

正则表达式
正则表达式
正则表达式用来处理文本信息功能强大,学习正则表达是其实就是学习其语法规则:测试的软件是RegexBuddy,文末有响应的测试文本
一、正则表达式语法一:普通字符
普通字符:数字、字母、下划线、汉字、没有特殊定义过的标点符号
转义字符:
| \n | 代表换行符 |
| \t | 代表制表符 |
| \\ | 代表\本身 |
| \{,\},\[,\],\(,\),\$,\^,\*,\+,\|,\.,\? | 代表该字符本身 |
记忆方法:第四行 六个括号+键盘Shit 4($)、 6(^)、 8(*与+) 还有三个|?.
二、正则表达式语法二:标准字符集
标准字符集合:能够代表某个字符集合的表达式
区分大小写:大写代表取反的意思
| \d | 代表0-9任意数字 | d:digit 数字的意思 |
| \w | 代表a-z, A-Z, 0-9,_ 任意字符 | w:word 字符的意思 |
| \s | 代表\n \t 等空格字符 | s:space 空格的意思 |
| . | 代表任意字符(除了换行符) |
三、正则表达式语法三:自定义字符集
自定义字符集合:[]括起来的字符串
| [abc@] | 匹配a或b或c或@字符 |
| [^abc@] | 匹配除a,b,c,@以外的任一字符 |
| [a-f] | 匹配a~f中的任一意字符 |
| [^a-f1-4] | 匹配a~f 1~4 以外的任一字符 |
1、自定义字符中包含的特殊字符都失去其特殊意义,除了^(表示取反)和-(表示区间)
2、自定义字符集中包含标准字符集(除了小数点外),则自定义字符集包含该标准字符集合
[\d.\-+]将匹配:数字、小数点、+、- : 这里的小数点不算标准字符集合,只代表小数点,-需要转义 + 正常表示
[\w\s.\-+]将匹配:数字、大小写字母、空格、小数点、+、-
四、正则表达式语法四:量词
量词:修饰匹配次数的特殊符号
| {m} | 表达式出现m次 |
| {m,} | 表达式至少出现m次 |
| {m,n} | 表达式出现m到n次 |
| + | 相当于{1,} |
| ? | 相当于{0,1} |
| * | 相当于{0,} |
匹配次数中的贪婪模式(匹配字符越多越好,默认!)
匹配次数中的非贪婪模式(匹配字符越少越好,修饰匹配次数的特殊符号后再加上一个 "?" 号)
这里的可以参考https://www.cnblogs.com/hahazexia/p/6001492.html
五、正则表达式语法五:零宽匹配
字符边界:本组标记匹配的不是字符而是位置,符合某种条件的位置
| ^ | 与字符串开始的地方匹配 |
| $ | 与字符串结束的地方匹配 |
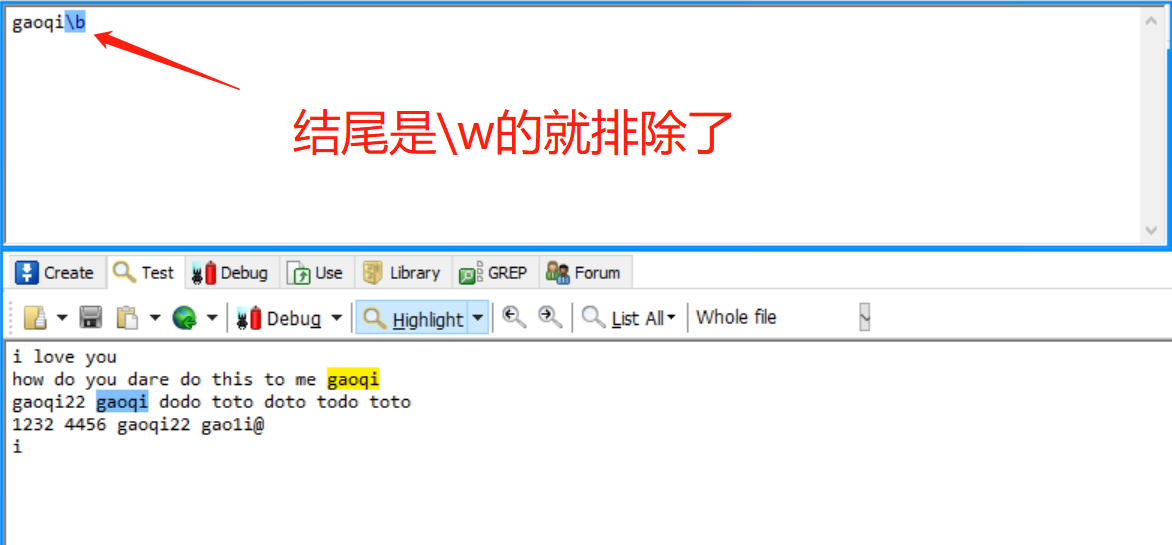
| \b | 匹配一个单词的边界 |
\b:表示匹配一个位置:这个位置不全是\w 意思就是这个位置全是\w 排除掉
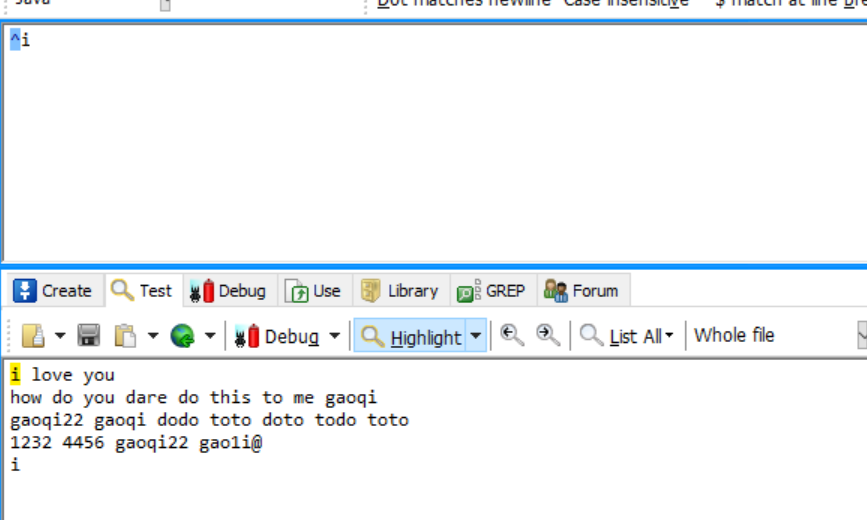
比如:^i 只会匹配字符串第一个字符i (这里这个文本表示一个字符串)
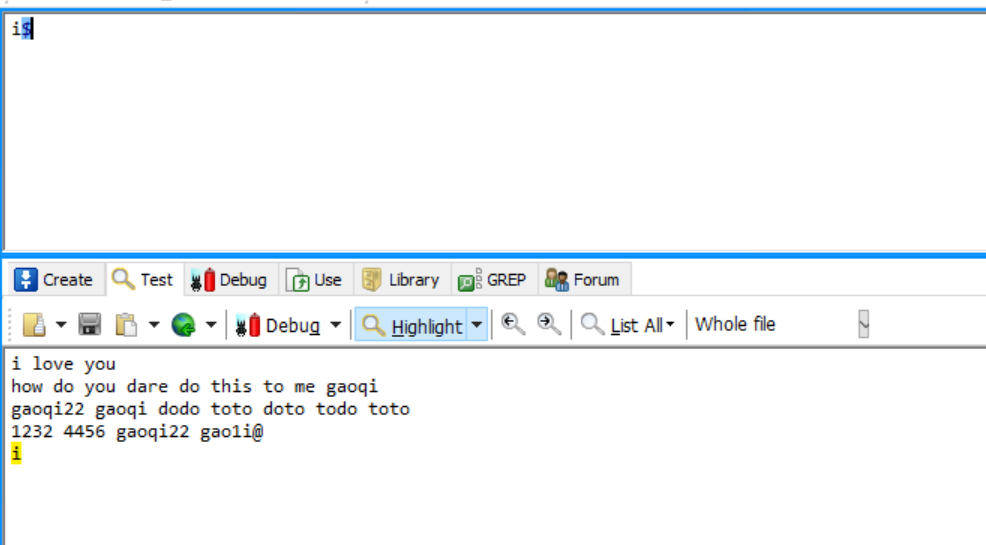
i$ 只会匹配字符串最后一个i
六、正则表达式语法六:选择符合分组
| | 选择结构 | 左右两边或关系 |
| ()捕获组 | 1.()内是一个整体被修饰等2.()内的值会被单独保存起来3.引用是通过左括号来计数的 |
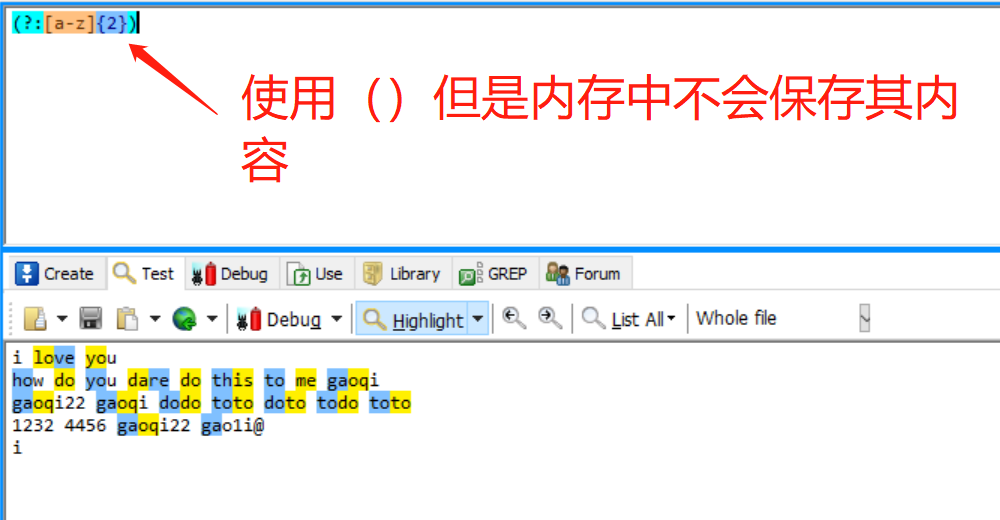
| (?:expression) | 当不需要保存()中的内容的时候,就用这个,减少内存消耗 |
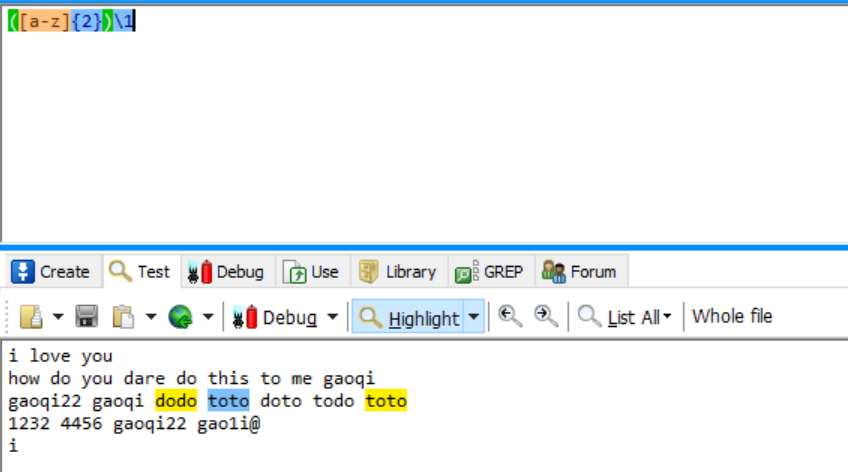
反向引用\nnn 例如\1 \2 表示引用第1个左括号中的内容 第2个左括号中的内容
七、正则表达式七:零宽断言
| (?=exp) | 断言自身出现的位置的后面能匹配表达式exp |
| (?<=exp) | 断言自身出现的位置的前面能匹配表达式exp |
| (?!exp) | 断言自身出现的位置的后面不能匹配表达式exp |
| (?<!exp) | 断言自身出现的位置的前面不能匹配表达式exp |
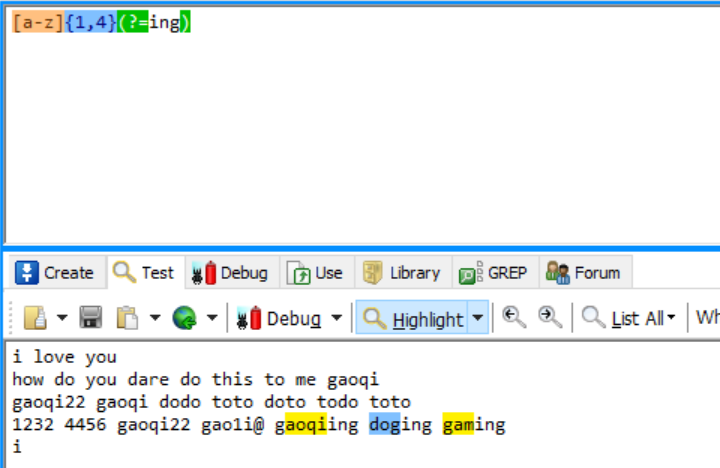
gaoqi后面是非数字,1-4位小写字母后面是ing 当然不包括ing



i love you
how do you dare do this to me gaoqi
gaoqi22 gaoqi dodo toto doto todo toto
1232 4456 gaoqi22 gao1i@ gaoqiing doging gaming
i

 浙公网安备 33010602011771号
浙公网安备 33010602011771号