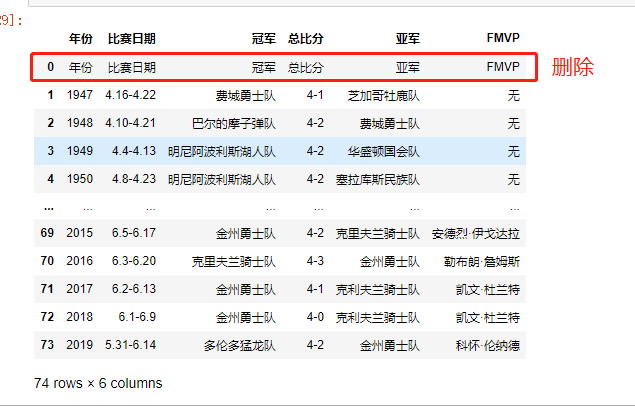
清洗数据,数据处理
df.columns = df.iloc[0] # 使用第一行的数据替换默认的横向索引
df
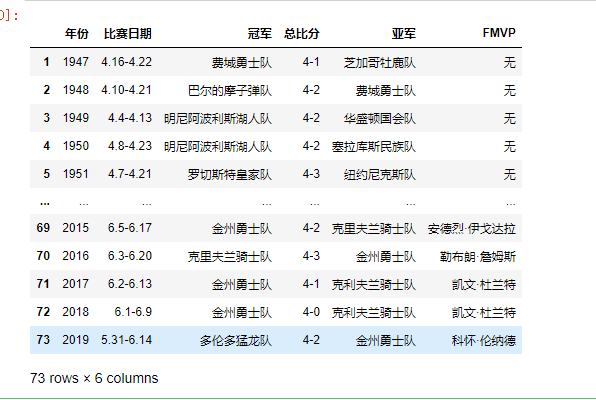
df.drop([0], inplace=True) # 删除第一行
df
分组处理数据
df.groupby('冠军').groups # 以冠军为分组

分组之后计数
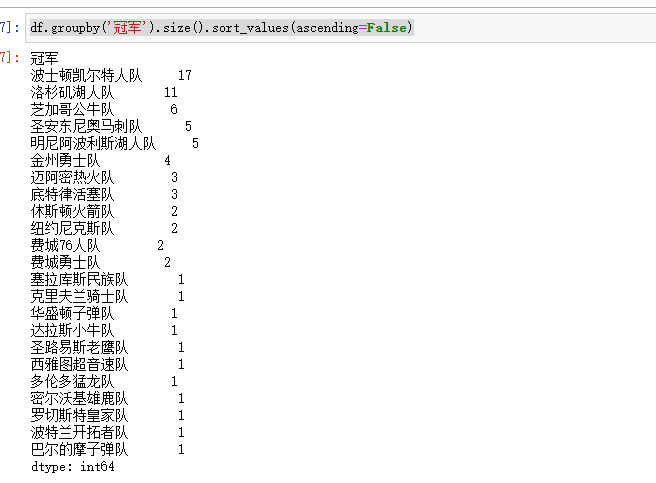
# 求每个队伍获取冠军的次数 ascending默认Ture升序排列,False降序排列
df.groupby('冠军').size().sort_values(ascending=False)
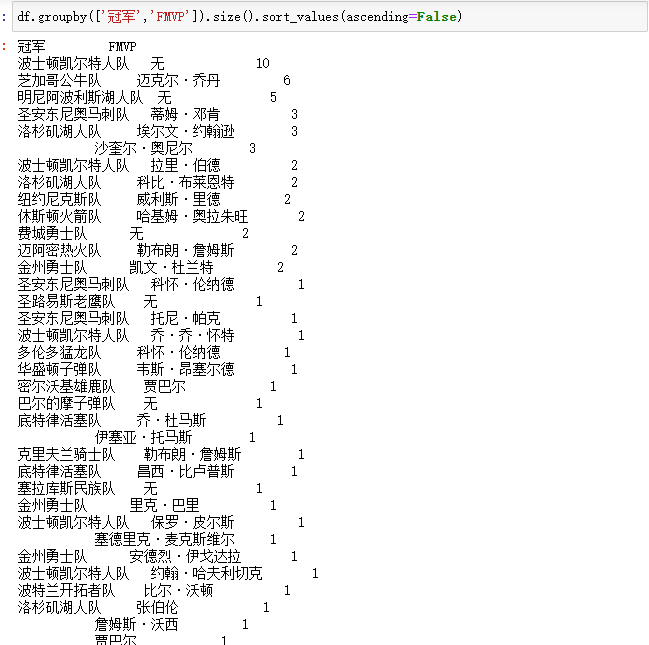
df.groupby(['冠军','FMVP']).size().sort_values(ascending=False)
聚合(组内应用某个函数)
聚合是指任何能够从数组产生标量值的数据转换过程。刚才上面的操作会发现使用GroupBy并不会直接得到一个显性的结果,而是一个中间数据,可以通过执行类似mean、count、min等计算得出结果,常见的还有一些:
| 函数名 | 描述 | |
|---|---|---|
| sum | 非NA值的和 | |
| median | 非NA值的算术中位数 | |
| std、var | 无偏(分母为n-1)标准差和方差 | |
| prod | 非NA值的积 | |
| first、last | 第一个和最后一个非NA值 |
自定义聚合函数
不仅可以使用这些常用的聚合运算,还可以自己自定义。
# 使用自定义的聚合函数,需要将其传入aggregate或者agg方法当中
def peak_to_peak(arr):
return arr.max() - arr.min()
f1.aggregate(peak_to_peak)
运行结果:
key1
x 3.378482
y 1.951752
Name: data1, dtype: float64
多函数聚合:
f1.agg(['mean','std'])
运行结果:
mean std
key1
x -0.856065 0.554386
y -0.412916 0.214939
最终得到的列就会以相应的函数命名生成一个DataFrame数组
apply

GroupBy当中自由度最高的方法就是apply,它会将待处理的对象拆分为多个片段,然后各个片段分别调用传入的函数,最后将它们组合到一起。
df.apply(
['func', 'axis=0', 'broadcast=None', 'raw=False', 'reduce=None', 'result_type=None', 'args=()', '**kwds']
func:传入一个自定义函数
axis:函数传入参数当axis=1就会把一行数据作为Series的数据
# 分析欧洲杯和欧洲冠军联赛决赛名单
import pandas as pd
url="https://en.wikipedia.org/wiki/List_of_European_Cup_and_UEFA_Champions_League_finals"
eu_champions=pd.read_html(url) # 获取数据
a1 = eu_champions[2] # 取出决赛名单
a1.columns = a1.loc[0] # 使用第一行的数据替换默认的横向索引
a1.drop(0,inplace=True) # 将第一行的数据删除
a1.drop('#',axis=1,inplace=True) # 将以#为列名的那一列删除
a1.columns=['Season', 'Nation', 'Winners', 'Score', 'Runners_up', 'Runners_up_Nation', 'Venue','Attendance'] # 设置列名
a1.tail() # 查看后五行数据
a1.drop([64,65],inplace=True) # 删除其中的缺失行以及无用行
a1
运行结果:

现在想根据分组选出Attendance列中值最高的三个。
# 先自定义一个函数
def top(df,n=3,column='Attendance'):
return df.sort_values(by=column)[-n:]
top(a1,n=3)
运行结果:

接下来,就对a1分组并且使用apply调用该函数:
a1.groupby('Nation').apply(top)
六、其他常用方法
pandas常用方法(适用Series和DataFrame)
- mean(axis=0,skipna=False)
- sum(axis=1)
- sort_index(axis, …, ascending) # 按行或列索引排序
- sort_values(by, axis, ascending) # 按值排序
- apply(func, axis=0) # 将自定义函数应用在各行或者各列上,func可返回标量或者Series
- applymap(func) # 将函数应用在DataFrame各个元素上
- map(func) # 将函数应用在Series各个元素上

