
pyTorch模型调优NPU
性能分析工具pyTorch Profiling

CANN Profiling
看task duration

调优手段1:使用亲和的数据类型
用AMP训练

AICore不支持torch.long.Tensor类型,会自动切换AICPU,影响训练。
调优手段2:优化调度耗时(融合tensor)

融合算子

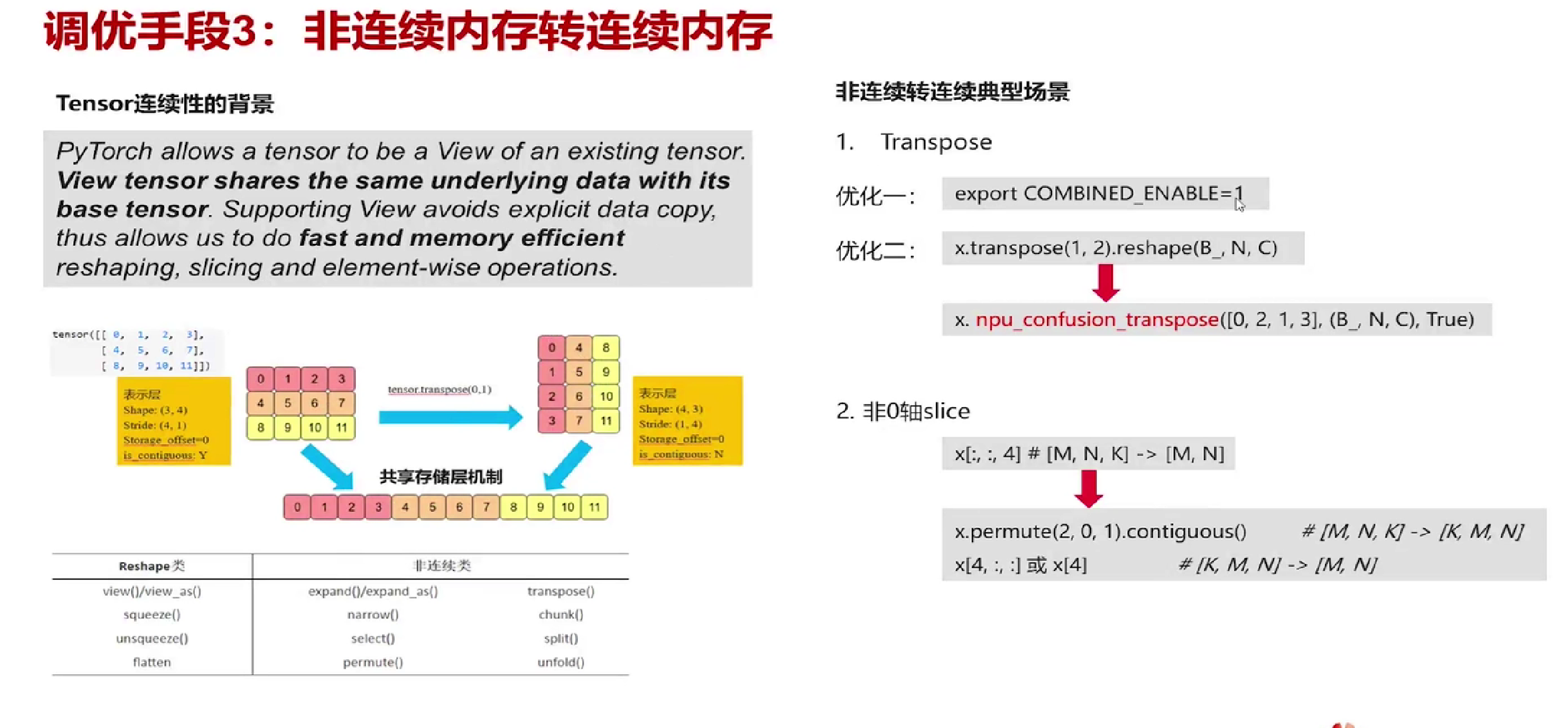
昇腾要求输入tensor连续,所以进行非连续内存转连续内存
使用自动调优工具AOE

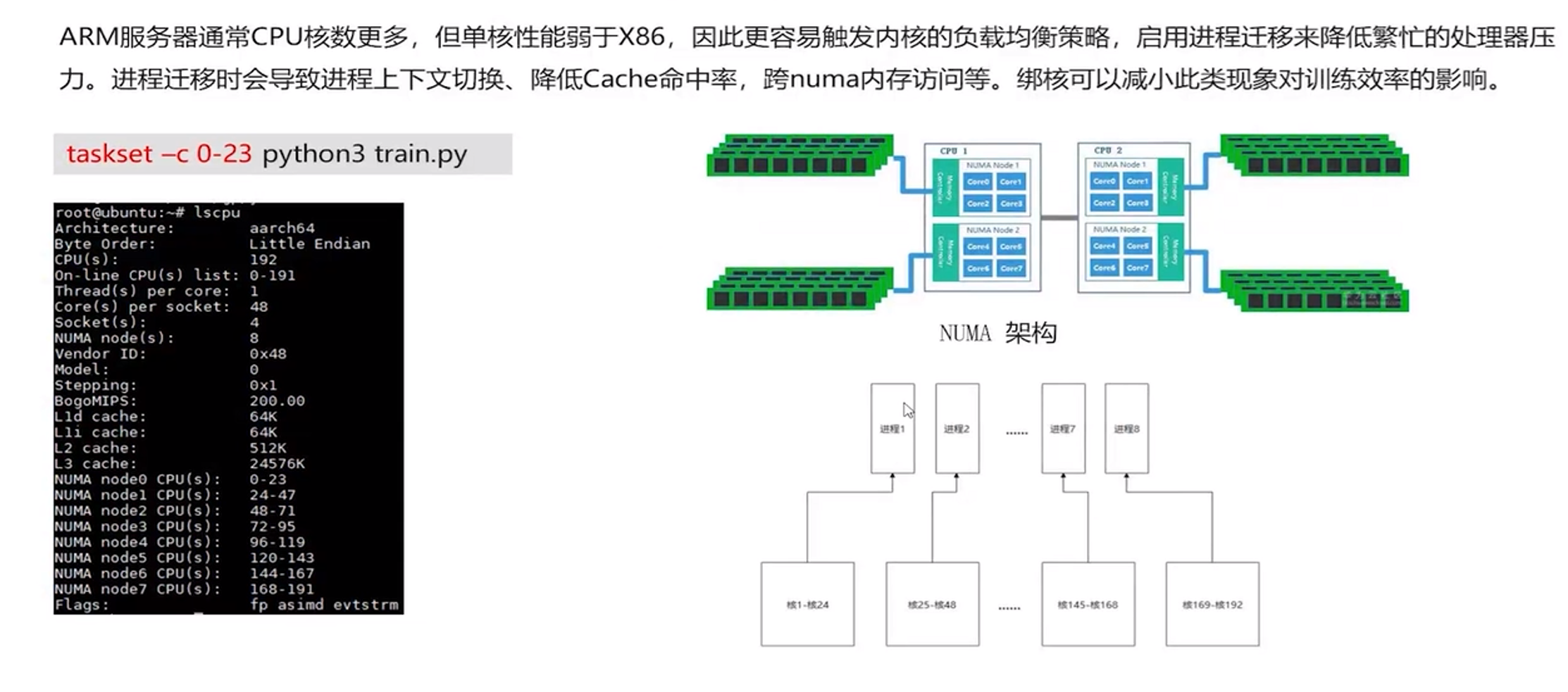
绑核,提升cpu性能(对于ARM服务器提升较大,对于x86一般)
具体算子调优
roll算子运行时间过长
了解其功能用相同语义替换。
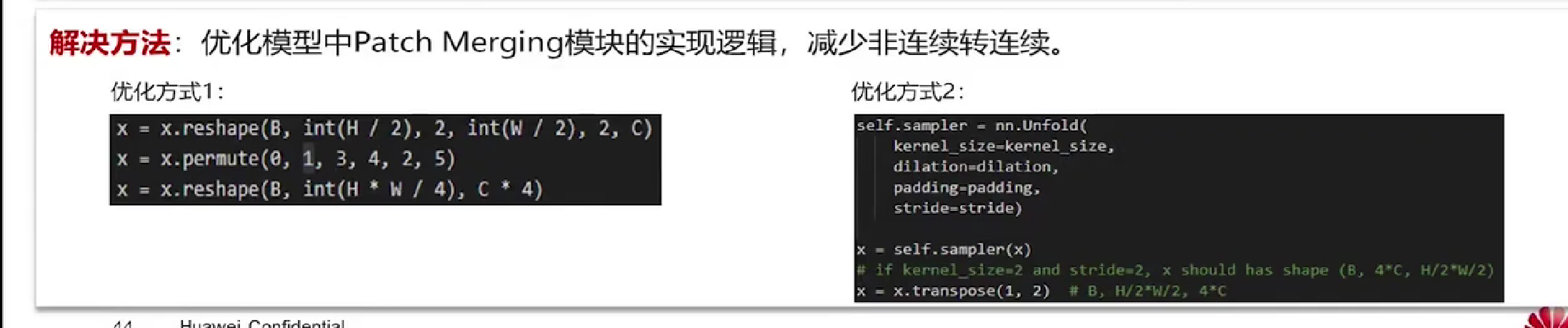
具体模块优化
PATCH
NPU可以理解为c++全部一起编译
GPU来一行编译一行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号