实验5_C语言指针应用编程
任务1_1
#include <stdio.h> #define N 5 void input(int x[], int n); void output(int x[], int n); void find_min_max(int x[], int n, int *pmin, int *pmax); int main() { int a[N]; int min, max; printf("录入%d个数据:\n", N); input(a, N); printf("数据是: \n"); output(a, N); printf("数据处理...\n"); find_min_max(a, N, &min, &max); printf("输出结果:\n"); printf("min = %d, max = %d\n", min, max); return 0; } void input(int x[], int n) { int i; for(i = 0; i < n; ++i) scanf("%d", &x[i]); } void output(int x[], int n) { int i; for(i = 0; i < n; ++i) printf("%d ", x[i]); printf("\n"); } void find_min_max(int x[], int n, int *pmin, int *pmax) { int i; *pmin = *pmax = x[0]; for(i = 0; i < n; ++i) if(x[i] < *pmin) *pmin = x[i]; else if(x[i] > *pmax) *pmax = x[i]; }
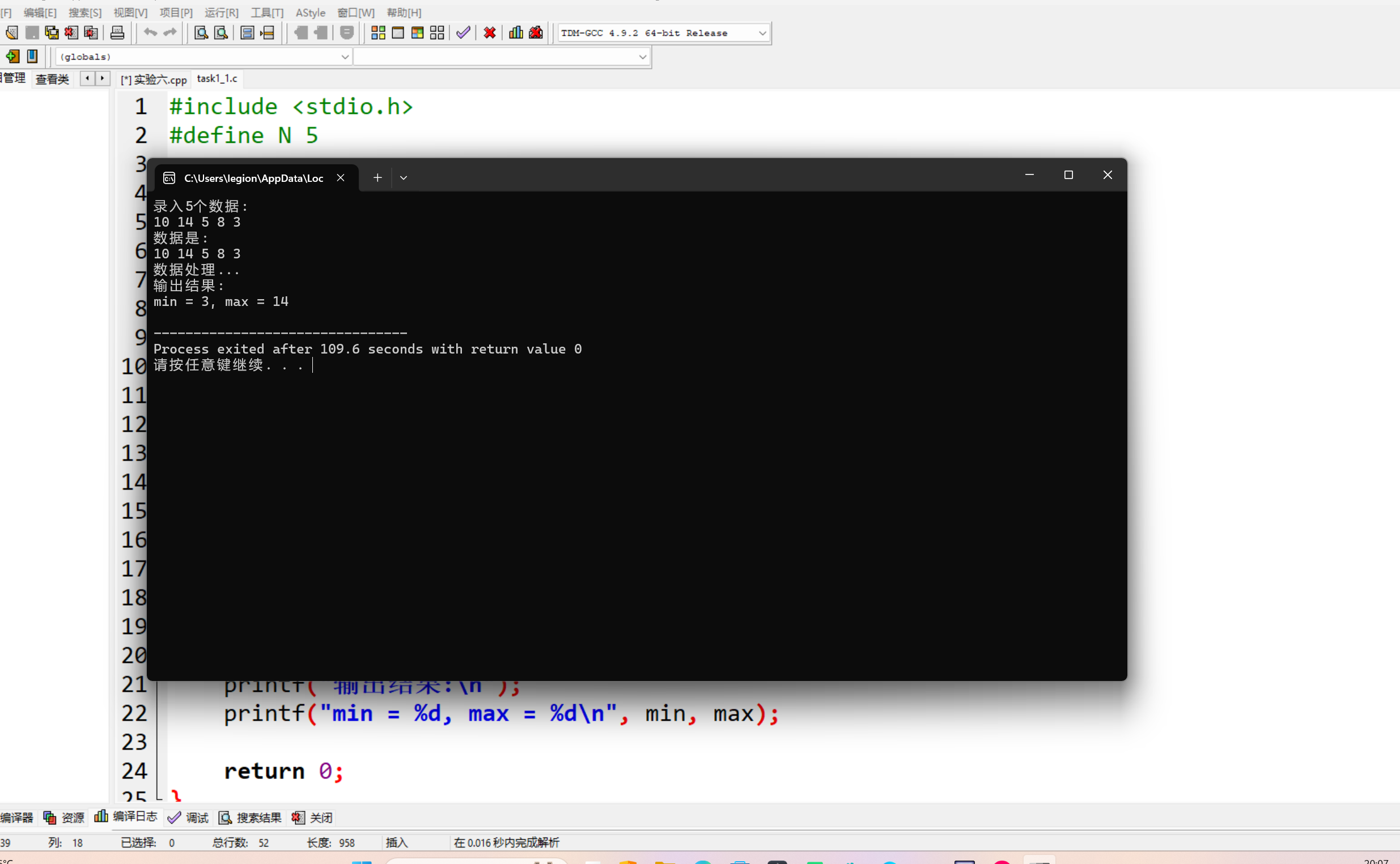
1.函数 find_min_max 的功能是在给定的整数数组 x 中查找数组元素的最小值和最大值。
main 函数中,定义了两个整型变量 min 和 max,然后调用 find_min_max 函数时,传递的是这两个变量的地址(通过 &min 和 &max)。line45(即 find_min_max 函数内部的代码开始执行时),指针变量 pmin 指向的是 main 函数中定义的变量 min 的地址,指针变量 pmax 指向的是 main 函数中定义的变量 max 的地址。这样,在 find_min_max 函数中对 *pmin 和 *pmax 的操作,实际就是在操作 main 函数中对应的 min 和 max 这两个变量,从而可以将找到的最小值和最大值传递回 main 函数中。#include <stdio.h> #define N 5 void input(int x[], int n); void output(int x[], int n); int *find_max(int x[], int n); int main() { int a[N]; int *pmax; printf("录入%d个数据:\n", N); input(a, N); printf("数据是: \n"); output(a, N); printf("数据处理...\n"); pmax = find_max(a, N); printf("输出结果:\n"); printf("max = %d\n", *pmax); return 0; } void input(int x[], int n) { int i; for(i = 0; i < n; ++i) scanf("%d", &x[i]); } void output(int x[], int n) { int i; for(i = 0; i < n; ++i) printf("%d ", x[i]); printf("\n"); } int *find_max(int x[], int n) { int max_index = 0; int i; for(i = 0; i < n; ++i) if(x[i] > x[max_index]) max_index = i; return &x[max_index]; }
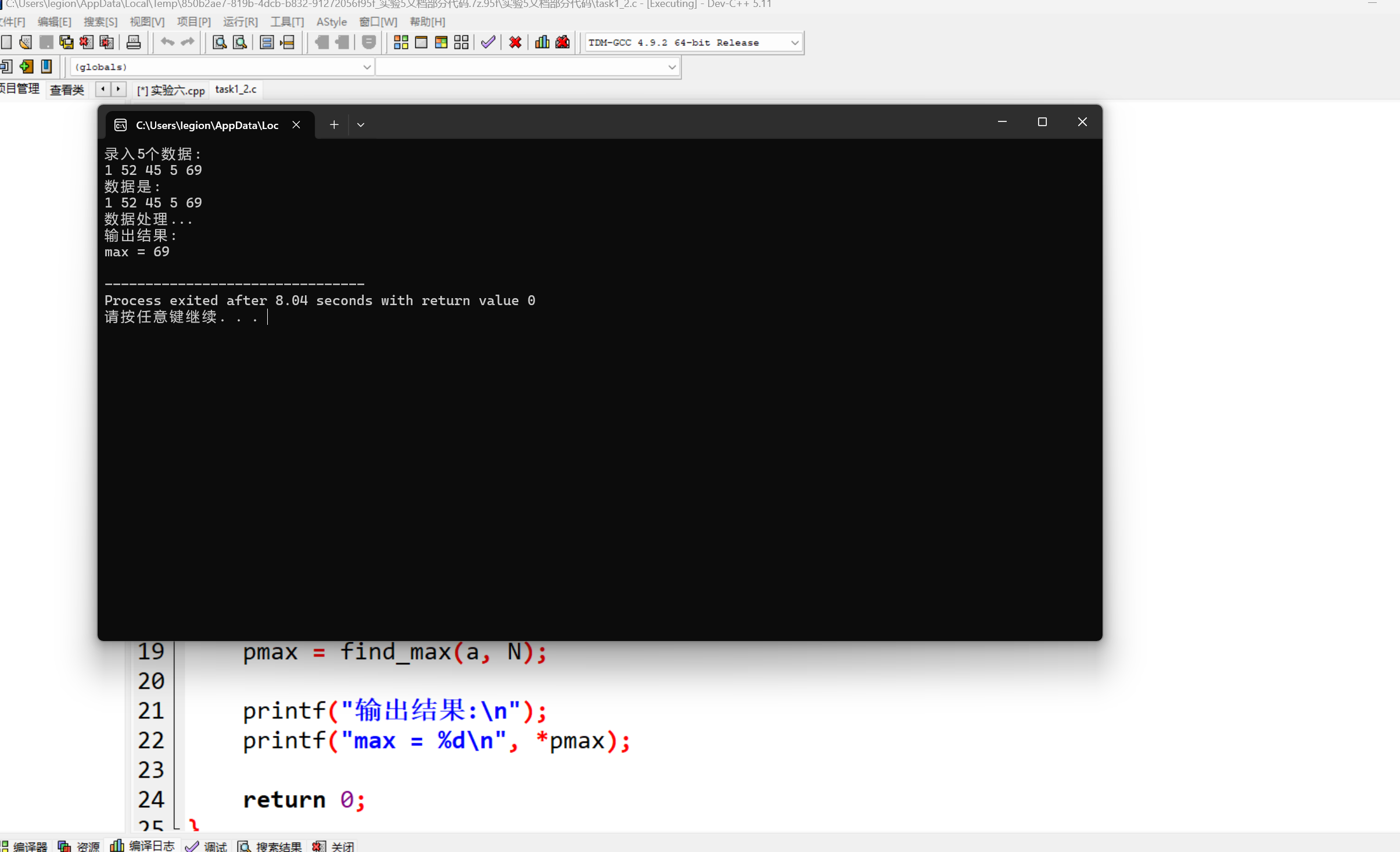
1.函数 find_max 的功能是在给定的整数数组 x 中查找数组元素的最大值,并返回指向该最大值所在数组元素的指针。
2.不可以。当传入的数组 x 为空数组(即 n == 0 时),代码中直接初始化为 &x[0] 会导致数组越界访问错误,因为空数组不存在 x[0] 这个元素。而原 find_max 函数虽然没有对空数组情况做特殊处理(严格来说也应该做处理更好),但它至少是基于有元素的情况去比较和记录索引,相对来说更不容易出现因空数组引发的崩溃性错误。
任务2_1
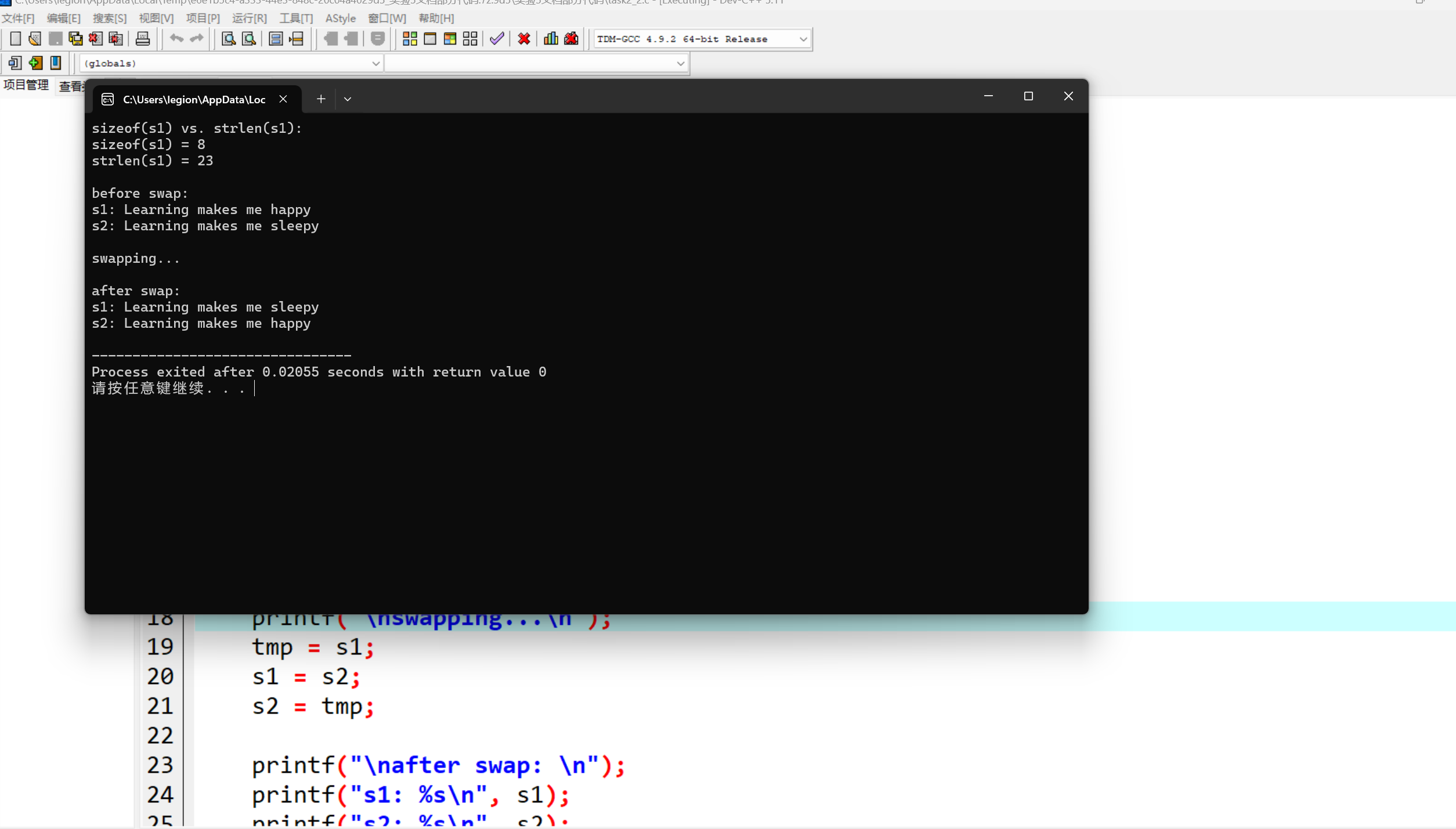
#include <stdio.h> #include <string.h> #define N 80 int main() { char s1[N] = "Learning makes me happy"; char s2[N] = "Learning makes me sleepy"; char tmp[N]; printf("sizeof(s1) vs. strlen(s1): \n"); printf("sizeof(s1) = %d\n", sizeof(s1)); printf("strlen(s1) = %d\n", strlen(s1)); printf("\nbefore swap: \n"); printf("s1: %s\n", s1); printf("s2: %s\n", s2); printf("\nswapping...\n"); strcpy(tmp, s1); strcpy(s1, s2); strcpy(s2, tmp); printf("\nafter swap: \n"); printf("s1: %s\n", s1); printf("s2: %s\n", s2); return 0; }
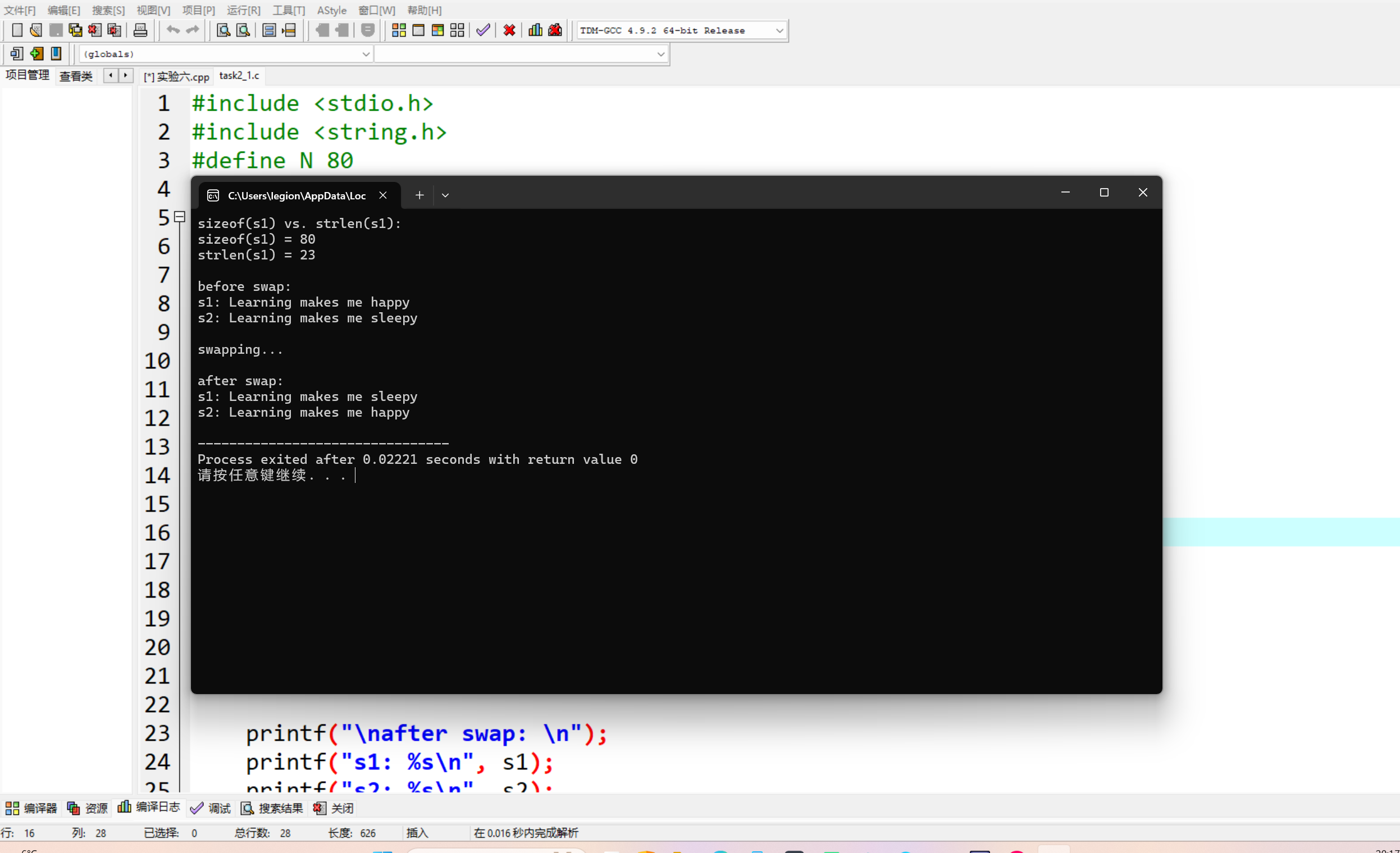
1.根据代码中定义 char s1[N],且 #define N 80,所以数组 s1 的大小是 80 个字节。
sizeof(s1) 计算的是整个字符数组 s1 在内存中所占用的字节数。
strlen(s1) 函数用于统计字符串 s1 中有效字符的个数,它从字符串的起始位置开始,依次向后计数,直到遇到字符串结束标志 '\0' 为止(不包含 '\0' 这个字符本身)。
2.这样的写法是不可以的。在 C 语言中,数组名代表的是数组首元素的地址,一旦数组被定义,数组名就成为了一个常量指针,它不能再被重新赋值指向其他内存区域,也就是不能像普通变量那样通过赋值语句来改变它所代表的地址。如果要给字符数组 s1 赋值字符串 "Learning makes me happy",可以使用像 strcpy 函数这样的字符串操作函数来实现,例如 strcpy(s1, "Learning makes me happy");,它会将给定字符串的内容逐个字符复制到字符数组 s1 对应的内存空间中,覆盖原来可能存在的内容,同时保证在末尾添加字符串结束标志 '\0'。
3.line19 - 21(也就是 strcpy(tmp, s1); strcpy(s1, s2); strcpy(s2, tmp); 这三行代码执行后,字符数组 s1 和 s2 中的内容是实现了交换的。
strcpy(tmp, s1);:首先通过strcpy函数将s1中的字符串(初始为"Learning makes me happy")完整地复制到临时字符数组tmp中,此时tmp中存储了和s1原来一样的字符串内容。strcpy(s1, s2);:接着,再使用strcpy函数将s2中的字符串(初始为"Learning makes me sleepy")复制到s1中,这样s1的内容就被替换成了原来s2的内容。strcpy(s2, tmp);:最后,把临时数组tmp中保存的原来s1的字符串内容复制到s2中,经过这三步操作,就成功实现了s1和s2中字符串内容的交换。
任务2_2
#include <stdio.h> #include <string.h> #define N 80 int main() { char *s1 = "Learning makes me happy"; char *s2 = "Learning makes me sleepy"; char *tmp; printf("sizeof(s1) vs. strlen(s1): \n"); printf("sizeof(s1) = %d\n", sizeof(s1)); printf("strlen(s1) = %d\n", strlen(s1)); printf("\nbefore swap: \n"); printf("s1: %s\n", s1); printf("s2: %s\n", s2); printf("\nswapping...\n"); tmp = s1; s1 = s2; s2 = tmp; printf("\nafter swap: \n"); printf("s1: %s\n", s1); printf("s2: %s\n", s2); return 0; }
1.指针变量 s1 存放的是字符串常量 "Learning makes me happy" 在内存中的首地址。
sizeof(s1) 计算的是指针变量 s1 自身在内存中所占用的字节数。
strlen(s1) 函数从指针 s1 所指向的内存地址开始,逐个字符向后统计,直到遇到字符串结束标志 '\0' 为止(不包含 '\0' 字符本身),统计出的是从该起始地址开始的字符串中有效字符的个数。
2.可以
char *s1 = "Learning makes me happy"; 的语义:
在定义指针变量 s1 的同时进行初始化,直接将 s1 初始化为指向字符串常量 "Learning makes me happy" 在内存中的存储位置,这是一种常见的在定义指针时就赋予其初始值的方式,一步完成了变量定义和赋值指向的操作。
char *s1; s1 = "Learning makes me happy"; 的语义:
先是声明了一个 char 类型的指针变量 s1,此时 s1 的值是未确定的,然后在下一行通过赋值语句 s1 = "Learning makes me happy"; 将 s1 明确指向了字符串常量 "Learning makes me happy" 在内存中的存储位置,是分两步完成了指针变量的定义和让其指向特定字符串的操作。
3.line19 - 21(即 tmp = s1; s1 = s2; s2 = tmp; 这三行代码)交换的是指针变量 s1 和 s2 的值,也就是改变了 s1 和 s2 这两个指针所指向的内存地址。
字符串常量 "Learning makes me happy" 和 "Learning makes me sleepy" 在内存中并没有交换。这两个字符串常量在程序编译时就被分配到了只读的内存区域,其存储位置是固定不变的,代码中只是交换了指向它们的指针变量的值,从而使得通过 s1 和 s2 去访问字符串时,访问到的对象发生了改变,但字符串常量本身在内存中的物理存储位置并未改变。
任务3
#include <stdio.h> int main() { int x[2][4] = {{1, 9, 8, 4}, {2, 0, 4, 9}}; int i, j; int *ptr1; // 指针变量,存放int类型数据的地址 int(*ptr2)[4]; // 指针变量,指向包含4个int元素的一维数组 printf("输出1: 使用数组名、下标直接访问二维数组元素\n"); for (i = 0; i < 2; ++i) { for (j = 0; j < 4; ++j) printf("%d ", x[i][j]); printf("\n"); } printf("\n输出2: 使用指针变量ptr1(指向元素)间接访问\n"); for (ptr1 = &x[0][0], i = 0; ptr1 < &x[0][0] + 8; ++ptr1, ++i) { printf("%d ", *ptr1); if ((i + 1) % 4 == 0) printf("\n"); } printf("\n输出3: 使用指针变量ptr2(指向一维数组)间接访问\n"); for (ptr2 = x; ptr2 < x + 2; ++ptr2) { for (j = 0; j < 4; ++j) printf("%d ", *(*ptr2 + j)); printf("\n"); } return 0; }
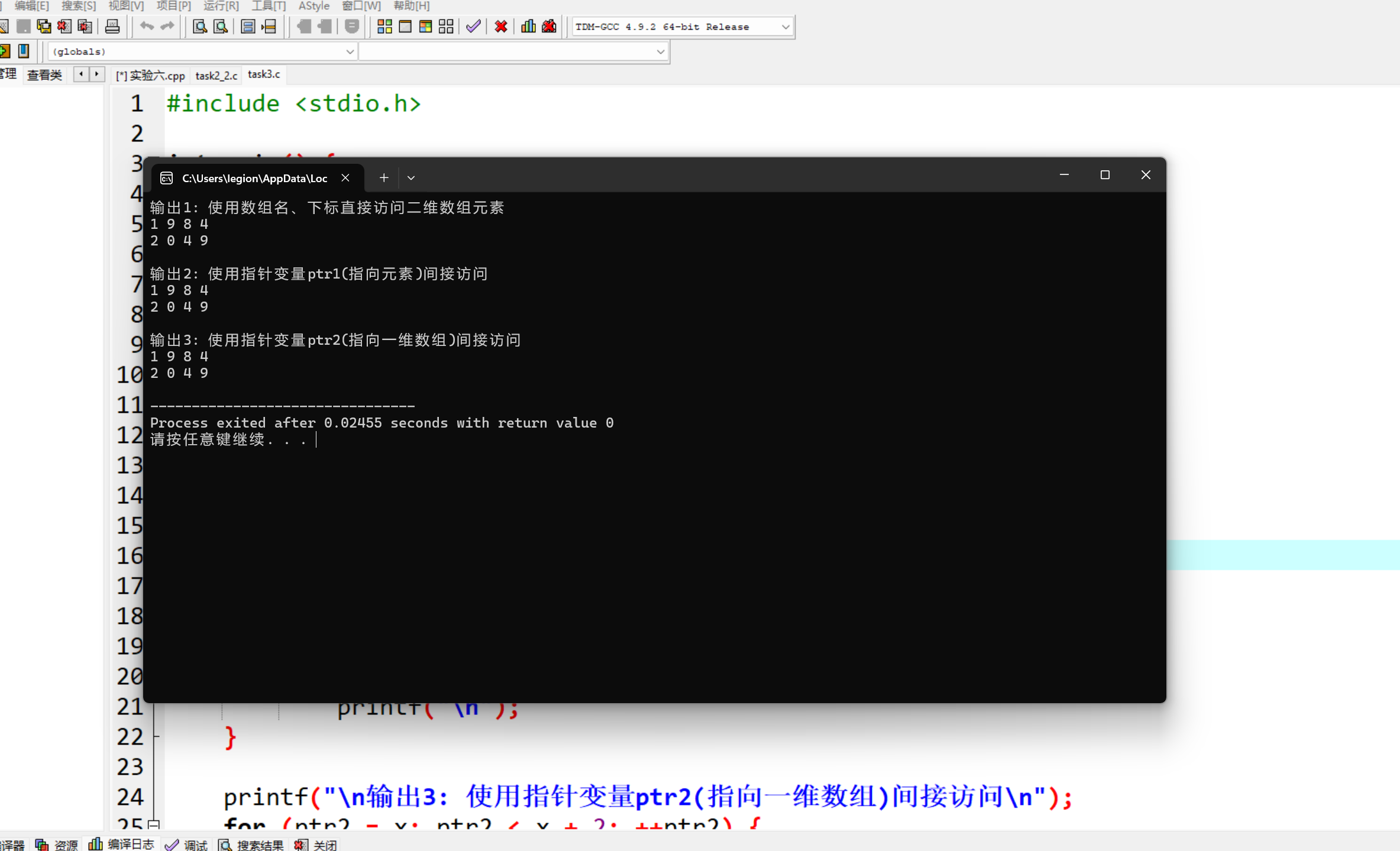
1.int (*ptr)[4]; 定义了一个指针变量 ptr,它是一个指向包含 4 个 int 类型元素的一维数组的指针。也就是说,ptr 所指向的内存区域可以看作是连续存放着 4 个 int 类型数据的一段内存空间,通过这个指针可以操作整个这样的一维数组。
2.int *ptr[4]; 定义的是一个数组,名为 ptr,该数组包含 4 个元素,每个元素的类型都是 int 类型的指针(即 int*)。可以理解为这个数组 ptr 是用来存放 4 个指向 int 类型数据的指针的数组。
任务4
#include <stdio.h> #define N 80 void replace(char *str, char old_char, char new_char); // 函数声明 int main() { char text[N] = "Programming is difficult or not, it is a question."; printf("原始文本: \n"); printf("%s\n", text); replace(text, 'i', '*'); // 函数调用 注意字符形参写法,单引号不能少 printf("处理后文本: \n"); printf("%s\n", text); return 0; } // 函数定义 void replace(char *str, char old_char, char new_char) { int i; while(*str) { if(*str == old_char) *str = new_char; str++; } }
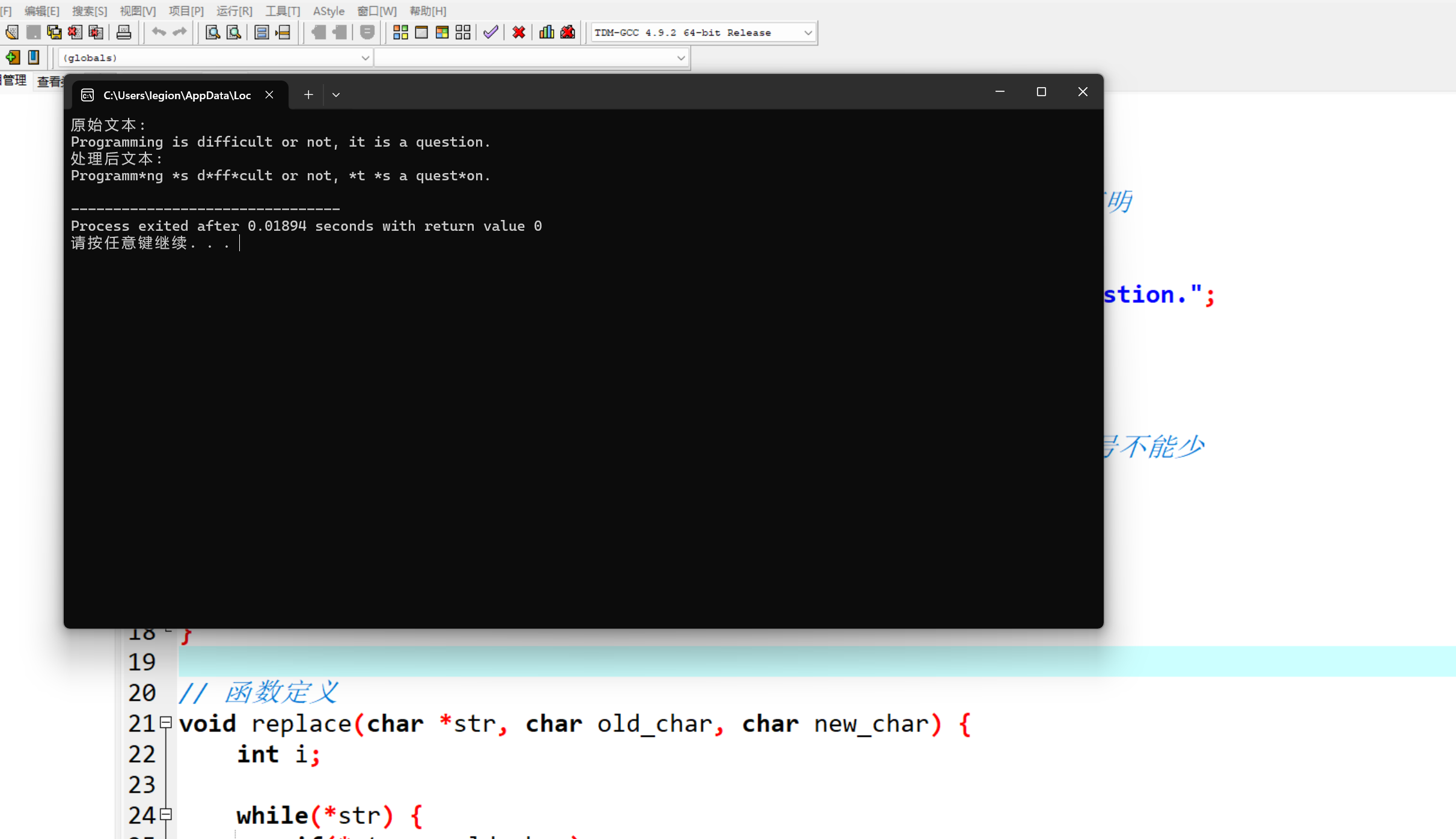
1.函数 replace 的功能是在给定的字符串 str 中,将所有出现的特定字符 old_char 替换为另一个指定字符 new_char。
2.可以改写成 *str!= '\0',这两种写法在功能上是完全等价的。字符串的末尾是以 '\0'(空字符)作为结束标志的,当通过指针遍历字符串时,判断当前指针所指向的字符是否为 '\0' 就可以确定是否到达了字符串的末尾。原代码中使用 while(*str) 来作为循环条件,其本质就是利用了 C 语言中当字符值为 '\0' 时对应的逻辑假,而其他非 '\0' 的字符值对应的逻辑真这一特性,来实现只要当前字符不是 '\0' 就继续循环遍历字符串的目的。
任务五
#include <stdio.h> #define N 80 char *str_trunc(char *str, char x); int main() { char str[N]; char ch; while (printf("输入字符串: "), gets(str)!= NULL) { printf("输入一个字符: "); ch = getchar(); printf("截断处理...\n"); str_trunc(str, ch); // 函数调用 printf("截断处理后的字符串: %s\n\n", str); getchar(); } return 0; } // 函数str_trunc定义 // 功能: 对字符串作截断处理,把指定字符自第一次出现及其后的字符全部删除, 并返回字符串地址 char *str_trunc(char *str, char x) { char *p = str; while (*str!= '\0') { if (*str == x) { *str = '\0'; break; } str++; } return p; }
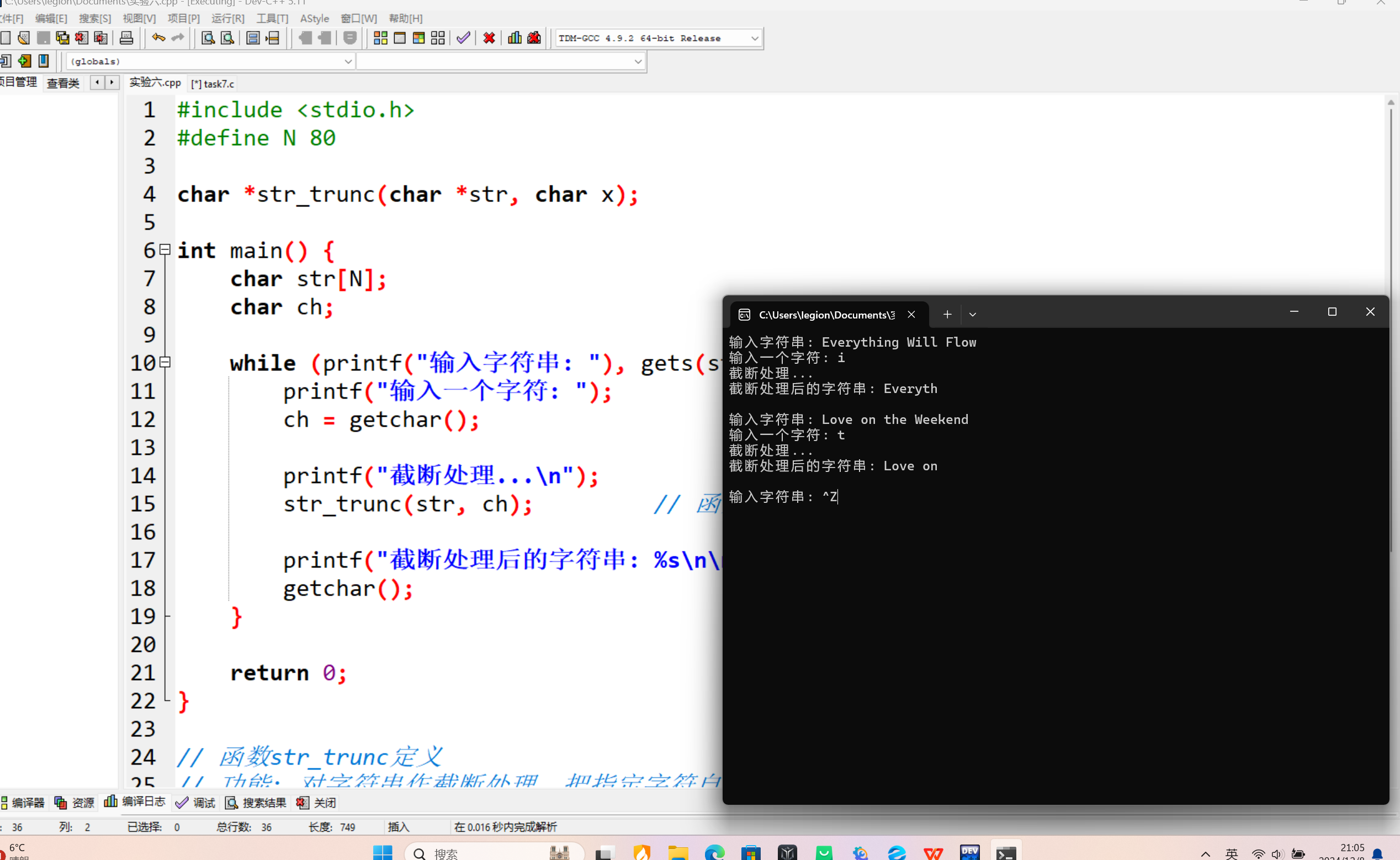
1.如果去掉这行代码,当进行多组输入时,会出现输入流程异常的情况。例如,第一次输入字符串和字符完成操作后,第二次输入字符串时,程序会直接跳过输入字符串的步骤,直接让用户输入用于截断的字符了。
2.line18处的getchar()函数的作用就是用于清除输入缓冲区中残留的回车键字符(\n),使得下一次循环时,gets(str)函数能够正常等待用户输入新的字符串内容,保证整个输入流程按照预期的顺序正常进行,避免因为输入缓冲区残留字符而导致的输入异常情况。
任务六
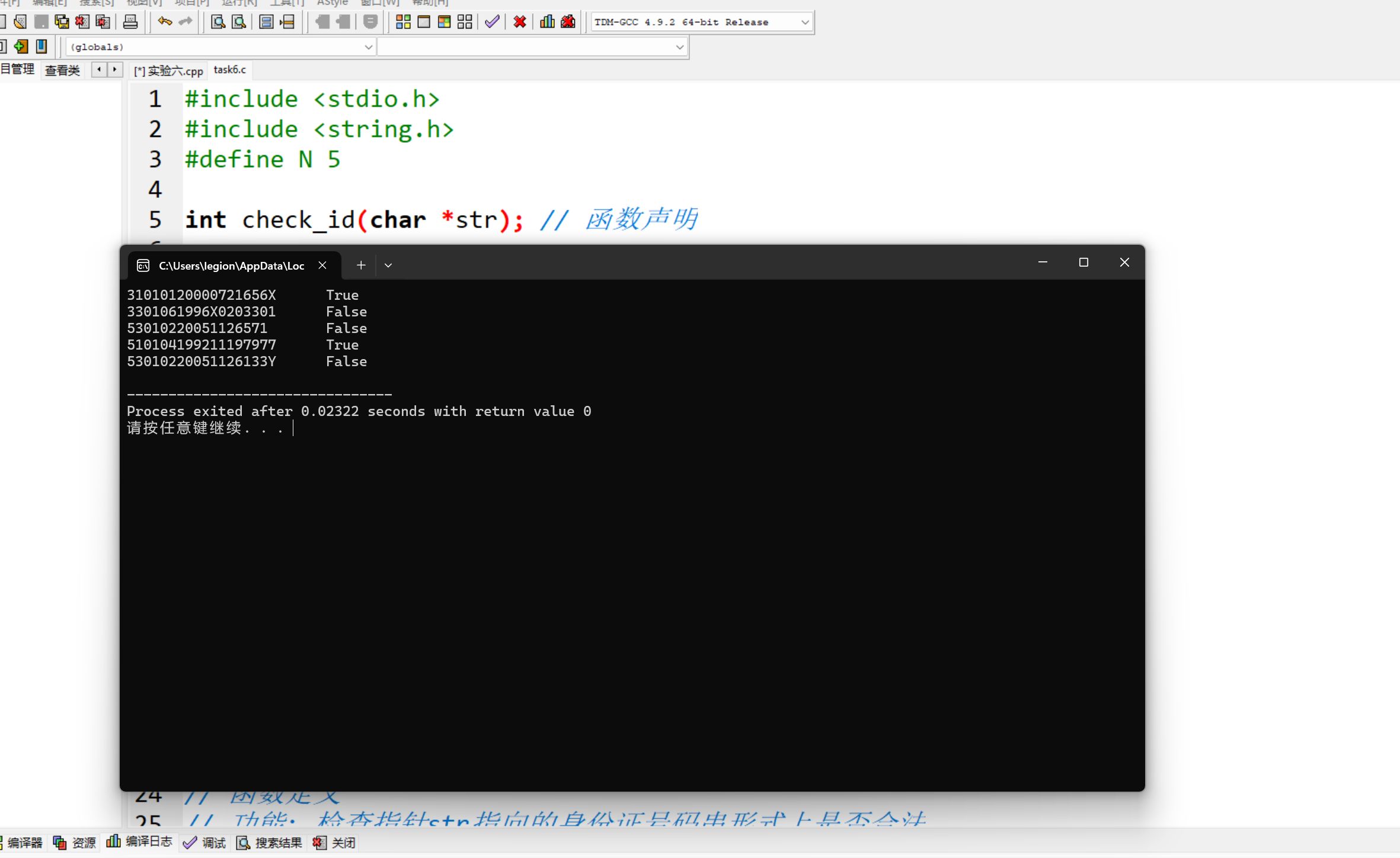
#include <stdio.h> #include <string.h> #define N 5 int check_id(char *str); // 函数声明 int main() { char *pid[N] = {"31010120000721656X", "3301061996X0203301", "53010220051126571", "510104199211197977", "53010220051126133Y"}; int i; for (i = 0; i < N; ++i) if (check_id(pid[i])) // 函数调用 printf("%s\tTrue\n", pid[i]); else printf("%s\tFalse\n", pid[i]); return 0; } // 函数定义 // 功能: 检查指针str指向的身份证号码串形式上是否合法 // 形式合法,返回1, 否则,返回0 int check_id(char *str) { int len = strlen(str); int i; // 首先判断长度是否为18位 if (len!= 18) { return 0; } // 遍历字符串除最后一位外的字符,判断是否都是数字 for (i = 0; i < len - 1; i++) { if (str[i] < '0' || str[i] > '9') { return 0; } } // 判断最后一位是否是数字或者大写X if (str[len - 1] < '0' || (str[len - 1] > '9' && str[len - 1]!= 'X')) { return 0; } return 1; }
任务七
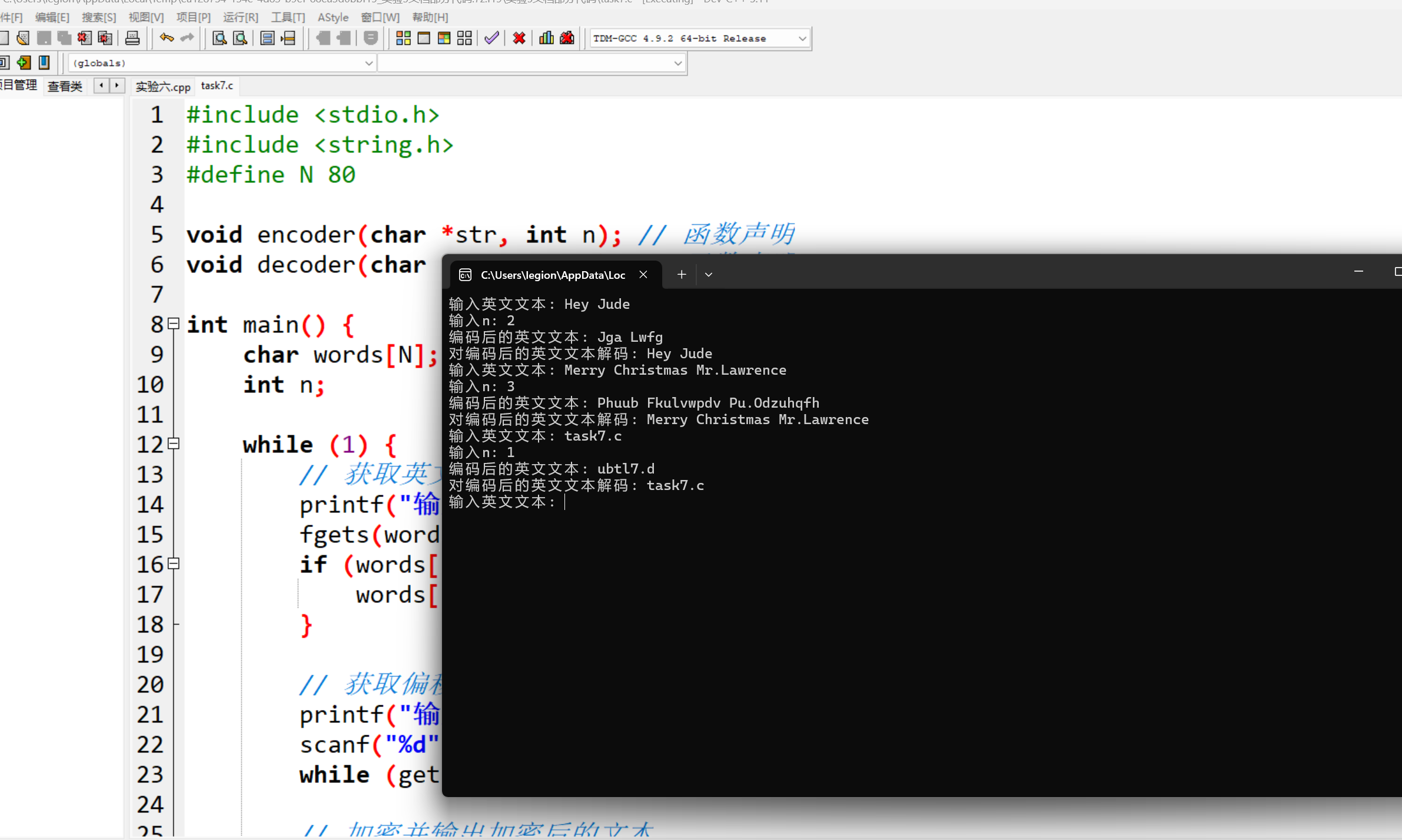
#include <stdio.h> #include <string.h> #define N 80 void encoder(char *str, int n); // 函数声明 void decoder(char *str, int n); // 函数声明 int main() { char words[N]; int n; while (1) { // 获取英文文本输入,使用fgets替代gets避免缓冲区溢出问题,并处理换行符 printf("输入英文文本: "); fgets(words, N, stdin); if (words[strlen(words) - 1] == '\n') { words[strlen(words) - 1] = '\0'; } // 获取偏移量n的输入,并处理scanf输入后缓冲区残留的换行符 printf("输入n: "); scanf("%d", &n); while (getchar()!= '\n'); // 加密并输出加密后的文本 printf("编码后的英文文本: "); encoder(words, n); printf("%s\n", words); // 解密并输出解密后的文本 printf("对编码后的英文文本解码: "); decoder(words, n); printf("%s\n", words); } return 0; } /*函数定义 功能:对s指向的字符串进行编码处理 编码规则: 对于a~z或A~Z之间的字母字符,用其后第n个字符替换; 其它非字母字符,保持不变 */ void encoder(char *str, int n) { while (*str!= '\0') { if ((*str >= 'a' && *str <= 'z') || (*str >= 'A' && *str <= 'Z')) { if ((*str >= 'a' && *str <= 'z')) { *str = ((*str - 'a' + n) % 26 + 'a'); } else { *str = ((*str - 'A' + n) % 26 + 'A'); } } str++; } } /*函数定义 功能:对s指向的字符串进行解码处理 解码规则: 对于a~z或A~Z之间的字母字符,用其前面第n个字符替换; 其它非字母字符,保持不变 */ void decoder(char *str, int n) { while (*str!= '\0') { if ((*str >= 'a' && *str <= 'z') || (*str >= 'A' && *str <= 'Z')) { if ((*str >= 'a' && *str <= 'z')) { *str = ((*str - 'a' - n + 26) % 26 + 'a'); } else { *str = ((*str - 'A' - n + 26) % 26 + 'A'); } } str++; } }
任务八
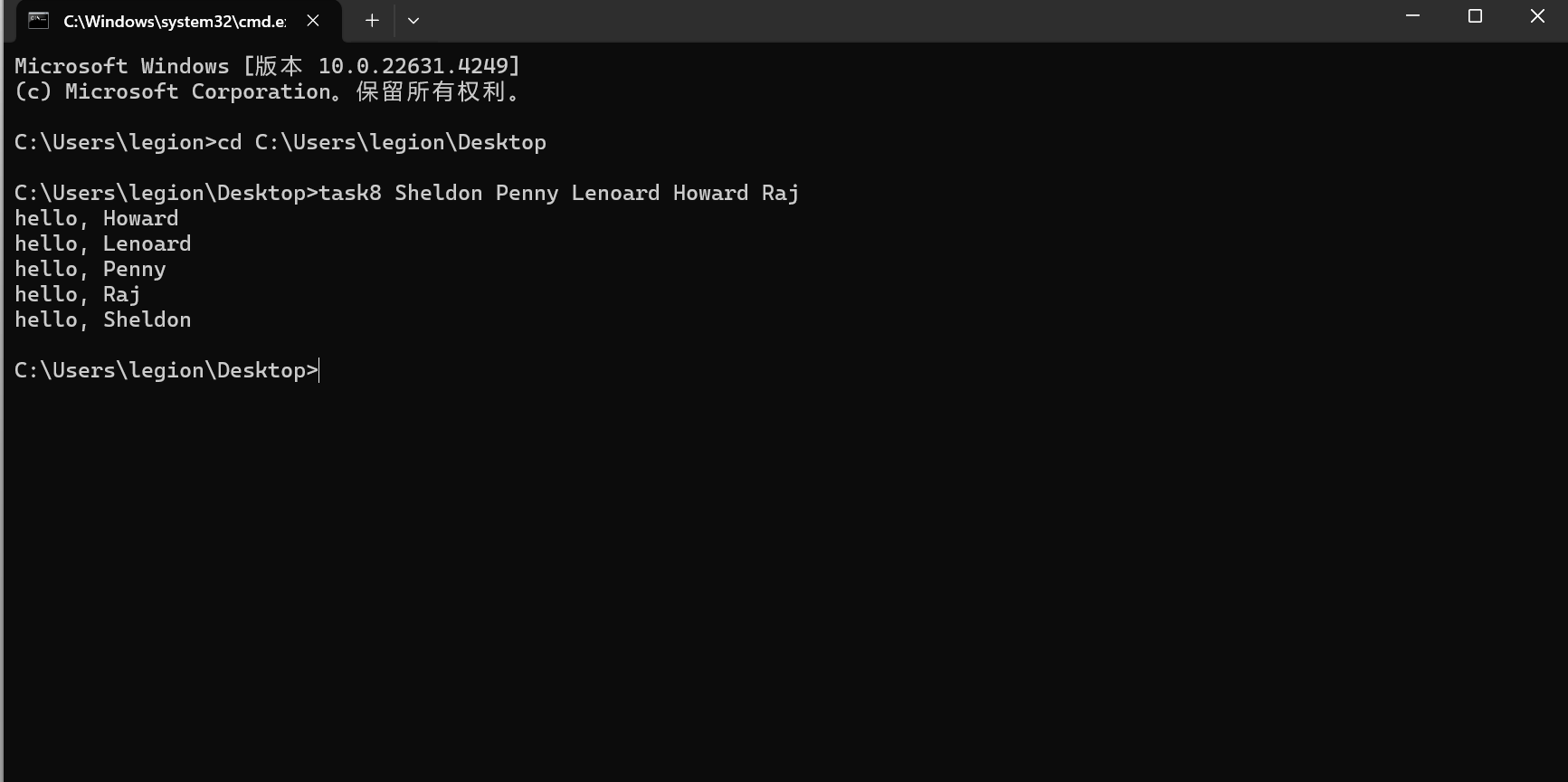
#include <stdio.h> #include <stdlib.h> #include <string.h> // 比较函数,用于qsort,按照字典序比较两个字符串 int compare(const void *a, const void *b) { return strcmp(*(const char **)a, *(const char **)b); } int main(int argc, char *argv[]) { if (argc == 1) { // 如果没有输入姓名参数,给出提示信息 return 1; } // 使用qsort对命令行输入的姓名进行字典序升序排序 qsort((void *)(argv + 1), argc - 1, sizeof(char *), compare); int i; for (i = 1; i < argc; ++i) { printf("hello, %s\n", argv[i]); } return 0; }