学习了一天的python,终于可以爬爬了-_-
恒久恒久以前在语言大陆就听过一种叫,人生苦短,我用python的至理名言.陆陆续续在课下和业余生活中学习的一点python,知道基本的语法和规则,不过py的库实在是太多了,而且许多概念也没有深入的学习,不过这并不影响使用py,基本上面的知识就可以应对了,工具服务生活,那我就用py来干有意思的事情了.
环境:
python3.3.6
首先添加依赖包,这里用到xpath,json,urllib3,有些库需要自己下载安装,这网上教程一大堆,就不再赘述了.
from lxml import etree import urllib3, urllib import json import random as rd import os import time
设置请求头
'''
漫画爬取-请求头
'''
header = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Cookie": "",
"Host": "",
"Pragma": "no-cache",
"Referer": "",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
}
'''
请求参数
'''
request = {
}
''' 漫画主站 ''' comicHost = "" ''' 漫画访问路径 ''' imgTemp = "/action/play/read"
具体网站就不公开了,毕竟是免费的.其他网站的爬取也是大同小异.
'''
构造请求参数
t=0.01
id:漫画id
jid:漫画当前级数
tid:当前图片数
rand:随机数
'''
imgData = {"id": "", "jid": "", "tid": "", "rand": ""}
'''
本地存储路径
'''
localImgs = "F:\\comic\\"
http = urllib3.PoolManager();
'''
分类解析(主站和漫画首页)
'''
urllib3.disable_warnings()
def isContain(strUrl):
return ".html" in strUrl
'''
漫画首页html信息
'''
bodyContent = ""
'''
返回解析数据
'''
def requestRemote(url, pattern):
res = http.request("GET", url, header)
# 保存页面信息
urlArray = etree.HTML(res.data.decode("utf-8")).xpath(pattern)
return urlArray
# 获取首页的漫画链接 arrayHtml = requestRemote(comicHost, "//div/ul/li/a/@href") # 去掉下载完成的连接 级数 endArray = [] # 正在操作的漫画连接 nowOperate = "" endSeries = 0 for url in arrayHtml: if isContain(url): pass else: flag = True for endUrl in endArray: if url == endUrl: flag = False break if flag: descArray = requestRemote(comicHost + url, "//div[@class='chapters']/ul/li/a/@href") for imgUrl in descArray: # 获取漫画id comicId = requestRemote(comicHost + imgUrl, "//div[@class='info clearfix']/form/input[@id='dataid']/@value") # 拼接漫画图片路径 imgRealUrl = comicHost + imgTemp # 获取漫画级数 sid = imgUrl.split("/")[2].split(".")[0] if url == nowOperate and int(sid) > endSeries: print("略过已经下载的级数..." + sid + "级") continue iid = 1 # 存储图片数组 imgArray = [] # 循环获取图片 while True: if len(comicId) != 0: imgData = {"did": comicId[0], "id": sid, "jid": id, "rand": rd.random()} print("请求的路径: " + imgRealUrl + "?" + urllib.parse.urlencode(imgData)) # 得到漫画的json数据 resJson = http.request("GET", imgRealUrl + "?" + urllib.parse.urlencode(imgData), header) # 判断漫画时候为空 JSON解析: JSON字符串中的内容应该用双引号,而非单引号。 result = json.loads(resJson.data.decode("utf-8"), encoding="utf-8") if result["Code"] == "": break else: imgArray.append(result["Code"]) iid += 1 # 遍历漫画 for imgSrc in imgArray: print("图片开始下载") # 构造图片本地存储路径 title = requestRemote(comicHost + url, "//div[@class='info d-item-content']/h1") createPath = localImgs + title[0].text.strip() + "\\" + sid + "\\" # 存储本级漫画 if os.path.exists(createPath): pass else: os.makedirs(createPath) img = http.request("GET", imgSrc) file = open(createPath + imgSrc.split("/")[6], "wb+") file.write(img.data) print("图片下载成功! " + time.strftime('%Y-%m-%d %H%M%S',time.localtime(time.time()))) print("成功保存第" + sid + "级...") else: print("无法获取漫画id忽略下载...") break print("结束爬取...")
结果:
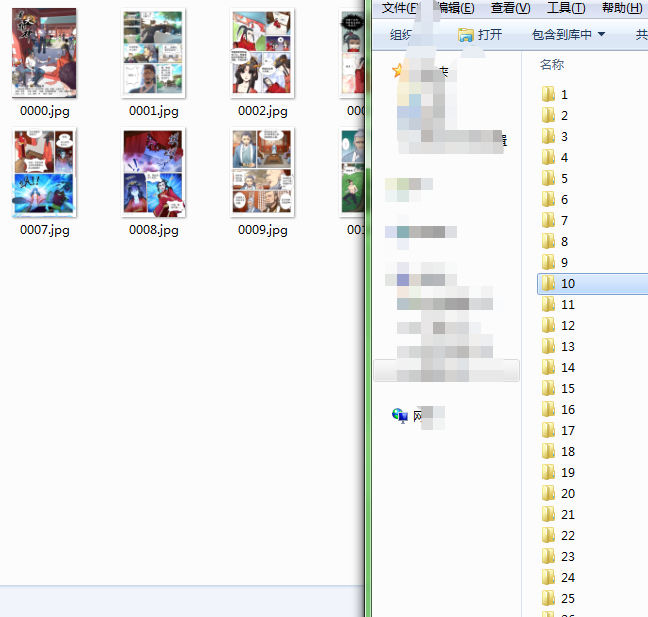
这里面需要注意几个就可以通用了:
- 所要爬去的具体地址,注意有的地址在网页上是无法发现的,需要第三方的抓包工具找到具体的请求地址
- 我这里使用的xpath对网页进行解析的,这个也比较简单,安装看下文档就可以直接使用了
- 我这里对照的每个下载的漫画做了一个过滤免下载,如果中间爬去错误的时候,则下载重新进行的时候,忽略其已经下载好的漫画
# 去掉下载完成的连接 级数
endArray = []
# 正在操作的漫画连接
nowOperate = ""
endSeries = 0
只需要知道点py的语法,urllib3知识,地方放的文档解析的插件,人人都可爬虫
平凡是我的一个标签

 浙公网安备 33010602011771号
浙公网安备 33010602011771号