
默认python已经配好,并已经导入idea,只剩下pyspark的安装
1、解压spark-2.1.0-bin-hadoop2.7放入磁盘目录
D:\spark-2.1.0-bin-hadoop2.7
2、将D:\spark-2.1.0-bin-hadoop2.7\python\pyspark拷贝到目录Python的Lib\site-packages
3、在idea中配置spark环境变量
(1)

(2)
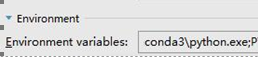
(3)

其中,需要配置的是SPARK_HOME。
如果系统中有多个版本的python,或者系统找不到python的位置,则需要配置PYSPARK_PYTHON ,我这里使用的是conda的python, E:\Program Files\Anaconda3\python.exe
(4) 安装py4j
pip install py4j
4、创建session需要注意的地方
from pyspark.sql import SparkSession # appName中的内容不能有空格,否则报错 spark = SparkSession.builder.master("local[*]").appName("WordCount").getOrCreate() #获取上下文 sc = spark.sparkContext 带有空格报错情况如下:

5、创建上下文,两种方式
#第一种 conf = SparkConf().setAppName('test').setMaster('local') sc = SparkContext(conf=conf) #第二种 sc=SparkContext('local','test')
6、实例(读取文件并打印)
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('test').setMaster('local') sc = SparkContext(conf=conf) rdd = sc.textFile('d:/scala/log.txt') print(rdd.collect())
结果:

注意:还有一种错误如下所示
Java.util.NoSuchElementException: key not found: _PYSPARK_DRIVER_CALLBACK_HOST
这是因为版本的问题,可能pyspark的版本与spark不匹配
例如: spark是2.1.0 所以当使用pip安装pyspark时需要带上版本号: pip install pyspark==2.1.2; 皆为2.1版本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号