

深度学习中的一些基础函数
激活函数概念
神经网络中每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传给下一层。在多层神经网络中,上层节点的输入在加权求和后与下层节点的输入之间具有一个函数关系,这个函数称为激活函数。
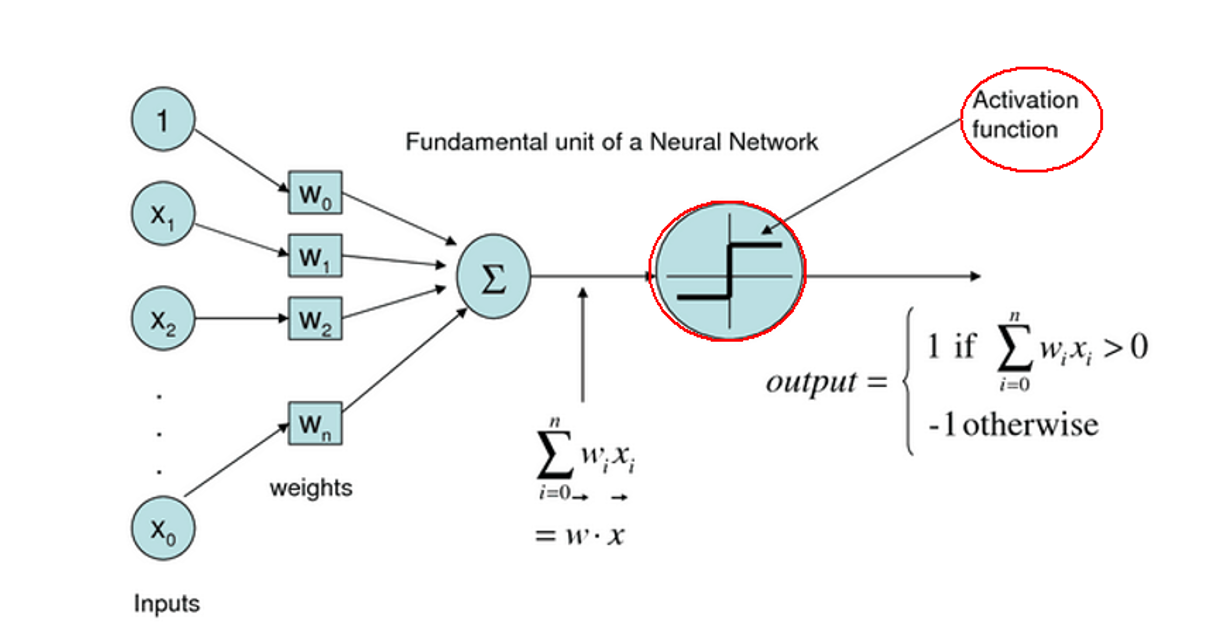
激活函数的作用
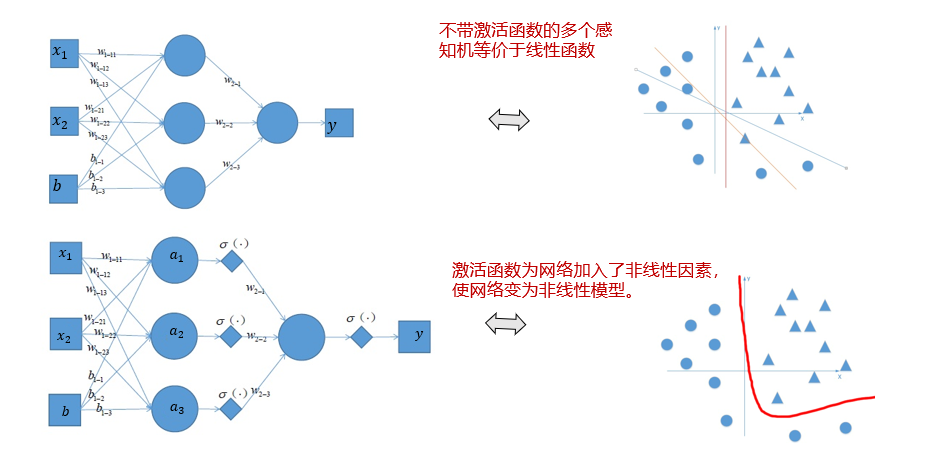
常见激活函数
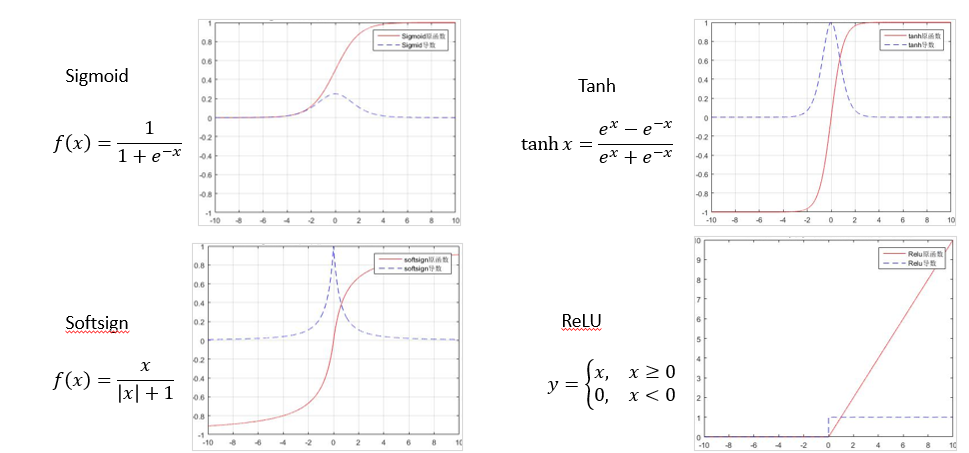
Sigmoid函数单调连续,求导容易,输出有界,网络比较容易收敛。但是我们看到,在远离中心点的位置,Sigmoid函数导数趋于0,在网络非常深的时候,越来越多反向传播的梯度会落入饱和区,从而让梯度的模越来越小。一般来说,Sigmoid网络在5层之内,就会产生梯度退化为0的现象,难以训练。这种现象称为梯度消失现象。另外,Sigmoid的输出并不是以0为中心的。
适合用:Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到 1,因此它对每个神经元的输出进行了归一化;用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适;梯度平滑,避免「跳跃」的输出值;函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率;明确的预测,即非常接近 1 或 0。
缺点:
容易出现梯度消失,2.函数输出并不是0均值化,3. 幂运算相对来讲比较耗时。
tanh函数:tanh也具有和Sigmoid函数类似的缺点,即远离中心的位置导数趋于0,但是因为其关于0点对称,输出的均值比Sigmoid更加接近于0,因此SGD会更接近自然梯度,然而,gradient vanishing的问题和幂运算的问题仍然存在。
Softsign函数是Tanh函数的另一个替代选择。就像Tanh函数一样,Softsign函数是反对称、去中心、可微分,并返回-1和1之间的值。其更平坦的曲线与更慢的下降导数表明它可以更高效地学习,比tTanh函数更好的解决梯度消失的问题。另一方面,Softsign函数的导数的计算比Tanh函数更麻烦。Softsign′(x)=1/(1+∣x∣)2
这个函数相比tanh函数,饱和得慢一些。
Sigmoid, tanh, softsign函数在训练深度神经网络的过程中,都无法回避梯度消失的问题,既在远离函数中心点的位置,函数导数趋于0,在网络非常深的时候,越来越多反向传播的梯度会落入饱和区,从而让梯度的模越来越小,最终趋近于0,导致权重无法更新。
一般来说,如果神经网络超出5层,就会产生梯度退化为0的现象,导致模型难以训练。
RELU线性整流函数,又称修正线性单元ReLU,是一种人工神经网络中常用的激活函数,通常指代以斜坡函数及其变种为代表的非线性函数。当输入为正时,不存在梯度饱和问题。
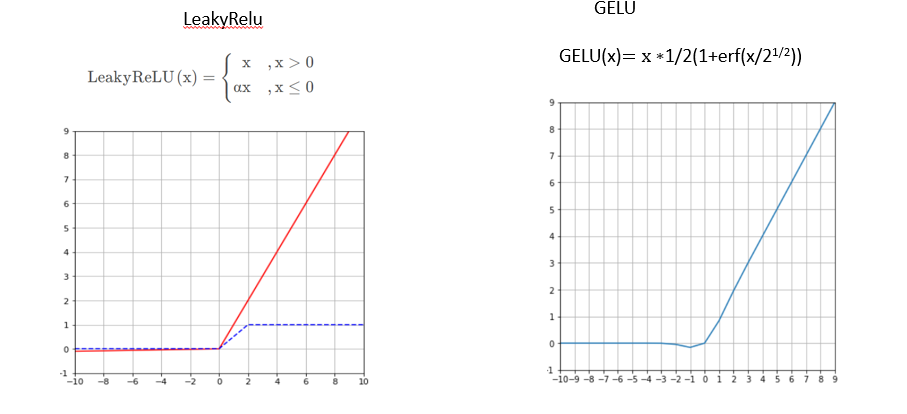
LeakyRelu用于解决Dead ReLU问题的激活函数:针对Relu函数中存在的Dead Relu Problem,Leaky Relu函数在输入为负值时,给予输入值一个很小的斜率,在解决了负输入情况下的0梯度问题的基础上,也很好的缓解了Dead Relu问题
GELU(Gaussian error linear units,高斯误差线性单元)可以看作 dropout的思想和relu的结合,,主要是为激活函数引入了随机性使得模型训练过程更加稳定
损失函数
反映了感知器目标输出和实际输出之间的误差。
极值:让损失函数沿着负梯度的方向进行搜索,不断迭代更新参数w,最终使得函数最小化。
解决思路:


优化器



正则化
正则化是机器学习中非常重要并且非常有效的减少泛化误差的技术,特别是在深度学习模型中,由于其模型参数非常多容易产生过拟合。防止过拟合,比较常用的技术包括:

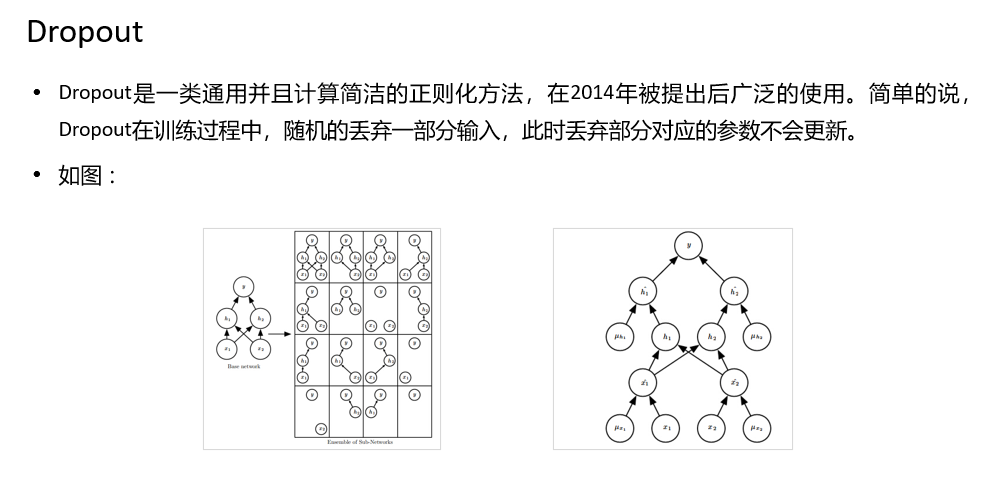
在每一轮的样本输入到神经网络进行训练时,设定一个概率p,使得每个神经元有一定的概率死亡,不参与网络的训练。
其流程为:1.首先以一定的概率p随机删除掉网络隐藏层中的神经元(暂时死亡),输入输出神经元保持不变。2.然后把输入x通过修改后的网络前向传播,把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。3.然后继续重复这一过程:恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
原始输入每一个节点选择概率0.8,隐藏层选择概率为0.5。
Dropout的优点:
相比于weight decay、范数约束等,该策略更有效。
计算复杂度低,实现简单而且可以用于其他非深度学习模型。
但是当训练数据较少时,效果不好。
Dropout训练过程中的随机过程不是充分也不是必要条件,可以构造不变的屏蔽参数,也能够得到足够好的解。

加速训练收敛:Batch Normalization通过规范化每一层的输入,使得激活函数的输入值落在对输入比较敏感的区域,这有助于增大梯度,进而加快模型的训练收敛速度。
提高模型性能:由于Batch Normalization有助于优化网络的权重分布,使得模型更易于训练,因此往往能够提升模型的性能。此外,通过规范化输入数据,模型对于输入的变化变得更加鲁棒,从而提高模型的泛化能力。
减少对初始权重和学习率的依赖:Batch Normalization使得模型对于初始权重的选择不再那么敏感,因此可以简化模型初始化过程。同时,由于Batch Normalization有助于稳定训练过程,因此可以使用较大的学习率进行训练,从而进一步加速训练过程。
减少过拟合:Batch Normalization通过破坏原来的数据分布,有助于缓解过拟合问题。它通过增加模型的泛化能力,使得模型能够更好地适应不同的数据集和任务。
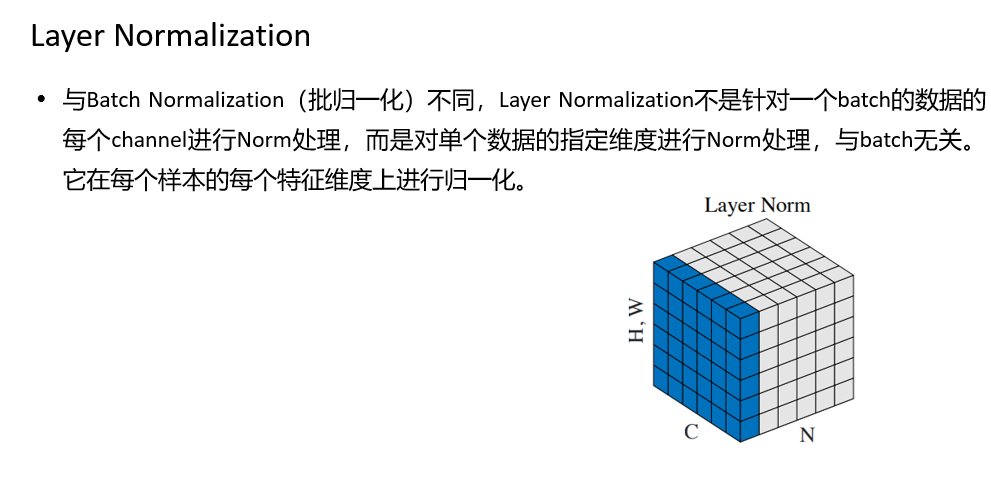
BN的第一个缺陷是依赖Batch size,第二个缺陷是对于RNN这样的动态网络效果不明显,且当推理序列长度超过训练的所有序列长度时,容易出问题。为此,提出了Layer Normalization。
向前传播
输入信号从输入层传输到输出层
对于每个神经元:
计算上层的输出值
计算激活函数值
最后输出:模型预测值
反向传播法
步骤:
将损失函数反向传播给每个计算单元。
每个计算单元根据获得的误差更新权重。
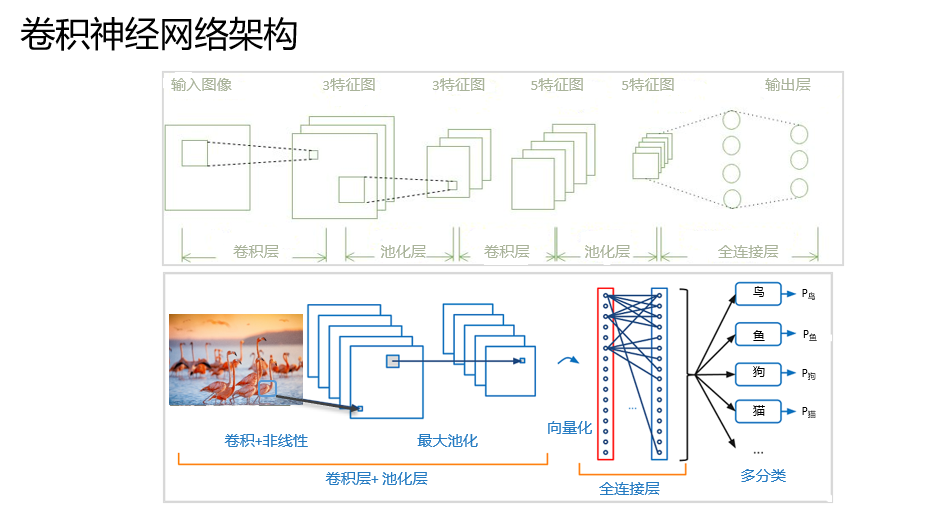
卷积神经网络
可以响应一部分覆盖范围内的单元,对于图像处理有出色表现。它包括卷积层,池化层,全连接层。
卷积;对图像(不同的数据窗口数据)和滤波矩阵(一维固定权重:因为每个神经元的权重固定,所以又可以看做一个恒定的滤波器filter(kernel))做内积(逐个元素相乘再求和)的操作就是卷积操作,也是卷积神经网络的名字来源。
核心思想:
局部感知
参数共享
循环神经网络
通过隐藏节点周期连接,来捕捉序列化数据中动态信息的神经网络,可以对序列化的数据进行分类。
RNN可以保存上下文状态,甚至不限于传统神经网络在空间上的边界,可以在时间序列上有延拓,直观上说就是本时间的隐藏层和下一时刻的隐藏层之间的节点有边。
深度学习的两个难题
梯度消失:当网络层数越多时,进行反向传播求导值越小,导致梯度消失。
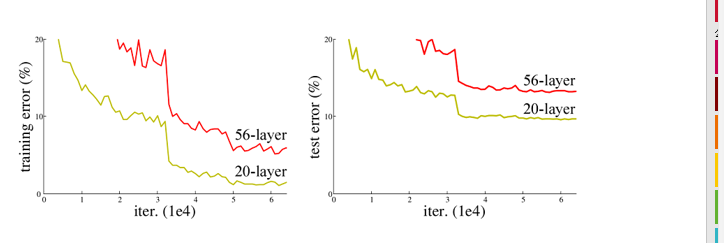
网络退化,网络深度增加,网络准确度应该同步增加。
当网络更深时,网络的参数空间更大,优化问题变得更难,因此简单地去增加网络的深度反而会导致更高的训练误差。
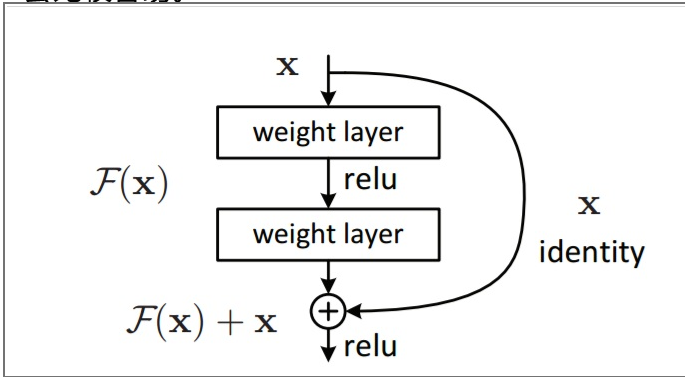
残差结构
提出一个可以防止训练的梯度消失的结构,称为残差结构。
残差模块在输入和输出之间建立了一个直接连接,这样新增的网络层仅仅需要在原来的输出层基础上学习新的特征,即学习残差,会比较容易
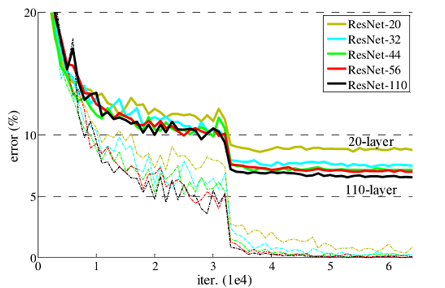
ResNet
在ResNet网络提出之前,传统的卷积神经网络都将一系列的卷积层和池化层堆叠得到的,但当网络到一定深度时,就会出现退化问题。
层数越多准确率越高
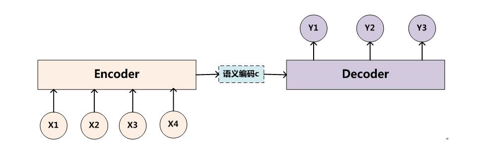
Seq2Seq
序列到序列模型,由编码器和解码器两部分组成。输入和输出都可以是一个不定长的序列。
编码器和解码器的作用:
编码器将长度可变的输入转换成长度固定的上下文向量,并且将输入序列的信息在该上下文向量中进行编码。
解码器进行相反的过程,将上下文向量进行解码,转换成长度可变的输出序列
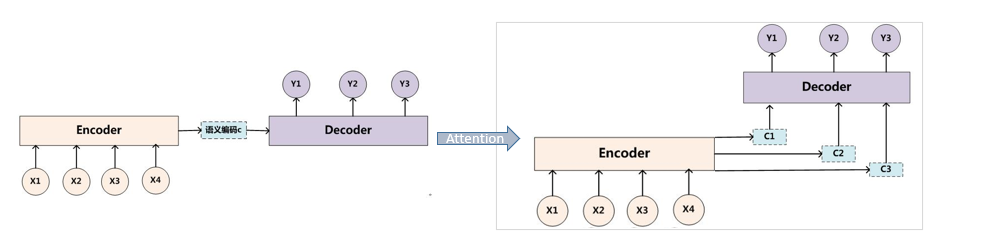
Attention机制
注意力机制:在解码器的每个步骤中,使用与编码器的直接连接来聚焦于源序列的特定部分。
注意力机制在输入信息中聚焦于更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,可以解决信息过载问题,并提高任务处理的效率和准确性。
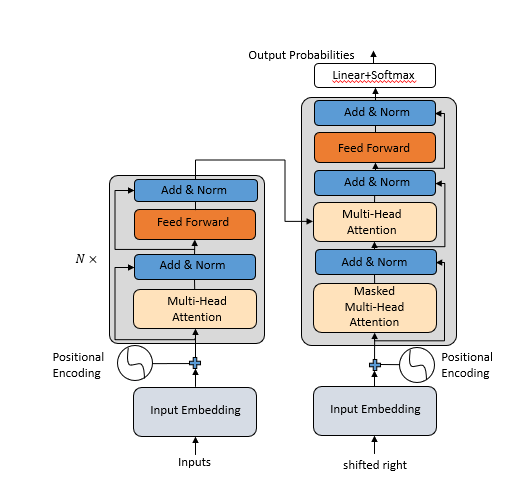
TransFormer
TransFormer是谷歌在2017做机器翻译任务的《attention is all you need》的论文中提出的,目前大多数大模型以Transformer为基础。
Transformer由Encode和Decode两部分组成。
输入层:
位置编码
embedding层
Encoder block,Decoder block
self-Attention
前馈网络层
残差结构
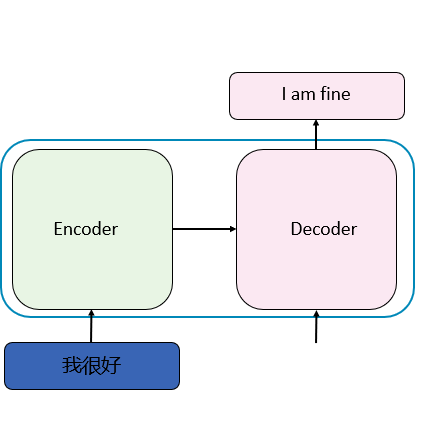
计算流程-获取输入
首先将每个输入单词通过Embedding转换为词向量,然后与每一个单词的位置Embedding相加得到每一个单词的表示向量x,最终,每个单词都被嵌入为一个512维的向量。
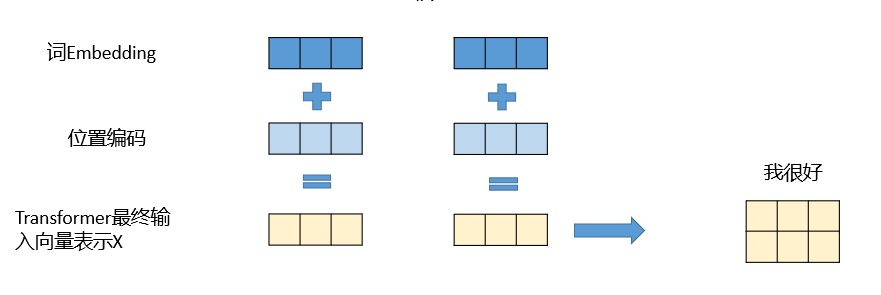
工作流程-Encoder
将得到的单词表示向量矩阵传入到Encoder中,经过6个Encoder block后可以得到句子所有的单词的编码信息矩阵库c,每一个Encoder block输出的矩阵维度与输入完全一致。
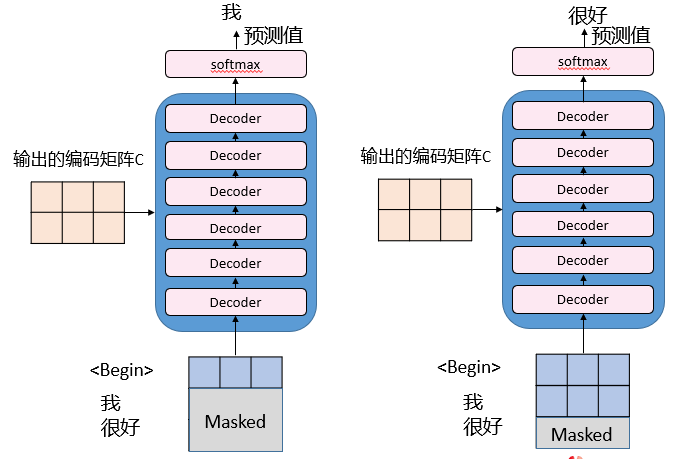
工作流程Decoder
将Encoder输出的编码信息矩阵C传递到Decoder中,Decoder依次会根据当前翻译过的单词来翻译下一个单词


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现
2023-07-30 天道7.30观后感