
python编码问题实例
ascii : 256
unicode - ucs2 : 2 ** 16 = 65535
unicode - ucs4 : 2 ** 32 = 4294967296
utf-8 : 对unicode进行了压缩,根据不同情况用不同模板,可以根据情况,用1/2/3/4个字节表示
utf-8表示中文时,用3个字节,2 ** 24,相比原生的unicode-ucs4节省了1个字节
1,编码问题,主要是区分面向人类的字符串,面向计算机的字节序列
在python3中,字符串是str(默认即unicode),字节序列是bytes
在python2中,字符串是unicode,字节序列是str
无论python3还是python2,从字符串向字节序列转换称为encode(编码),从字节序列向字符串转换称为decode(解码)
python2中可以通过type(s)确定是str还是unicode
#coding:utf-8
1)s1 = '人生' # s1是str,类型是utf-8
2)s1 = '人生'.encode('gbk') # 报错,原因是python实际执行了s = '中文'.decode('asc-ii').encode('gbk'),而ascii不支持中文
3)s1 = '人生'.decode('utf-8').encode('utf-8') # s1是str,类型是utf-8,转换过程是utf-8、unicode、utf-8
4)s1 = '人生'.decode('utf-8').encode('gbk') # s1是str,类型是gbk,转换过程是utf-8、unicode、gbk
5)s1 = u'人生' # s1是unicode
6)s1 = '人生'.decode('utf-8') # s1是unicode
7)s1 = unicode('人生' , 'utf-8') # s1是unicode,内部先转成str('utf-8'),再转成unicode,后面的'utf-8'改成'gbk'也行,如果不写则是通过defaultencoding转换
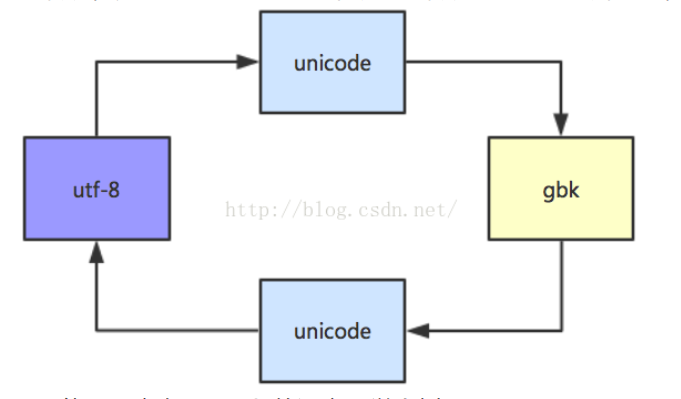
对于s = '你好',如果要显示到windows的gbk环境:
python2中,需要经过utf-8,unicode,gbk的转换,可以是:
#coding:utf-8
print '中文'.decode('utf-8').encode('gbk')
print unicode('中文', 'utf-8').encode('gbk')
print u'中文'.encode('gbk')
python3中,str所代表的都是unicode,可以直接输出到其他环境,支持中文显示:
print('中文')
4,python3编码
假设一段文本是gbk编码的
在windows上,系统默认gbk:
open(path, 'r') 或者 open(path, 'r', encoding='gbk') 可以正常解码
open(path, 'r', encoding='utf-8') 会报错, UnicodeDecodeError: 'utf-8' codec can't decode byte ......
在linux上,系统默认utf-8:
open(path, 'r', encoding='gbk') 可以正常解码
open(path, 'r') 或者 open(path, 'r', encoding='utf-8') 会报错, UnicodeDecodeError: 'utf-8' codec can't decode byte ......
假设bytes字节流压缩成gbk, 在linux上用python接受该字节流时, 必须用gbk解码,但保存至文本时,该文本会变成utf-8(python的默认编码)
sys.getdefaultencoding()拿到的应该是python语言的默认编码, 不是系统的默认编码
总结: 在windows上打开gbk编码文本不需要加encoding参数, 在linux上打开utf-8编码文本不需要加encoding参数
5,\r\n和\n
a = b"\x61\x62\x63\x64"
b = b"abcd" # 内存中存储了abcd是16进制数字,即\x61\x62\x63\x64
for i in b:
print(i) # 97 98 99 100
print(a == b) # True
s = 'abcd' # 内存中并没有存储ascii码,str是一个对象
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
----------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
查看中文"马"字对应的unicode号(在GO中,该号码称为rune码点信息)
name := "马"
fmt.Println([]rune(name)) // 39532,rune即unicode码点信息,"马"在unicode中即39532
39532对应的2进制: 1001 1010 0110 1100 (如果转换到16进制,就是9A6C,占2个字节)
内存并不是直接存储39532,需要根据上述编码表转换到utf-8编码,汉字在utf-8中占3个字节:
fmt.Println(name[0]) // 233
fmt.Println(name[1]) // 169
fmt.Println(name[2]) // 172
即: 233 169 172
转换为2进制: 11101001 10101001 10101100
这个结果就是将39532对应2进制1001 1010 0110 1100,填入到1110xxxx 10xxxxxx 10xxxxxx的结果
GO语言中
2进制 -> 10进制:
fmt.Println(strconv.ParseInt("10101100", 2, 32))
10进制 -> 2进制
fmt.Println(strconv.FormatInt(int64(300), 2))
显示字符 <-> utf-8编码互相转换:
sName := "让世界更美好" // 显示字符
aiNameUtf8 := []byte(sName) // utf8的字节数组
aiNameRune = []rune(sName) // rune的字节数组
fmt.Println(aiNameUtf8) // [232 174 169 228 184 150 231 149 140 230 155 180 231 190 142 229 165 189]
fmt.Println(aiNameRune) // [35753 19990 30028 26356 32654 22909]
fmt.Println(string(aiNameUtf8)) // 让世界更美好
fmt.Println(string(aiNameRune)) // 让世界更美好
备注:
直接存储unicode的话,按照ucs4,要占4个字节,对于英文(1个字节),汉字(2个字节)就太浪费了
汉字虽然在unicode中是2个字节,但是转换utf-8需要加上前缀开销,就变3个字节了
能不能不加开销直接存储unicode?这样英文只要存1个字节,汉字只要存2个字节?不行!因为英文/中文的1/2字节可能会被其他3/4字节的编码包含了,计算器在读取时就会出问题,按照utf-8编码,计算机就可以根据前缀来确认怎么组合后面的编码
python和go语言中,实际存储的编码格式是utf-8,打印显示字符串时,计算机会将内存中的utf-8编码数据根据unicode编码找到对应的字符,然后呈现出来

 浙公网安备 33010602011771号
浙公网安备 33010602011771号