

作业一
要求
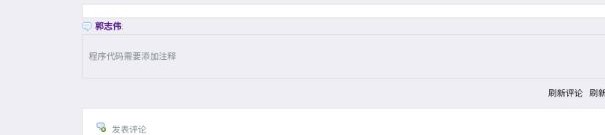
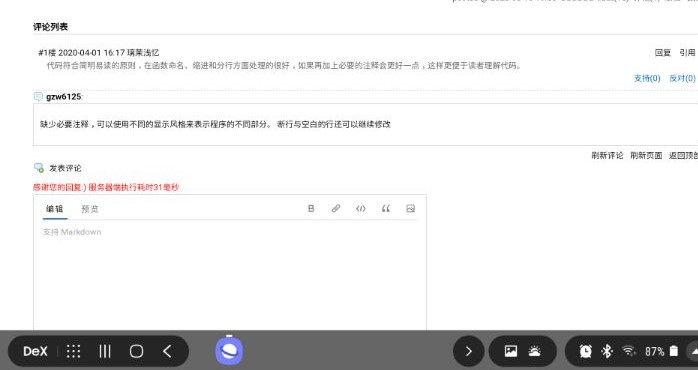
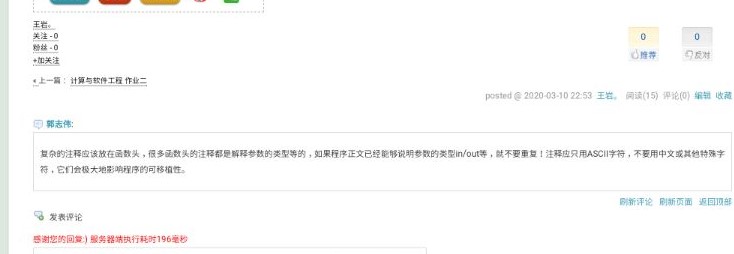
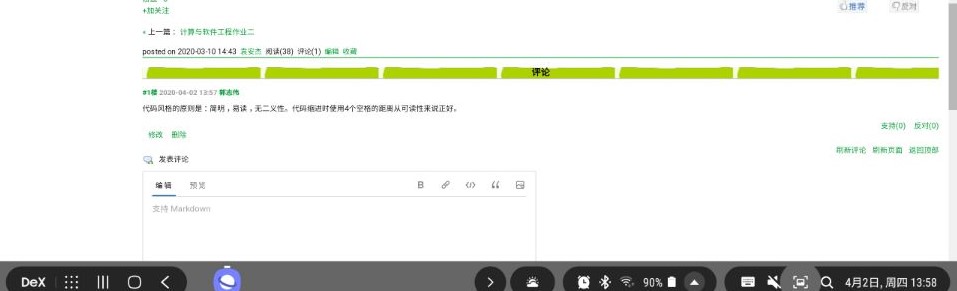
每个人针对之前两次作业所写的代码,针对要求,并按照代码规范(风格规范、设计规范)要求评判其他学生的程序,同时进行代码复审(按照代码复审表 https://www.cnblogs.com/xinz/archive/2011/11/20/2255971.html ),要求评价数目不少于8人次,评价内容直接放在你被评价的作业后面评论中同时另建立一个博客,将你作的评论的截图或者链接,放在博客中,并在你的博客中谈谈自己的总体看法
代码复审
总体看法
为什么我们需要代码规范?代码规范就是规定代码中某些格式必须遵守一定条件,比如缩进、注释等。当制定了合理的规范后,不仅代码本身会显得美观,而且每个人都很容易读懂,代码的可维护性也大大增强。即使是完美,代码复审还有“教育”和“传播知识”的作用。更重要的是,不管多么厉害的开发者都会或多或少地犯一些错误,有欠考虑的地方,如果有问题的代码已签入到产品代码中,再要把所有的问题找出来就更困难了。大家学习软件工程都知道越是项目后期发现的问题,修复的代价越大。代码复审正是要在早期发现,并修复这些问题。最后,我们做代码复审的目的是为了减少错误的发生,避免不必要的繁文缛节,而不是找一个人来对着你的代码点头。一些简单的修改不是非得要一个复审者来走一遍形式。所以,我们需要代码规范和代码复审。
作业二
要求
两人自由组队进行结对编程
- 参考结对编程的方法、过程(https://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html)开展两人合作完成本项目
1.实现一个简单而完整的软件工具(中文文本文件人物统计程序):针对小说《红楼梦》要求能分析得出各个人物在每一个章回中各自出现的次数,将这些统计结果能写入到一个csv格式的文件。
2. 进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
3 . 进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
4 .使用源代码管理系统 (GitHub, Gitee, Coding.net, 等);
5 . 针对上述形成的软件程序,对于新的文本小说《水浒传》分析各个章节人物出现次数,来考察代码。 - 将上述程序开发结对编程过程记录到新的博客中,尤其是需要通过各种形式展现结对编程过程,并将程序获得的《红楼梦》与《水浒传》各个章节人物出现次数与全本人物出现总次数,通过柱状图、饼图、表格等形式展现。
- 《红楼梦》与《水浒传》的文本小说将会发到群里。
结对编程同伴链接:https://www.cnblogs.com/17074211zh/p/12636264.html
注意,要求能够分章节自动获得人物出现次数
程序代码
import jieba
txt = open(‘redstone.txt’, ‘r’, encoding = ‘utf-8’).read() #读取txt文件
words = jieba.lcut(txt) #使用jieba库进行精确模式分词,返回一个列表类型的分析结果
counts = {} #创建字典数据类型
for word in words: #统计词出现的次数
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0)+1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(15): #输出出现次数较多的前15个人物
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))

import jieba
txt = open(‘redstone.txt’, ‘r’, encoding = ‘utf-8’).read()
excludes = {‘什么’, ‘一个’, ‘我们’, ‘你们’, ‘如今’, ‘说道’, ‘知道’, ‘起来’, ‘这里’,‘姑娘’,‘出来’,‘众人’,‘那里’,‘自己’}
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == ‘贾母’ or word == ‘老太太’:
rword = ‘贾母’
else:
rword = word
counts[word] = counts.get(word,0)+1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))

总结
因为之前没有学过python,作业完成起来有些困难,在上网浏览借鉴相关资料后,才完成部分要求,其他详细还需打磨。

