78. Subsets(M) & 90. Subsets II(M) & 131. Palindrome Partitioning
Given a set of distinct integers, nums, return all possible subsets. Note: The solution set must not contain duplicate subsets. For example, If nums = [1,2,3], a solution is: [ [3], [1], [2], [1,2,3], [1,3], [2,3], [1,2], [] ]
class Solution { public: vector<vector<int>> subsets(vector<int>& nums) { const size_t n = nums.size(); vector<int> v; vector<vector<int> > result; for (int i = 0; i < 1<<n; ++i) { for (int j = 0; j < n; ++j) { if(i & 1 << j) v.push_back(nums[j]); } result.push_back(v); v.clear(); } return result; } };
3ms
迭代,增量构造.没看懂
http://www.cnblogs.com/TenosDoIt/p/3451902.html
class Solution { public: vector<vector<int> > subsets(vector<int> &S) { sort(S.begin(), S.end()); vector<vector<int> > result(1); for (auto elem : S) { result.reserve(result.size() * 2); auto half = result.begin() + result.size(); copy(result.begin(), half, back_inserter(result)); for_each(half, result.end(), [&elem](decltype(result[0]) &e){ e.push_back(elem); }); } return result; } };
3ms
位向量法
class Solution { public: vector<vector<int> > subsets(vector<int> &S) { sort(S.begin(), S.end()); // vector<vector<int> > result; vector<bool> selected(S.size(), false); subsets(S, selected, 0, result); return result; } private: static void subsets(const vector<int> &S, vector<bool> &selected, int step, vector<vector<int> > &result) { if (step == S.size()) { vector<int> subset; for (int i = 0; i < S.size(); i++) { if (selected[i]) subset.push_back(S[i]); } result.push_back(subset); return; } //S[step] selected[step] = false; subsets(S, selected, step + 1, result); //S[step] selected[step] = true; subsets(S, selected, step + 1, result); } };

6ms
class Solution { public: vector<vector<int> > subsets(vector<int> &S) { sort(S.begin(), S.end()); // vector<vector<int> > result; vector<int> path; subsets(S, path, 0, result); return result; } private: static void subsets(const vector<int> &S, vector<int> &path, int step, vector<vector<int> > &result) { if (step == S.size()) { result.push_back(path); return; } //S[step] subsets(S, path, step + 1, result); //S[step] path.push_back(S[step]); subsets(S, path, step + 1, result); path.pop_back(); } };

6ms
Iterative This problem can also be solved iteratively. Take [1, 2, 3] in the problem statement as an example. The process of generating all the subsets is like: Initially: [[]] Adding the first number to all the existed subsets: [[], [1]]; Adding the second number to all the existed subsets: [[], [1], [2], [1, 2]]; Adding the third number to all the existed subsets: [[], [1], [2], [1, 2], [3], [1, 3], [2, 3], [1, 2, 3]]. Have you got the idea :-) The code is as follows. class Solution { public: vector<vector<int>> subsets(vector<int>& nums) { sort(nums.begin(), nums.end()); vector<vector<int>> subs(1, vector<int>()); for (int i = 0; i < nums.size(); i++) { int n = subs.size(); for (int j = 0; j < n; j++) { subs.push_back(subs[j]); subs.back().push_back(nums[i]); } } return subs; } };

1 // Recursion. 2 class Solution { 3 public: 4 vector<vector<int> > subsets(vector<int> &S) { 5 vector<vector<int> > res; 6 vector<int> out; 7 sort(S.begin(), S.end()); 8 getSubsets(S, 0, out, res); 9 return res; 10 } 11 void getSubsets(vector<int> &S, int pos, vector<int> &out, vector<vector<int> > &res) { 12 res.push_back(out); 13 for (int i = pos; i < S.size(); ++i) { 14 //if (i != pos && S[i] == S[i-1]) continue;//subsets II 15 out.push_back(S[i]); 16 getSubsets(S, i + 1, out, res); 17 out.pop_back(); 18 //while (S[i] == S[i + 1]) ++i; //subsets II 19 } 20 } 21 };

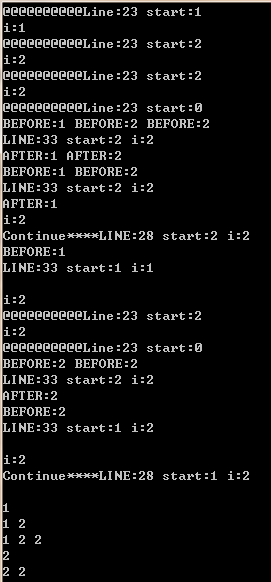
#include <bits/stdc++.h> using namespace std; class Solution { public: vector<vector<int> > subsetsWithDup(vector<int> &S) { sort(S.begin(), S.end()); // ???? vector<vector<int> > result; vector<int> path; dfs(S, S.begin(), path, result); for (int i = 0; i < result.size(); ++i) { for (int j = 0; j < result[i].size(); ++j) { printf("%d ", result[i][j]); }printf("\n"); } return result; } private: static void dfs(const vector<int> &S, vector<int>::iterator start, vector<int> &path, vector<vector<int> > &result) { result.push_back(path); printf("@@@@@@@@@@Line:%d start:%d\n", __LINE__, *start); for (auto i = start; i < S.end(); i++) { printf("i:%d\n", *i); if (i != start && *i == *(i-1)) { printf("Continue****LINE:%d start:%d i:%d\n", __LINE__, *start, *i); continue; } path.push_back(*i); dfs(S, i + 1, path, result); for(auto xx : path) printf("BEFORE:%d ", xx); printf("\nLINE:%d start:%d i:%d\n", __LINE__, *start, *i); path.pop_back(); for (auto xx : path) printf("AFTER:%d ", xx); printf("\n"); } } }; int main(int argc, char *argv[]) { vector<int> v{1,2,2}; Solution sn; sn.subsetsWithDup(v); //printf("%d %d\n",v[0],v.size()); return 0; }
This structure might apply to many other backtracking questions, but here I am just going to demonstrate Subsets, Permutations, and Combination Sum.
Subsets : https://leetcode.com/problems/subsets/
public List<List<Integer>> subsets(int[] nums) { List<List<Integer>> list = new ArrayList<>(); Arrays.sort(nums); backtrack(list, new ArrayList<>(), nums, 0); return list; } private void backtrack(List<List<Integer>> list , List<Integer> tempList, int [] nums, int start){ list.add(new ArrayList<>(tempList)); for(int i = start; i < nums.length; i++){ tempList.add(nums[i]); backtrack(list, tempList, nums, i + 1); tempList.remove(tempList.size() - 1); } }
Subsets II (contains duplicates) : https://leetcode.com/problems/subsets-ii/
public List<List<Integer>> subsetsWithDup(int[] nums) { List<List<Integer>> list = new ArrayList<>(); Arrays.sort(nums); backtrack(list, new ArrayList<>(), nums, 0); return list; } private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int start){ list.add(new ArrayList<>(tempList)); for(int i = start; i < nums.length; i++){ if(i > start && nums[i] == nums[i-1]) continue; // skip duplicates tempList.add(nums[i]); backtrack(list, tempList, nums, i + 1); tempList.remove(tempList.size() - 1); } }
Permutations : https://leetcode.com/problems/permutations/
public List<List<Integer>> permute(int[] nums) { List<List<Integer>> list = new ArrayList<>(); // Arrays.sort(nums); // not necessary backtrack(list, new ArrayList<>(), nums); return list; } private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums){ if(tempList.size() == nums.length){ list.add(new ArrayList<>(tempList)); } else{ for(int i = 0; i < nums.length; i++){ if(tempList.contains(nums[i])) continue; // element already exists, skip tempList.add(nums[i]); backtrack(list, tempList, nums); tempList.remove(tempList.size() - 1); } } }
Permutations II (contains duplicates) : https://leetcode.com/problems/permutations-ii/
public List<List<Integer>> permuteUnique(int[] nums) { List<List<Integer>> list = new ArrayList<>(); Arrays.sort(nums); backtrack(list, new ArrayList<>(), nums, new boolean[nums.length]); return list; } private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, boolean [] used){ if(tempList.size() == nums.length){ list.add(new ArrayList<>(tempList)); } else{ for(int i = 0; i < nums.length; i++){ if(used[i] || i > 0 && nums[i] == nums[i-1] && !used[i - 1]) continue; used[i] = true; tempList.add(nums[i]); backtrack(list, tempList, nums, used); used[i] = false; tempList.remove(tempList.size() - 1); } } }
Combination Sum : https://leetcode.com/problems/combination-sum/
public List<List<Integer>> combinationSum(int[] nums, int target) { List<List<Integer>> list = new ArrayList<>(); Arrays.sort(nums); backtrack(list, new ArrayList<>(), nums, target, 0); return list; } private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int remain, int start){ if(remain < 0) return; else if(remain == 0) list.add(new ArrayList<>(tempList)); else{ for(int i = start; i < nums.length; i++){ tempList.add(nums[i]); backtrack(list, tempList, nums, remain - nums[i], i); // not i + 1 because we can reuse same elements tempList.remove(tempList.size() - 1); } } }
Combination Sum II (can't reuse same element) : https://leetcode.com/problems/combination-sum-ii/
public List<List<Integer>> combinationSum2(int[] nums, int target) { List<List<Integer>> list = new ArrayList<>(); Arrays.sort(nums); backtrack(list, new ArrayList<>(), nums, target, 0); return list; } private void backtrack(List<List<Integer>> list, List<Integer> tempList, int [] nums, int remain, int start){ if(remain < 0) return; else if(remain == 0) list.add(new ArrayList<>(tempList)); else{ for(int i = start; i < nums.length; i++){ if(i > start && nums[i] == nums[i-1]) continue; // skip duplicates tempList.add(nums[i]); backtrack(list, tempList, nums, remain - nums[i], i + 1); tempList.remove(tempList.size() - 1); } } }
Palindrome Partitioning : https://leetcode.com/problems/palindrome-partitioning/
public List<List<String>> partition(String s) { List<List<String>> list = new ArrayList<>(); backtrack(list, new ArrayList<>(), s, 0); return list; } public void backtrack(List<List<String>> list, List<String> tempList, String s, int start){ if(start == s.length()) list.add(new ArrayList<>(tempList)); else{ for(int i = start; i < s.length(); i++){ if(isPalindrome(s, start, i)){ tempList.add(s.substring(start, i + 1)); backtrack(list, tempList, s, i + 1); tempList.remove(tempList.size() - 1); } } } } public boolean isPalindrome(String s, int low, int high){ while(low < high) if(s.charAt(low++) != s.charAt(high--)) return false; return true; }
/*Without any crap! Hit the road! Since we have to collect all the possible sets that meet the requirements -> a palindrome; so traversing the whole possible paths will be definitely the case -> using DFS and backtracking seems to be on the table. try from the start index of the string till any index latter and then check its validity - a palindrome? from the start index till the ending? if so, we need to store it in a stack for latter collection and then traverse further starting from the previous ending index exclusively and begin the checking again and on and on till the start index is beyond the string; at that time we are to collect the palindromes along the paths. Several stuff should be specified: checking whether a string is palindrome is quite simple in C using pointer; using DP might not help a lot since the checking process is quite fast while DP will require extra work to record and space allocation and so on. In the end, let's check its space and time consumption: space cost O(n*2^n) -> one set of palindrome will take about O(n) but the amount of sets is dependent on the original string itself. time cost O(n*2^n) -> collecting them while using the space to store them so the space and time cost should be linearly proportional; since the range can be varied a lot depending on the actual provided string so the performance might not be a problem. by LHearen
4ms in us. 72ms in cn. */ void traverse(char* s, int len, int begin, char** stack, int top, char**** arrs, int** colSizes, int* returnSize) { if(begin == len) //there is nothing left, collect the strings of a set; { *returnSize += 1; *colSizes = (int*)realloc(*colSizes, sizeof(int)*(*returnSize)); int size = top+1; (*colSizes)[*returnSize-1] = size; *arrs = (char***)realloc(*arrs, sizeof(char**)*(*returnSize)); (*arrs)[*returnSize-1] = (char**)malloc(sizeof(char*)*size); for(int i = 0; i < size; i++) (*arrs)[*returnSize-1][i] = stack[i]; return ; } for(int i = begin; i < len; i++) //check each string that begin with s[begin]; { int l=begin, r=i; while(l<r && s[l]==s[r]) l++, r--; if(l >= r) //it's a palindrome; { int size = i-begin+1; char *t = (char*)malloc(sizeof(char)*(size+1)); *t = '\0'; strncat(t, s+begin, size); stack[top+1] = t; traverse(s, len, i+1, stack, top+1, arrs, colSizes, returnSize); //collect the left; } } } char*** partition(char* s, int** colSizes, int* returnSize) { if(!*s) return NULL; int len = strlen(s); *returnSize = 0; *colSizes = (char*)malloc(sizeof(char)); char*** arrs = (char***)malloc(sizeof(char**)); char** stack = (char**)malloc(sizeof(char*)*len); int top = -1; traverse(s, strlen(s), 0, stack, top, &arrs, colSizes, returnSize); return arrs; }
public class Solution { public List<List<String>> partition(String s) { List<List<String>> res = new ArrayList<>(); boolean[][] dp = new boolean[s.length()][s.length()]; for(int i = 0; i < s.length(); i++) { for(int j = 0; j <= i; j++) { if(s.charAt(i) == s.charAt(j) && (i - j <= 2 || dp[j+1][i-1])) { dp[j][i] = true; } } } helper(res, new ArrayList<>(), dp, s, 0); return res; } private void helper(List<List<String>> res, List<String> path, boolean[][] dp, String s, int pos) { if(pos == s.length()) { res.add(new ArrayList<>(path)); return; } for(int i = pos; i < s.length(); i++) { if(dp[pos][i]) { path.add(s.substring(pos,i+1)); helper(res, path, dp, s, i+1); path.remove(path.size()-1); } } } } /* The normal dfs backtracking will need to check each substring for palindrome, but a dp array can be used to record the possible break for palindrome before we start recursion. Edit: Sharing my thought process: first, I ask myself that how to check if a string is palindrome or not, usually a two point solution scanning from front and back. Here if you want to get all the possible palindrome partition, first a nested for loop to get every possible partitions for a string, then a scanning for all the partitions. That's a O(n^2) for partition and O(n^2) for the scanning of string, totaling at O(n^4) just for the partition. However, if we use a 2d array to keep track of any string we have scanned so far, with an addition pair, we can determine whether it's palindrome or not by justing looking at that pair, which is this line if(s.charAt(i) == s.charAt(j) && (i - j <= 2 || dp[j+1][i-1])). This way, the 2d array dp contains the possible palindrome partition among all. second, based on the prescanned palindrome partitions saved in dp array, a simple backtrack does the job. Java DP + DFS solution by yfcheng */
bool isPalin(char* s, int end); void helper(char* s, char*** ret, int** colS, int* retS, char** cur, int k ); char*** partition(char* s, int** colS, int* retS) { *retS = 0; if(s == NULL || !strcmp(s, "")) return NULL; /* I know ... I hate static mem alloc as well */ *colS = (int*)malloc(sizeof(int)*500); char*** ret = (char***)malloc(sizeof(char**) * 500); int len = strlen(s)+1; char** cur = (char**)malloc(sizeof(char*) * 500); for(int i = 0; i<500; i++) cur[i] = (char*)malloc(len); /* backtracking starting from s[0] */ helper(s, ret, colS, retS, cur, 0); return ret; } void helper(char* s, char*** ret, int** colS, int* retS, char** cur, int k ) { /* termination if already at the end of string s we found a partition */ if(*s == 0) { ret[*retS] = (char**)malloc(sizeof(char*)*k); for(int i = 0; i<k; i++) { ret[*retS][i] = (char*)malloc(strlen(cur[i]) + 1); strcpy(ret[*retS][i], cur[i]); } (*colS)[(*retS)++] = k; return; } /* explore next */ int len = strlen(s); for(int i = 0; i < len; i++) { if(isPalin(s, i)) { /* put it into the cur list */ strncpy(cur[k], s, i+1); cur[k][i+1] = '\0'; /* backtracking */ helper(s+i+1, ret, colS, retS, cur, k+1); } } } bool isPalin(char* s, int end) { /* printf("error: start %d, end %d\n", start, end); */ if(end < 0) return false; int start = 0; while(end > start) { if(s[start] != s[end]) return false; start++; end--; } return true; } // by zcjsword Created at: September 11, 2015 5:12 AM
char*** result; int head; int check(char* s,int left,int right){ while(s[left]==s[right]){ left++,right--; } return left>=right; } int getResult(char* s,int left,int right,int path[],int index,int* colSize){ //printf("%d %d\n",left,right); if(left>right){ char** list=(char**)malloc(sizeof(char*)); int h=0; for(int i=index-1;i>0;i--){ char* tmp=(char*)malloc(sizeof(char)*(path[i-1]-path[i]+2)); int count=0; for(int j=path[i];j<path[i-1];j++){ tmp[count++]=s[j]; } tmp[count]='\0'; list[h++]=tmp; list=(char**)realloc(list,sizeof(char*)*(h+1)); } colSize[head]=h; result[head++]=list; result=(char***)realloc(result,sizeof(char**)*(head+1)); } for(int i=right;i>=left;i--){ if(check(s,i,right)){ path[index]=i; getResult(s,left,i-1,path,index+1,colSize); } } return 0; } char*** partition(char* s, int** columnSizes, int* returnSize) { result=(char***)malloc(sizeof(char**)); head=0; int path[10000]; *columnSizes=(int*)malloc(sizeof(int)*1000); path[0]=strlen(s); getResult(s,0,path[0]-1,path,1,*columnSizes); *returnSize=head; return result; } // 28ms example
#define MAXCOL 1000 void DFS(char *s,int startIndex,char **temp_result,char ***result, int len,int** columnSizes, int* returnSize) { int i,j; if(startIndex >= len) { for(i = 0;i < (*columnSizes)[*returnSize];i ++) { for(j = 0;temp_result[i][j] != '\0';j ++) { result[*returnSize][i][j] = temp_result[i][j]; } result[*returnSize][i][j] = '\0'; } *returnSize += 1; (*columnSizes)[*returnSize] = (*columnSizes)[*returnSize-1]; } for(i = startIndex;i < len;i ++) { int left = startIndex; int right = i; while(left <= right && s[left]==s[right]) { left ++; right --; } if(left >= right) { strncpy(temp_result[(*columnSizes)[*returnSize]],s+startIndex,i - startIndex + 1); temp_result[(*columnSizes)[*returnSize]][i - startIndex + 1] = '\0'; (*columnSizes)[*returnSize] += 1; //printf("OK\n"); DFS(s,i+1,temp_result,result,len,columnSizes,returnSize); (*columnSizes)[*returnSize] -= 1; } } } char*** partition(char* s, int** columnSizes, int* returnSize) { int i,j,k; int len = strlen(s); char ***result = malloc(MAXCOL*sizeof(char**)); for(i = 0;i < MAXCOL;i ++) { result[i] = malloc(len*sizeof(char*)); for(j = 0;j < len;j ++) { result[i][j] = malloc(len*sizeof(char)); } } char **temp_result = malloc(len*sizeof(char*)); for(i = 0;i < len;i ++) { temp_result[i] = malloc(len*sizeof(char)); } *columnSizes = calloc(MAXCOL,sizeof(int)); *returnSize = 0; DFS(s,0,temp_result,result,len,columnSizes,returnSize); return result; } // 52ms example

 浙公网安备 33010602011771号
浙公网安备 33010602011771号