网络并发(1-50)
目录
- 1、python的底层网络交互模块有哪些?
- 2、简述OSI七层协议
- 3、什么是C/S和B/S架构?
- 4、简述TCP协议?
- 5、什么是arp协议?
- 6、tcp和UDP的区别?为什么tcp协议更可靠?
- 7、什么是局域网和广域网?
- 8、什么是socket?简述基于tcp协议的套接字通信流程?
- 9、什么是粘包?socket中造成粘包的原因是什么?那些情况会发送粘包现象?
- 10、IO多路复用的作用?
- 11、什么是防火墙以及作用?
- 12、select、poll、epoll模型的区别?
- 13、简述进程、线程、协程的区别以及应用场景?
- 14、什么是GIL全局解释器锁?
- 15、Python中如何使用线程池和进程池?
- 16、threading.local的作用?
- 17、进程之间二u和进行通讯?
- 18、什么是并发和并行?
- 19、同步和异步,阻塞和非阻塞的区别?
- 20、路由器和交换机的区别?
- 21、什么是域名解析?
- 22、如何让修改本地的hosts文件?
- 23、生产者和消费者模型应用场景?
- 24、什么是cdn服务?
- 25、有A.txt和B.txt两个文件,使用多进程和进程池的方式分别读取这两个文件?
- 26、那些是常见的TCPFlags?
- 27、tracerroute--一般使用的是哪种网络层协议?
- 28、iptabkes只是考察,根据要求写出防火墙规则?
- 29、socket套接字编程?
- 30、对于多线程,CPU密集型怎么使用?IO密集型怎么使用?
- 31、说说线程互斥锁,进程锁互斥锁?
- 32、说说守护线程?
- 33、TCP协议在每次建立断开连接时,都要在收发双方之间交换?报文
- 34、简述多进程开发中join与deamon的区别?
- 35、简述GIL对Python性能的影响?
- 36、线程、进程、协程使用场景?
- 37、简述线程死锁现象?
- 38、asynio是什么?
- 39、gevent模块是什么?
- 40、twisted框架?
- 41、什么是LVS?
- 42、什么是Nginx?
- 43、什么是keepalived?
- 44、什么是haproxy?
- 45、什么是负载均衡?
- 46、什么是rpc及应用场景?
- 47、什么是反向代理?
- 48、创建进程?
- 49、创建线程?
- 50、进程之间的通讯Queue
1、python的底层网络交互模块有哪些?
# 答案:
'''
socket, urllib,urllib3 , requests, grab, pycurl
'''
2、简述OSI七层协议
应表会传网数物
'''
应用层:HTTP,FTP,NFS
表示层:Telnet,SNMP
会话层:SMTP,DNS
传输层:TCP,UDP
网络层:IP,ICMP,ARP,
数据链路层:Ethernet,PPP,PDN,SLIP,FDDI
物理层:IEEE 802.1A,IEEE 802.11
'''
3、什么是C/S和B/S架构?
# 答案:
'''
软件系统体系结构:
C/S体系结构:client/server
指的是客户端/服务端 例如;QQ,微信
B(browser)/S体系结构:browser/server
指的是浏览器/服务端 例如12306(网站);购物网站,微信小程序
两者区别:
C/S :优点:交互性好,对服务器压力小,安全 ;缺点:服务器更新时需要同步更新客户端
B/S:优点:不需要更新客户端 缺点:交互性差,安全性低
'''
4、简述TCP协议?
TCP协议又叫:流失协议、可靠协议
1.TCP协议像流水一样一直发送,一直接收
2.TCP协议可靠的原因:有反馈机制(发送一句,回复一句才会发送下一句)
洪水攻击:同一时间发送给服务器大量请求
三次握手建立连接,四次挥手断开连接
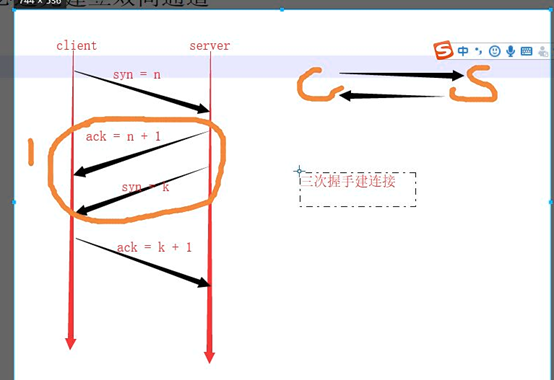
5、什么是arp协议?
# 答案:
'''
ARP协议,全称“Address Resolution Protocol”,中文名是地址解析协议,使用ARP协议可实现通过IP地址获得对应主机的物理地址(MAC地址)。
'''
6、tcp和UDP的区别?为什么tcp协议更可靠?
# TCP和UDP的区别?
TCP类似于:打电话(反馈机制,有回复)
UDP类似于:发短信(只管往一个地址发送,没有反馈机制)
'''
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
'''
# 为何基于tcp协议的通信比基于udp协议的通信更可靠?
'''
tcp:可靠 对方给了确认收到信息,才发下一个,如果没收到确认信息就重发
udp:不可靠 一直发数据,不需要对方回应
'''
7、什么是局域网和广域网?
# 答案:
'''
两者范围不一样:
局域网就是在固定的一个地理区域内由2台以上的电脑用网线和其他网络设备搭建而成的一个封闭的计算机组,范围在几千米以内;
广域网是一种地域跨度非常大的网络集合,范围在几十公里到几千公里。
两者的IP地址设置不一样:
局域网里面,必须在网络上有一个唯一的IP地址,这个IP地址是唯一的,在另外一个局域网,这个IP地址仍然能够使用。
广域网上的每一台电脑(或其他网络设备)都有一个或多个广域网IP地址,而且不能重复。
'''
8、什么是socket?简述基于tcp协议的套接字通信流程?
# 答案:
'''
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部。
服务端:
创建socket对象,绑定ip端口bind(), 设置最大链接数listen(), accept()与客户端的connect()创建双向管道, send(), recv(),close()
客户端:
创建socket对象,connect()与服务端accept()创建双向管道, send(),recv(),close()
'''
9、什么是粘包?socket中造成粘包的原因是什么?那些情况会发送粘包现象?
'''
粘包:
数据粘在一起,主要因为:接收方不知道消息之间的界限,不知道一次性提取多少字节的数据,造成的数据量比较小,时间间隔比较短,就合并成了一个包,这是底层的一个优化算法(Nagle算法)
'''
10、IO多路复用的作用?
检测有没有IO的模块:genent 模块
monkey : 猴子补听,监听
from gevent import monkey;monkey.patch_all() # 由于该模块经常被使用 所以建议写成一行
'''
I/O多路复用是用于提升效率,单个进程可以同时监听多个网络连接IO。
举例:
通过一种机制,可以监视多个文件描述符,一旦描述符就绪(读就绪和写就绪),能通知程序进行相应的读写操作,I/O多路复用避免阻塞在io上,原本为多进程或多线程来接收多个连接的消息变为单进程或单线程保存多个socket的状态后轮询处理。
'''
11、什么是防火墙以及作用?
'''
在互联网上防火墙是一种非常有效的网络安全模型,通过它可以隔离风险区域(即Internet或有一定风险的网络)与安全区域(局域网)的连接,同时不会妨碍人们对风险区域的访问。所以它一般连接在核心交换机与外网之间。
作用:
1.过滤进出网络的数据
2.管理进出访问网络的行为
3.封堵某些禁止业务
4.记录通过防火墙信息内容和活动
5.对网络攻击检测和告警
'''
12、select、poll、epoll模型的区别?
'''
I/O多路复用的本质就是用select/poll/epoll,去监听多个socket对象,如果其中的socket对象有变化,只要有变化,用户进程就知道了。
select是不断轮询去监听的socket,socket个数有限制,一般为1024个;
poll还是采用轮询方式监听,只不过没有个数限制;
epoll并不是采用轮询方式去监听了,而是当socket有变化时通过回调的方式主动告知用户进程。
'''
13、简述进程、线程、协程的区别以及应用场景?
内存是工厂,进程是车间,线程是流水线
'''
1.进程:资源单位(进程之间数据隔离)
2.线程:执行单位(线程之间数据共享)
3.每一个进程自带一个线程
4.协程:单线程下实现并发。通IO监听的模块,有IO操作就切换控制权,欺骗操作系统,让操作系统误认为没有IO,让程序一直处于运行态和就绪态。阻塞态就是IO操作
'''
14、什么是GIL全局解释器锁?
'''
全局解释锁,每次只能一个线程获得cpu的使用权:为了线程安全,也就是为了解决多线程之间的数据完整性和状态同步而加的锁,因为我们知道线程之间的数据是共享的。
'''
15、Python中如何使用线程池和进程池?
在保证计算机硬件安全的情况下最大限度的利用计算机
池其实降低的程序的运行效率,但是保证了硬件的安全
因为硬件的发展跟不上软件的发展
# 答案:
# 线程池
import threadpool, time
with open(r'../uoko_house_id.txt', 'r', encoding='utf-8') as f: # with open语句表示通用的打开文件的方式,此处用来获取需要爬取参数的列表
roomIdLi = f.readlines()
roomIdList =[x.replace('\n','').replace(' ','') for x in roomIdLi]
print(roomIdList)
li = [[i, item] for i, item in enumerate(roomIdList)] # enumerate()将列表中元素和其下标重新组合输出
def run(roomId):
"""对传入参数进行处理"""
print('传入参数为:', roomId)
time.sleep(1)
def main():
roomList = li # 房间信息
start_time = time.time()
print('启动时间为:', start_time)
pool = threadpool.ThreadPool(10)
requests = threadpool.makeRequests(run, roomList)
[pool.putRequest(req) for req in requests]
pool.wait()
print("共用时:", time.time()-start_time)
if __name__ == '__main__':
main()
# 进程池
from multiprocessing.pool import Pool
from time import sleep
def fun(a):
sleep(5)
print(a)
if __name__ == '__main__':
p = Pool()
for i in range(10):
p.apply_async(fun, args= (i, ))
p.close()
p.join()
print("end")
16、threading.local的作用?
# 答案:
为每个线程创建一个独立的空间,使得线程对自己的空间中的数据进行操作(数据隔离)。
import threading
from threading import local
import time
obj = local()
def task(i):
obj.xxxxx = i
time.sleep(2)
print(obj.xxxxx,i)
for i in range(10): #开启了10个线程
t = threading.Thread(target=task,args=(i,))
t.start()
17、进程之间二u和进行通讯?
python提供了多种进程通信的方式,主要Queue和Pipe这两种方式,Queue用于多个进程间实现通信,Pipe是两个进程的通信。
from multiprocessing import Process,Queue
"""
创建两个子进程,让一个子进程放数据,另一个子进程拿数据
"""
def producer(q):
q.put('hello jeff')
def consumer(q):
print(q.get())
if __name__ == '__main__':
q = Queue() # 生成一个队列
p = Process(target=producer, args=(q,)) # 创建一个生产进程对象
c = Process(target=consumer, args=(q,)) # 创建一个消费进程对象
p.start() # 创建进程,启动
c.start() # 创建进程,启动
# 结果:
hello jeff
18、什么是并发和并行?
并发:看起来像同时运行,内部:服务器来回切换者服务,速度很快,用户感觉不到
并行:真正意义上的同时运行
19、同步和异步,阻塞和非阻塞的区别?
同步异步:表示任务的提交方式
同步:任务提交之后,必须等待有返回结果,才继续执行下一步
异步:任务提交之后,不等待,继续执行下一步,(返回结果通过其他方式调用)
阻塞:阻塞态,在执行一个操作时,不能做其他操作
非阻塞:就绪态,运行态。在执行一个操作时,能做其他事
20、路由器和交换机的区别?
'''
1:交换机:是负责内网里面的数据传递(arp协议)根据MAC地址寻址。
路由器:在网络层,路由器根据路由表,寻找该ip的网段。
2:路由器可以把一个IP分配给很多个主机使用,这些主机对外只表现出一个IP。
交换机可以把很多主机连起来,这些主机对外各有各的IP。
3:交换机是做端口扩展的,也就是让局域网可以连进来更多的电脑。
路由器是用来做网络连接,也就是连接不同的网络。
'''
21、什么是域名解析?
'''
在互联网上,所有的地址都是ip地址,现阶段主要是IPv4(比如:110.110.110.110)。
但是这些ip地址太难记了,所以就出现了域名(比如http://baidu.com)。
域名解析就是将域名,转换为ip地址的这样一种行为。
'''
22、如何让修改本地的hosts文件?
'''
Hosts是一个没有扩展名的系统文件,可以用记事本等工具打开,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,
当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从Hosts文件中寻找对应的IP地址,
一旦找到,系统会立即打开对应网页,如果没有找到,则系统会再将网址提交给DNS域名解析服务器进行IP地址的解析。
文件路径:C:\WINDOWS\system32\drivers\etc。
将127.0.0.1 www.163.com 添加在最下面
修改后用浏览器访问“www.163.com”会被解析到127.0.0.1,导致无法显示该网页。
'''
23、生产者和消费者模型应用场景?
生产者和消费者模型:处理供需不平衡的问题
生产者:生产/制造数据的
消费者:消费/处理数据的
例子:做包子的,买包子的
'''
生产者与消费者模式是通过一个容器来解决生产者与消费者的强耦合关系,生产者与消费者之间不直接进行通讯,
而是利用阻塞队列来进行通讯,生产者生成数据后直接丢给阻塞队列,消费者需要数据则从阻塞队列获取,
实际应用中,生产者与消费者模式则主要解决生产者与消费者的生产与消费的速率不一致的问题,达到平衡生产者与消费者的处理能力,而阻塞队列则相当于缓冲区。
应用场景:用户提交订单,订单进入引擎的阻塞队列中,由专门的线程从阻塞队列中获取数据并处理。
优势:
1;解耦
假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。
将来如果消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。
2:支持并发
生产者直接调用消费者的某个方法,还有另一个弊端。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只能一直等着
而使用这个模型,生产者把制造出来的数据只需要放在缓冲区即可,不需要等待消费者来取。
3:支持忙闲不均
缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。
当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。
'''
24、什么是cdn服务?
'''
目的是使用户可以就近到服务器取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。
cdn 即内容分发网络
'''
25、有A.txt和B.txt两个文件,使用多进程和进程池的方式分别读取这两个文件?
# 多进程
"""通过多进程加速读取excel的测试"""
__author__ = "hanyaning@deri.energy"
import os.path
import time
from service import logger
import pandas as pd
from multiprocessing import Process, Manager
startTime = time.time()
logger = logger.MyLogger("multi_process").getLogger()
def getExcelData(path, return_data=None, file_name=""):
global startTime
logger.info("开始读取Excel文件,当前进程pid:" + str(os.getpid()))
if not os.path.exists(path):
raise FileNotFoundError()
if os.path.isfile(path):
return_data[file_name] = pd.read_excel(path, skiprows=1, skipfooter=1)
logger.info("读取Excel文件完毕,当前进程pid:" + str(os.getpid()))
if __name__ == "__main__":
excel_path = os.path.join(os.getcwd(), "../excels")
xls_names = [x for x in os.listdir(excel_path) if x.endswith(".xls")]
first = str(time.time() - startTime)
logger.info("进入程序用时:" + first)
p_list = []
# Manager类似于同步数据管理工具,可在多进程时实现各进程操作同一个数据,比如这里通过它组织返回值
manager = Manager()
# Manager.dict()类似于共享变量,各个进程可以修改它,通过每次添加不同的key值,可以实现方法返回值的获取
return_data = manager.dict()
first = time.time() - startTime
# 手动创建多个进程读取,可能存在创建进程过多导致系统崩溃的情况
for file_name in xls_names:
p = Process(target=getExcelData, args=(os.path.join(excel_path, file_name), return_data, file_name))
p.start()
p_list.append(p)
print(p_list)
"""
经测试,直到这里都还会延迟数秒才执行进程的target方法,尽管前面已经调用了start(),但进程并没有立即执行
寡人认为是系统创建进程需要时间,并且是创建好所有进程后才各进程才开始工作,这里要创建120个进程花费了大多数的时间
后面在采用进程池时,当设置最大进程数为120时,依然花费了大把的时间,而设置为10时,大大缩小了创建进程到执行target方法所要等待的时间
这也证明了寡人的观点,至于正确与否,寡人先跟代码去了,且等下回分解
"""
for p in p_list:
# 如果有子进程没有执行完,需要先阻塞主进程
p.join()
logger.info("各进程执行完毕")
# 获取返回值字典为列表
data_frames = return_data.values()
# 合并列表为一个dataFrame
data = pd.DataFrame()
for da in data_frames:
data = data.append(da)
endTime = time.time()
print(endTime - startTime)
print(len(data))
# 进程池
"""通过多进程加速读取excel的测试"""
__author__ = "hanyaning@deri.energy"
import os.path
import time
from service import logger
import pandas as pd
from multiprocessing import Pool
logger = logger.MyLogger("multi_process").getLogger()
def getExcelData(path):
logger.info("开始读取excel,当前进程pid:" + str(os.getpid()))
data = pd.DataFrame()
if not os.path.exists(path):
raise FileNotFoundError()
if os.path.isfile(path):
logger.info("读取Excel文件完毕,当前进程pid:" + str(os.getpid()))
return data.append(pd.read_excel(path, skiprows=1, skipfooter=1), sort=False)
if __name__ == "__main__":
excel_path = os.path.join(os.getcwd(), "../excels")
xls_names = [x for x in os.listdir(excel_path) if x.endswith(".xls")]
startTime = time.time()
p_list = []
# 使用进程池Pool
pool = Pool(processes=10)
pool_data_list = []
data = pd.DataFrame()
for file_name in xls_names:
# 需要注意不能直接在这里调用get方法获取数据,原因是apply_async后面 get()等待线程运行结束才会下一个,这里多进程会变成阻塞执行
pool_data_list.append(pool.apply_async(getExcelData, (os.path.join(excel_path, file_name),)))
pool.close()
# 需要阻塞以下,等所有子进程执行完毕后主线程才继续执行
pool.join()
for pool_data in pool_data_list:
# 这里再使用get()方法可以获取返回值
data = data.append(pool_data.get())
endTime = time.time()
print(endTime - startTime)
print(len(data))
26、那些是常见的TCPFlags?
'''
SYN:表示建立连接
FIN:表示关闭连接
RST:表示连接重置
ACK:表示响应,三次握手,四次挥手
URG:
PSH:表示有DATA数据传输
'''
27、tracerroute--一般使用的是哪种网络层协议?
ICMP协议
ICMP(Internet Control Message Protocol)Internet控制报文协议。它是TCP/IP协议簇的一个子协议,用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。这些控制消息虽然并不传输用户数据,但是对于用户数据的传递起着重要的作用
28、iptabkes只是考察,根据要求写出防火墙规则?
'''
A.屏蔽192.168.1.5访问本机dns服务端口
B.允许10.1..0/2访问本机的udp88889999端口
'''
# 答案:
'''
iptables -A INPUT -p ICMP --icmp-type 8 -m time --timestart 00:00:00 --timestop 23:59:59 --weekdays Mon -j DROP
'''
29、socket套接字编程?
'''
要求:
1.实现server端的功能即可
2.遵循基本语言编程规范
'''
服务端:
import socket
server = socket.socket() # 生成对象
server.bind(('127.0.0.1', 8080)) # 绑定IP和端口 (自己的)
server.listen(5) # 半连接池,允许等待数
conn, addr = server.accept() # 等待接听
# conn:地址 addr:端口号(随机分配)
while True:
data = conn.recv(1024) # 接收
print(data) # 打印接收的内容
# 判断如果接收的是空,就跳出循环
if len(data) == 0:
break
conn.send(data.lower()) # 发送反馈内容
客户端:
import socket
client = socket.socket() # 生成对象
client.connect(('127.0.0.1', 8080)) # 拨号,对方IP和端口
while True:
msg = input('请输出 >>>:').strip().encode('utf-8') # 转二进制
if len(msg) == 0:
continue
client.send(msg) # 发送
data = client.recv(1024) # 接收反馈内容
print(data)
30、对于多线程,CPU密集型怎么使用?IO密集型怎么使用?
'''
并发本质:切换+保存状态
CPU密集型使用多进程
IO密集型使用多线程
'''
31、说说线程互斥锁,进程锁互斥锁?
多个进程同时间操作同一份文件,会造成数据絮乱
处理方法:加锁处理,将并发变成串行,虽然降低了效率,但是提高了安全
注意:1.锁不要轻易使用,容易造成死锁现象
2.只在处理关键数据的部分加锁
3.锁必须在主进程中产生,交给子进程使用
Lock模块:加锁
mutex.acquire() # 抢锁
mutex.release() # 释放锁
metex = Lock() # 创建锁,生成一把锁
32、说说守护线程?
关键字:子线程对线.daemon = True 设置该 子线程 为 主线程的 守护线程
主线程结束,守护线程立马结束
33、TCP协议在每次建立断开连接时,都要在收发双方之间交换?报文
三个
34、简述多进程开发中join与deamon的区别?
join :等待
t = Thread(target=task,args=(1,))
t.daemon = True # 设置为守护线程
t.start() # 启动
'''
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
'''
from threading import Thread,current_thread
import time
def task(i):
print(current_thread().name) # 打印子线程的名字
time.sleep(i)
print('子线程结束')
t = Thread(target=task,args=(1,))
t.daemon = True # 设置为守护线程
t.start() # 启动
print('主线程')
35、简述GIL对Python性能的影响?
'''
GIL:全局解释器锁。每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程可以执行字节码。
线程释放GIL锁的情况:
在IO操作等可能会引起阻塞的system call之前,可以暂时释放GIL,但在执行完毕后,必须重新获取GIL
Python 3.x使用计时器(执行时间达到阈值后,当前线程释放GIL)或Python 2.x,tickets计数达到100
Python使用多进程是可以利用多核的CPU资源的。
多线程爬取比单线程性能有提升,因为遇到IO阻塞会自动释放GIL锁
'''
36、线程、进程、协程使用场景?
'''
1.在写高并发的服务端代码时。
2.在写高性能爬虫的时候。
'''
37、简述线程死锁现象?
死锁大白话:两把锁的时候:你锁我,我锁你。。。。死锁。你家钥匙在我手上,我家钥匙在你手上,我们都被锁在家里。
1.加锁顺序(线程按照一定的顺序加锁)
2.加锁时限(线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁)
3.死锁检测
38、asynio是什么?
python高并发模块
39、gevent模块是什么?
from gevent import monkey;monkey.patch_all() # 由于该模块经常被使用 所以建议写成一行
from gevent import spawn
实现协程
'''
gevent是第三方库,通过greenlet实现协程,其基本思想是:
当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
'''
40、twisted框架?
'''
twisted是异步非阻塞框架。爬虫框架Scrapy依赖twisted。
'''
41、什么是LVS?
'''
LVS :Linux虚拟服务器
作用:LVS主要用于多服务器的负载均衡。
它工作在网络层,可以实现高性能,高可用的服务器集群技术。
它廉价,可把许多低性能的服务器组合在一起形成一个超级服务器。
它易用,配置非常简单,且有多种负载均衡的方法。
它稳定可靠,即使在集群的服务器中某台服务器无法正常工作,也不影响整体效果。另外可扩展性也非常好。
'''
42、什么是Nginx?
'''
Nginx是一款自由的、开源的、高性能的HTTP服务器和反向代理服务器,同时也是一个IMAP、POP3、SMTP代理服务器。可以用作HTTP服务器、方向代理服务器、负载均衡。
'''
43、什么是keepalived?
'''
Keepalived起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态,它根据TCP/IP参考模型的第三、第四层、第五层交换机制检测每个服务节点的状态,如果某个服务器节点出现异常,或者工作出现故障,Keepalived将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。
后来Keepalived又加入了VRRP的功能,VRRP(Vritrual Router Redundancy Protocol,虚拟路由冗余协议)出现的目的是解决静态路由出现的单点故障问题,通过VRRP可以实现网络不间断稳定运行,因此Keepalvied 一方面具有服务器状态检测和故障隔离功能,另外一方面也有HA cluster功能,下面介绍一下VRRP协议实现的过程。
'''
44、什么是haproxy?
'''
- TCP 代理:可从监听 socket 接受 TCP 连接,然后自己连接到 server,HAProxy 将这些 sockets attach 到一起,使通信流量可双向流动。
- HTTP 反向代理(在 HTTP 专用术语中,称为 gateway):HAProxy 自身表现得就像一个 server,通过监听 socket 接受 HTTP 请求,然后与后端服务器建立连接,通过连接将请求转发给后端服务器。
- SSL terminator / initiator / offloader: 客户端 -> HAProxy 的连接,以及 HAProxy -> server 端的连接都可以使用 SSL/TLS
- TCP normalizer: 因为连接在本地操作系统处终结,client 和 server 端没有关联,所以不正常的 traffic 如 invalid packets, flag combinations, window advertisements, sequence numbers, incomplete connections(SYN floods) 不会传递给 server 端。这种机制可以保护脆弱的 TCP stacks 免遭协议上的攻击,也使得我们不必修改 server 端的 TCP 协议栈设置就可以优化与 client 的连接参数。
- HTTP normalizer: HAProxy 配置为 HTTP 模式时,只允许有效的完整的请求转发给后端。这样可以使得后端免遭 protocol-based 攻击。一些不规范的定义也被修改,以免在 server 端造成问题(eg: multiple-line headers,会被合并为一行)
- HTTP 修正工具:HAProxy 可以 modify / fix / add / remove / rewrite URL 及任何 request or response header。
- a content-based switch: 可基于内容进行转发。可基于请求中的任何元素转发请求或连接。因此可基于一个端口处理多种协议(http,https, ssh)
- a server load balancer: 可对 TCP 连接 和 HTTP 请求进行负载均衡调度。工作于 TCP 模式时,可对整个连接进行负载均衡调度;工作于 HTTP 模式时,可对 HTTP 请求进行调度。
- a traffic regulator: 可在不同的方面对流量进行限制,保护 server ,使其不超负荷,基于内容调整 traffic 优先级,甚至可以通过 marking packets 将这些信息传递给下层以及网络组件。
- 防御 DDos 攻击及 service abuse: HAProxy 可为每个 IP地址,URL,cookie 等维护大量的统计信息,并对其进行检测,当发生服务滥用的情况,采取一定的措施如:slow down the offenders, block them, send them to outdated contents, etc
- 是 network 的诊断的一个观察节点:根据精确记录细节丰富的日志,对网络诊断很有帮助
- an HTTP compression offloader:可自行对响应进行压缩,而不是让 server 进行压缩,因此对于连接性能较差的 client,或使用高延迟移动网络的 client,可减少页面加载时间。
'''
45、什么是负载均衡?
'''
系统的扩展可分为纵向(垂直)扩展和横向(水平)扩展。纵向扩展,是从单机的角度通过增加硬件处理能力,比如CPU处理能力,内存容量,磁盘等方面,实现服务器处理能力的提升,不能满足大型分布式系统(网站),大流量,高并发,海量数据的问题。因此需要采用横向扩展的方式,通过添加机器来满足大型网站服务的处理能力。比如:一台机器不能满足,则增加两台或者多台机器,共同承担访问压力。这就是典型的集群和负载均衡架构
'''
46、什么是rpc及应用场景?
'''
RPC主要用于公司内部的服务调用,性能消耗低,传输效率高,服务治理方便。HTTP主要用于对外的异构环境,浏览器接口调用,APP接口调用,第三方接口调用等...
'''
47、什么是反向代理?
'''
反向代理:加速网络,保护真实服务器
这个词相信搞网络的朋友都很熟悉的,但是具体是什么意思呢?说实话,复杂的我也不懂,就我个人理解而言,反向代理有很多用途,比如说保护真实服务器不被外界攻击,加速网络等等。今天我们要介绍的就是加速网络的一种。
'''
48、创建进程?
from multiprocessing import Process
import time
def test(name):
print('%s 子进程开始' % name)
time.sleep(2)
print('%s 子进程结束' % name)
if __name__ == '__main__':
p = Process(target=test, args=('jeff',)) # 创建一个子进程对象
p.start() # 告诉操作系统帮你创建一个进程
print('主程序')
49、创建线程?
# 第一种第一种实例化Thread方法
def task(name):
print('%s 开启了' % name)
time.sleep(3)
print('%s 结束了' % name)
if __name__ == '__main__':
t = Thread(target=task, args=('jeff',)) # 创建子线程对象
t.start() # 告诉操作系统开启这个线程
print('主线程')
50、进程之间的通讯Queue
在初始化Queue()对象时,若括号中没有指定最大可接受的消息数量,或数量为负值时,那么就代表可接受的消息数量没有上限,一直在内存的尽头
选择了IT,必定终身学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号