面试题
HTML
1.常见的行内,块级元素
块级元素:
特点:可设置宽高边距,占满整行,会自动换行
示例:div、 p、 h1 、h6、ol、ul、dl、table、address、blockquote、form
行内元素:
特点:无法设置宽高 以设置左右方向的内边距和外边距,会影响其他元素和文本的位置,不会占满整行,不会自动换行,行内元素设置垂直方向的 padding 或 padding-bottom 时,它会影响元素的实际高度,因为内边距会被添加到元素的内容框和行框之间,从而改变元素的尺寸。
示例:a、strong、b、em、i、del、s、ins、u、span
行内块元素:
特点:可设置宽高,占满整行,但不会自动换行
示例:img、input
2.简述一下 src 与 href 的区
src 用于替换当前元素,href 用于在当前文档和引用资源之间确立联系。
src 是 source 的缩写,指向外部资源的位置,指向的内容将会嵌入到文档中当前标签所在 位置;在请求 src 资源时会将其指向的资源下载并应用到文档内,例如 js 脚本,img 图片 和 frame 等元素。
<script src =”js.js”></script>
当浏览器解析到该元素时,会暂停其他资源的下载和处理,直到将该资源加载、编译、执行 完毕,图片和框架等元素也如此,类似于将所指向资源嵌入当前标签内。这也是为什么将 js 脚本放在底部而不是头部。 href 是 Hypertext Reference 的缩写,指向网络资源所在位置,建立和当前元素(锚点) 或当前文档(链接)之间的链接,如果我们在文档中添加
<link href=”common.css” rel=”stylesheet”/>
那么浏览器会识别该文档为 css 文件,就会并行下载资源并且不会停止对当前文档的处理。 这也是为什么建议使用 link 方式来加载 css,而不是使用@import 方式。
3.描述 cookies, sessionStorage 和 localStorage 的区别?
cookie 是⽹站为了标示用户身份而储存在用户本地终端 ( Client Side)上的数据 ( 通常 经过加密)
cookie数据始终在同源的http请求中携带 ( 即使不需要), 记会在浏览器和服务器间来回 传递
sessionStorage 和 localStorage 不会自动把数据发给服务器,仅在本地保存
存储⼤小: cookie 数据⼤小不能超过4k sessionStorage 和 localStorage 虽然也有存储⼤小的限制,但比 cookie ⼤得 多, 可以达*到5M或更⼤
有期时间: localStorage 存储持久数据, 浏览器关闭后数据不丢失除⾮主动删除数据 sessionStorage 数据在当前浏览器窗⼝关闭后自动删除 cookie 设置的 cookie 过期时间之前⼀直有效, 即使窗⼝或浏览器关
4.a标签中 active hover link visited 正确的设置顺序是什么?
a:link
a:visited
a:hover
a:active
5.html5有哪些新特性?
HTML5 现在已经不是 SGML 的子集,主要是关于图像,位置,存储,多任务等功能的增加。
(1)绘画 canvas;
(2)用于媒介回放的 video 和 audio 元素;
(3)本地离线存储 localStorage 长期存储数据,浏览器关闭后数据不丢失;
(4)sessionStorage 的数据在浏览器关闭后自动删除;
(5)语意化更好的内容元素,比如 article、footer、header、nav、section;
(6)表单控件,calendar、date、time、email、url、search;
(7)新的技术webworker, websocket, Geolocation;
6.前端页面渲染过程
下面我们来逐一介绍:
1、构建DOM树与CSSOM树
这两者是比较相似的,所以我们放在一起来说。html与css都是拥有层级关系的结构,所以我们将其解析为树结构。
(1)拿到html文件后,首先会将字节转换为字符,确认tokens标签,然后转换为节点,通过节点构建DOM树。
(2)同样的,对应的css也会将字节转换为字符,确认tokens标签,然后转换为节点,通过节点构建CSSOM树。在解析html的过程中,遇到head标签中引用的css,会暂停DOM树的构建,先将css解析并构建CSSOM,然后再继续解析html。这是因为如果后面的html用到了css样式,而样式没有提前解析,就会出现无样式状态。
(3)加载js,在页面渲染期间,如果遇到javascript,浏览器的渲染引擎会暂停工作,先交给javascript引擎来执行需要的js代码。因为如果后面的DOM中涉及到js修改的节点,会造成两次渲染,所以要进行js阻塞。
2、构建渲染树
在DOM树和CSSOM树构建的过程中,渲染树会同时进行构建,它将DOM与CSS进行合并,形成渲染树。
3、重绘与重排
完成渲染树的构建之后,页面会进行初始化渲染,也就是重排(回流),这时一个完整的页面就渲染完成了
7.回流和重绘
回流(reflow):当render tree中的元素的宽高、布局、显示、隐藏或元素内部文字结结构发生改变时,会影响自身及其父元素、甚至追溯到更多的祖先元素发生改变,则会导致元素内部、周围甚至整个页面的重新渲染,页面发生重构,回流就产生了。
重绘(repaint):元素的结构(宽高、布局、显示隐藏、内部文字大小)未发生改变,只是元素的外观样式发生改变,比如背景颜色、内部文字颜色、边框颜色等。此时会引起浏览器重绘,显然重绘的速度快于回流。
回流一定会触发重绘,重绘不一定触发回流。
回流重绘对性能的影响
这里了解一个知识点:渲染css样式会影响js执行的时间,使得加载js脚本变慢。原因如下:
浏览器渲染一个网页的时候会启用两条线程:一条渲染javascript 脚本,另一条渲染 ui 即css 样式的渲染。但这两条线程是互斥的,当javascript 线程运行的时候 ui 线程则会中止暂停,反之亦然。因为当ui 线程运行对页面进行渲染的时候, js 脚本难免会涉及到页面视图上的一些样式的改变,为了使这个改变更加准确 js 脚本只好等待ui 线程渲染完成的时候才去执行。
所以当一个页面的元素样式改动频繁的时候ui 线程就会持续渲染,造成js 代码反应慢半拍,卡顿的情况。回流和重绘都会使得ui线程渲染时间加长,太多就会使得网站性能变差,因此要尽量减少reflow和repaint。
如何减少回流和重绘
导致回流发生的情况如下:
- 改变窗口大小
- 改变文字大小
- 内容的改变,如用户在输入框中敲字
- 激活伪类,如:hover
- 操作class属性
- 脚本操作DOM
- 计算offsetWidth和offsetHeight
- 设置style属性
对应的css属性如下:
- 盒子模型相关属性
- 定位及浮动属性
- 节点内部的文字结构

导致重绘的css属性如下:

减少回流和重绘注意点如下:
css
避免设置多层内联样式。
如果需要设置动画效果,最好将元素脱离正常的文档流。
避免使用CSS表达式(例如:calc())。
123
JavaScript
1.避免频繁操作样式,最好将样式列表定义为class并一次性更改class属性。
2.避免频繁操作DOM,创建一个documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中。
3.可以先为元素设置为不可见:display: none,操作结束后再把它显示出来。
8.iframe的有缺带点
iframe的优点:
1、iframe能够原封不动的把嵌入的网页展现出来;
2、如果有多个网页引用iframe,那么只需要修改iframe的内容,就可以实现调用每一个页面的更改,方便快捷;
3、网页如果为了统一风格,头部和版本都是一样的,就可以写成一个页面,用iframe嵌套,可以增加代码的可重用;
4、如果遇到加载缓慢的第三方内容,如图标或广告,这些问题可以由iframe来解决;
5、iframe会堵塞主页面的Onload事件;
6、iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载。
iframe的缺点:
1、iframe会阻塞主页面的Onload事件;
2、iframe和主页面共享链接池,而浏览器对相同城的链接有限制,所以会影响页面的并行加载;
3、使用iframe之前需要考虑这两个缺点,如果需要使用iframe,最好是通过JavaScript;
4、动态给iframe添加src属性值,这样可以可以绕开以上两个问题
5、不利于seo
6、代码复杂,无法一下被搜索引擎索引到
7、iframe框架页面会增加服务器的http请求,对于大型网站不可取。
8、很多的移动设备无法完全显示框架,设备兼容性差。
CSS
1.display 的 block、inline 和 inline-block 的区别
(1)block:会独占一行,多个元素会另起一行,可以设置 width、 height、margin 和 padding 属性;
(2)inline:元素不会独占一行,设置 width、height 属性无效。 但可以设置水平方向的 margin 和 padding 属性,不能设置垂直方向 的 padding 和 margin;
(3)inline-block:将对象设置为 inline 对象,但对象的内容作为 block 对象呈现,之后的内联对象会被排列在同一行内。
2.display: none; 与 visibility: hidden; 的区别
- display:none ;会让元素完全从渲染树中消失, 渲染的时候
不占据任何空间; - visibility: hidden ;不会让元素从渲染树消失, 渲染师元素继续占据空间, 只是内 容不可⻅
- display: none ;是
⾮继承属性, ⼦孙节点消失由于元素从渲染树消失造成, 通过修改 ⼦孙节点属性⽆法显示 ; - visibility: hidden; 是
继承属性, ⼦孙节点消失由于继承 了 hidden , 通过设置 visibility: visible; 可以让⼦孙节点显式
修改常规流中元素的 display 通常会造成⽂档重排 。修改 visibility 属性只会造成 本元素的重绘。 读屏器不会读取 display: none ;元素内容;会读取 visibility: hidden; 元素内容
opacity 属性表示元素的透明度,将元素的透明度设置为0后,在我们⽤户眼中,元素也是隐藏的 不会引发重排,⼀般情况下也会引发重绘
.transparent {
opacity:0;
}
由于其仍然是存在于⻚⾯上的,所以他⾃身的的事件仍然是可以触发的,但被他遮挡的元素是不能触发 其事件的 需要注意的是:其⼦元素不能设置opacity来达到显示的效果 特点:改变元素透明度,元素不可⻅,占据⻚⾯空间,可以响应点击事件
clip-path
.hide {
clip-path: polygon(0px 0px,0px 0px,0px 0px,0px 0px);
}
特点:元素不可⻅,占据⻚⾯空间,⽆法响应点击事件
3. 对 BFC 的理解,如何创建 BFC
块格式化上下文(Block Formatting Context,BFC)是 Web 页面的 可视化 CSS 渲染的一部分,是布局过程中生成块级盒子的区域,也是 浮动元素与其他元素的交互限定区域。 通俗来讲:BFC 是一个独立的布局环境,可以理解为一个容器,在这 个容器中按照一定规则进行物品摆放,并且不会影响其它环境中的物 品。如果一个元素符合触发 BFC 的条件,则 BFC 中的元素布局不受外 部影响。
- 创建 BFC 的条件
- 根元素:body;
- 元素设置浮动:float 除 none 以外的值;
- 元素设置绝对定位:position (absolute、fixed);
- display 值为:inline-block、table-cell、table-caption、flex 等;
- overflow 值为:hidden、auto、scroll;
BFC 的特点:
- 垂直方向上,自上而下排列,和文档流的排列方式一致。
- 在 BFC 中上下相邻的两个容器的
margin 会重叠 - 计算 BFC 的高度时,需要计算浮动元素的高度 BFC 区域不会与浮动的容器发生重叠
- BFC 是独立的容器,容器内部元素不会影响外部元素
- 每个元素的左 margin 值和容器的左 border 相接触
BFC 的作用:
解决 margin 的重叠问题:由于 BFC 是一个独立的区域,内部的元素 和外部的元素互不影响,将两个元素变为两个 BFC,就解决了 margin 重叠的问题。
解决高度塌陷的问题:在对子元素设置浮动后,父元素会发生高度塌 陷,也就是父元素的高度变为 0。解决这个问题,只需要把父元素变 成一个 BFC。常用的办法是给父元素设置 overflow:hidden
外边距折叠是 CSS 中的一个特性,它可以导致垂直相邻的外边距合并成一个外边距,从而影响元素之间的间距。以下是外边距折叠的一般规则:
-
兄弟元素折叠: 当两个垂直相邻的兄弟元素都具有外边距时,它们的外边距可能会折叠成一个外边距。折叠的大小取两者中的较大者,而不是简单地将它们相加。
-
父子元素折叠: 父元素的外边距与第一个/最后一个子元素的外边距可能会折叠。这种情况只在
没有边框、内边距、块格式化上下文、清除浮动等分隔的情况下才会发生。 -
空块元素折叠: 一个没有内容,只有外边距的空块级元素的外边距可能会折叠。
问题:相邻两个盒子垂直方向上的margin会发生重叠,只会取比较大的margin
解决:(1)设置padding代替margin
(2)设置float
(3)设置overflow
(4)设置position:absolute 绝对定位
(5)设置display: inline-block
4.css3中有哪些新特性
-
选择器和伪类:
- 各种新的选择器,如属性选择器、子选择器、相邻兄弟选择器等。
- 伪类和伪元素的扩展,如
:nth-child()、:nth-of-type()、:not()、:before、:after等。
-
盒模型和布局:
- 圆角边框(
border-radius) - 阴影效果(
box-shadow) - 内容框分割(
box-sizing) - 弹性盒子布局(Flexbox)
- 网格布局(Grid)
- 圆角边框(
-
颜色和渐变:
- RGBA和HSLA颜色表示法
- 线性渐变(
linear-gradient) - 径向渐变(
radial-gradient)
-
文本排版和效果:
- 自定义字体(
@font-face) - 多列文本布局(
column-count、column-gap等) - 文本阴影(
text-shadow) - 文本溢出省略号(
text-overflow: ellipsis)
- 自定义字体(
-
过渡和动画:
- 过渡效果(
transition) - 关键帧动画(
@keyframes、animation)
- 过渡效果(
-
变换和变形:
- 2D和3D变换(
transform) - 3D变换(
perspective、transform-style)
- 2D和3D变换(
-
背景和渐变:
- 背景图像大小调整(
background-size) - 多重背景图像(
background-image) - 多重背景渐变
- 背景图像大小调整(
-
多媒体查询和响应式设计:
- 媒体查询(
@media) - 视口单位(
vw、vh、vmin、vmax)
- 媒体查询(
-
过滤和混合:
- 图像滤镜(
filter) - 混合模式(
mix-blend-mode)
- 图像滤镜(
-
边框和滚动:
-
多边框(
border-image) -
自定义滚动条样式(
::-webkit-scrollbar)
-
5.css定位
1.1 静态定位(static) - 了解
- 静态定位是元素的默认定位方式,无定位的意思。它相当于 border 里面的none,静态定位static,不要定位的时候用。
- 语法:
选择器 { position: static;
}
- 静态定位 按照标准流特性摆放位置,它没有边偏移。
- 静态定位在布局时我们几乎不用的
1.2 相对定位(relative) - 重要
- 相对定位是元素在移动位置的时候,是相对于它自己原来的位置来说的(自恋型)。
- 语法:
选择器 { position: relative;
}
-
相对定位的特点:(务必记住)
-
1.它是相对于自己原来的位置来移动的(移动位置的时候参照点是自己原来的位置)。
-
2.原来在标准流的位置继续占有,后面的盒子仍然以标准流的方式对待它。
因此,相对定位并没有脱标。它最典型的应用是给绝对定位当爹的。
-
-
效果图:

1.3 绝对定位(absolute) - 重要
1.3.1 绝对定位的介绍
- 绝对定位是元素在移动位置的时候,是相对于它祖先元素来说的(拼爹型)。
- 语法:
选择器 { position: absolute; }
- 完全脱标 —— 完全不占位置;
- 父元素没有定位,则以浏览器为准定位(Document 文档)。

3.父元素要有定位
-
元素将依据最近的已经定位(绝对、固定或相对定位)的父元素(祖先)进行定位。
-

-
绝对定位的特点总结:(务必记住)
1.如果没有祖先元素或者祖先元素没有定位,则以浏览器为基准定位(Document 文档)。
2.如果祖先元素有定位(相对、绝对、固定定位),则以最近一级的有定位祖先元素为参考点移动位置。
3.绝对定位不再占有原先的位置。所以绝对定位是脱离标准流的。(脱标)
6.css实现水平垂直居中
1.利⽤定位+margin:auto
.father { width: 300px; height: 300px; background-color: pink; position: relative; } .son { position: absolute; width: 150px; height: 150px; background-color: greenyellow; top:0; left:0; right:0; bottom:0; margin:auto ; }⽗级设置为相对定位,⼦级绝对定位 ,并且四个定位属性的值都设置了0,那么这时候如果⼦级没有设 置宽⾼,则会被拉开到和⽗级⼀样宽⾼ 这⾥⼦元素设置了宽⾼,所以宽⾼会按照我们的设置来显示,但是实际上⼦级的虚拟占位已经撑满了整 个⽗级,这时候再给它⼀个 margin:auto 它就可以上下左右都居中了
2.利⽤定位+margin:负值
.father { width: 300px; height: 300px; background-color: pink; position: relative; } .son { position: absolute; width: 150px; height: 150px; background-color: greenyellow; top: 50%; left: 50%; margin-left:-75px; margin-top:-75px; }3.利⽤定位+transform
.father { width: 300px; height: 300px; background-color: pink; position: relative; } .son { position: absolute; width: 150px; height: 150px; background-color: greenyellow; top: 50%; left: 50%; transform: translate(-50%,-50%); }4.flex弹性布局
.father { width: 300px; height: 300px; background-color: pink; display: flex; align-items: center; justify-content: center; } .son { width: 150px; height: 150px; background-color: greenyellow; }7.css哪些属性可被子元素继承
1. 字体属性:
font、font-style、font-variant、font-weight、font-size、line-height等属性是字体样式的属性,都可以被子元素继承。
2. 文本属性:
color、text-indent、text-align、text-decoration、text-transform、letter-spacing、word-spacing等属性也是可以被子元素继承的属性。
3. 元素可见性:
visibility属性可以被子元素继承,它可以将元素隐藏起来,但不会改变网页的布局。
4. 表格属性:
border-collapse、border-spacing、caption-side、empty-cells等表格属性也是可继承属性。
5. 列表属性:
list-style、list-style-type、list-style-position等列表属性也可以被子元素继承,用于设置无序列表和有序列表的样式。
不可以被继承的css属性
1.display:规定元素应该生成的框的类型;
2.文本属性:vertical-align、text-decoration(用于设置文本的修饰线外观包括上/下划线,管穿线,删除线,闪烁 );
3.盒子模型的属性:width、height、margin、border、padding;
4.背景属性:background、background-color、background-image;
5.定位属性:float、clear、position、top、right、bottom、left、min-width、min-height、maxwidth、max-height、overflow、clip;
css层叠性
8.css选择器以及优先级
- id选择器(#box),选择id为box的元素
- 类选择器(.one),选择类名为one的所有元素
- 标签选择器(div),选择标签为div的所有元素
- 后代选择器(#box div),选择id为box元素内部所有的div元素
- ⼦选择器(.one>one_1),选择⽗元素为.one的所有.one_1的元素
- 相邻同胞选择器(.one+.two),选择紧接在.one之后的所有.two元素
- 群组选择器(div,p),选择div、p的所有元素
- 交集选择器(p.highlight) 选择 class 为 "highlight" 的所有
元素s
伪类选择器
:link :选择未被访问的链接
:visited:选取已被访问的链接
:active:选择活动链接
:hover :⿏标指针浮动在上⾯的元素
:focus :选择具有焦点的
:first-child:⽗元素的⾸个⼦元素
伪元素选择器
:first-letter :⽤于选取指定选择器的⾸字⺟
:first-line :选取指定选择器的⾸⾏
:before : 选择器在被选元素的内容前⾯插⼊内容
:after : 选择器在被选元素的内容后⾯插⼊内容
属性选择器
[attribute] 选择带有attribute属性的元素
[attribute=value] 选择所有使⽤attribute=value的元素
[attribute~=value] 选择attribute属性包含value的元素
[attribute|=value]:选择attribute属性以value开头的元素
css3新增
:first-of-type 表示⼀组同级元素中其类型的第⼀个元素
:last-of-type 表示⼀组同级元素中其类型的最后⼀个元素
:only-of-type 表示没有同类型兄弟元素的元素
:only-child 表示没有任何兄弟的元素
:nth-child(n) 根据元素在⼀组同级中的位置匹配元素
:nth-last-of-type(n) 匹配给定类型的元素,基于它们在⼀组兄弟元素中的位置,从末尾开始计
数
:last-child 表示⼀组兄弟元素中的最后⼀个元素
:root 设置HTML⽂档
:empty 指定空的元素
:enabled 选择可⽤元素
:disabled 选择被禁⽤元素
:checked 选择选中的元素
:not(selector) 选择与 <selector> 不匹配的所有元素
[attribute*=value]:选择attribute属性值包含value的所有元素
[attribute^=value]:选择attribute属性开头为value的所有元素
[attribute$=value]:选择attribute属性结尾为value的所有元素
优先级
!important>内联 > ID选择器 > 类选择器 > 标签选择器
到具体的计算层⾯,优先级是由 A 、B、C、D 的值来决定的,其中它们的值计算规则如下:
-
如果存在内联样式,那么 A = 1, 否则 A = 0
-
B的值等于 ID选择器出现的次数
-
C的值等于 类选择器 和 属性选择器 和 伪类 出现的总次数
-
D 的值等于 标签选择器 和 伪元素 出现的总次数
#nav-global > ul > li > a.nav-link
套⽤上⾯的算法,依次求出 A B C D 的值:
- 因为没有内联样式 ,所以 A = 0
- ID选择器总共出现了1次, B = 1
- 类选择器出现了1次, 属性选择器出现了0次,伪类选择器出现0次,所以 C = (1 + 0 + 0) = 1
- 标签选择器出现了3次, 伪元素出现了0次,所以 D = (3 + 0) = 3
上⾯算出的 A 、 B 、 C 、 D 可以简记作: (0, 1, 1, 3)
知道了优先级是如何计算之后,就来看看⽐较规则:
- 从左往右依次进⾏⽐较 ,较⼤者优先级更⾼
- 如果相等,则继续往右移动⼀位进⾏⽐较
- 如果4位全部相等,则后⾯的会覆盖前⾯的
经过上⾯的优先级计算规则,我们知道内联样式的优先级最⾼,如果外部样式需要覆盖内联样式,就需 要使⽤ !important
9. 清除浮动的方法
<style>
.fahter{
width: 400px;
border: 1px solid deeppink;
}
.big {
width: 200px;
height: 200px;
background-color: pink;
float: left;
}
.small{
width: 250px;
height: 250px;
background-color: green;
float: left;
}
</style>
</head>
<body>
<div class="fahter clearfix">
<div class="big">big</div>
<div class="small">small</div>
</div>
</body>
单标签法
.clear {
clear: both;
}
<div class="clear">额外标签法</div>
父级添加overflow方法
.fahter{
width: 400px;
border: 1px solid deeppink;
overflow: hidden;
}
使用after伪元素清除浮动,:after方式为空元素的升级版,好处是不用单独加标签了。IE8以上和非IE浏览器才支持:after
.clearfix:after{/*伪元素是行内元素 正常浏览器清除浮动方法*/
content: "";
display: block;
height: 0;
clear:both;
visibility: hidden;
}
</style>
</head>
<body>
<div class="fahter clearfix">
<div class="big">big</div>
<div class="small">small</div>
</div>
使用before和after双伪元素清除浮动
.clearfix:after,.clearfix:before{
content: "";
display: block;
clear: both;
}
10. 行内元素float:left后是否变为块级元素
行内元素设置成浮动之后变得更加像是 inline-block (行内块级元素,设置 成这个属性的元素会同时拥有行内和块级的特性, 最明显的不同是它的默认宽 度不是 100% ), 这时候给行内元素设置 padding-top 和 padding-bottom 或者 width 、 height 都是有效果的
11.如何实现单⾏/多⾏⽂本溢出的省略样式
理解也很简单,即⽂本在⼀⾏内显示,超出部分以省略号的形式展现 实现⽅式也很简单,涉及的 css 属性有:
-
text-overflow:规定当⽂本溢出时,显示省略符号来代表被修剪的⽂本
-
white-space:设置⽂字在⼀⾏显示,不能换⾏
-
overflow:⽂字⻓度超出限定宽度,则隐藏超出的内容
-
overflow 设为 hidden ,普通情况⽤在块级元素的外层隐藏内部溢出元素,或者配合下⾯两个属性 实现⽂本溢出省略
-
white-space:nowrap ,作⽤是设置⽂本不换⾏,是 overflow:hidden 和 text-overflow: ellipsis ⽣效的基础
-
text-overflow 属性值有如下: clip:当对象内⽂本溢出部分裁切掉 ellipsis:当对象内⽂本溢出时显示省略标记(...)
<style>
p{
overflow: hidden;
line-height: 40px;
width:400px;
height:40px;
border:1px solid red;
text-overflow: ellipsis;
white-space: nowrap;
}
</style>
</head>
<body>
<p>Lorem ipsum dolor, sit amet consectetur adipisicing elit. Expedita adipisci, ratione modi dicta, molestias cum maxime natus, cupiditate sit vel consequuntur quidem? At deserunt neque ab molestias tempora quam a.
Perferendis non, minus quaerat qui libero nostrum sapiente quam repellat, vel obcaecati eveniet. Voluptate voluptatum explicabo ea cum neque nesciunt tempore quaerat amet sit. Neque amet molestias tenetur minus repudiandae!</p>
多行文本移除省略
.demo {
position: relative;
line-height: 20px;
height: 40px;
overflow: hidden;
}
.demo::after {
content: "...";
position: absolute;
bottom: 0;
right: 0;
padding: 0 20px 0 10px;
}
实现原理很好理解,就是通过伪元素绝对定位到⾏尾并遮住⽂字,再通过 overflow: hidden 隐藏 多余⽂字
基于⾏数截断
纯 css 实现也⾮常简单,核⼼的 css 代码如下:
- -webkit-line-clamp: 2:⽤来限制在⼀个块元素显示的⽂本的⾏数,为了实现该效果,它需要组合 其他的WebKit属性)
- display: -webkit-box:和1结合使⽤,将对象作为弹性伸缩盒⼦模型显示
- -webkit-box-orient: vertical:和1结合使⽤ ,设置或检索伸缩盒对象的⼦元素的排列⽅式
- overflow: hidden:⽂本溢出限定的宽度就隐藏内容
- text-overflow: ellipsis:多⾏⽂本的情况下,⽤省略号“…”隐藏溢出范围的⽂本
p {
width: 400px;
border-radius: 1px solid red;
-webkit-line-clamp: 2;
display: -webkit-box;
-webkit-box-orient: vertical;
overflow: hidden;
text-overflow: ellipsis;
}
12.css画一个三角形
CSS 简写属性/复合属性
border
- 使用1个值时表示上、右、下、左的值都一样
- 使用2个值时,第一个值表示上/下,第二个值表示左/右
- 使用3个值时,第一个值表示上,第二个值表示左/右,第三个值表示下
- 使用4个值时,四个值分别代表上、右、下、左的值
border-radius
- 使用1个值时表示四个角的值都一样
- 使用2个值时,第一个值表示左上/右下,第二个值表示右上/左下
- 使用3个值时,第一个值表示左上,第二个值表示右上/左下,第三个值表示右下
- 使用4个值时,四个值分别代表左上、右上、右下、左下的值
background
background-color: #000000;
background-image: url(images/bg.png);
background-repeat: no-repeat;
background-position: top right;
可以简写成:
/*-----zeda--------*/
background: #000000 url(images/bg.png) no-repeat top right;
font
- font-style
- font-variant
- font-weight
- font-size/line-height
- font-family
<style>
.border {
width: 0;
height: 0;
border: 50px solid;
border-color: transparent transparent transparent #d9534f;
}
</style>
</head>
<body>
<div class="border"></div>
clip-path 就是使用它来绘制多边形(或圆形、椭圆形等)并将其定位在元素内。
.border {
width: 80px;
height: 100px;
background-color: skyblue;
clip-path: polygon(0 0, 0% 100%, 100% 50%);
}
linear-gradient
.border {
display: inline-block;
height: 100px;
width: 120px;
/* 线性方向是从左上角到右下角,背景色从蓝色开始变,到50%位置时切换为透明色再开始变,最后到100%位置时以透明色结束 */
background: linear-gradient(to top right, blue, blue 50%, transparent 50%, transparent 100%);
}
13.::before 和::after 中双冒号和单冒号有什么区别、作用?
在 CSS 中伪类一直用 : 表示,如 :hover, :active 等
伪元素在 CSS1 中已存在,当时语法是用 : 表示,如 :before 和 :after
后来在 CSS3 中修订,伪元素用 :: 表示,如 ::before 和 ::after,以此区分伪元素和伪类
由于低版本 IE 对双冒号不兼容,开发者为了兼容性各浏览器,可以继续使用 :after 这种老语法表示伪元素
- 单冒号(:)用于 css3 的伪类
- 双冒号(::)用于 css3 的伪元素
作用:::before 和 ::after 的主要作用是在元素内容前后加上指定内容。
另外,伪类与伪元素的区别有:
- 伪类与伪元素都是用于向选择器加特殊效果
- 伪类与伪元素的本质区别就是是否抽象创造了新元素
- 伪类只要不是互斥可以叠加使用
- 伪元素在一个选择器中只能出现一次,并且只能出现在末尾
- 伪类与伪元素优先级分别与类、标签优先级相同
14.z-index属性在什么情况下会失效?
通常 z-index 的使用是在有两个重叠的标签,在一定的情况下控制其中一个在另一个的上方或者下方出现。z-index值越大就越是在上层。z-index元素的position属性需要是relative,absolute或是fixed。
z-index属性在下列情况下会失效:
- 父元素position为relative时,子元素的z-index失效。解决:父元素position改为absolute或static;
- 元素没有设置position属性为非static属性。解决:设置该元素的position属性为relative,absolute或是fixed中的一种;
- 元素在设置z-index的同时还设置了float浮动。解决:float去除,改为
display:inline-block
15. 说说你对盒子模型的理解
一个盒子由四个部分组成:content、padding、border、margin
标准盒子模型,是浏览器默认的盒子模型
下面看看标准盒子模型的模型图:
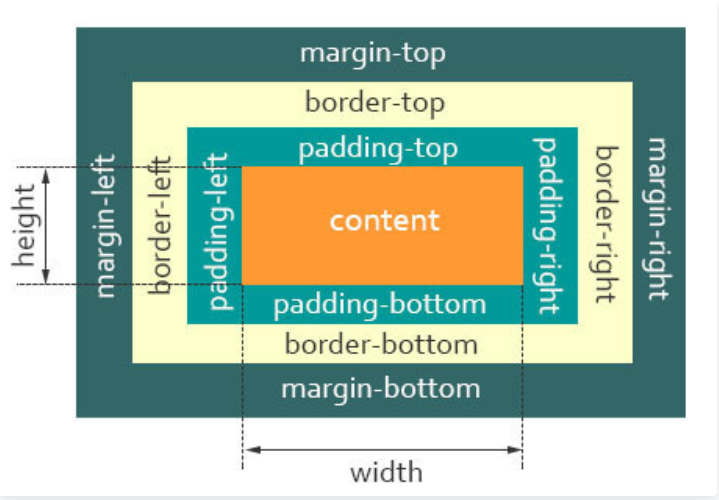
预览
从上图可以看到:
- 盒子总宽度 = width + padding + border + margin;
- 盒子总高度 = height + padding + border + margin
也就是,width/height 只是内容高度,不包含 padding 和 border 值
所以上面问题中,设置width为200px,但由于存在padding,但实际上盒子的宽度有240px
同样看看IE 怪异盒子模型的模型图:

预览
从上图可以看到:
- 盒子总宽度 = width + margin;
- 盒子总高度 = height + margin;
也就是,width/height 包含了 padding 和 border 值
Box-sizing
CSS 中的 box-sizing 属性定义了引擎应该如何计算一个元素的总宽度和总高度
语法:
1box-sizing: content-box|border-box|inherit;
- content-box 默认值,元素的 width/height 不包含padding,border,与标准盒子模型表现一致
- border-box 元素的 width/height 包含 padding,border,与怪异盒子模型表现一致
- inherit 指定 box-sizing 属性的值,应该从父元素继承
回到上面的例子里,设置盒子为 border-box 模型
1<style>
2.box {
3 width: 200px;
4 height: 100px;
5 padding: 20px;
6 box-sizing: border-box;
7}
8</style>
9<div class=\"box\">
10盒子模型
11</div>
这时候,就可以发现盒子的所占据的宽度为200px
16.em/px/rem/vh/vw 这些单位有什么区别?
在css单位中,可以分为长度单位、绝对单位,如下表所指示
| CSS单位 | |
|---|---|
| 相对长度单位 | em、ex、ch、rem、vw、vh、vmin、vmax、% |
| 绝对长度单位 | cm、mm、in、px、pt、pc |
这里我们主要讲述px、em、rem、vh、vw
px
px,表示像素,所谓像素就是呈现在我们显示器上的一个个小点,每个像素点都是大小等同的,所以像素为计量单位被分在了绝对长度单位中
有些人会把px认为是相对长度,原因在于在移动端中存在设备像素比,px实际显示的大小是不确定
这里之所以认为px为绝对单位,在于px的大小和元素的其他属性无关
em
em是相对长度单位。相对于当前对象内文本的字体尺寸。如当前对行内文本的字体尺寸未被人为设置,则相对于浏览器的默认字体尺寸(1em = 16px)
为了简化 font-size 的换算,我们需要在css中的 body 选择器中声明font-size= 62.5%,这就使 em 值变为 16px*62.5% = 10px
这样 12px = 1.2em, 10px = 1em, 也就是说只需要将你的原来的 px 数值除以 10,然后换上 em 作为单位就行了
特点:
- em 的值并不是固定的
- em 会继承父级元素的字体大小
- em 是相对长度单位。相对于当前对象内文本的字体尺寸。如当前对行内文本的字体尺寸未被人为设置,则相对于浏览器的默认字体尺寸
- 任意浏览器的默认字体高都是 16px
举个例子
<div class="big">
我是14px=1.4rem
<div class="small">我是12px=1.2rem</div>
4</div>
样式为
<style>
html {font-size: 10px; } /* 公式16px*62.5%=10px */
.big{font-size: 1.4rem}
.small{font-size: 1.2rem}
</style>
这时候.big元素的font-size为14px,而.small元素的font-size为12px
rem
rem,相对单位,相对的只是HTML根元素font-size的值
同理,如果想要简化font-size的转化,我们可以在根元素html中加入font-size: 62.5%
html {font-size: 62.5%; } /* 公式16px*62.5%=10px */
这样页面中1rem=10px、1.2rem=12px、1.4rem=14px、1.6rem=16px;使得视觉、使用、书写都得到了极大的帮助
特点:
- rem单位可谓集相对大小和绝对大小的优点于一身
- 和em不同的是rem总是相对于根元素,而不像em一样使用级联的方式来计算尺寸
vh、vw
vw ,就是根据窗口的宽度,分成100等份,100vw就表示满宽,50vw就表示一半宽。(vw 始终是针对窗口的宽),同理,vh则为窗口的高度
这里的窗口分成几种情况:
- 在桌面端,指的是浏览器的可视区域
- 移动端指的就是布局视口
像vw、vh,比较容易混淆的一个单位是%,不过百分比宽泛的讲是相对于父元素:
对于普通定位元素就是我们理解的父元素
- 对于position: absolute;的元素是相对于已定位的父元素
- 对于position: fixed;的元素是相对于 ViewPort(可视窗口)
三、总结
px:绝对单位,页面按精确像素展示
em:相对单位,基准点为父节点字体的大小,如果自身定义了font-size按自身来计算,整个页面内1em不是一个固定的值
rem:相对单位,可理解为root em, 相对根节点html的字体大小来计算
vh、vw:主要用于页面视口大小布局,在页面布局上更加方便简单
17.IconFont 的原理是什么
conFont 的使用原理来自于 css 的 @font-face 属性。
这个属性用来定义一个新的字体,基本用法如下:
@font-face {
font-family: <YourFontName>;
src: <url> [<format>],[<source> [<format>]], *;
[font-weight: <weight>];
[font-style: <style>];
}
- font-family:为载入的字体取名字。
- src:[url]加载字体,可以是相对路径,可以是绝对路径,也可以是网络地址。[format]定义的字体的格式,用来帮助浏览器识别。主要取值为:【truetype(.ttf)、opentype(.otf)、truetype-aat、embedded-opentype(.eot)、svg(.svg)、woff(.woff)】。
- font-weight:定义加粗样式。
- font-style:定义字体样式。
18.怎么做移动端的样式适配?
19.怎么实现样式隔离
20.常见布局
两栏布局一般指的是页面中一共两栏,左边固定,右边自适应的布局,一共有四种实现的方式。//以左边宽度固定为200px为例/
/*(1)利用浮动,将左边元素宽度设置为200px,并且设置向左浮动。将右边元素的margin-left设置为200px,宽度设置为auto(默认为auto,撑满整个父元素)。*/
.outer {
height: 100px;}
.left {
float: left;
height: 100px;
width: 200px;
background: tomato;}
.right {
margin-left: 200px;
width: auto;
height: 100px;
background: gold;}
/*(2)第二种是利用flex布局,将左边元素的放大和缩小比例设置为0,基础大小设置为200px。将右边的元素的放大比例设置为1,缩小比例设置为1,基础大小设置为auto。*/
.outer {
display: flex;
height: 100px;}
.left {
flex-shrink: 0;
flex-grow: 0;
flex-basis: 200px;
background: tomato;}
.right {
flex: auto; /*11auto*/
background: gold;}
/*(3)第三种是利用绝对定位布局的方式,将父级元素设置相对定位。左边元素设置为absolute定位,并且宽度设置为200px。将右边元素的margin-left的值设置为200px。*/
.outer {
position: relative;
height: 100px;}
.left {
position: absolute;
width: 200px;
height: 100px;
background: tomato;}
.right {
margin-left: 200px;
height: 100px;
background: gold;}
/*(4)第四种还是利用绝对定位的方式,将父级元素设置为相对定位。左边元素宽度设置为200px,右边元素设置为绝对定位,左边定位为200px,其余方向定位为0。*/
.outer {
position: relative;
height: 100px;}
.left {
width: 200px;
height: 100px;
background: tomato;}
.right {
position: absolute;
top: 0;
right: 0;
bottom: 0;
left: 200px;
background: gold;}
/三栏布局一般指的是页面中一共有三栏,左右两栏宽度固定,中间自适应的布局,一共有五种实现方式。这里以左边宽度固定为100px,右边宽度固定为200px为例。/
/*(1)利用绝对定位的方式,左右两栏设置为绝对定位,中间设置对应方向大小的margin的值。*/
.outer {
position: relative;
height: 100px;}
.left {
position: absolute;
width: 100px;
height: 100px;
background: tomato;}
.right {
position: absolute;
top: 0;
right: 0;
width: 200px;
height: 100px;
background: gold;}
.center {
margin-left: 100px;
margin-right: 200px;
height: 100px;
background: lightgreen;}
/*(2)利用flex布局的方式,左右两栏的放大和缩小比例都设置为0,基础大小设置为固定的大小,中间一栏设置为auto*/
.outer {
display: flex;
height: 100px;}
.left {
flex: 00100px;
background: tomato;}
.right {
flex: 00200px;
background: gold;}
.center {
flex: auto;
background: lightgreen;}
/*(3)利用浮动的方式,左右两栏设置固定大小,并设置对应方向的浮动。中间一栏设置左右两个方向的margin值,注意这种方式,中间一栏必须放到最后。*/
.outer { height: 100px;}
.left {
float: left;
width: 100px;
height: 100px;
background: tomato;}
.right {
float: right;
width: 200px;
height: 100px;
background: gold;}
.center {
height: 100px;
margin-left: 100px;
margin-right: 200px;
background: lightgreen;}
/*(4)圣杯布局,利用浮动和负边距来实现。父级元素设置左右的 padding,三列均设置向左浮动,中间一列放在最前面,宽度设置为父级元素的宽度,因此后面两列都被挤到了下一行,通过设置 margin 负值将其移动到上一行,再利用相对定位,定位到两边。*/
.outer {
height: 100px;
padding-left: 100px;
padding-right: 200px;}
.left {
position: relative;
left: -100px;
float: left;
margin-left: -100%;
width: 100px;
height: 100px;
background: tomato;}
.right {
position: relative;
left: 200px;
float: right;
margin-left: -200px;
width: 200px;
height: 100px;
background: gold;}
.center {
float: left;
width: 100%;
height: 100px;
background: lightgreen;}
/*(5)双飞翼布局,双飞翼布局相对于圣杯布局来说,左右位置的保留是通过中间列的 margin 值来实现的,而不是通过父元素的 padding 来实现的。本质上来说,也是通过浮动和外边距负值来实现的。*/
.outer { height: 100px;}
.left {
float: left;
margin-left: -100%;
width: 100px;
height: 100px;
background: tomato;}
.right {
float: left;
margin-left: -200px;
width: 200px;
height: 100px;
background: gold;}
.wrapper {
float: left;
width: 100%;
height: 100px;
background: lightgreen;}
.center {
margin-left: 100px;
margin-right: 200px;
height: 100px;}
·JavaScript
1.js数据类型有几种
js数据类型
- Number
- String
- Boolean
- Null
- Undefined
- Object
- Symbol
- BigInt
按照类型来分有基本数据类型和引用数据类型:
基本数据类型:String、Number、Boolean、Null、Undefined、Symbol、BigInt
引用数据类型:Object【Object是个大类,function函数、array数组、date日期...等都归属于Object】
2. for in和for of 的区别
for in 用它可以遍历数组,对象,集合。遍历数组遍历的值是数组index索引,遍历对象和集合时遍历的是key值。
ad59e3c46d7766249af49e932232a3f4
//遍历数组
var arr = [1,3,5,7]
for (var index in arr) {
console.log(index) //输出0,1,2,3
}
//遍历对象
var obj = {
name: '张三',
gender: '男',
age: 18
}
for (var key in obj) {
console.log(key) //输出name,gender,age
}
//遍历集合
var map = new Map()
map.name = "zs"
map.gender = "男"
map.age = 18 //相当于添加了三个属性,不是以长度没有变化
for (const value in map) {
console.log(value) //name,gender,age
}
for of 是es6 新加加入的语法,适用于遍历数组,字符串,map/set等拥有iterator迭代器的的集合。遍历数组它与for in 遍历的结果不一样,它遍历的是数组的value值,而不是数组索引值index,结果如下:
for of 不能遍历对象,只能遍历带有iterator接口的,例如Set,Map,String,Array
var arr = [1,3,5,7]
for (var value of arr) {
console.log(value) //输出1,3,5,7
}
var str = "你好世界!"
for (var value in str) {
console.log(value) //输出 你,好,世,界!
}
//遍历集合
var map = new Map()
map.set('name','张三')
map.set('gender','男')
map.set('age',18)
//得到key-value的结果:
for (const entries of map) {
console.log(entries) //['name', '张三'],['gender', '男'],['age', 18]
}
//遍历key值
for (const key of map.keys()) {
console.log(key)//name,gender,age
}
//遍历value值
for (const value of map.values()) {
console.log(value)//张三,男,18
}
虽然然Object没有内置迭代器iterator,但我们可以通过Object提供的方法来遍历对象值:
var obj = {
name: '张三',
gender: '男',
age: 18
}
//通过Object()
for (const obj of Object(map)) {
console.log(obj)//['name', '张三'],['gender', '男'],['age', 18]
}
//通过Object.keys()
for (const key of Object.values(obj)) {
console.log(key)//name,gender,age
}
//通过Object.values()
for (const value of Object.values(obj)) {
console.log(value)//张三,男,18
}
3. for循环中var和let的思考
1、for循环有一个特别之处,就是设置循环变量的那部分是一个父作用域,而循环体内部是一个单独的子作用域。
2、只要块级作用域内存在let、const命令,它所声明的变量就“绑定”(binding)这个区域,不再受外部的影响。
3、var 会穿透 for 、if 等语句。
4、let不允许在相同作用域内,重复声明同一个变量。
1、代码一
for (var i = 0; i < 3; i++) {
let i = 'abc';
console.log(i);
}
结果:输出三遍 ‘abc’
原因:父子作用域互不干扰,所以打印三遍‘abc’。其中,由于var会穿透for语句,全局作用域下,多了一个 i 的变量,值为3
2、代码二
for (let i = 0; i < 3; i++) {
let i = 'abc';
console.log(i);
}
结果:输出三遍 ‘abc’
原因:父子作用域互不干扰,所以打印三遍‘abc’。
3、代码三
for (var i = 0; i < 3; i++) {
var i = 'abc';
console.log(i);
}
结果:输出一遍 ‘abc’
原因:执行第一个循环的时候,由于var会穿透for语句,i=‘abc’改变了全局环境的i,i++变成了NaN,跳出循环,所以打印一遍‘abc’。其中,全局作用域下,多了一个 i 的变量,值为NaN
4、代码四
for (let i = 0; i < 3; i++) {
var i = 'abc';
console.log(i);
}
结果:报错:Uncaught SyntaxError: Identifier ‘i’ has already been declared
原因:由于var会穿透for语句,循环体内部的i提升到了设置循环变量那部分的父作用域,由于let不允许在相同作用域内,重复声明同一个变量,所以报错。
这段代码我们应该都见过,想要的效果是我们每隔一秒钟分别打印出来1,2,3,4,5。然而,效果却是打印了5,5,5,5,5。但是我们把声明i的声明语句改成let就可以这是为什么呢?
for (var i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, i*1000);
}
原因是因为,var声明的变量会被变量提升,上面一段代码相当于
var i;
for (i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, i*1000);
}
那么为什么使用let就可以解决呢?
因为let声明的变量会存在一个块级作用域的概念,使用let声明迭代变量时,js引擎会在后台为每一个迭代循环声明一个新的迭代变量,因此每次使用的i算是不同的。
如何不使用let来解决var变量作用域相同的问题呢?
-
内部函数引用外部的变量
-
有内部函数
-
有外部函数
for (var i = 0; i < 5; i++) {
//2.a的结果时一个函数
let a = creater();
//3.执行i,此时i的值还未改变,此时另一个函数作用域中引用了i变量的值,因此i并不会就此销毁而是会被延用到a函数这个作用域中
a(i);
}
//1.creater相当于就是一个工厂函数,用来延长i的作用域
function creater() {
//4.此时参数的i就是a中的i。在创建函数时会创建一个作用域链,此时参数中的i指向的是a中的i,而a中的i又是全局中的i,在函数创建过程中会预装载全局变量对象,并保存到内部的scope中。此时就创建了一个新的空间,因此全局变量的修改就不会影响到i的改变。
return function (i) {
setTimeout(() => {
console.log(i);
}, i*1000);
};
}
4. js闭包的理解
闭包(closure)就是能够读取其他函数内部变量的函数。在javascript中,只有函数内部的子函数才能读取局部变量,所以闭包可以理解成 “定义在一个函数内部的函数”。在本质上,闭包是将函数内部和函数外部连接起来的桥梁。(闭包的最典型的应用是实现回调函数(callback) )。
1.让外部访问函数内部变量变成可能
2.变量会常驻在内存中
3.可以避免使用全局变量,防止全局变量污染;
- 闭包的第一个用途是使我们在函数外部能够访问到函数内部的变量。通过使用闭包,可以通过在外部调用闭包函数,从而在外部访问到函数内部的变量,可以使用这种方法来创建私有变量。
- 闭包的另一个用途是使已经运行结束的函数上下文中的变量对象继续留在内存中,因为闭包函数保留了这个变量对象的引用,所以这个变量对象不会被回收。
比如,函数 A 内部有一个函数 B,函数 B 可以访问到函数 A 中的变量,那么函数 B 就是闭包。
function A() {
let a = 1
window.B = function () {
console.log(a)
}
}
A()
B() // 1
在 JS 中,闭包存在的意义就是让我们可以间接访问函数内部的变量。经典面试题:循环中使用闭包解决 var 定义函数的问题
- 第一种是使用闭包的方式
for (var i = 1; i <= 5; i++) {;
(function(j) {
setTimeout(function timer() {
console.log(j)
}, j * 1000)
})(i)
}
- 第二种就是使用
setTimeout的第三个参数,这个参数会被当成timer函数的参数传入。
for (var i = 1; i <= 5; i++) {
setTimeout(
function timer(j) {
console.log(j)
}, i * 1000, i)
}
- 第三种就是使用
let定义i了来解决问题了,这个也是最为推荐的方式
for (let i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i)
}, i * 1000)
}
思考题
代码片段一。
var name = "The Window";
var object = {
name : "My Object",
getNameFunc : function(){
return function(){
return this.name;
};
}
};
alert(object.getNameFunc()()); //The Window
关键字"this"的含义取决于其所在的执行环境。
在这种情况下,"this"关键字在函数内部指向调用它的对象。在 object.getNameFunc()() 这一行代码中,outer函数返回的是 inner 函数的引用,并且inner函数被作为一个函数立即调用了。由于 getNameFunc 函数是作为 object 对象的属性调用的,因此 “this” 关键字在 inner 函数内部将指向 object 对象。
但是,需要注意的是,在inner函数内部的返回函数中,该函数被视为全局上下文的一部分,因此在这个环境中,“this” 关键字将指向全局对象(通常是浏览器中的 “window” 对象)。因此,outer函数通过返回 inner 函数的引用时,返回的函数内部的 “this” 关键字将指向全局对象 “window”,而不是原始的 object 对象。
因此,当执行 alert(object.getNameFunc()()); 时,弹出的警告框中将显示字符串 “The Window”,而不是 “My Object”。
代码片段二。
var name = "The Window";
var object = {
name : "My Object",
getNameFunc : function(){
var that = this;
return function(){
return that.name;
};
}
};
alert(object.getNameFunc()()); //My Object
通过使用一个辅助变量 “that”,可以解决上一个问题中的 “this” 关键字的问题。
在 object.getNameFunc() 函数中,将 “this” 关键字存储在变量 “that” 中。由于上下文的闭包,返回的函数可以访问到外部函数中的变量 “that”。所以,无论返回函数在什么环境中被调用,它将始终通过 “that” 变量来访问原始的 object 对象。
因此,当执行 alert(object.getNameFunc()()); 时,弹出的警告框中将显示字符串 “My Object”,而不是 “The Window”。这是因为在返回函数的上下文中,“that” 变量引用了包含它的 object 对象,而不是全局对象。
5. js中的this指向
一、全局环境下的this指向
在全局作用域下,this始终指向全局对象window,无论是否是严格模式!

congsole.log()完整的写法是window.console.log(),window可以省略,window调用了console.log()方法,所以此时this指向window。
二、函数内的this
- 普通函数内的this分为两种情况,严格模式下和非严格模式下。
1. 严格模式下:

直接test()调用函数,this指向undefined,window.test()调用函数this指向window。因此,在严格模式下, 我们对代码的的调用必须严格的写出被调用的函数的对象,不可以有省略或者说简写。
2. 非严格模式下:

非严格模式下,通过test()和window.test()调用函数对象,this都指向window。
三、对象中的this
对象内部方法的this指向调用这些方法的对象,也就是谁调用就指向谁。
1. 一层对象:

调用obj.skill()方法,返回值为蒙犽,说明此时this指向obj。
2. 二层对象:
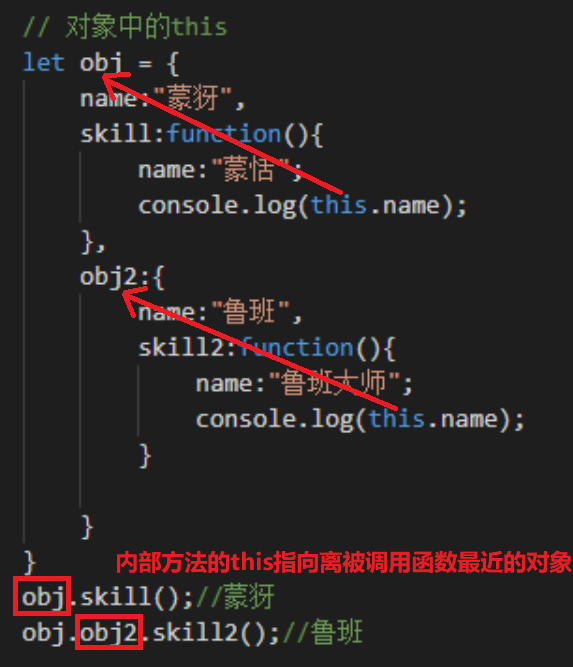
调用skill2()方法的顺序为,obj.obj2.skill2() ,返回值为鲁班,说明skill2()方法中的this指向obj2。
总结:
- 函数的定义位置不影响其this指向,this指向只和调用函数的对象有关。
- 多层嵌套的对象,内部方法的this指向离被调用函数最近的对象。
四、箭头函数中的this
箭头函数:this指向于函数作用域所用的对象。
- 箭头函数的重要特征:箭头函数中没有this和arguments,是真的没有!
- 箭头函数没有自己的this指向,它会捕获自己定义所处的外层执行环境,并且继承这个this值,指向当前定义时所在的对象。箭头函数的this指向在被定义的时候就确定了,之后永远都不会改变。即使使用
call()、apply()、bind()等方法改变this指向也不可以。
下面是普通函数的列子:
var name = 'window'; // 其实是window.name = 'window'
var A = {
name: 'A',
sayHello: function(){
console.log(this.name)
}
}
A.sayHello();// 输出A
var B = {
name: 'B'
}
A.sayHello.call(B);//输出B
A.sayHello.call();//不传参数指向全局window对象,输出window.name也就是window
从上面可以看到,sayHello这个方法是定义在A对象中的,当当我们使用call方法,把其指向B对象,最后输出了B;可以得出,sayHello的this只跟使用时的对象有关。
改造一下:
var name = 'window';
var A = {
name: 'A',
sayHello: () => {
console.log(this.name)
}
}
A.sayHello();// 还是以为输出A ? 错啦,其实输出的是window
我相信在这里,大部分同学都会出错,以为sayHello是绑定在A上的,但其实它绑定在window上的,那到底是为什么呢?
一开始,我重点标注了“该函数所在的作用域指向的对象”,作用域是指函数内部,这里的箭头函数,也就是sayHello,所在的作用域其实是最外层的js环境,因为没有其他函数包裹;然后最外层的js环境指向的对象是winodw对象,所以这里的this指向的是window对象。
那如何改造成永远绑定A呢:
var name = 'window';
var A = {
name: 'A',
sayHello: function(){
var s = () => console.log(this.name)
return s//返回箭头函数s
}
}
var sayHello = A.sayHello();
sayHello();// 输出A
var B = {
name: 'B';
}
sayHello.call(B); //还是A
sayHello.call(); //还是A
OK,这样就做到了永远指向A对象了,我们再根据“该函数所在的作用域指向的对象”来分析一下:
- 该函数所在的作用域:箭头函数s 所在的作用域是sayHello,因为sayHello是一个函数。
- 作用域指向的对象:A.sayHello指向的对象是A。
所以箭头函数s 中this就是指向A啦 ~~
z、改变this指向的方法
1. call()
call(a, b, c)方法接收三个参数,第一个是this指向,第二个,三个是传递给函数的实参,可以是数字,字符串,数组等类型的数据类型都可以。
示例:
//定义函数
function fn(n1,n2){
console.log(this);
console.log(n1,n2)
}
//调用call()方法
fn.call();//=>this:window;
let obj = {fn:fn};
fn.call(obj);//=>this:obj;n1,n2:undefined
fn.call(1,2);//=>this: 1;n1=2,n2=undefined;
fn.call(obj,1,2);//=>this: obj;n1=1,n2=2;
//Call方法的几个特殊属性
//非严格模式下
fn.call(undefined);//this=>window
fn.call(null);//this=>window
//严格模式下
"use strict"
fn.call(undefined);//this=>undefined
fn.call(null);//this=>null
2. apply()
apply(a, [b])和call基本上一致,唯一区别在于传参方式,apply把需要传递给fn()的参数放到一个数组(或者类数组)中传递进去,虽然写的是一个数组,但是也相当于给fn()一个个的传递。
//call()的传参方式
fn.call(obj, 1, 2);
//apply()的传参方式
fn.apply(obj, [1, 2]);
1234
示例:
//apply方法的使用和call方法基本相同,唯一的区别是,apply方法传参要求是数组类型的,数组内可以任意形式的数据
function fn (n1,n2){
console.log(this);
console.log(n1,n2)
console.log(arguments)
}
let obj = {fn:fn};
//调用apply()方法
fn.applay(abj,[1,2]);
fn.applay(abj,1,2);//报错
fn.applay(abj,[11,'apply',{a:123}]);//注意第二个参数必须是数组,否则会报错
123456789101112
3. bind()
-
bind(a, b, c):语法和call一模一样,区别在于立即执行还是等待执行,bind不兼容IE6~8 -
bind与call的唯一区别就是call直接改变函数test的指向,而bind是生成了一个新函数
test2(),该函数改变了指向。
//call()方法:改变fn中的this,并且把fn立即执行
fn.call(obj, 1, 2);
//bind()方法:改变fn中的this,fn并不执行
fn.bind(obj, 1, 2);
示例:
//bind和call方法调用形式类似,但是原理完全不同
fn.call(obj,10,20);//=>fn先执行,将fn内的this指向obj,并且把参数10,20传递给fn
fn.bind(obj,10,20)//bind是先将fn中的this指向obj,并且将参数10,20预先传递给fn,但是此时的fn并没有被执行,只有fn执行时this指向和传递参数才有作用
fn.bind(obj,10,20);//=>不会有任何输出
fn.bind(obj,10,20)();//=>调用后才会有输出
//=>需求:点击box这个盒子的时候,需要执行fn,并且让fn中的this指向obj
oBox.onclick=fn; //=>点击的时候执行了fn,但此时fn中的this是oBox
oBox.onclick=fn.call(opp); //=>绑定事件的时候就已经把fn立即执行了(call本身就是立即执行函数),然后把fn执行的返回值绑定给事件
oBox.onclick=fn.bind(opp);
//=>fn.bind(opp):fn调取Function.prototype上的bind方法,执行这个/*
* function(){
* fn.call(opp);
* }
*/
oBox.onclick=function(){
//=>this:oBox
fn.call(opp);
}
6.js中原型和原型链
在 JavaScript 中是使用构造函数来新建一个对象的,每一个构造函数的内部都有一个 prototype 属性,它的属性值是一个对象,这个 对象包含了可以由该构造函数的所有实例共享的属性和方法。当使用构造函数新建一个对象后,在这个对象的内部将包含一个指针,这个指针指向构造函数的prototype属性对应的值,在 ES5 中这个指针 被称为对象的原型。一般来说不应该能够获取到这个值的,但是现在 浏览器中都实现了__ proto__ 属性来访问这个属性,但是最好不要 使用这个属性,因为它不是规范中规定的。ES5 中新增了一个 Object.getPrototypeOf() 方法,可以通过这个方法来获取对象的原 型
构造器(constructor)和原型(prototype)的关系怎么来描述呢
原型对象的 constructor 是 构造器。
构造器的 prototype 是原型对象。
在js中有一句话叫万物皆对象,每个对象都有原型。我们创建函数,如果采用new的方式调用,当然这种调用方式有个名字叫实例化。
// 创建一个函数
function B(name) {
this.name = name;
};
// 实例化
var bb = new B('实例化的b');
console.log(bb.name); // 实例化的b;
如上面的代码,bb是通过B实例化之后得到的对象。在这里B就是一个构造器,他所拥有的名字(this.name)属性会带给bb;这也符合之前杯子的例子,杯子的属性会从构造器中获得。
假如我们想要做出来的bb具有一定的功能,那么就需要在原型上下功夫了。根据上面构造器和原型的关系。我们可以这样做。
// 创建一个函数
function B(name) { this.name = name;};
// 在原型上添加一个方法
B.prototype.tan = function() { alert('弹出框');}
// 实例化
var bb = new B('实例化的b');
console.log(bb.name); // 实例化的b;
bb.tan(); // alert('弹出框');
在上面的代码中,我们在B的原型上添加了一个tan的方法,在实例化出来的bb也具备了这个方法。这里我们就简单实现了一个类。
用下面一张图,说明一下。实例对象(bb), 原型(prototype), 构造函数(constructor)的关系。
B是我们构造的一个类,这里称为构造函数。他用prototype指向了自己的原型。而他的原型也通过constructor指向了它。
B.prototype.constructor === B; // true;
bb和B没有直接的关联,虽然B是bb的构造函数,这里用虚线表示。bb有一个__ proto__属性,指向了B的prototype
bb.__ proto__ === B.prototype; // true;
bb.__ proto__.constructor = B; // true;
总之
1,每创建一个函数B,就会为该函数创建一个prototype属性,这个属性指向函数的原型对象;
2,原型对象会默认去取得constructor属性,指向构造函数。
3,当调用构造函数创建一个新实例bb后,该实例的内部将包含一个指针__ proto__,指向构造函数的原型对象。
7.原型链的终点是什么?
我们知道,所有引用对象都默认继承了Object,所有函数的默认原型都是Object的实例。
之前说过构造函数和原型之间具备对应关系,如下:
既然函数的默认原型都是Object的实例,B的原型对象也应该是Object的实例子,也就是说。B的原型的__ proto__应该指向Objct的原型。
Object的原型对象的原型是最底部了,所以不存在原型,指向NULL;
console.log(Object.prototype.__ proto__); // null;
Function对象*
我们知道,函数也是对象,任何函数都可以看作是由构造函数Function实例化的对象,所以Function与其原型对象之间也存在如下关系
如果将Foo函数看作实例对象的话,其构造函数就是Function(),原型对象自然就是Function的原型对象;同样Object函数看作实例对象的话,其构造函数就是Function(),原型对象自然也是Function的原型对象。
如果Function的原型对象看作实例对象的话,如前所述所有对象都可看作是Object的实例化对象,所以Function的原型对象的__ proto __指向Object的原型对象。
到这里prototype,__ proto __, constructor三者之间的关系我们就说完了
8.探究js继承的集中方法
1.原型链继承:
构造函数、原型和实例,三者之间存在着一定的关系,即每一个构造函数都有一个原型对象,原型对象又包含一个指向构造函数的指针,而实例则包含一个原型对象的指针。
function Parent() {
this.name = 'Parent';
this.sex = "男"
this.play =[1,2,3]
}
Parent.prototype.sayHello = function() {
console.log('I am ' + this.name+",今年"+this.age+"岁,性别:"+this.sex);
}
Parent.prototype.age = 13
function Child() {
this.name = 'Child';
}
let p = new Parent() // p.__proto__ ==Parent.prototype
Child.prototype = p // Child.prototype.__proto__ == Parent.prototype
var child = new Child();
var child1 = new Child()
child.sex="女"
child.play.push(4)
child.sayHello(); // I am Child,今年13岁,性别:男
console.log(child.age) //输出13
child.age = 14
console.log(child.age) //输出14
child1.sayHello() //I am Child,今年13岁,性别:男 sex并没有设置为女
console.log(child.play,child1.play); //(4) [1, 2, 3, 4] (4) [1, 2, 3, 4]
console.log(child.sex,child1.sex); //女 男
console.log(child,child1);
为什么设置child为女后,child1输出确实男 ,而引用数据类型则该改变?
引用类型属性在对象本身不存在时,会通过原型链共享同一个属性值,而基本类型属性则会直接在对象本身进行修改。
在代码中,sex属性在父类构造函数Parent中被定义为this.sex = "男",因此它是Parent对象的属性。在通过原型继承的过程中,子类构造函数Child的原型对象Child.prototype被设置为Parent的实例,因此它会继承Parent对象的所有属性,包括sex属性。
在创建子类对象child时,由于子类构造函数并没有定义sex属性,因此在对象本身中并不存在该属性。然而,在访问child.sex时,JavaScript会沿着原型链向上查找,最终找到了原型链上的Parent对象,从而获取到sex属性的值。
因此,尽管child对象本身没有sex属性,但它通过原型继承从Parent对象继承了sex属性的值,所以在打印child对象时,会显示sex: "男"。而在修改child.sex时,它只会修改child对象本身的sex属性,并不会影响原型链上的Parent对象的sex属性, 所以,即使child.sex被修改为"女",而childchild1对象仍然继承了原型链上的sex属性,所以打印出来仍然是"男"。
重点:让新实例的原型等于父类的实例。
特点:1、实例可继承的属性有:实例的构造函数的属性,父类构造函数属性,父类原型的属性。(新实例不会继承父类实例的属性!)
缺点:1、新实例无法向父类构造函数传参。
2、继承单一。
3、所有新实例都会共享父类实例的属性。(原型上的属性是共享的,一个实例修改了原型属性,另一个实例的原型属性也会被修改!)
2.构造函数继承:
function Parent(name) {
this.name = name;
this.sex = "男"
}
Parent.prototype.getName = function(){
console.log(this.name);
}
function Child(name) {
Parent.call(this, name);
}
var child = new Child('Child');
console.log(child.name); // 输出:Child
console.log(child.sex); //输出 男
child.getName() //Uncaught TypeError: child.getName is not a functionat 原型继承.html:49:11
console.log(child instanceof Parent) //false
重点:用.call()和.apply()将父类构造函数引入子类函数(在子类函数中做了父类函数的自执行(复制))
特点:1、只继承了父类构造函数的属性,没有继承父类原型的属性。它使父类的引用属性不会被共享
2、解决了原型链继承缺点1、2、3。
3、可以继承多个构造函数属性(call多个)。
4、在子实例中可向父实例传参。
缺点:1、只能继承父类构造函数的属性和方法,不能继承父类原型上的。
2、无法实现构造函数的复用。(每次用每次都要重新调用)
3、每个新实例都有父类构造函数的副本,臃肿。
3.组合继承:结合原型链继承和构造函数继承的方式,实现同时继承属性和方法
function Parent(name) {
this.name = name;
this.age = 13
this.play = [1,2,3]
}
Parent.prototype.sayHello = function() {
console.log('Hello, I am ' + this.name+",今年"+this.age+"岁")
}
function Child(name) {
Parent.call(this, name);
}
Child.prototype = new Parent();
var child = new Child('Child');
var ciild1 = new Child("Child1")
child.play.push(4)
child.age = 14
child.name = "小明"
child.sayHello() //Hello, I am 小明,今年13岁
ciild1.sayHello() //Hello, I am Child1,今年13岁
console.log(child.play,ciild1.play); //(4) [1, 2, 3, 4] (3) [1, 2, 3]
重点:结合了两种模式的优点,传参和复用
特点:1、可以继承父类原型上的属性,可以传参,可复用。
2、每个新实例引入的构造函数属性是私有的。
缺点:调用了两次父类构造函数(耗内存),子类的构造函数会代替原型上的那个父类构造函数。
4.原型式继承
//Object.create 方法,这个方法接收两个参数:一是用作新对象原型的对象、二是为新对象定义额外属性的对象(可选参数)
var parent = {
name: 'Parent',
sayHello: function() {
console.log('Hello, I am ' + this.name);
},
play:[1,2,3]
}
var child = Object.create(parent);
var child1 = Object.create(parent)
child.name = 'Child';
child.play.push(4)
child1.name = "child1"
child.sayHello(); // 输出:Hello, I am Child
child1.sayHello() // 输出:Hello, I am Child1
console.log(child.play,child1.play); //(4) [1, 2, 3, 4] (4) [1, 2, 3, 4]
console.log(child,child1);
最后两个数组输出结果是一样的,讲到这里你应该可以联想到 02 讲中浅拷贝的知识点,关于引用数据类型“共享”的问题,其实 Object.create 方法是可以为一些对象实现浅拷贝的
重点:用一个函数包装一个对象,然后返回这个函数的调用,这个函数就变成了个可以随意增添属性的实例或对象。object.create()就是这个原理。
特点:类似于复制一个对象,用函数来包装。
缺点:1、所有实例都会继承原型上的属性。
2、无法实现复用。(新实例属性都是后面添加的)
5.寄生式继承
使用原型式继承可以获得一份目标对象的浅拷贝,然后利用这个浅拷贝的能力再进行增强,添加一些方法,这样的继承方式就叫作寄生式继承。
function createChild(parent, name) {
var child = Object.create(parent);
child.name = name;
child.sayHi = function name(params) {
console.log("sayhi")
}
return child;
}
var parent = {
name: 'Parent',
sayHello: function() {
console.log('Hello, I am ' + this.name);
},
play:[1,2,3]
}
var child = createChild(parent,"小明")
var child1 = createChild(parent,"小红")
child.name = 'Child';
child.play.push(4)
child1.name = "child1"
child.sayHello(); // 输出:Hello, I am Child
child1.sayHello(); // 输出:Hello, I am Child1
child.sayHi() // sayhi
console.log(child.play,child1.play); //(4) [1, 2, 3, 4] (4) [1, 2, 3, 4]
console.log(child,child1);
重点:就是给原型式继承外面套了个壳子。跟3一样即两次调用父类的构造函数造成浪费,
优点:没有创建自定义类型,因为只是套了个壳子返回对象(这个),这个函数顺理成章就成了创建的新对象。
缺点:没用到原型,无法复用。
寄生组合式继承(常用)
function inheritPrototype(subType, superType){
var prototype = Object.create(superType.prototype); // 创建了父类原型的浅复制
prototype.constructor = subType; // 修正原型的构造函数
subType.prototype = prototype; // 将子类的原型替换为这个原型
// child.prototype = Object.create(parent.prototype)
// child.prototype.constructor = child
}
// function inheritPrototype(subType, superType) {
// subType.prototype = Object.setPrototypeOf(new superType(), superType.prototype);
// subType.prototype.constructor = subType;
// }
function Parent(name) {
this.name = name;
this.age = 13
this.play = [1,2,3]
}
Parent.prototype.sayHello = function() {
console.log('Hello, I am ' + this.name+",今年"+this.age+"岁")
console.log(11);
}
function Child(name) {
Parent.call(this, name);
}
inheritPrototype(Child,Parent)
var child = new Child('Child');
var ciild1 = new Child("Child1")
child.play.push(4)
child.age = 14
child.name = "小明"
console.log(child,ciild1);
child.sayHello() //Hello, I am 小明,今年13岁
ciild1.sayHello() //Hello, I am Child1,今年13岁
console.log(child.play,ciild1.play); //(4) [1, 2, 3, 4] (3) [1, 2, 3]
重点:修复了组合继承的问题
9. js判断数据类型的方法
1.typeof
通常用来判断基本数据类型,它返回表示数据类型的字符串(返回结果只能包括number,boolean,string,function,undefined,object); *注意,使用typeof来判断null和引用类型 返回的结果都是 'object'
可以使用typeof判断变量是否存在(如if(typeof a!="undefined"){...});
typeof 1 //number
typeof 'a' //string
typeof true //boolean
typeof undefined //undefined
typeof null //object
typeof {} //object
typeof [1,2,3] //object
function Fn(){}
typeof new Fn() //object
typeof new Array() //object
2.instanceof
使用instanceof,如:a instanceof A 根据instanceof的定义:判断参照对象(大写字母A)的prototype属性所指向的对象是否在被行测对象a的原型链上,instanceof 只能用来判断两个对象是否属于实例关系,而不能判断一个对象实例具体属于哪种类型,例如:
function A(name,age){
this.name = name;
this.age = age;
}
a = new A('张三',18);
console.log(a instanceof A) //true
obj = new Object()//创建一个空对象obj
//或者通过字面量来创建:
obj = {}
console.log(obj instanceof Object); // true
arr = new Array() //创建一个空数组arr 或arr = []
console.log(arr instanceof Array ); // true
date = new Date()
console.log(date instanceof Date ); // true
// 注意:instanceof后面一定要是对象类型,instanceof前面相当于它的实例对象,
// 后面的对象类型大小写不能写错,该方法试用一些条件选择或分支
但是这种方式判断有个弊端:对于number,string,boolean这三种基本数据类型,
只有通过构造函数定义比如:let num =new Number(1);这样定义才能检测出。
let num = 1; 这样定义是检测不出来的
简单实现instanceof:
function my_instanceof(L, R) {
const O = R.prototype;
if (L === null) {
return false;
}
L = L.__proto__;
while (true) {
if (L === null) {
return false;
}
if (L === O) {
return true;
}
L = L.__proto__;
}
}
3.constructor
- 针对于instanceof的弊端,我们使用constructor检测,constructor是原型对象的属性指向构造函数。
console.log('数据类型判断 - constructor');
let num = 23;
let date = new Date();
let str = "biu~";
let reg = new RegExp();
let bool = true;
let fn = function () {
console.log(886);
};
let udf = undefined;
let nul = null;
let array = [1, 2, 3];
console.log(num.constructor); // [Function: Number]
console.log(date.constructor); // [Function: Date]
console.log(str.constructor); // [Function: String]
console.log(bool.constructor); // [Function: Boolean]
console.log(fn.constructor); // [Function: Function]
console.log(reg.constructor); // [Function: RegExp]
console.log(array.constructor); // [Function: Array]
这种方式解决了instanceof的弊端,可以检测出除了undefined和null的9种类型(因为它两没有原生构造函数)
console.log(udf.constructor);//Cannot read property "constructor" of undefined
console.log(nul.constructor);//Cannot read property "constructor" of null
4.toString.call()
在《你不知道的javaScript》(中卷)中讲到:所有typeof返回值为"object"的对象,都包含一个内部属性[[Class]],我们可以把他看作一个内部的分类,而非传统意义上面向对象的类,这个属性无法直接访问,一般通过Object.prototype.toString(…)来查看。并且对于基本数据类类型null,undefined这样没有原生构造函数,内部的[[Class]]属性值仍然是Null和Undefined
Object.prototype.toString.call();
console.log(toString.call(123)); //[object Number]
console.log(toString.call('123')); //[object String]
console.log(toString.call(undefined)); //[object Undefined]
console.log(toString.call(true)); //[object Boolean]
console.log(toString.call({})); //[object Object]
console.log(toString.call([])); //[object Array]
console.log(toString.call(function(){})); //[object Function]
10 .说说你对作用域链的理解
Javascript中有三种作用域:
- 全局作用域;
- 函数作用域;
- 块级作用域;
全局作用域
任何不在函数中或是大括号中声明的变量,都是在全局作用域下,全局作用域下声明的变量可以在程序的任意位置访问
// 全局变量
var greeting = 'Hello World!';
function greet() {
console.log(greeting);
}
// 打印 'Hello World!'
greet();
函数作用域
函数作用域也叫局部作用域,如果一个变量是在函数内部声明的它就在一个函数作用域下面。这些变量只能在函数内部访问,不能在函数以外去访问
function greet() {
var greeting = 'Hello World!';
console.log(greeting);
}
// 打印 'Hello World!'
greet();
// 报错: Uncaught ReferenceError: greeting is not defined
console.log(greeting);
可见上述代码中在函数内部声明的变量或函数,在函数外部是无法访问的,这说明在函数内部定义的变量或者方法只是函数作用域
块级作用域
ES6引入了let和const关键字,和var关键字不同,在大括号中使用let和const声明的变量存在于块级作用域中。在大括号之外不能访问这些变量
{
// 块级作用域中的变量
let greeting = 'Hello World!';
var lang = 'English';
console.log(greeting); // Prints 'Hello World!'
}
// 变量 'English'
console.log(lang);
// 报错:Uncaught ReferenceError: greeting is not defined
console.log(greeting);
当在 Javascript 中使⽤⼀个变量的时候,⾸先 Javascript 引擎会尝试在当前作⽤域下去寻找该 变量,如果没找到,再到它的上层作⽤域寻找,以此类推直到找到该变量或是已经到了全局作⽤域 , 如果在全局作⽤域⾥仍然找不到该变量,它就会在全局范围内隐式声明该变量(⾮严格模式下)或是直接报错.
11.dom事件监听和事件委托
- DOM L0
- 事件源.on事件 = function()
- DOM L2
- 事件源.addEventListener(事件, 事件处理函数)
- 两种注册事件的区别
- 传统on注册(L0)
- 同一个对象,后面注册的事件会覆盖前面注册(同一个事件)
- 直接使用null覆盖偶就可以实现事件的解绑
- 都是冒泡阶段执行的
- 事件监听注册(L2)
- 语法: addEventListener(事件类型, 事件处理函数, 是否使用捕获)
- 后面注册的事件不会覆盖前面注册的事件(同一个事件)
- 可以通过第三个参数去确定是在冒泡或者捕获阶段执行
- 必须使用removeEventListener(事件类型, 事件处理函数, 获取捕获或者冒泡阶段)
- 匿名函数无法被解绑
- 传统on注册(L0)
事件传播是一种定义当发生事件时元素次序的方法。假如
,然后用户点击了这个
元素,应该首先处理哪个元素“click”事件?
在冒泡中,最内侧元素的事件会首先被处理,然后是更外侧的:首先处理
元素的点击事件,然后是
在捕获中,最外侧元素的事件会首先被处理,然后是更内侧的:首先处理
元素的点击事件。
在 addEventListener() 方法中,你能够通过使用“useCapture”参数来规定传播类型:
addEventListener(event, function, useCapture);
默认值是 false,将使用冒泡传播,如果该值设置为 true,则事件使用捕获传播。
事件委托
事件委托,会把一个或者一组元素的事件委托到它的父层或者更外层元素上,真正绑定事件的是外层元素,而不是目标元素
当事件响应到目标元素上时,会通过事件冒泡机制从而触发它的外层元素的绑定事件上,然后在外层元素上去执行函数
<div id="dv1">
<div id="dv2">
<div id="dv3">click</div>
</div>
</div>
<script>
let i1 = document.getElementById("dv1")
let i2 = document.getElementById("dv2")
let i3 = document.getElementById("dv3")
function f1(params) {
console.log(this.id);
}
i2.addEventListener("click",f1,true)
i3.addEventListener("click",f1,true)
i1.addEventListener("click",f1,true) //状态为true时为时事件捕获,输出 1 2 3
从上面应用场景中,我们就可以看到使用事件委托存在两大优点:
- 减少整个页面所需的内存,提升整体性能
- 动态绑定,减少重复工作
但是使用事件委托也是存在局限性:
focus、blur这些事件没有事件冒泡机制,所以无法进行委托绑定事件mousemove、mouseout这样的事件,虽然有事件冒泡,但是只能不断通过位置去计算定位,对性能消耗高,因此也是不适合于事件委托的
12. 说说new操作符具体干了什么
function Person (name,age) {
this.name = name
this.age = age
}
Person.prototype.sayName = function () {
console.log(this.name)
}
let man = new Person('xl',20)
console.log(man) // Person { name: 'xl', age: 20 }
man.sayName() // 'xl'
- new通过Person创建出来的实例可以访问到构造函数中的属性
- new通过Person创建出来的实例可以访问到构造函数原型链上的方法和属性 如果在构造函数内加上返回值是什么结果呢?
- 返回基本数据类型
function Car (price) {
this.price = price
return 20
}
let bigCar = new Car(90)
console.log(bigCar.price) // 90
可以看到返回基本数据类型时返回值会被忽略
- 返回引用数据类型
function Car (price) {
this.price = price
return { km: 200 }
}
let bigCar = new Car(90)
console.log(bigCar.price, bigCar.km) // undefined, 200
可以看到返回引用数据类型会被正常使用
new关键字主要做了以下的工作:
- 创建一个新的对象
obj - 将对象与构建函数通过原型链连接起来
- 将构建函数中的
this绑定到新建的对象obj上 - 根据构建函数返回类型作判断,如果是原始值则被忽略,如果是返回对象,需要正常处理
流程图如下:

手写new操作符
function mynew(Func, ...args) {
// 1.创建一个新对象
const obj = {}
// 2.新对象原型指向构造函数原型对象
obj.__proto__ = Func.prototype
// 3.将构建函数的this指向新对象
let result = Func.apply(obj, args)
// 4.根据返回值判断
return result instanceof Object ? result : obj
}
测试一下
function mynew(func, ...args) {
const obj = {}
obj.__proto__ = func.prototype
let result = func.apply(obj, args)
return result instanceof Object ? result : obj
}
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype.say = function () {
console.log(this.name)
}
let p = mynew(Person, "huihui", 123)
console.log(p) // Person {name: "huihui", age: 123}
p.say() // huihui
13.数组常用方法
一、操作方法
增
下面前三种是对原数组产生影响的增添方法,第四种则不会对原数组产生影响
push()unshift()splice()- concat()
push()
push()方法接收任意数量的参数,并将它们添加到数组末尾,返回数组的最新长度
let colors = []; // 创建一个数组
let count = colors.push("red", "green"); // 推入两项
console.log(count) // 2
unshift()
unshift()在数组开头添加任意多个值,然后返回新的数组长度
let colors = new Array(); // 创建一个数组
let count = colors.unshift("red", "green"); // 从数组开头推入两项
alert(count); // 2
splice
传入三个参数,分别是开始位置、0(要删除的元素数量)、插入的元素,返回空数组 ,如果不为0,则返回删除的元素
let colors = ["red", "green", "blue"];
let removed = colors.splice(1, 0, "yellow", "orange")
console.log(colors) // red,yellow,orange,green,blue
console.log(removed) // []
concat()
首先会创建一个当前数组的副本,然后再把它的参数添加到副本末尾,最后返回这个新构建的数组,不会影响原始数组
let colors = ["red", "green", "blue"];
let colors2 = colors.concat("yellow", ["black", "brown"]);
console.log(colors); // ["red", "green","blue"]
console.log(colors2); // ["red", "green", "blue", "yellow", "black", "brown"]
删
下面三种都会影响原数组,最后一项不影响原数组:
pop()shift()splice()- slice()
pop()
pop() 方法用于删除数组的最后一项,同时减少数组的length 值,返回被删除的项
let colors = ["red", "green"]
let item = colors.pop(); // 取得最后一项
console.log(item) // green
console.log(colors.length) // 1
shift()
shift()方法用于删除数组的第一项,同时减少数组的length 值,返回被删除的项
let colors = ["red", "green"]
let item = colors.shift(); // 取得第一项
console.log(item) // red
console.log(colors.length) // 1
splice()
传入两个参数,分别是开始位置,删除元素的数量,返回包含删除元素的数组
let colors = ["red", "green", "blue"];
let removed = colors.splice(0,1); // 删除第一项
console.log(colors); // green,blue
console.log(removed); // red,只有一个元素的数组
slice()
slice() 用于创建一个包含原有数组中一个或多个元素的新数组 ,包含从start到end(不包含该元素)的数组元素,不会影响原始数组
let colors = ["red", "green", "blue", "yellow", "purple"];
let colors2 = colors.slice(1);
let colors3 = colors.slice(1, 4);
console.log(colors) // red,green,blue,yellow,purple
concole.log(colors2); // green,blue,yellow,purple
concole.log(colors3); // green,blue,yellow
查
即查找元素,返回元素坐标或者元素值
- indexOf()
- includes()
- find()
indexOf()
返回要查找的元素在数组中的位置,如果没找到则返回 -1
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
numbers.indexOf(4) // 3
includes()
返回要查找的元素在数组中的位置,找到返回true,否则false
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
numbers.includes(4) // true
find()
返回第一个匹配的元素
const people = [
{
name: "Matt",
age: 27
},
{
name: "Nicholas",
age: 29
}
];
people.find((element, index, array) => element.age < 28) // // {name: "Matt", age: 27}
二、排序方法
数组有两个方法可以用来对元素重新排序:两者都会改变原数组
reverse()sort()
reverse()
顾名思义,将数组元素方向反转
let values = [1, 2, 3, 4, 5];
values.reverse();
alert(values); // 5,4,3,2,1
sort()
sort()方法接受一个比较函数,用于判断哪个值应该排在前面
function compare(value1, value2) {
if (value1 < value2) {
return -1;
} else if (value1 > value2) {
return 1;
} else {
return 0;
}
}
let values = [0, 1, 5, 10, 15];
values.sort(compare);
alert(values); // 0,1,5,10,15
三、转换方法
常见的转换方法有:
join()
join() 方法接收一个参数,即字符串分隔符,返回包含所有项的字符串 ,不改变原数组
let colors = ["red", "green", "blue"];
alert(colors.join(",")); // red,green,blue
alert(colors.join("||")); // red||green||blue
四、迭代方法
常用来迭代数组的方法(都不改变原数组)有如下:
- some()
- every()
forEach()- filter()
- map()
- reduce()
some()
对数组每一项都运行传入的测试函数,如果至少有1个元素返回 true ,则这个方法返回 true
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
let someResult = numbers.some((item, index, array) => item > 2);
console.log(someResult) // true
every()
对数组每一项都运行传入的测试函数,如果所有元素都返回 true ,则这个方法返回 true
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
let everyResult = numbers.every((item, index, array) => item > 2);
console.log(everyResult) // false
forEach()
对数组每一项都运行传入的函数,没有返回值
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
numbers.forEach((item, index, array) => {
// 执行某些操作
});
filter()
对数组每一项都运行传入的函数,函数返回 true 的项会组成数组之后返回
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
let filterResult = numbers.filter((item, index, array) => item > 2);
console.log(filterResult); // 3,4,5,4,3
map()
对数组每一项都运行传入的函数,返回由每次函数调用的结果构成的数组
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
let mapResult = numbers.map((item, index, array) => item * 2);
console.log(mapResult) // 2,4,6,8,10,8,6,4,2
reduce()
reduce() 方法对数组中的每个元素按序执行一个提供的 reducer 函数,每一次运行 reducer 会将先前元素的计算结果作为参数传入,最后将其结果汇总为单个返回值。
第一次执行回调函数时,不存在“上一次的计算结果”。如果需要回调函数从数组索引为 0 的元素开始执行,则需要传递初始值。否则,数组索引为 0 的元素将被用作初始值,迭代器将从第二个元素开始执行(即从索引为 1 而不是 0 的位置开始)。
arr.reduce(function(prev,cur,index,arr){
...
}, init);
123
arr :原数组;
prev :上一次调用回调时的返回值,或者初始值 init;
cur : 当前正在处理的数组元素;
index :当前正在处理的数组元素的索引,若提供 init 值,则索引为0,否则索引为1;
init :初始值
其实常用的参数只有两个:prev 和 cur。
const array1 = [1, 2, 3, 4];
// 0 + 1 + 2 + 3 + 4
const initialValue = 0;
const sumWithInitial = array1.reduce((accumulator, currentValue) => accumulator + currentValue, initialValue);
console.log(sumWithInitial);
// Expected output: 10
//最大值
var arr = [1,2,3,4];
// 法1:
var max = arr.reduce(function (prev, cur) {
return prev > cur ? prev : cur;
}); // 4
// 法2::Math.max(a,b,...,x,y) 返回数个数字中较大的值
var max = arr.reduce(function (prev, cur) {
return Math.max(prev,cur);
}); // 4
//去重
var arr = [1,2,3,4,2,1,5];
var newArr = arr.reduce((prev, cur)=> {
prev.indexOf(cur) === -1 && prev.push(cur);
return prev;
},[]); // [1, 2, 3, 4, 5]
14.数组去重常用方法
1.利用Set()+Array.from()
const arr = [1, 2, 2, 'abc', 'abc', true, true, false, false, undefined, undefined, NaN, NaN]
const result = Array.from(new Set(arr))
console.log(result) // [ 1, 2, 'abc', true, false, undefined, NaN ]
2.利用两层循环+数组的splice方法
通过两层循环对数组元素进行逐一比较,然后通过splice方法来删除重复的元素。此方法对NaN是无法进行去重的,因为进行比较时NaN !== NaN
const arr = [1, 2, 2, 'abc', 'abc', true, true, false, false, undefined, undefined, NaN, NaN]
function removeDuplicate(arr) {
let len = arr.length
for (let i = 0; i < len; i++) {
for (let j = i + 1; j < len; j++) {
if (arr[i] === arr[j]) {
arr.splice(j, 1)
len-- // 减少循环次数提高性能
j-- // 保证j的值自加后不变
}
}
}
return arr
}
const result = removeDuplicate(arr)
console.log(result) // [ 1, 2, 'abc', true, false, undefined, NaN, NaN ]
3.利用数组的indexOf方法
新建一个空数组,遍历需要去重的数组,将数组元素存入新数组中,存放前判断数组中是否已经含有当前元素,没有则存入。此方法也无法对NaN去重
const arr = [1, 2, 2, 'abc', 'abc', true, true, false, false, undefined, undefined, NaN, NaN]
function removeDuplicate(arr) {
const newArr = []
arr.forEach(item => {
if (newArr.indexOf(item) === -1) {
newArr.push(item)
}
})
return newArr // 返回一个新数组
}
const result = removeDuplicate(arr)
console.log(result) // [ 1, 2, 'abc', true, false, undefined, NaN, NaN ]
4.利用数组的includes方法
此方法逻辑与indexOf方法去重异曲同工,只是用includes方法来判断是否包含重复元素
const arr = [1, 2, 2, 'abc', 'abc', true, true, false, false, undefined, undefined, NaN, NaN]
function removeDuplicate(arr) {
const newArr = []
arr.forEach(item => {
if (!newArr.includes(item)) {
newArr.push(item)
}
})
return newArr
}
const result = removeDuplicate(arr)
console.log(result) // [ 1, 2, 'abc', true, false, undefined, NaN ]
注意:为什么includes能够检测到数组中包含NaN,其涉及到includes底层的实现。如下图为includes实现的部分代码,在进行判断是否包含某元素时会调用sameValueZero方法进行比较,如果为NaN,则会使用isNaN()进行转化。
具体实现可参考:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Array/includes

简单测试includes()对NaN的判断:
const testArr = [1, 'a', NaN]
console.log(testArr.includes(NaN)) // true
5.利用数组的filter()+indexOf()
filter方法会对满足条件的元素存放到一个新数组中,结合indexOf方法进行判断。
const arr = [1, 2, 2, 'abc', 'abc', true, true, false, false, undefined, undefined, NaN, NaN]
function removeDuplicate(arr) {
return arr.filter((item, index) => {
return arr.indexOf(item) === index
})
}
const result = removeDuplicate(arr)
console.log(result) // [ 1, 2, 'abc', true, false, undefined ]
注意:这里的输出结果中不包含NaN,是因为indexOf()无法对NaN进行判断,即arr.indexOf(item) === index返回结果为false。测试如下:
const testArr = [1, 'a', NaN]
console.log(testArr.indexOf(NaN)) // -1
6.利用Map()
Map对象是JavaScript提供的一种数据结构,结构为键值对形式,将数组元素作为map的键存入,然后结合has()和set()方法判断键是否重复。
const arr = [1, 2, 2, 'abc', 'abc', true, true, false, false, undefined, undefined, NaN, NaN]
function removeDuplicate(arr) {
const map = new Map()
const newArr = []
arr.forEach(item => {
if (!map.has(item)) { // has()用于判断map是否包为item的属性值
map.set(item, true) // 使用set()将item设置到map中,并设置其属性值为true
newArr.push(item)
}
})
return newArr
}
const result = removeDuplicate(arr)
console.log(result) // [ 1, 2, 'abc', true, false, undefined, NaN ]
7.利用对象
其实现思想和Map()是差不多的,主要是利用了对象的属性名不可重复这一特性。
const arr = [1, 2, 2, 'abc', 'abc', true, true, false, false, undefined, undefined, NaN, NaN]
function removeDuplicate(arr) {
const newArr = []
const obj = {}
arr.forEach(item => {
if (!obj[item]) {
newArr.push(item)
obj[item] = true
}
})
return newArr
}
const result = removeDuplicate(arr)
console.log(result) // [ 1, 2, 'abc', true, false, undefined, NaN ]
8.使用 reduce:遍历数组,对每个元素判断是否在新数组中出现过,如果没有则将其添加到新数组中。
const arr = [1, 2, 3, 2, 1, 4]
const uniqueArr = arr.reduce((acc, cur) => {
if (!acc.includes(cur)) {
acc.push(cur)
}
return acc
}, [])
console.log(uniqueArr) // [1, 2, 3, 4]
数组中包含对象去重
在 JavaScript 中,可以使用以下几种方法去重数组对象:
- 使用 Set Set 是 ES6 中新增的一种数据结构,它类似于数组,但是成员的值都是唯一的,可以用来去重。我们可以使用 Set 来去重数组对象,然后再将结果转换为数组。
javascript复制代码const arr = [
{ id: 1, name: 'Alice' },
{ id: 2, name: 'Bob' },
{ id: 1, name: 'Alice' },
{ id: 3, name: 'Charlie' }
];
const result = Array.from(new Set(arr.map(JSON.stringify)), JSON.parse);
console.log(result); // [{ id: 1, name: 'Alice' }, { id: 2, name: 'Bob' }, { id: 3, name: 'Charlie' }]
这个方法的原理是:先使用 Array.prototype.map() 将数组中的对象转换为字符串,然后再用 Set 去重,最后再将字符串转换回对象。
- 使用 reduce 我们也可以使用 reduce 方法进行去重,具体步骤如下:
遍历数组中的每一个元素; 对于每一个元素,判断它是否已经出现过(使用 Array.prototype.findIndex() 判断); 如果没有出现过,就将它添加到结果数组中。
javascript复制代码const arr = [
{ id: 1, name: "Alice" },
{ id: 2, name: "Bob" },
{ id: 1, name: "Alice" },
{ id: 3, name: "Charlie" },
]
const result = arr.reduce((acc, curr) => {
const index = acc.findIndex((item) => item.id === curr.id)
if (index < 0) {
acc.push(curr)
}
return acc
}, [])
console.log(result) // [{ id: 1, name: 'Alice' }, { id: 2, name: 'Bob' }, { id: 3, name: 'Charlie' }]
- 使用 Map Map 也可以用来去重数组对象,具体步骤如下:
遍历数组中的每一个元素; 对于每一个元素,判断它是否已经出现过(使用 Map.has() 判断); 如果没有出现过,就将它添加到结果数组中。
javascript复制代码const arr = [
{ id: 1, name: "Alice" },
{ id: 2, name: "Bob" },
{ id: 1, name: "Alice" },
{ id: 3, name: "Charlie" },
]
const map = new Map()
const result = []
for (const item of arr) {
if (!map.has(item.id)) {
map.set(item.id, true)
result.push(item)
}
}
console.log(result) // [{ id: 1, name: 'Alice' }, { id: 2, name: 'Bob' }, { id: 3, name: 'Charlie' }]
以上就是几种常用的去重数组对象的方法。
15.JavaScript字符串的常用方法有哪些?
一、操作方法
我们也可将字符串常用的操作方法归纳为增、删、改、查,需要知道字符串的特点是一旦创建了,就不可变
增
这里增的意思并不是说直接增添内容,而是创建字符串的一个副本,再进行操作
除了常用+以及${}进行字符串拼接之外,还可通过concat
concat
用于将一个或多个字符串拼接成一个新字符串
let stringValue = "hello ";
let result = stringValue.concat("world");
console.log(result); // "hello world"
console.log(stringValue); // "hello"
删
这里的删的意思并不是说删除原字符串的内容,而是创建字符串的一个副本,再进行操作
常见的有:
- slice()
- substr()
- substring()
这三个方法都返回调用它们的字符串的一个子字符串,而且都接收一或两个参数。
let stringValue = "hello world";
console.log(stringValue.slice(3)); // "lo world"
console.log(stringValue.substring(3)); // "lo world"
console.log(stringValue.substr(3)); // "lo world"
console.log(stringValue.slice(3, 7)); // "lo w"
console.log(stringValue.substring(3,7)); // "lo w"
console.log(stringValue.substr(3, 7)); // "lo worl"
改
这里改的意思也不是改变原字符串,而是创建字符串的一个副本,再进行操作
常见的有:
- trim()、trimLeft()、trimRight()
- repeat()
- padStart()、padEnd()
- toLowerCase()、 toUpperCase()
trim()、trimLeft()、trimRight()
删除前、后或前后所有空格符,再返回新的字符串
let stringValue = " hello world ";
let trimmedStringValue = stringValue.trim();
console.log(stringValue); // " hello world "
console.log(trimmedStringValue); // "hello world"
repeat()
接收一个整数参数,表示要将字符串复制多少次,然后返回拼接所有副本后的结果
let stringValue = "na ";
let copyResult = stringValue.repeat(2) // na na
padEnd()
复制字符串,如果小于指定长度,则在相应一边填充字符,直至满足长度条件
let stringValue = "foo";
console.log(stringValue.padStart(6)); // " foo"
console.log(stringValue.padStart(9, ".")); // "......foo"
toLowerCase()、 toUpperCase()
大小写转化
let stringValue = "hello world";
console.log(stringValue.toUpperCase()); // "HELLO WORLD"
console.log(stringValue.toLowerCase()); // "hello world"
查
除了通过索引的方式获取字符串的值,还可通过:
- chatAt()
- indexOf()
- startWith()
- includes()
charAt()
返回给定索引位置的字符,由传给方法的整数参数指定
let message = "abcde";
console.log(message.charAt(2)); // "c"
indexOf()
从字符串开头去搜索传入的字符串,并返回位置(如果没找到,则返回 -1 )
let stringValue = "hello world";
console.log(stringValue.indexOf("o")); // 4
startWith()、includes()
从字符串中搜索传入的字符串,并返回一个表示是否包含的布尔值
let message = "foobarbaz";
console.log(message.startsWith("foo")); // true
console.log(message.startsWith("bar")); // false
console.log(message.includes("bar")); // true
console.log(message.includes("qux")); // false
二、转换方法
split
把字符串按照指定的分割符,拆分成数组中的每一项
let str = "12+23+34"
let arr = str.split("+") // [12,23,34]
三、模板匹配方法
针对正则表达式,字符串设计了几个方法:
- match()
- search()
- replace()
match()
接收一个参数,可以是一个正则表达式字符串,也可以是一个RegExp对象,返回数组
let text = "cat, bat, sat, fat";
let pattern = /.at/;
let matches = text.match(pattern);
console.log(matches[0]); // "cat"
search()
接收一个参数,可以是一个正则表达式字符串,也可以是一个RegExp对象,找到则返回匹配索引,否则返回 -1
let text = "cat, bat, sat, fat";
let pos = text.search(/at/);
console.log(pos); // 1
eplace()
接收两个参数,第一个参数为匹配的内容,第二个参数为替换的元素(可用函数)
let text = "cat, bat, sat, fat";
let result = text.replace("at", "ond");
console.log(result); // "cond, bat, sat, fat"
16.谈谈 JavaScript 中的类型转换机制
一、显示转换
显示转换,即我们很清楚可以看到这里发生了类型的转变,常见的方法有:
- Number()
- parseInt()
- String()
- Boolean()
Number()
将任意类型的值转化为数值
先给出类型转换规则:
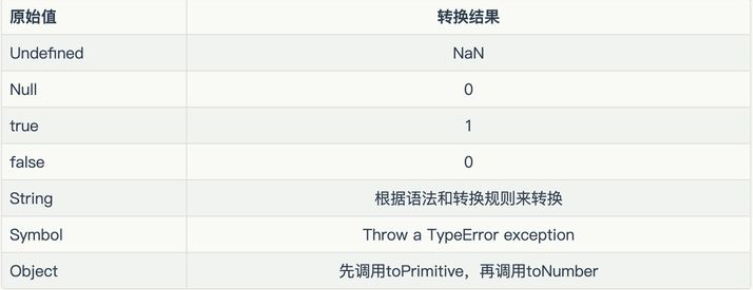
实践一下:
Number(324) // 324
// 字符串:如果可以被解析为数值,则转换为相应的数值
Number('324') // 324
// 字符串:如果不可以被解析为数值,返回 NaN
Number('324abc') // NaN
// 空字符串转为0
Number('') // 0
// 布尔值:true 转成 1,false 转成 0
Number(true) // 1
Number(false) // 0
// undefined:转成 NaN
Number(undefined) // NaN
// null:转成0
Number(null) // 0
// 对象:通常转换成NaN(除了只包含单个数值的数组)
Number({a: 1}) // NaN
Number([1, 2, 3]) // NaN
Number([5]) // 5
从上面可以看到,Number转换的时候是很严格的,只要有一个字符无法转成数值,整个字符串就会被转为NaN
parseInt()
parseInt相比Number,就没那么严格了,parseInt函数逐个解析字符,遇到不能转换的字符就停下来
特别注意,parseInt 解析空字符串为 NaN,Number 解析空字符串为0。
parseInt('32a3') //32
parseInt('qwe') // NaN
parseInt('') // NaN 这个要注意
parseFloat 工作方式和 parseInt 是一样的,只是 parseFloat 可以处理小数。
js复制代码parseInt(5.433) // 5
parseFloat(5.433) // 5.433
parseFloat('5.43.3') // 5.43 parseFloat 只解析第一个小数点
string()
可以将任意类型的值转化成字符串
给出转换规则图:

实践一下:
// 数值:转为相应的字符串
String(1) // "1"
//字符串:转换后还是原来的值
String("a") // "a"
//布尔值:true转为字符串"true",false转为字符串"false"
String(true) // "true"
//undefined:转为字符串"undefined"
String(undefined) // "undefined"
//null:转为字符串"null"
String(null) // "null"
//对象
String({a: 1}) // "[object Object]"
String([1, 2, 3]) // "1,2,3"
Boolean()
可以将任意类型的值转为布尔值,转换规则如下:

实践一下:
Boolean(undefined) // false
Boolean(null) // false
Boolean(0) // false
Boolean(NaN) // false
Boolean('') // false
Boolean({}) // true
Boolean([]) // true
Boolean(new Boolean(false)) // true
二、隐式转换
下面这些情况,JS 会发生隐式转换,
- 比较运算(
==、!=、>、<) - 算术运算(
+、-、*、/、%) - 逻辑语句
if、while需要布尔值的地方
当然,这些场景下运算符两边的操作数要不是同一类型,才会发生隐式转换。
1.算术运算符
1.减、乘、除
对各种非Number类型运用数学运算符(- * /)时,会先将非Number类型转换为Number类型。
100 - true // 99, 首先把 true 转换为数字 1, 然后执行 100 - 1
100 - null // 100, 首先把 null 转换为数字 0, 然后执行 100 - 0
1 * undefined // NaN, undefined 转换为数字是 NaN
2 * ['5'] // 10, ['5']首先会变成 '5', 然后再变成数字 5
2.加法
JS里 +还可以用来拼接字符串,所以要特殊一些,有下面3条规则:
- 当一侧为
String类型,被识别为字符串拼接,并会优先将另一侧转换为字符串类型。 - 当一侧为
Number类型,另一侧为原始类型,则将原始类型转换为Number类型。 - 当一侧为
Number类型,另一侧为引用类型,将引用类型和Number类型转换成字符串后拼接。
以上 3 点,优先级从高到低
123 + '123' // 123123 (规则1)
123 + null // 123 (规则2)
123 + true // 124 (规则2)
123 + {} // 123[object Object] (规则3)
2.逻辑运算符
if (1) {
// do something...
}
while (1) {
// 别这么写,会死循环的
// do something...
}
- undefined
- null
- false
- +0
- -0
- NaN
- '' 除了上面几种会被转化成
false,其他都换被转化成true
3.比较运算符
以 == 运算符举例
- 规则1:NaN 和其他任何类型比较永远返回 false(包括和他自己)。
js
NaN == NaN // false
- 规则2:Boolean 和其他任何类型比较,Boolean 首先被转换为 Number 类型。
true == 1 // true
true == '2' // false, 先把 true 变成 1,再参考规则3
true == ['1'] // true, 先把 true 变成 1, ['1']拆箱成 '1', 再参考规则3
true == ['2'] // false, 同上
undefined == false // false ,首先 false 变成 0,然后参考规则4
null == false // false,同上
- 规则3:String 和 Number 比较,先将 String 转换为 Number 类型。
123 == '123' // true, '123' 会先变成 123
'' == 0 // true, '' 会首先变成 0
- 规则4: null == undefined 比较结果是 true ,除此之外,null、undefined 和其他任何结果的比较值都为 false。
null == undefined // true
null == '' // false
null == 0 // false
null == false // false
undefined == '' // false
undefined == 0 // false
undefined == false // false
- 规则5:
原始类型和引用类型做比较时,引用类型会依照前文提过的ToPrimitive规则转换为原始类型。
'[object Object]' == {}
// true, 对象和字符串比较,对象通过 toString 得到一个基本类型值
'1,2,3' == [1, 2, 3]
// true, 同上 [1, 2, 3]通过 toString 得到一个基本类型值
- 规则6:两个都为引用类型,则比较它们是否指向同一个对象
let obj1 = { name: 'lin' }
let obj2 = { name: 'lin' }
obj1 == obj2 // false
let obj3 = { name: 'lin' }
let obj4 = obj3
obj3 == obj4 // true
其他比较运算符隐式类型转换规则和 == 是一样的,只是转换之后再做其他比较,比如 !=、>、<。
一个复杂对象在转为基础类型的时候会调用ToPrimitive(hint)方法来指定其目标类型。如果传入的hint值为number,那么就先调用对象的valueOf()方法,调用完valueOf()方法后,如果返回的是原始值,则结束ToPrimitive操作,如果返回的不是原始值,则继续调用对象的toString()方法,调用完toString()方法之后如果返回的是一个原始值,则结束ToPrimitive操作,如果返回的还是复杂值,则抛出异常。如果传入的hint值为string,则先调用toString()方法,再调用valueOf()方法,其余的过程一样。
调用valueOf()返回的结果:
| 对象 | 返回值 |
|---|---|
| Array | 返回数组本身 |
| Boolean | 布尔值 |
| Date | 存储的时间是从1970年1月1日午夜开始级的毫秒数UTC,eg:(new Date()).valueOf() -->1626695004310 (相当于调用了getTime()) |
| Function | 函数本身 |
| Number | 数字值 |
| Object | 对象本身(这是默认情况) |
| String | 字符串 |
| undefined、Null对象没有valueOf方法(Math、Error貌似有) |
调用toString()返回的结果:
| 对象 | 返回值 |
|---|---|
| Array | 以逗号分隔每个数组形成的字符串,约等于调用.join() |
| Boolean | “true”或“false” |
| Date | “Mon Jul 19 2021 18:46:05 GMT+0800 (中国标准时间)” |
| Function | 函数的文本定义 |
| Number | 数字转成的字符串如"123" |
| Object | “[object Object]” ,特例:用new关键字加上内置对象创建的Object类型数据,调用toString。eg: (new String(‘abc’)).toString() ==> ‘abc’ (相当于先给他拍成对应的基础数据类型再调用toString方法) |
| String | 字符串本身 |
什么是稀奇古怪的东西?比如,
s[] == ! [] // true
[] == [] // false
{} == !{} // false
{} == {} // false
const a = {
i: 1,
toString: function () {
return a.i++;
}
}
if (a == 1 && a == 2 && a == 3) {
console.log('hello world!');
}
17.什么是防抖和节流?有什么区别?如何实现?
定义
- 节流: n 秒内只运行一次,若在 n 秒内重复触发,只有一次生效
- 防抖: n 秒后在执行该事件,若在 n 秒内被重复触发,则重新计时
防抖
function debounce(func, wait) {
let timeout = null;
return function () {
let context = this; // 保存this指向
let args = arguments; // 拿到event对象
if (timer) clearTimeout(timeout)
timeout = setTimeout(function(){
func.apply(context, args)
timer = null;
}, wait);
}
}
立即执行
// 第一个参数是需要进行防抖处理的函数,第二个参数是延迟时间,默认为1秒钟
// 这里多传一个参数,immediate用来决定是否要第一次立即执行, 默认为false
function debounce(fn, delay = 1000, immediate = false) {
// 实现防抖函数的核心是使用setTimeout
// time变量用于保存setTimeout返回的Id
let time = null
// isImmediateInvoke变量用来记录是否立即执行, 默认为false
let isImmediateInvoke = false
// 将回调接收的参数保存到args数组中
return function(...args) {
// 如果time不为0,也就是说有定时器存在,将该定时器清除
if (time !== null) {
clearTimeout(time)
}
// 当是第一次触发,并且需要触发第一次事件
if (!isImmediateInvoke && immediate) {
fn.apply(this, args)
// 将isImmediateInvoke设置为true,这样不会影响到后面频繁触发的函数调用
isImmediateInvoke = true;
}
time = setTimeout(() => {
// 使用apply改变fn的this,同时将参数传递给fn
fn.apply(this, args)
// 当定时器里的函数执行时,也就是说是频繁触发事件的最后一次事件
// 将isImmediateInvoke设置为false,这样下一次的第一次触发事件才能被立即执行
isImmediateInvoke = false
}, delay)
}
}
节流
function debounce(func, wait) {
let timeout = null;
return function () {
let context = this; // 保存this指向
let args = arguments; // 拿到event对象
if (timer) return
timeout = setTimeout(function(){
func.apply(context, args)
timer = null;
}, wait);
}
}
function throttle(func, delay) {
let lastTime = 0;
return function() {
const currentTime = Date.now();
if (currentTime - lastTime >= delay) {
func.apply(this, arguments);
lastTime = currentTime;
}
};
}
// 使用示例
const throttledFunc = throttle(() => {
// 执行相应的操作
}, 300);
// 在事件监听中使用
element.addEventListener('scroll', throttledFunc);
18.说说 JavaScript 中内存泄漏的几种情况?
内存泄漏(Memory leak)是在计算机科学中,由于疏忽或错误造成程序未能释放已经不再使用的内存
并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费
程序的运行需要内存。只要程序提出要求,操作系统或者运行时就必须供给内存
对于持续运行的服务进程,必须及时释放不再用到的内存。否则,内存占用越来越高,轻则影响系统性能,重则导致进程崩溃
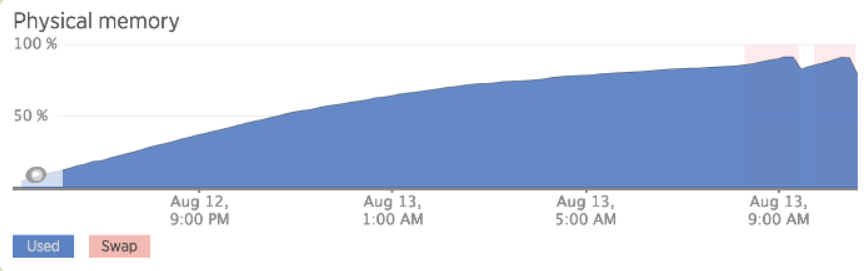
在C语言中,因为是手动管理内存,内存泄露是经常出现的事情。
char * buffer;
buffer = (char*) malloc(42);
// Do something with buffer
free(buffer);
上面是 C 语言代码,malloc方法用来申请内存,使用完毕之后,必须自己用free方法释放内存。
这很麻烦,所以大多数语言提供自动内存管理,减轻程序员的负担,这被称为"垃圾回收机制"
二、垃圾回收机制
Javascript 具有自动垃圾回收机制(GC:Garbage Collecation),也就是说,执行环境会负责管理代码执行过程中使用的内存
原理:垃圾收集器会定期(周期性)找出那些不在继续使用的变量,然后释放其内存
通常情况下有两种实现方式:
- 标记清除
- 引用计数
标记清除
JavaScript最常用的垃圾收回机制
当变量进入执行环境是,就标记这个变量为“进入环境“。进入环境的变量所占用的内存就不能释放,当变量离开环境时,则将其标记为“离开环境“
垃圾回收程序运行的时候,会标记内存中存储的所有变量。然后,它会将所有在上下文中的变量,以及被在上下文中的变量引用的变量的标记去掉
在此之后再被加上标记的变量就是待删除的了,原因是任何在上下文中的变量都访问不到它们了
随后垃圾回收程序做一次内存清理,销毁带标记的所有值并收回它们的内存
举个例子:
var m = 0,n = 19 // 把 m,n,add() 标记为进入环境。
add(m, n) // 把 a, b, c标记为进入环境。
console.log(n) // a,b,c标记为离开环境,等待垃圾回收。
function add(a, b) {
a++
var c = a + b
return c
}
引用计数
语言引擎有一张"引用表",保存了内存里面所有的资源(通常是各种值)的引用次数。如果一个值的引用次数是0,就表示这个值不再用到了,因此可以将这块内存释放
如果一个值不再需要了,引用数却不为0,垃圾回收机制无法释放这块内存,从而导致内存泄漏
const arr = [1, 2, 3, 4];
console.log('hello world');
上面代码中,数组[1, 2, 3, 4]是一个值,会占用内存。变量arr是仅有的对这个值的引用,因此引用次数为1。尽管后面的代码没有用到arr,它还是会持续占用内存
如果需要这块内存被垃圾回收机制释放,只需要设置如下:
arr = null
通过设置arr为null,就解除了对数组[1,2,3,4]的引用,引用次数变为 0,就被垃圾回收了
小结
有了垃圾回收机制,不代表不用关注内存泄露。那些很占空间的值,一旦不再用到,需要检查是否还存在对它们的引用。如果是的话,就必须手动解除引用
三、常见内存泄露情况
意外的全局变量
function foo(arg) {
bar = "this is a hidden global variable";
}
另一种意外的全局变量可能由 this 创建:
function foo() {
this.variable = "potential accidental global";
}
// foo 调用自己,this 指向了全局对象(window)
foo();
上述使用严格模式,可以避免意外的全局变量
定时器也常会造成内存泄露
var someResource = getData();
setInterval(function() {
var node = document.getElementById('Node');
if(node) {
// 处理 node 和 someResource
node.innerHTML = JSON.stringify(someResource));
}
}, 1000);
如果id为Node的元素从DOM中移除,该定时器仍会存在,同时,因为回调函数中包含对someResource的引用,定时器外面的someResource也不会被释放
包括我们之前所说的闭包,维持函数内局部变量,使其得不到释放
function bindEvent() {
var obj = document.createElement('XXX');
var unused = function () {
console.log(obj, '闭包内引用obj obj不会被释放');
};
obj = null; // 解决方法
}
没有清理对DOM元素的引用同样造成内存泄露
const refA = document.getElementById('refA');
document.body.removeChild(refA); // dom删除了
console.log(refA, 'refA'); // 但是还存在引用能console出整个div 没有被回收
refA = null;
console.log(refA, 'refA'); // 解除引用
包括使用事件监听addEventListener监听的时候,在不监听的情况下使用removeEventListener取消对事件监听
19.扩展运算符的用法
- 数组
1.1 构造数组 没有扩展运算符的时候,只能组合使用 push,splice,concat 等方法,将已有数组元素变成新数组的一部分。 有了扩展运算符, 构造新数组会变得更简单、更优雅: 扩展运算符(spread)就是我们知道的三个点(...),它就好像 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列。
console.log(...[1,2,3]);
// 1 2 3
console.log(1,...[2,3,4],5)
// 1 2 3 4 5
console.log([1,...[2,3,4],5])
// [1, 2, 3, 4, 5]
1.2 数组拷贝 展开语法和 Object.assign() 行为一致, 执行的都是浅拷贝
let arr = [1, 2, 3];
let arr2 = [...arr]; // [1, 2, 3]
arr2.push(4);
console.log(arr2); // [1, 2, 3, 4]
// 数组含空位
let arr3 = [1, , 3],
arr4 = [...arr3];
console.log(arr4); // [1, undefined, 3]
1.3 合并数组 本质:将一个数组转为用逗号分隔的参数序列,然后置于数组中
var arr1 = [0, 1, 2];
var arr2 = [3, 4, 5];
var arr3 = [...arr1, ...arr2];// 将 arr2 中所有元素附加到 arr1 后面并返回
//等同于
var arr4 = arr1.concat(arr2);
console.log(arr3,arr4) // [0,1,2,3,4,5] [0,1,2,3,4,5]
- 对象
扩展运算符(...)用于取出 参数对象 所有 可遍历属性 然后拷贝到当前对象。 2.1 克隆对象 当 String,Number,Boolean 时,属于深拷贝; 当 Object,Array时,属于浅拷贝;
var obj1 = { foo: 'bar', x: 42 };
var clonedObj = { ...obj1 };
console.log(clonedObj); // { foo: "bar", x: 42 }
2.2 合并对象
let age = {age: 15};
let name = {name: "Amy"};
let person = {...age, ...name};
console.log(person); // {age: 15, name: "Amy"}
注意: 自定义的属性在拓展运算符后面,则拓展运算符对象内部同名的属性将被覆盖掉; 自定义的属性在拓展运算度前面,则自定义的属性将被覆盖掉;
let person = {name: "Amy", age: 15};
let someone = { ...person, name: "Mike", age: 17};
let someone1 = { name: "Mike", age: 17,...person};
console.log(someone); // {name: "Mike", age: 17}
console.log(someone1); // {name: "Amy", age: 15}
扩展运算符后面是空对象、null、undefined,没有任何效果也不会报错。
//空对象
let a = {...{}, a: 1, b: 2};
console.log(a); //{a: 1, b: 2}
// null 、 undefined
let b = {...null, ...undefined, a: 1, b: 2};
console.log(b); //{a: 1, b: 2}
- 函数
函数调用中,扩展运算符(...)将一个数组,变为参数序列
function sum(x, y, z) {
return x + y + z;
}
const numbers = [1, 2, 3];
//不使用延展操作符
console.log(sum.apply(null, numbers));
//使用延展操作符
console.log(sum(...numbers)); // 6
扩展运算符与的函数参数可以结合使用,非常灵活:
function f(x,y,z,v,w,u){
console.log(x,y,z,v,w,u)
}
var args = [0,1,5];
f(-1,...args,2,...[3]); // -1, 0, 1, 5, 2 ,3
4.字符串转字符数组
String 也是一个可迭代对象,所以也可以使用扩展运算符 ... 将其转为字符数组,如下:
const title = "china";
const charts = [...title];
console.log(charts); // [ 'c', 'h', 'i', 'n', 'a' ]
进而可以简单进行字符串截取,如下:
const title = "china";
const short = [...title];
short.length = 2;
console.log(short.join("")); // ch
解构变量
解构数组,如下:
const [currentMonth, ...others] = [7, 8, 9, 10, 11, 12];
console.log(currentMonth); // 7
console.log(others); // [ 8, 9, 10, 11, 12 ]
解构对象,如下:
const userInfo = { name: "Crayon", province: "Guangdong", city: "Shenzhen" };
const { name, ...location } = userInfo;
console.log(name); // Crayon
console.log(location); // { province: 'Guangdong', city: 'Shenzhen' }
20.深拷贝与浅拷贝
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存(分支)。
- 浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。
- 如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。

深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象,是“值”而不是“引用”(不是分支)
-
拷贝第一层级的对象属性或数组元素
-
递归拷贝所有层级的对象属性和数组元素
-
深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。
-

实现方式
浅拷贝
Object.assign()
Object.assign() 方法可以把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象。
let obj1 = {
person:{
name:"xiaohe",
age:18
},
hobby:"run"
}
let obj2 = Object.assign({},obj1) // 浅拷贝
obj2.person.name = "xiaobai"; // 修改引用类型
obj2.hobby = "eat" // 修改基本类型
console.log(obj1)
console.log(obj2)
注意:当object只有一层的时候,是深拷贝

2.Array.prototype.concat()

修改新对象会改到原对象:

3.Array.prototype.slice()

同样修改新对象会改到原对象:
关于Array的slice和concat方法的补充说明:Array的slice和concat方法不修改原数组,只会返回一个浅复制了原数组中的元素的一个新数组。
原数组的元素会按照下述规则拷贝:
如果该元素是个对象引用(不是实际的对象),slice 会拷贝这个对象引用到新的数组里。两个对象引用都引用了同一个对象。如果被引用的对象发生改变,则新的和原来的数组中的这个元素也会发生改变。
对于字符串、数字及布尔值来说(不是 String、Number 或者 Boolean 对象),slice 会拷贝这些值到新的数组里。在别的数组里修改这些字符串或数字或是布尔值,将不会影响另一个数组。
可能这段话晦涩难懂,我们举个例子,将上面的例子小作修改:

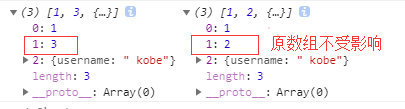
function shallowCopy (params) {
// 基本类型直接返回
if (!params || typeof params !== "object") return params;
// 根据 params 的类型判断是新建一个数组还是对象
let newObject = Array.isArray(params) ? [] : {};
// 遍历 params 并判断是 params 的属性才拷贝
for (let key in params) {
if (params.hasOwnProperty(key)) {
newObject[key] = params[key];
}
}
return newObject;
}
let params = { a: 1, b: { c: 1 } }
let newObj = shallowCopy(params)
// 拷贝对象中---基本类型老死不相往来,引用类型藕断丝连
params.a = 222
params.b.c = 666
console.log(params); // { a: 222, b: { c: 666 } }
console.log(newObj); // { a: 1, b: { c: 666 } }
深拷贝
JSON.parse(JSON.stringify())
let arr = [1, 3, {username: ' xiaohe'}];
let arr2 = JSON.parse(JSON.stringify(arr));
arr2[1] = 2;
arr2[2].username = 'xiaoming';
console.log(arr, arr2)
输出结果:
解析:这也是使用 JSON.stringify 将JS对象转成JSON字符串,再用JSON.parse把字符串解析成JS对象,一去一来,新的对象产生了,而且对象会开辟新的栈,实现深拷贝。
注意点:这种方法虽然可以实现数组或对象深拷贝,但不能处理函数和正则,因为这两者基于JSON.stringify和JSON.parse处理后,得到的正则就不再是正则(变为空对象),得到的函数就不再是函数(变为null)了。
示例代码:
let arr = [1, 3, {
username: 'xiaohe'
},function(){}];
let arr2 = JSON.parse(JSON.stringify(arr));
arr2[2].username = 'xiaobai';
console.log(arr, arr2)
你可以在控制台或者编辑器使用 console.dir 打印 arr(深拷贝后) 和 arr2(深拷贝前) 看一下。(这里我直接放图片的对比)
===>
递归
function deepClone(obj) {
if (typeof obj != 'object') return obj;
var temp = Array.isArray(obj) ? [] : {};
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
if (obj[key] && typeof obj[key] == 'object') { // 如果obj[key]还是对象则执行递归
temp[key] = deepClone(obj[key]); // 递归
} else {
temp[key] = obj[key];
}
}
}
return temp;
}
var obj = {
age: 13,
name: {
addr: '天边'
}
}
var obj2 = deepClone(obj);
obj2.age = 14
obj2.name.addr = '地心'
console.log(obj.age); //13
console.log(obj.name.addr); //天边
使用lodash库
lodash官方文档:www.lodashjs.com/docs/lodash…
使用方法如下:
(1)先引入lodash CDN
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"></script>
(2)调用_.cloneDeep() 方法,里面传入要拷贝的变量即可 。示例代码如下:
let info = {
name: 'xiaohe',
age: 18,
friend: {
name: 'xiaoming',
age: 19
}
}
let obj = _.cloneDeep(info);
info.friend.name = 'xiaobai'
console.log(info.friend.name) // 'xiaobai'
console.log(obj.friend.name) // 'xiaoming'
21 怎么判断元素是否进可视区域
判断一个元素是否在可视区域,我们常用的有三种办法:
- offsetTop、scrollTop
- getBoundingClientRect
- Intersection Observer
offsetTop、scrollTop
offsetTop,元素的上外边框至包含元素的上内边框之间的像素距离,其他offset属性如下图所示:

下面再来了解下clientWidth、clientHeight:
clientWidth:元素内容区宽度加上左右内边距宽度,即clientWidth = content + paddingclientHeight:元素内容区高度加上上下内边距高度,即clientHeight = content + padding
这里可以看到client元素都不包括外边距
最后,关于scroll系列的属性如下:
scrollWidth和scrollHeight主要用于确定元素内容的实际大小scrollLeft和scrollTop属性既可以确定元素当前滚动的状态,也可以设置元素的滚动位置-
- 垂直滚动
scrollTop > 0 - 水平滚动
scrollLeft > 0
- 垂直滚动
- 将元素的
scrollLeft和scrollTop设置为 0,可以重置元素的滚动位置
注意
- 上述属性都是只读的,每次访问都要重新开始
下面再看看如何实现判断:
公式如下:
el.offsetTop - document.documentElement.scrollTop <= viewPortHeight
代码实现:
function isInViewPortOfOne (el) {
// viewPortHeight 兼容所有浏览器写法
const viewPortHeight = window.innerHeight || document.documentElement.clientHeight || document.body.clientHeight
const offsetTop = el.offsetTop
const scrollTop = document.documentElement.scrollTop
const top = offsetTop - scrollTop
return top <= viewPortHeight
}
getBoundingClientRect
返回值是一个 DOMRect对象,拥有left, top, right, bottom, x, y, width, 和 height属性
const target = document.querySelector('.target');
const clientRect = target.getBoundingClientRect();
console.log(clientRect);
// {
// bottom: 556.21875,
// height: 393.59375,
// left: 333,
// right: 1017,
// top: 162.625,
// width: 684
// }
属性对应的关系图如下所示:
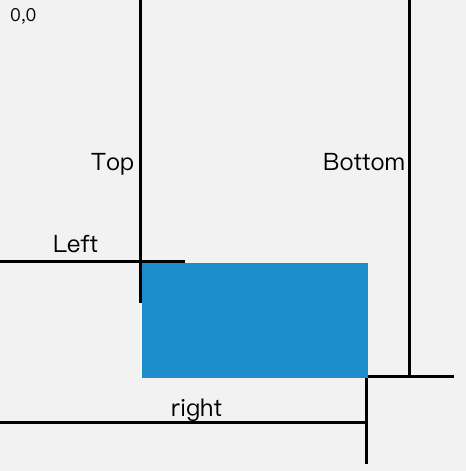
当页面发生滚动的时候,top与left属性值都会随之改变
如果一个元素在视窗之内的话,那么它一定满足下面四个条件:
- top 大于等于 0
- left 大于等于 0
- bottom 小于等于视窗高度
- right 小于等于视窗宽度
实现代码如下:
function isInViewPort(element) {
const viewWidth = window.innerWidth || document.documentElement.clientWidth;
const viewHeight = window.innerHeight || document.documentElement.clientHeight;
const {
top,
right,
bottom,
left,
} = element.getBoundingClientRect();
return (
top >= 0 &&
left >= 0 &&
right <= viewWidth &&
bottom <= viewHeight
);
}
Intersection Observer
Intersection Observer 即重叠观察者,从这个命名就可以看出它用于判断两个元素是否重叠,因为不用进行事件的监听,性能方面相比getBoundingClientRect会好很多
使用步骤主要分为两步:创建观察者和传入被观察者
创建观察者
const options = {
// 表示重叠面积占被观察者的比例,从 0 - 1 取值,
// 1 表示完全被包含
threshold: 1.0,
root:document.querySelector('#scrollArea') // 必须是目标元素的父级元素
};
const callback = (entries, observer) => { ....}
const observer = new IntersectionObserver(callback, options);
通过new IntersectionObserver创建了观察者 observer,传入的参数 callback 在重叠比例超过 threshold 时会被执行`
关于callback回调函数常用属性如下:
// 上段代码中被省略的 callback
const callback = function(entries, observer) {
entries.forEach(entry => {
entry.time; // 触发的时间
entry.rootBounds; // 根元素的位置矩形,这种情况下为视窗位置
entry.boundingClientRect; // 被观察者的位置举行
entry.intersectionRect; // 重叠区域的位置矩形
entry.intersectionRatio; // 重叠区域占被观察者面积的比例(被观察者不是矩形时也按照矩形计算)
entry.target; // 被观察者
});
};
传入被观察者
通过 observer.observe(target) 这一行代码即可简单的注册被观察者
const target = document.querySelector('.target');
observer.observe(target);
22.谈谈对promise的理解
Promise 是 JavaScript 中一种处理异步操作的机制,它用于更加可控和可维护地管理异步代码。Promise 提供了一种标准化的方式来处理异步任务,它可以表示一个异步操作的最终完成或失败,以及它的结果值。
以下是对 Promise 的核心概念和工作原理的理解:
- 状态 (State):
- Promise 可以处于三种状态之一:
pending(进行中)、fulfilled(已成功)或rejected(已失败)。 - 初始状态是
pending,然后可以转移到fulfilled或rejected状态,一旦进入其中一种状态,就不能再改变。
- Promise 可以处于三种状态之一:
- 值 (Value):
- 在状态为
fulfilled时,Promise 会包含一个表示成功结果的值。 - 在状态为
rejected时,Promise 会包含一个表示失败原因的值。
- 在状态为
- 回调函数 (Callbacks):
- 使用
then()方法来附加回调函数,分别处理成功和失败的情况。 then()接受两个参数,第一个是处理成功情况的回调,第二个是处理失败情况的回调。
- 使用
- 链式调用 (Chaining):
- Promise 支持链式调用,这意味着你可以按顺序附加多个
.then()来执行一系列异步操作。 - 这有助于避免回调地狱(Callback Hell)。
- Promise 支持链式调用,这意味着你可以按顺序附加多个
- 错误处理 (Error Handling):
- 使用
.catch()方法来捕获 Promise 链中任何地方发生的错误。 - 错误会沿着链传递,如果没有适当的处理,它们会一直传递到链的末尾。
- 使用
- 并行执行 (Parallel Execution):
- 使用
Promise.all()可以并行执行多个 Promise,只有当所有 Promise 都成功完成时,Promise.all()才会返回成功,否则返回第一个失败的 Promise。 - 使用
Promise.race()可以竞争多个 Promise,只要有一个 Promise 完成(无论成功或失败),Promise.race()就会返回相应的结果。 - 使用
Promise.any(), 区别于Promise.all(), Promise.any() 只要有一个成功,就返回成功的promise,如果没有一个成功,就返回一个失败的promise。
- 使用
- 异步操作 (Asynchronous Operations):
- Promise 通常用于处理异步操作,例如网络请求、文件读写、定时器等。
- 它们使得异步代码更具可读性和可维护性,因为它们以同步的方式编写,而不需要嵌套回调函数。
示例:
javascriptCopy codeconst fetchData = () => {
return new Promise((resolve, reject) => {
setTimeout(() => {
const randomNum = Math.random();
if (randomNum < 0.5) {
resolve('成功');
} else {
reject('失败');
}
}, 1000);
});
};
fetchData()
.then((result) => {
console.log('成功:', result);
})
.catch((error) => {
console.error('失败:', error);
});
上述示例演示了如何创建一个简单的 Promise,然后使用 .then() 处理成功情况和 .catch() 处理失败情况。这是 Promise 的基本使用方法,用于管理异步操作的流程和处理结果。
https://blog.csdn.net/yin_ping1101/article/details/124596019
23. async/await 的理解
async/await 是 JavaScript 中用于处理异步操作的一种语法糖,它使异步代码看起来更像同步代码,从而提高了代码的可读性和可维护性。async 声明一个异步函数,而 await 用于等待一个异步操作的完成。
下面是一些关于 async/await 的关键概念和理解:
-
异步函数:通过在函数前面加上
async关键字,你可以定义一个异步函数。异步函数内部可以包含await表达式,以等待异步操作的结果。async function fetchData() { // 异步操作 const data = await fetch('https://api.example.com/data'); return data.json(); } -
等待操作:使用
await关键字来等待一个异步操作的完成。在等待期间,JavaScript 引擎会继续执行其他任务,直到异步操作完成并返回结果。async function fetchData() { const response = await fetch('https://api.example.com/data'); const data = await response.json(); return data; } -
错误处理:你可以使用
try/catch块来捕获异步操作中的错误。如果异步操作抛出异常,它将被catch块捕获。async function fetchData() { try { const response = await fetch('https://api.example.com/data'); const data = await response.json(); return data; } catch (error) { console.error('发生错误:', error); } } -
返回 Promise:异步函数总是返回一个 Promise 对象。如果函数内部没有明确返回一个 Promise,它将隐式返回一个已解析的 Promise。
async function foo() { return 'Hello, World!'; } foo().then(result => { console.log(result); // 输出 'Hello, World!' }); -
并行执行:使用
await时,异步操作会按顺序执行,但如果你需要并行执行多个异步操作,可以使用Promise.all或其他并发控制方法。async function fetchMultiple() { const [data1, data2] = await Promise.all([ fetch('https://api.example.com/data1').then(response => response.json()), fetch('https://api.example.com/data2').then(response => response.json()) ]); return [data1, data2]; }
async/await 是一种非常强大的异步编程工具,可以简化异步代码的编写和理解。它适用于处理异步操作,如网络请求、文件读写、定时器等等,帮助开发者更容易地编写具有良好结构和错误处理的异步代码。
24 js原生节点操作
原生 JavaScript 提供了一系列用于节点(DOM元素)操作的方法,这些方法允许你创建、删除、修改和查询文档中的元素。以下是一些常见的原生 JavaScript 节点操作方法:
-
选择元素:获取文档中的元素节点。
document.getElementById(id):通过元素的 ID 获取一个元素。document.querySelector(selector):通过 CSS 选择器选择一个元素。document.querySelectorAll(selector):通过 CSS 选择器选择多个元素。
const elementById = document.getElementById('myElement'); const elementBySelector = document.querySelector('.myClass'); const elementsBySelectorAll = document.querySelectorAll('.myClass'); -
创建元素:创建新的元素节点。
document.createElement(tagName):创建一个新的元素节点。
javascriptCopy code const newElement = document.createElement('div'); -
插入元素:将元素插入到文档中的指定位置。
parentNode.appendChild(node):将一个元素添加到父节点的末尾。parentNode.insertBefore(newNode, referenceNode):在父节点的指定子节点前插入一个元素。
const parent = document.getElementById('parentElement'); const child = document.getElementById('childElement'); parent.appendChild(child); // 或者 parent.insertBefore(child, referenceNode); -
删除元素:从文档中移除元素。
node.parentNode.removeChild(node):从父节点中删除一个元素。
const elementToRemove = document.getElementById('elementToRemove'); elementToRemove.parentNode.removeChild(elementToRemove); -
替换元素:用一个新元素替换已有的元素。
parentNode.replaceChild(newNode, oldNode):用新元素替换旧元素。
const parent = document.getElementById('parentElement'); const newElement = document.createElement('div'); const oldElement = document.getElementById('oldElement'); parent.replaceChild(newElement, oldElement); -
修改元素:修改元素的属性和内容。
element.setAttribute(name, value):设置元素的属性。element.innerHTML:获取或设置元素的 HTML 内容。element.textContent:获取或设置元素的文本内容。
const element = document.getElementById('myElement'); element.setAttribute('class', 'newClass'); element.innerHTML = '<p>New content</p>'; element.textContent = 'New text content'; -
遍历节点:遍历文档中的节点。
node.childNodes:获取元素的子节点列表。node.firstChild和node.lastChild:获取第一个和最后一个子节点。node.nextSibling和node.previousSibling:获取相邻的节点。
const parent = document.getElementById('parentElement'); const firstChild = parent.firstChild; const nextSibling = firstChild.nextSibling;
这些是一些常见的原生 JavaScript 节点操作方法,它们允许你创建、删除、修改和查询文档中的元素,从而实现对页面内容的动态操作。
25.前端怎么实现跨域
- CORS
CORS 通信过程都是浏览器自动完成,需要浏览器(都支持)和服务器都支持,所以关键在只要服务器支持,就可以跨域通信,CORS请求分两类,简单请求和非简单请求
另外CORS请求默认不包含Cookie以及HTTP认证信息,如果需要包含Cookie,需要满足几个条件:
- 服务器指定了
Access-Control-Allow-Credentials: true - 开发者须在请求中打开withCredentials属性:
xhr.withCredentials = true Access-Control-Allow-Origin不要设为星号,指定明确的与请求网页一致的域名,这样就不会把其他域名的Cookie上传
简单请求
需要同时满足两个条件,就属于简单请求:
- 请求方法是:
HEAD、GET、POST,三者之一 - 请求头信息不超过以下几个字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-Id
- Content-Type:值为三者之一application/x-www/form/urlencoded、multipart/form-data、text/plain
需要这些条件是为了兼容表单,因为历史上表单一直可以跨域
浏览器直接发出CORS请求,具体来说就是在头信息中增加Origin字段,表示请求来源来自哪个域(协议+域名+端口),服务器根据这个值决定是否同意请求。如果同意,返回的响应会多出以下响应头信息
Access-Control-Allow-Origin: http://juejin.com // 和 Orign 一致 这个字段是必须的
Access-Control-Allow-Credentials: true // 表示是否允许发送 Cookie 这个字段是可选的
Access-Control-Expose-Headers: FooBar // 指定返回其他字段的值 这个字段是可选的
Content-Type: text/html; charset=utf-8 // 表示文档类型
在简单请求中服务器至少需要设置:Access-Control-Allow-Origin 字段
非简单请求
比如 PUT 或 DELETE 请求,或 Content-Type 为 application/json ,就是非简单请求。
非简单 CORS 请求,正式请求前会发一次 OPTIONS 类型的查询请求,称为预检请求,询问服务器是否支持网页所在域名的请求,以及可以使用哪些头信息字段。只有收到肯定的答复,才会发起正式XMLHttpRequest请求,否则报错
预检请求的方法是OPTIONS,它的头信息中有几个字段
- Origin: 表示请求来自哪个域,这个字段是必须的
- Access-Control-Request-Method:列出CORS请求会用到哪些HTTP方法,这个字段是必须的
- Access-Control-Request-Headers: 指定CORS请求会额外发送的头信息字段,用逗号隔开
OPTIONS请求次数过多也会损耗性能,所以要尽量减少OPTIONS请求,可以让服务器在请求返回头部添加
Access-Control-Max-Age: Number // 数字 单位是秒
表示预检请求的返回结果可以被缓存多久,在这个时间范围内再请求就不需要预检了。不过这个缓存只对完全一样的URL才会生效
- Nginx代理跨域
配置一个代理服务器向服务器请求,再将数据返回给客户端,实质和CORS跨域原理一样,需要配置请求响应头Access-Control-Allow-Origin等字段
1server {
listen 81; server_name www.domain1.com;
location / {
proxy_pass http://xxxx1:8080; // 反向代理
proxy_cookie_domain www.xxxx1.com www.xxxx2.com; // 修改cookie里域名
index index.html index.htm;
// 当用webpack-dev-server等中间件代理接口访问nignx时,此时无浏览器参与,故没有同源限制,下面的跨域配置可不启用
add_header Access-Control-Allow-Origin http://www.xxxx2.com; // 当前端只跨域不带cookie时,可为*
add_header Access-Control-Allow-Credentials true;
}
}
- Node中间件代理跨域
在 Vue 中 vue.config.js 中配置
module.export = {
...
devServer: {
proxy: {
[ process.env.VUE_APP_BASE_API ]: {
target: \'http://xxxx\',//代理跨域目标接口
ws: true,
changeOrigin: true,
pathRewrite: {
[ \'^\' + process.env.VUE_APP_BASE_API ] : \'\'
}
}
}
}
}
Node + express
const express = require(\'express\')
const proxy = require(\'http-proxy-middleware\')
const app = express()
app.use(\'/\', proxy({
// 代理跨域目标接口
target: \'http://xxxx:8080\',
changeOrigin: true,
// 修改响应头信息,实现跨域并允许带cookie
onProxyRes: function(proxyRes, req, res) {
res.header(\'Access-Control-Allow-Origin\', \'http://xxxx\')
res.header(\'Access-Control-Allow-Credentials\', \'true\')
},
// 修改响应信息中的cookie域名
cookieDomainRewrite: \'www.domain1.com\' // 可以为false,表示不修改
}));
app.listen(3000);
- WebSocket
WebSocket是HTML5标准中的一种通信协议,以ws://(非加密)和wss://(加密)作为协议前缀,该协议不实行同源政策,只要服务器支持就行
因为WebSocket请求头信息中有Origin字段,表示请求源来自哪个域,服务器可以根据这个字段判断是否允许本次通信,如果在白名单内,就可以通信
- postMessage
postMessage是HTML5标准中的API,它可以给我们解决如下问题:
- 页面和新打开的窗口间数据传递
- 多窗口之间数据传递
- 页面与嵌套的 iframe 之间数据传递
- 上面三个场景之间的
跨域传递
postMessage 接受两个参数,用法如下:
- 参数一:发送的数据
- 参数二:你要发送给谁就写谁的地址
(协议 + 域名 +端口),也可以设置为*,表示任意窗口,为/表示与当前窗口同源的窗口
- JSONP
原理就是通过添加一个标签,向服务器请求JSON数据,这样不受同源政策限制。服务器收到请求后,将数据放在一个callback回调函数中传回来。比如axios。
不过只支持GET请求且不安全,可能遇到XSS攻击,不过它的好处是可以向老浏览器或不支持CORS的网站请求数据
let script = document.createElement('script')
script.type = 'text/javascript'
script.src = 'http://juejin.com/xxx?callback=handleCallback'
document.body.appendChild(script)
function handleCallback(res){
console.log(res)
}
服务器返回并立即执行
handleCallback({ code: 200, msg: 'success', data: [] })
26jsonp的实现原理
JSONP(JSON with Padding)是一种利用浏览器的脚本标签(<script>)来进行跨域请求的技术。JSONP 的实现原理涉及以下几个步骤:
-
前端发起请求:前端页面通过创建一个
<script>标签来请求包含 JSON 数据的资源,这个资源通常位于另一个域名下。在请求中,前端会指定一个回调函数的名称,例如callback=processData。<script src="https://api.example.com/data?callback=processData"></script> -
服务器响应:服务器接收到请求后,会将数据包装在回调函数中,并返回给前端。响应的内容通常会是一个 JavaScript 脚本,其中包含了回调函数的调用以及数据作为参数传递给回调函数。
processData({ "name": "John", "age": 30 }); -
前端处理数据:前端页面中事先定义了
processData回调函数,该函数会在脚本加载并执行时被调用,接收到数据作为参数。前端页面可以在该回调函数内处理数据。function processData(data) { // 处理接收到的数据 console.log(data.name); // 输出 "John" }
要注意 JSONP 的一些重要特点和限制:
- JSONP 只支持 GET 请求,因为它是通过
<script>标签发起的。 - JSONP 不支持像 CORS 那样的自定义请求头。
- 安全风险:JSONP 存在安全风险,因为它要求前端信任目标域名提供的回调函数,可能会被滥用来执行恶意代码。
- JSONP 不是一种现代的跨域请求解决方案,CORS 更安全、更灵活,推荐使用 CORS 来处理跨域请求。
由于 JSONP 的安全风险,现代前端开发通常更倾向于使用 CORS 或其他跨域通信方式来处理跨域请求。 JSONP 通常仅在特殊情况下或与不支持 CORS 的老旧系统一起使用。
27.Generator的理解
JavaScript 中的 Generator 是一种特殊的函数,它可以被暂停和恢复,并且允许你多次从函数中生成值。Generator 通过使用 function* 声明来创建,并包含一个或多个 yield 语句,用于产生值。
以下是对 JavaScript Generator 的一些关键概念和理解:
-
生成器函数声明:生成器函数通过使用
function*关键字声明。它可以包含一个或多个yield语句,这些语句用于产生值。function* myGenerator() { yield 1; yield 2; yield 3; } -
生成器对象:当你调用生成器函数时,它不会立即执行,而是返回一个生成器对象。生成器对象具有一个
next()方法,用于启动生成器函数的执行并获取生成的值。const gen = myGenerator(); console.log(gen.next()); // { value: 1, done: false } console.log(gen.next()); // { value: 2, done: false } console.log(gen.next()); // { value: 3, done: false } console.log(gen.next()); // { value: undefined, done: true }next()方法返回一个对象,其中value包含生成的值,而done表示生成器函数是否已经执行完成。 -
暂停和恢复:生成器函数的执行可以在
yield语句处暂停,然后可以通过next()方法恢复执行。这使得你可以逐步生成值,而不必一次性生成所有值。 -
无限序列:生成器可以用于生成无限序列,因为它们可以无限次调用
yield语句。function* infiniteSequence() { let i = 0; while (true) { yield i++; } } -
Generator 中的返回值:你可以在生成器函数内使用
return语句来结束生成器的执行,并返回一个特定的值。这将导致生成器对象的done属性变为true。function* myGenerator() { yield 1; yield 2; return 3; } const gen = myGenerator(); console.log(gen.next()); // { value: 1, done: false } console.log(gen.next()); // { value: 2, done: false } console.log(gen.next()); // { value: 3, done: true } -
Generator 的应用:Generators 可以用于异步编程,例如在处理异步操作时,让代码看起来更同步化。它们还用于迭代大量数据,以及创建可中断的任务。
-
for...of循环:可以使用for...of循环来遍历生成器生成的值,它会自动迭代生成器并获取每个值。function* myGenerator() { yield 1; yield 2; yield 3; } for (const value of myGenerator()) { console.log(value); }
总的来说,JavaScript 的 Generator 是一种强大的功能,它允许你创建可暂停和恢复的函数,用于生成值的迭代和异步操作,使代码更加可读和易于管理。Generators 在处理异步操作和复杂的控制流时非常有用
JavaScript Generators 在实际开发中有多种应用场景,它们主要用于处理异步操作和控制流,以及简化一些复杂的任务。以下是一些常见的使用场景:
-
异步操作管理:Generators 可以简化异步代码的编写和维护,使其看起来更像同步代码。通过
yield语句,你可以将异步操作的步骤分解成可读的同步形式,而不需要嵌套的回调函数。function* fetchData() { try { const data1 = yield fetch('https://api.example.com/data1'); const data2 = yield fetch('https://api.example.com/data2'); // 处理数据 } catch (error) { // 处理错误 } } -
迭代大数据集合:Generators 可以用于逐个生成大型数据集合的值,而不必一次性将其全部加载到内存中。这对于处理大型日志文件、数据库查询结果等很有用。
function* dataGenerator(data) { for (const item of data) { yield item; } } -
可中断的任务:你可以使用 Generators 创建可中断的任务,当需要停止任务时,只需调用生成器对象的
return()方法。function* longRunningTask() { try { while (true) { // 执行任务 yield; } } finally { // 清理任务 } } const task = longRunningTask(); // 中断任务 task.return();
28.ajax的实现原理
实现 Ajax 异步交互需要服务器逻辑进行配合,需要完成以下步骤:
- 创建
Ajax的核心对象XMLHttpRequest对象 - 通过
XMLHttpRequest对象的open()方法与服务端建立连接 - 构建请求所需的数据内容,并通过
XMLHttpRequest对象的send()方法发送给服务器端 - 通过
XMLHttpRequest对象提供的onreadystatechange事件监听服务器端你的通信状态 - 接受并处理服务端向客户端响应的数据结果,通过
xhr.responseText来获取服务器返回的数据。 - 将处理结果更新到
HTML页面中
创建XMLHttpRequest对象
通过XMLHttpRequest() 构造函数用于初始化一个 XMLHttpRequest 实例对象
const xhr = new XMLHttpRequest();
与服务器建立连接
通过 XMLHttpRequest 对象的 open() 方法与服务器建立连接
xhr.open(method, url, [async][, user][, password])
参数说明:
method:表示当前的请求方式,常见的有GET、POSTurl:服务端地址async:布尔值,表示是否异步执行操作,默认为trueuser: 可选的用户名用于认证用途;默认为`nullpassword: 可选的密码用于认证用途,默认为`null
给服务端发送数据
通过 XMLHttpRequest 对象的 send() 方法,将客户端页面的数据发送给服务端
xhr.send([body])
body`: 在 `XHR` 请求中要发送的数据体,如果不传递数据则为 `null
如果使用GET请求发送数据的时候,需要注意如下:
- 将请求数据添加到
open()方法中的url地址中 - 发送请求数据中的
send()方法中参数设置为null
绑定onreadystatechange事件
onreadystatechange 事件用于监听服务器端的通信状态,主要监听的属性为XMLHttpRequest.readyState ,
关于XMLHttpRequest.readyState属性有五个状态,如下图显示
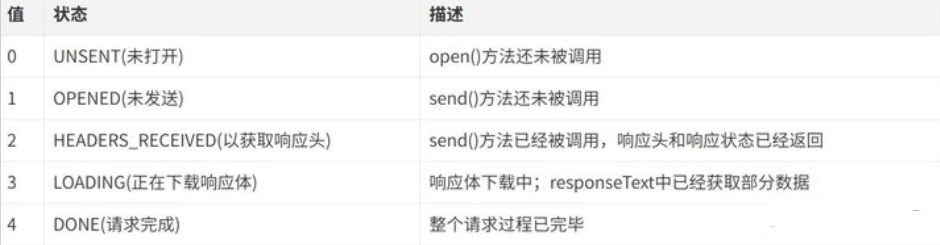
预览
只要 readyState 属性值一变化,就会触发一次 readystatechange 事件
XMLHttpRequest.responseText属性用于接收服务器端的响应结果
举个例子:
const request = new XMLHttpRequest()
request.onreadystatechange = function(e){
if(request.readyState === 4){ // 整个请求过程完毕
if(request.status >= 200 && request.status <= 300){
console.log(request.responseText) // 服务端返回的结果
}else if(request.status >=400){
console.log("错误信息:" + request.status)
}
}
}
request.open('POST','http://xxxx')
request.send()
三、封装
通过上面对XMLHttpRequest 对象的了解,下面来封装一个简单的ajax请求
//封装一个ajax请求
function ajax(options) {
//创建XMLHttpRequest对象
const xhr = new XMLHttpRequest()
//初始化参数的内容
options = options || {}
options.type = (options.type || 'GET').toUpperCase()
options.dataType = options.dataType || 'json'
const params = options.data
//发送请求
if (options.type === 'GET') {
xhr.open('GET', options.url + '?' + params, true)
xhr.send(null)
} else if (options.type === 'POST') {
xhr.open('POST', options.url, true)
xhr.send(params)
//接收请求
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
let status = xhr.status
if (status >= 200 && status < 300) {
options.success && options.success(xhr.responseText, xhr.responseXML)
} else {
options.fail && options.fail(status)
}
}
}
}
使用方式如下
ajax({
type: 'post',
dataType: 'json',
data: {},
url: 'https://xxxx',
success: function(text,xml){//请求成功后的回调函数
console.log(text)
},
fail: function(status){////请求失败后的回调函数
console.log(status)
}
})
29 说说你对事件循环的理解
事件循环(Event Loop)是 JavaScript 运行时环境中的一个重要概念,它负责管理和协调异步操作、事件处理和代码执行。当面试官问你关于事件循环的问题时,你可以这样回答:
事件循环是 JavaScript 运行时环境的核心组成部分,用于处理异步任务和事件驱动的操作。它的工作方式可以概括为以下几个步骤:
- 执行同步任务:首先,JavaScript 引擎会执行当前调用栈中的同步任务,这些任务是按照它们在代码中的顺序依次执行的。
- 处理消息队列:在执行同步任务期间,如果有异步任务完成(如定时器到期、HTTP 请求完成、事件触发等),它们会被添加到消息队列(Message Queue)中,等待进一步处理。
- 事件循环:一旦当前调用栈中的同步任务执行完毕,JavaScript 引擎会检查消息队列是否有待处理的任务。如果有,它会从队列中取出一个任务,并将其执行(进入调用栈)。这个过程重复进行,形成了一个循环,被称为事件循环。
- 执行异步任务:异步任务可以包括宏任务(如定时器、IO 操作、HTTP 请求)和微任务(Promise 的
then回调、async/await的await表达式)。宏任务通常比微任务优先级更低,因此宏任务会在微任务之后执行。 - 微任务队列:微任务队列用于存放需要在当前事件循环中尽快执行的任务,这些任务会在宏任务执行完毕之后立即执行,确保了优先级较高的任务能够迅速处理。
总的来说,事件循环使得 JavaScript 能够在单线程环境中处理异步操作,而不会阻塞整个应用程序的执行。它的核心思想是通过不断地轮询消息队列,检查是否有待处理的任务,然后依次执行它们。这种机制保证了 JavaScript 的异步性和非阻塞特性。
在面试中,你可以进一步展开讨论事件循环的细节,如宏任务和微任务的执行顺序、Promise 的角色、setTimeout 和 setInterval 的工作方式以及 requestAnimationFrame 的应用等。这将展示你对 JavaScript 异步编程模型的深刻理解。
30.宏任务和微任务
下面是一些常见的宏任务和微任务的例子:
宏任务(Macrotasks):
- setTimeout 和 setInterval:通过
setTimeout和setInterval创建的回调函数将被添加到宏任务队列中,它们会在一定的延迟之后执行。 - DOM事件:用户交互事件,例如点击、鼠标移动、键盘输入等,都触发宏任务。
- Ajax请求:通过
XMLHttpRequest或fetch发起的网络请求的回调函数也是宏任务。 - I/O操作:文件读写、数据库查询等 I/O 操作通常会被添加到宏任务队列中。
- requestAnimationFrame:用于执行动画的
requestAnimationFrame方法也会创建宏任务。 - MessageChannel:使用
MessageChannelAPI 创建的消息通道也可以用于创建宏任务。
微任务(Microtasks):
- Promise:
Promise的then和catch方法的回调函数会被添加到微任务队列中。这使得 Promise 非常适合处理异步操作。 - process.nextTick(Node.js环境):
process.nextTick方法会将回调函数添加到微任务队列中,它在 Node.js 环境中使用较多。 - MutationObserver:
MutationObserver的回调函数用于监视 DOM 变化,并且也是微任务。 - queueMicrotask:
queueMicrotask函数可以用于将回调函数添加到微任务队列。 - Object.observe(已弃用):虽然已经弃用,但
Object.observe也是一个创建微任务的机制。 - React的setState回调:在 React 中,通过
setState的回调函数也是微任务,用于处理状态更新后的操作。 - Vue的nextTick:在 Vue.js 中,
nextTick方法也创建了微任务,用于处理DOM更新后的操作。
微任务具有高优先级,它们会在宏任务队列执行完毕之前立即执行。这使得微任务非常适合处理需要尽快完成的异步操作,如更新UI、处理Promise的结果等。它们在代码执行的"微观"层面上提供了更精细的控制。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构