


Python 分部分项 数据处理2 桂柳
excel格式
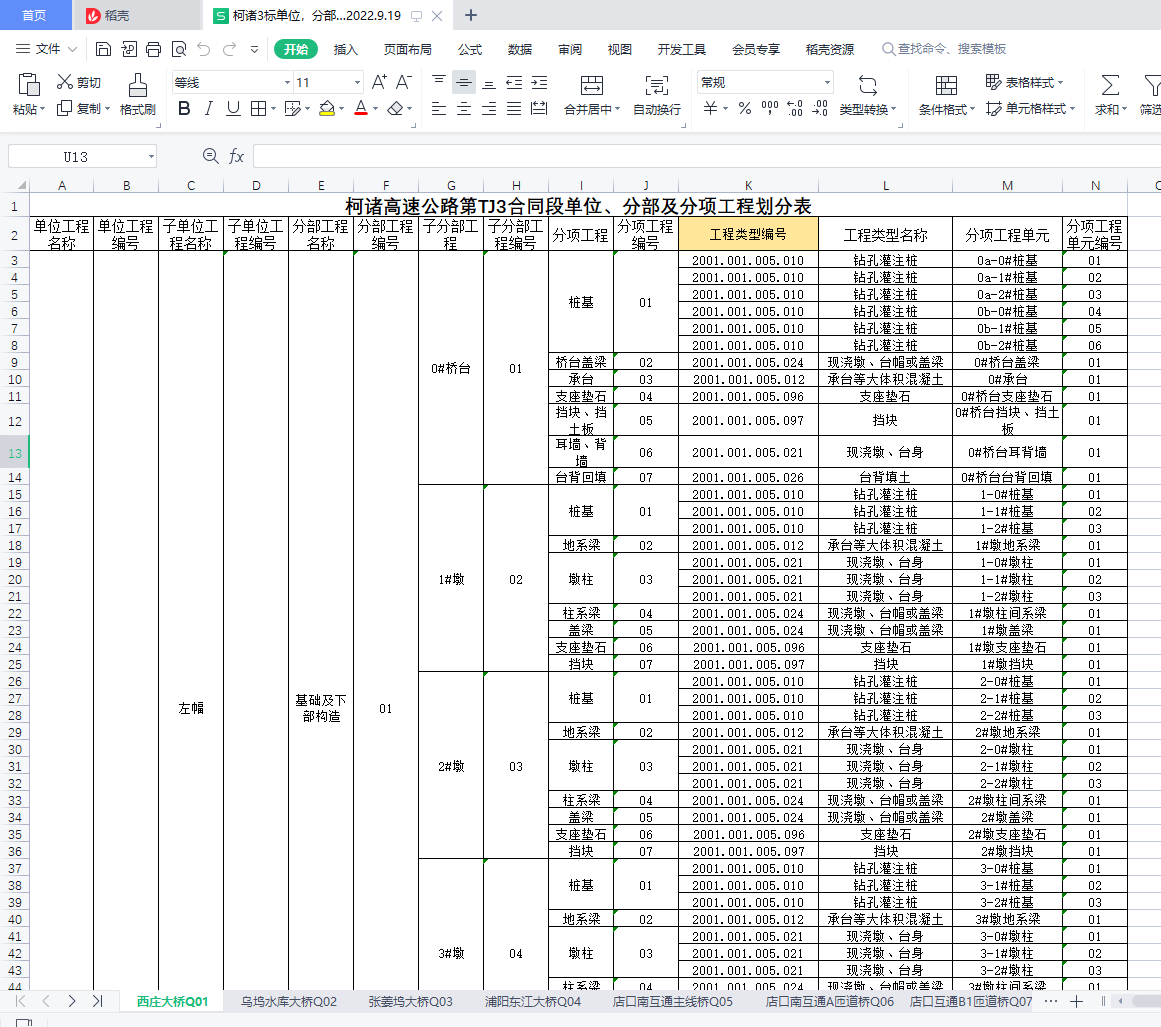
最终效果
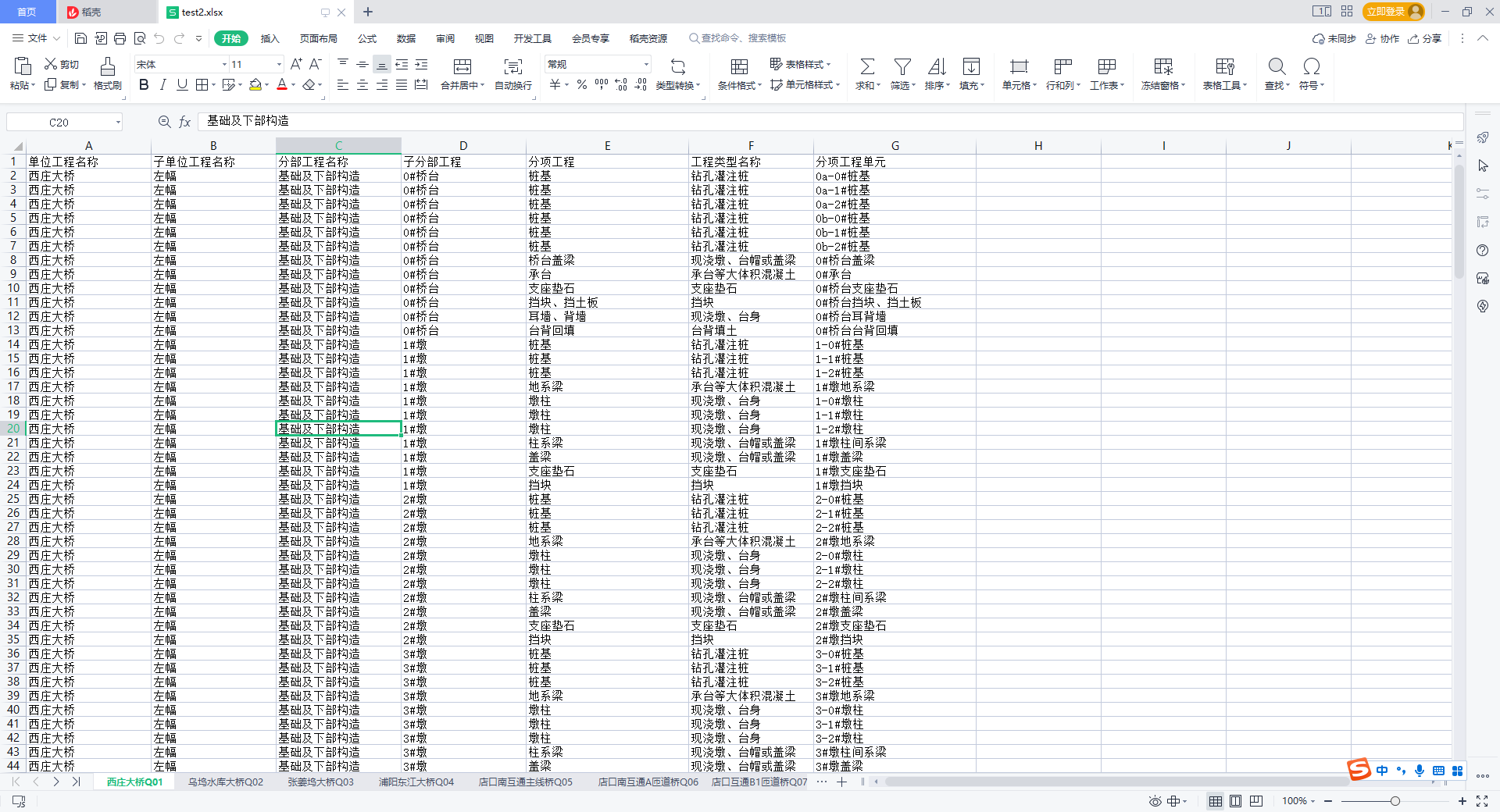
python代码
import os
import openpyxl
from openpyxl import Workbook
from copy import deepcopy
from openpyxl.utils import get_column_letter
# 原文:https://www.cnblogs.com/liuda9495/p/9039732.html
workbook2 = Workbook()
def create_worksheet(path):
#path='test1.xlsx'
workbook = openpyxl.load_workbook(path)# 加载excel
name_list = workbook.sheetnames# 所有sheet的名字
for index, value in enumerate(name_list):
print(index, value)
worksheet = workbook[name_list[index]]# 读取第一个工作表
# 获取所有 合并单元格的 位置信息
# 是个可迭代对象,单个对象类型:openpyxl.worksheet.cell_range.CellRange
# print后就是excel坐标信息
m_list = worksheet.merged_cells
l = deepcopy(m_list)# 深拷贝
# 拆分合并的单元格 并填充内容
for m_area in l:
# 这里的行和列的起始值(索引),和Excel的一样,从1开始,并不是从0开始(注意)
r1, r2, c1, c2 = m_area.min_row, m_area.max_row, m_area.min_col, m_area.max_col
worksheet.unmerge_cells(start_row=r1, end_row=r2, start_column=c1, end_column=c2)
#print('区域:', m_area, ' 坐标:', r1, r2, c1, c2)
# 获取一个单元格的内容
first_value = worksheet.cell(r1, c1).value
# 数据填充
for r in range(r1, r2+1):# 遍历行
if c2 - c1 > 0:# 多个列,遍历列
for c in range(c1, c2+1):
worksheet.cell(r, c).value = first_value
else:# 一个列
worksheet.cell(r, c1).value = first_value
# 删除行
#worksheet.delete_rows(2)
worksheet.delete_rows(1)
# 首列批量填充数据
worksheet2 = workbook2.create_sheet(name_list[index])
for x in range(worksheet.max_row):
r = x+1
for y in range(worksheet.max_column):
c = y+1
worksheet2.cell(r, c).value = worksheet.cell(r, c).value
# 编号列删除
for y in range(worksheet.max_column, 0, -1):
c = y
r = 1
cellValue = worksheet.cell(r, c).value
if cellValue is not None:
if "编号" in cellValue:
worksheet2.delete_cols(y)
# 列宽度自适应
for y in range(worksheet.max_column):
column_width = 10
for x in range(worksheet.max_row):
c = y+1
r = x+1
cellLength = 10
cellValue = worksheet.cell(r, c).value
if cellValue is not None:
if type(cellValue) == int:
cellLength = 10
else:
cellLength = len(cellValue)
if cellLength > column_width:
column_width = cellLength
column_NameEn = get_column_letter(y + 1)
worksheet2.column_dimensions[column_NameEn].width = column_width * 2
def each_files():
pathDir = os.listdir('./files/')
for index, value in enumerate(pathDir):
filepath2 = './files/' + value
print(filepath2)
create_worksheet(filepath2)
each_files()
workbook2.save('test2.xlsx')
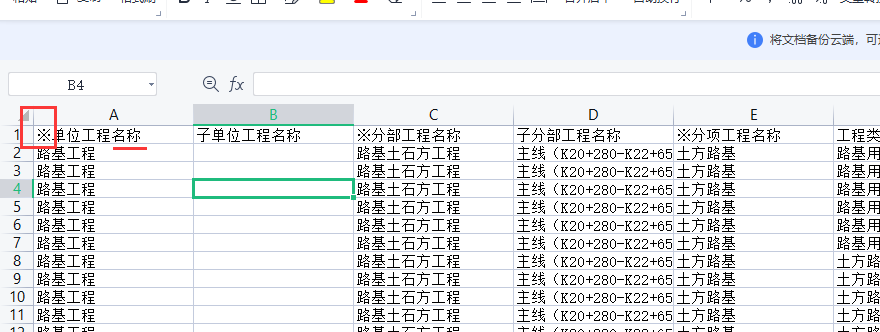
SQL语句特殊处理
要去掉这个这些

select * from Projects2
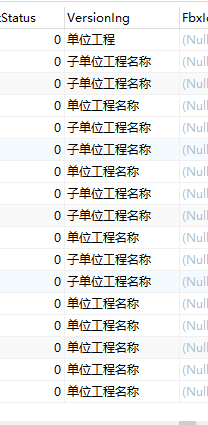
select VersionIng, REPLACE(VersionIng, '名称', '') from Projects2
update Projects2 set VersionIng=REPLACE(VersionIng, '名称', '')
update Projects2 set VersionIng=REPLACE(VersionIng, '※', '')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2020-09-26 数据分析 一些基本的知识