LSTM长短期记忆递归神经网络
当前项目中用到自动学习,这部分在读书期间学得比较泛,没有深入。加之,时间一长,学得都还给老师了。今天重温LSTM.
0. 什么是LSTM
LSTM,全称 Long Short Term Memory (长短期记忆) 是一种特殊的递归神经网络 。这种网络与一般的前馈神经网络不同,
LSTM可以利用时间序列对输入进行分析;简而言之,当使用前馈神经网络时,神经网络会认为我们 t 时刻输入的内容与
t+1 时刻输入的内容完全无关,对于许多情况,例如图片分类识别,这是毫无问题的,可是对于一些情景,例如自然语
言处理 (NLP, Natural Language Processing) 或者我们需要分析类似于连拍照片这样的数据时,合理运用 t或之前的输入
来处理 t+n 时刻显然可以更加合理的运用输入的信息。为了运用到时间维度上信息,人们设计了递归神经网络 (RNN,
Recurssion Neural Network),一个简单的递归神经网络可以用这种方式表示
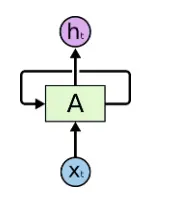
在图中, xt是在 t 时刻的输入信息, ℎt 是在 t时刻的输入信息,我们可以看到神经元A会递归的调用自身并且
将 t−1 时刻的信息传递给t 时刻。递归神经网络在许多情况下运行良好,特别是在对短时间序列数据的分析时
十分方便。但是,注意到前面着重强调了“短”,这是为什么呢?
上图所示的简单递归神经网络存在一个“硬伤“,长期依赖问题:递归神经网络只能处理我们需要较接近的上
下文的情况:
Example 1. 想象现在设计了一个基于简单RNN的句子自动补全器,当我输入"Sea is ..." 的时候会自动补全为"Sea is blue"。
在这种情况下,我们需要获取从上文获取的信息极短,而RNN可以很好的收集到 t=0 时的信息"Sea"并且补上"blue"
Example 2. 现在,假设我们用刚刚的RNN试图补全一篇文章"我一直呆在中国,……,我会说一口流利的 (?)"。
在这里,为了补全最后的空缺,需要的信息在非常远的上文(e.g. 200+字前)提到的”中国“。在实验中简单的理想状态下,
经过精心调节的RNN超参数可以良好的将这些信息向后传递。可是在现实的情况中,基本没有RNN可以做到这一点。一些
学者后来研究发现RNN的长期依赖问题是这种网络结构本身的问题。
不但如此,相比于一般的神经网络,这种简单的RNN还很容易出现两种在神经网络中臭名昭著的问题:梯度消失问题(神经
网络的权重/偏置梯度极小,导致神经网络参数调整速率急剧下降)和梯度爆炸问题(神经网络的权重/偏置梯度极大,导致神经
网络参数调整幅度过大,矫枉过正)。相信大家都看过一个著名的鸡汤, (0.99)365 和 (1.01)365 的对比。实际上,这个鸡汤
非常好的描述了梯度问题的本质:对于任意信息递归使用足够多次同样的计算,都会导致极大或极小的结果,也就是说…
根据微分链式法则,在RNN中,神经元的权重的梯度可以被表示为一系列函数的微分的连乘。因为神经元的参数(权重与偏置)
都是基于学习速率(一般为常数)和参数梯度相反数(使得神经网络输出最快逼近目标输出)得到的,一个过小或过大的梯度会
导致我们要么需要极长的训练时间(本来从-2.24 调节到 -1.99 只用500个样本,由于梯度过小,每次只调 10−6 ,最后用了几万
个样本),要么会导致参数调节过度(例如本来应该从-10.02调节到-9.97,由于梯度过大,直接调成了+20.3)
1. 为什么需要LSTM
LSTM从被设计之初就被用于解决一般递归神经网络中普遍存在的长期依赖问题,使用LSTM可以有效的传递和表达长时间序列
中的信息并且不会导致长时间前的有用信息被忽略(遗忘)。与此同时,LSTM还可以解决RNN中的梯度消失/爆炸问题。
2. LSTM 的直觉解释
LSTM的设计或多或少的借鉴了人类对于自然语言处理的直觉性经验。要想了解LSTM的工作机制,可以先阅读一下一个(虚构的)
淘宝评论:
“这个笔记本非常棒,纸很厚,料很足,用笔写起来手感非常舒服,而且没有一股刺鼻的油墨味;更加好的是这个笔记本不但便
宜还做工优良,我上次在别家买的笔记本裁纸都裁不好,还会割伤手……”
如果让你看完这段话以后马上转述,相信大多数人都会提取出来这段话中几个重要的关键词“纸好”,“没味道”,“便宜”和“做工好”,
然后再重新组织成句子进行转述。这说明了以下两点:
- 在一个时间序列中,不是所有信息都是同等有效的,大多数情况存在“关键词”或者“关键帧”
- 我们会在从头到尾阅读的时候“自动”概括已阅部分的内容并且用之前的内容帮助理解后文
基于以上这两点,LSTM的设计者提出了“长短期记忆”的概念——只有一部分的信息需要长期的记忆,而有的信息可以不记下来。
同时,我们还需要一套机制可以动态的处理神经网络的“记忆”,因为有的信息可能一开始价值很高,后面价值逐渐衰减,这时候
我们也需要让神经网络学会“遗忘”特定的信息
3. LSTM的具体解释
一个普通的,使用tanh函数的RNN可以这么表示:
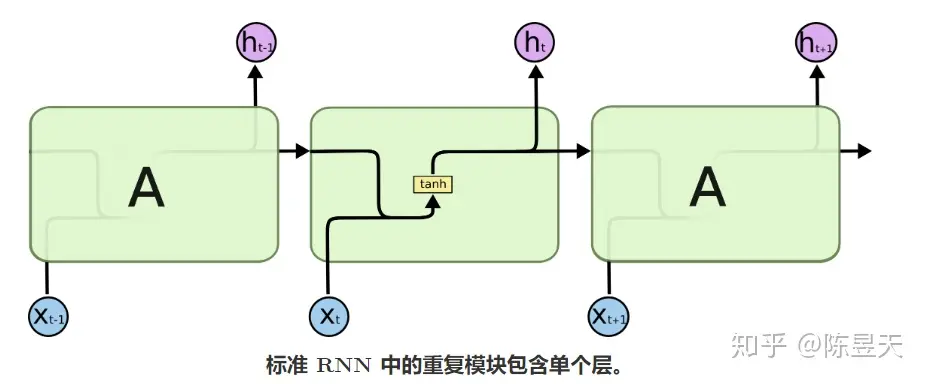
在这里,我们可以看到A在 t−1 时刻的输出值 ℎt−1 被复制到了 t 时刻,与 t时刻的输入xt 整合后经过一个带权重和偏置的
tanh函数后形成输出,并继续将数据复制到 t+1 时刻……
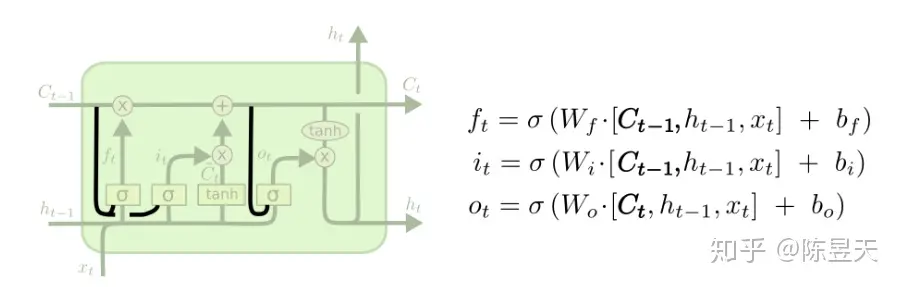
与上图朴素的RNN相比,单个LSTM单元拥有更加复杂的内部结构和输入输出:
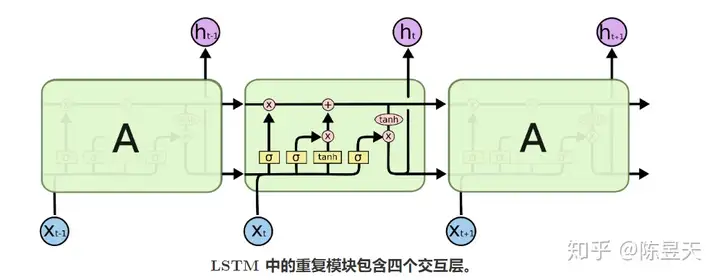
在上图中,每一个红色圆形代表对向量做出的操作(pointwise operation, 对位操作),而黄色的矩形代表一个
神经网络层,上面的字符代表神经网络所使用的激活函数

LSTM的关键:单元状态
LSTM能够从RNN中脱颖而出的关键就在于上图中从单元中贯穿而过的线 ——神经元的隐藏态(单元状态),我们
可以将神经元的隐藏态简单的理解成递归神经网络对于输入数据的“记忆”,用Ct表示神经元在 t时刻过后的“记忆”,
这个向量涵盖了在 t+1 时刻前神经网络对于所有输入信息的“概括总结”
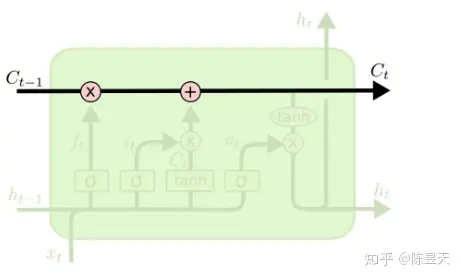
接下来会描述一下LSTM四个函数层分别在做些什么
LSTM_1 遗忘门
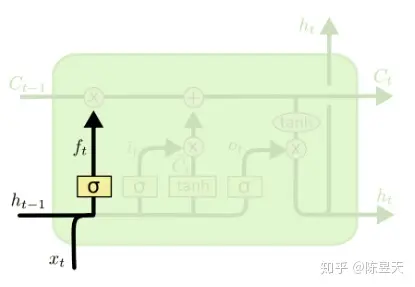
对于上一时刻LSTM中的单元状态来说,一些“信息”可能会随着时间的流逝而“过时”。为了不让过多记忆影
响神经网络对现在输入的处理,我们应该选择性遗忘一些在之前单元状态中的分量——这个工作就交给了
“遗忘门”每一次输入一个新的输入,LSTM会先根据新的输入和上一时刻的输出决定遗忘掉之前的哪些记
忆——输入和上一步的输出会整合为一个单独的向量,然后通过sigmoid神经层,最后点对点的乘在单元
状态上。因为sigmoid 函数会将任意输入压缩到 (0,1) 的区间上,我们可以非常直觉的得出这个门的工作
原理 —— 如果整合后的向量某个分量在通过sigmoid层后变为0,那么显然单元状态在对位相乘后对应的
分量也会变成0,换句话说,“遗忘”了这个分量上的信息;如果某个分量通过sigmoid层后为1,单元状态会
“保持完整记忆”。不同的sigmoid输出会带来不同信息的记忆与遗忘。通过这种方式,LSTM可以长期记忆
重要信息,并且记忆可以随着输入进行动态调整
下面的公式可以用来描述遗忘门的计算,其中 ft 就是sigmoid神经层的输出向量:
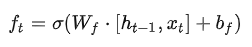
LSTM_2 & 3 记忆门
记忆门是用来控制是否将在t时刻(现在)的数据并入单元状态中的控制单位。首先,用tanh函数层将现
在的向量中的有效信息提取出来,然后使用(图上tanh函数层左侧)的sigmoid函数来控制这些记忆要放
“多少”进入单元状态。这两者结合起来就可以做到:
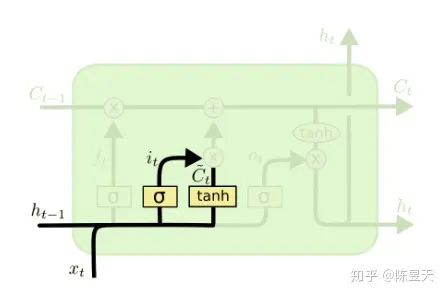
- 从当前输入中提取有效信息
- 对提取的有效信息做出筛选,为每个分量做出评级(0 ~ 1),评级越高的最后会有越多的记忆进入单元状态
下面的公式可以分别表示这两个步骤在LSTM中的计算:
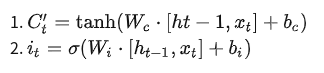
LSTM_4 输出门
输出门,顾名思义,就是LSTM单元用于计算当前时刻的输出值的神经层。输出层会先将当前输入值与上一时
刻输出值整合后的向量(也就是公式中的 [ℎt−1,xt] )用sigmoid函数提取其中的信息,接着,会将当前的
单元状态通过tanh函数压缩映射到区间(-1, 1)中*
为什么我们要在LSTM的输出门上使用tanh函数?
以下引用自Stack Overflow上问题 What is the intuition of using tanh in LSTM 中的最佳答案:
https://stackoverflow.com/questions/40761185/what-is-the-intuition-of-using-tanh-in-lstm
在LSTM的输入和输出门中使用tanh函数有以下几个原因:
1. 为了防止梯度消失问题,我们需要一个二次导数在大范围内不为0的函数,而tanh函数可以满足这一点
2. 为了便于凸优化,我们需要一个单调函数
3. tanh函数一般收敛的更快
4. tanh函数的求导占用系统的资源更少
将经过tanh函数处理后的单元状态与sigmoid函数处理后的,整合后的向量点对点的乘起来就可以得到LSTM在t 时刻的输出了!
4. LSTM 的变体
自从LSTM在自然语言处理等方面大获成功后,许多种LSTM的变体被提出,其中只有几种值得特别关注:
这种LSTM让各个门都可以在获得了上一时刻的单元状态的前提下进行运算。在上面的图中,单元状态被额外赋予到了所有三个层中(输出门除外),
然而在实际的应用中,大部分研究者只会选择性的打开三个通道中的一或两个
除此之外,还有很多其他LSTM变体以及通过其他方式构建RNN达到类似LSTM的效果的架构,然而这些架构的效率都大同小异,所以不过多说明了
5. 参考资料
[1] “Understanding LSTM Networks.” Understanding LSTM Networks -- Colah's Blog, http://colah.github.io/posts/2015-08-Understanding-LSTMs/.
[2] “Long Short-Term Memory.” Wikipedia, Wikimedia Foundation, 1 Apr. 2020, http://en.wikipedia.org/wiki/Long_short-term_memory.
[3] “LSTM以及三重门,遗忘门,输入门,输出门.” LSTM以及三重门,遗忘门,输入门,输出门_网络_Lison_Zhu's Blog-CSDN博客, http://blog.csdn.net/Lison_Zhu/article/details/97236501.
[4] “递归神经网络问题整理.” 递归神经网络问题整理_网络_leo鱼的博客-CSDN博客, http://blog.csdn.net/webzjuyujun/article/details/71124695.
[5] “详解机器学习中的梯度消失、爆炸原因及其解决方法.” 详解机器学习中的梯度消失、爆炸原因及其解决方法_网络_Double_V的博客-CSDN博客, http://blog.csdn.net/qq_25737169/article/details/78847691.
[6] Dnkdnk. “What Is the Intuition of Using Tanh in LSTM.” Stack Overflow, 1 Sept. 1966, http://stackoverflow.com/questions/40761185/what-is-the-intuition-of-using-tanh-in-lstm.
转自:LSTM

