
hadoop集群规划
目标:创建2个NameNode,做高可用,一个NameNode挂掉,另一个能够启动;一个运行Yarn,3台DataNode,3台Zookeeper集群,做高可用。
在
hadoop2中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active
NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active
namenode的状态,以便能够在它失败时快速进行切换。
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态
安装我都把hadoop和Zookeeper放到了/soft/下面;

0、系统环境安装
操作系统CentOS6.5,64位操作系统,采用最小化安装,为了能够实现目标,采用VMware 虚拟机来搭建6台服务器,所以建议服务器至少有8G内存;vmware使用的是VMware® Workstation 11.0.0 build-2305329;
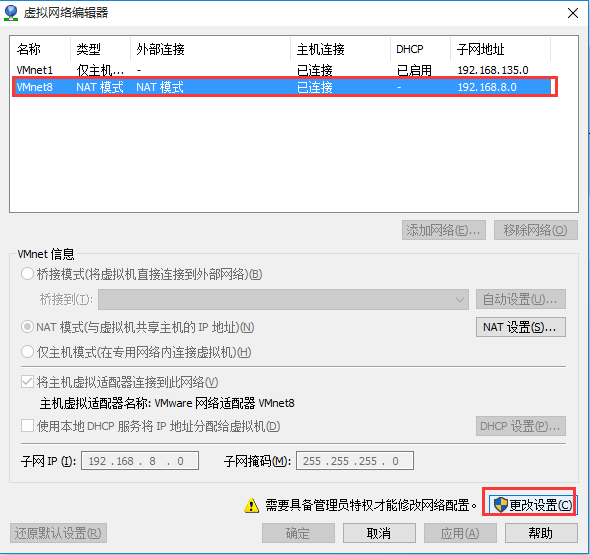
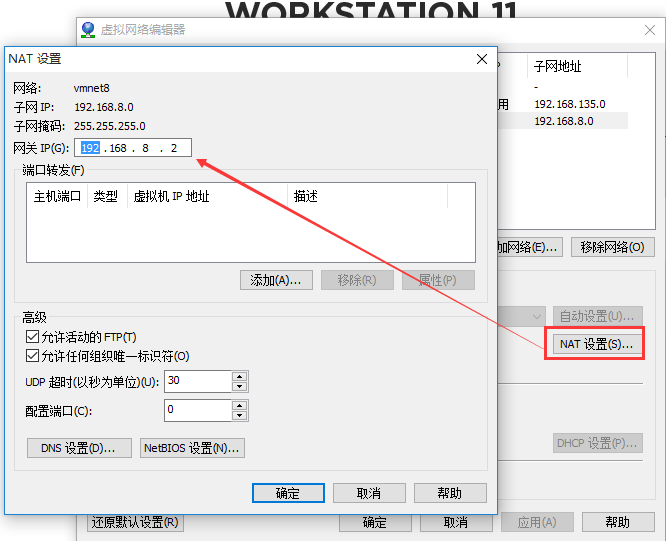
网络配置如下:

虚拟机配置如下:
1、同步机器时间
yum install -y ntp #安装时间服务ntpdate us.pool.ntp.org #同步时间
2、设置主机IP
vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0IPADDR=192.168.8.101NETMASK=255.255.255.0GATEWAY=192.168.8.2HWADDR=00:0C:29:56:63:A1TYPE=EthernetUUID=ecb7f947-8a93-488c-a118-ffb011421cacONBOOT=yesNM_CONTROLLED=yesBOOTPROTO=none
然后重启网络服务
service network restart
查看ip配置
ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:0C:29:6C:20:2Binet addr:192.168.8.101 Bcast:192.168.8.255 Mask:255.255.255.0inet6 addr: fe80::20c:29ff:fe6c:202b/64 Scope:LinkUP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1RX packets:777 errors:0 dropped:0 overruns:0 frame:0TX packets:316 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:1000RX bytes:70611 (68.9 KiB) TX bytes:49955 (48.7 KiB)
这就说明我们配置的IP地址是成功的
注意:
使用vmware克隆了5台虚拟机,配置网卡的时候出现报错:”Bring up interface eth0:Device eth0 does not seem to be present,delaying initialization”
解决步骤:
第一步 删除文件70-persistent-net.rules
rm -f /etc/udev/rules.d/70-persistent-net.rule
第二步 修改ifcfg-eth0
vim /etc/sysconfig/network-scripts/ifcfg-eth0
删除或者注释MAC地址的配置
第三步:重启服务器
reboot
这样就可以设置新的ip地址了
3、设置主机名
把一台主机的名称改为:hadoop01
vi /etc/sysconfig/network
修改hostname就可以了:
NETWORKING=yesHOSTNAME=hadoop01NETWORKING_IPV6=no
要修改hosts
vi /etc/hosts
127.0.0.1 localhost192.168.8.101 hadoop01 192.168.8.102 hadoop02 192.168.8.103 hadoop03 192.168.8.104 hadoop04 192.168.8.105 hadoop05 192.168.8.106 hadoop06
关闭ipv6
1、查看系统是否开启ipv6
a)通过网卡属性查看
命令:ifconfig
注释:有 “inet6 addr:。。。。。。。“ 的表示开启了ipv6功能
b)通过内核模块加载信息查看
命令:lsmod | grep ipv6
2、ipv6关闭方法
在/etc/modprobe.d/dist.conf结尾添加
alias net-pf-10 offalias ipv6 off
可用vi等编辑器,也可以通过命令:
cat <<EOF>>/etc/modprobe.d/dist.conf
alias net-pf-10 off
alias ipv6 off
EOF
关闭防火墙
chkconfig iptables stopchkconfig iptables off
改好后重启服务器:
reboot
hadoop02-hadoop06都需要设置
4、安装JDK
将压缩包解压到指定目录,然后编辑环境变量
vi /etc/proflie
在文件后面追加环境变量
export JAVA_HOME=/soft/jdk1.7.0_80/export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
刷新
source /etc/profile
可以用java -version测试安装是否正确
5、SSH免密码登录
对于需要远程管理其它机器,一般使用远程桌面或者telnet。linux一般只能是telnet。但是telnet的缺点是通信不加密,存在不安全因素,只适合内网访问。为
解决这个问题,推出了通信加密通信协议,即SSH(Secure Shell)。使用非对称加密方式,传输内容使用rsa或者dsa加密,可以避免网络窃听。
hadoop的进程之间同信使用ssh方式,需要每次都要输入密码。为了实现自动化操作,需要配置ssh免密码登陆方式。
hadoop01\hadoop02做为NameNode,要访问到其他的节点,我们要在hadoop01可以访问到hadoop01-hadoop06(记住hadoop01也需要免登陆自己),hadoop02可以访问到hadoop01,hadoop03是yarn服务,要可以访问到datanode,所以hadoop03要免登陆到hadoop04-hadoop06;
首先要在hadoop01上生成ssh私钥和公钥
cd /root/.sshssh-keygen -t rsa #4个回车
上面的命令会在.ssh目录生成一个私钥和一个公钥
id_rsa id_rsa.pub
然后将hadoop01的公钥复制到hadoop02-hadoop06,用以下命令执行
ssh-copy-id -i hadoop01ssh-copy-id -i hadoop02ssh-copy-id -i hadoop03ssh-copy-id -i hadoop04ssh-copy-id -i hadoop05ssh-copy-id -i hadoop06
上面的命令一行一行执行,先输入yes,再输入机器的密码就可以了;
现在我们来检验以一下hadoop01到hadoop05的免登陆
我们在hadoop01中无密码登录hadoop05输入:
[root@hadoop01 .ssh]# ssh hadoop05Last login: Tue Nov 10 17:43:41 2015 from 192.168.8.1[root@hadoop05 ~]#
可以看到已经可以从hadoop01到hadoop05免登陆了;输入exit退出
接下来设置hadoop02到hadoop01的免登陆
在hadoop02的/root/.ssh中执行
ssh-keygen -t rsa #4个回车
ssh-copy-id -i hadoop01
如果出现以上信息就表示配置成功了。用exit退出;
那现在就很方便了,不用打开多个ssh,用一个就全搞定了;也可以配置一个hadoop用户,我现在都是使用root用户。
同里也要配置hadoop03到hadoop04-hadoop06的免登陆,这里就不列出了。
6、安装zookeeper
要将zookeeper集群部署到hadoop04、hadoop05、hadoop06上,先来设置hadoop04,操作如下
解压zookeeper到指定目录
tar -zxvf zookeeper-3.4.6.tar.gz -C /root/soft
切换到zookeeper目录的conf目录,修改zoo.sample.cfg为zoo.cfg
mv zoo.sample.cfg zoo.cfg
配置zoo.cfg
vi zoo.cfg
[root@hadoop04 conf]# vi zoo.cfg# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial# synchronization phase can takeinitLimit=10# The number of ticks that can pass between# sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just# example sakes.dataDir=/soft/zookeeper-3.4.6/data# the port at which the clients will connectclientPort=2181# the maximum number of client connections.# increase this if you need to handle more clients#maxClientCnxns=60## Be sure to read the maintenance section of the# administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1server.1=192.168.8.104:2888:3888server.2=192.168.8.105:2888:3888server.3=192.168.8.106:2888:3888
保存zoo.cfg
server.1=192.168.8.104:2888:3888
2888是通信端口,3888是zookeeper选举端口,这里用ip也可以,用主机名也可以。
注意配置文件中的datadir
dataDir=/soft/zookeeper-3.4.6/data
这个目录要真实存在才可以;
接下来要在/soft/zookeeper-3.4.6/data目录中增加一个文件"myid"
vi myid
文件里面写入1,然后保存,这表示是server.1;
好了,这样就配置好了,将配置好的拷贝到hadoop05、hadoop06,注意要修改data目录中myid的内容为响应的2和3
启动hadoop04、hadoop05、hadoop06的zookeeper服务
zookeeper-3.4.6目录执行以下命令
bin/zkServer.sh start #启动bin/zkServer.sh status #查看状态
hadoop04的结果:
[root@hadoop04 zookeeper-3.4.6]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /soft/zookeeper-3.4.6/bin/../conf/zoo.cfgMode: leader
hadoop05的结果:
[root@hadoop05 zookeeper-3.4.6]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /soft/zookeeper-3.4.6/bin/../conf/zoo.cfgMode: follower
hadoop06的结果:
[root@hadoop06 zookeeper-3.4.6]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /soft/zookeeper-3.4.6/bin/../conf/zoo.cfgMode: follower
接下来测试以下zookeeper集群,在hadoop04上关闭zookeeper
bin/zkServer.sh stop
hadoop04的结果:
[root@hadoop04 zookeeper-3.4.6]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /soft/zookeeper-3.4.6/bin/../conf/zoo.cfgError contacting service. It is probably not running.[root@hadoop04 zookeeper-3.4.6]#
hadoop05的结果:
[root@hadoop05 zookeeper-3.4.6]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /soft/zookeeper-3.4.6/bin/../conf/zoo.cfgMode: follower
hadoop06的结果:
[root@hadoop06 zookeeper-3.4.6]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /soft/zookeeper-3.4.6/bin/../conf/zoo.cfgMode: leader
从上面结果可以看出,zookeeper集群是没有问题的,hadoop04挂掉,hadoop06就变成了leader,这说明zookeeper集群已经部署好了。
7、hadoop安装
现在hadoop01上面配置好,然后再拷贝到其他机器上;
先解压hadoop-2.7.1.tar.gz到soft,查看hadoop目录文件如下:
[root@hadoop01 hadoop-2.7.1]# lsbin etc include journal lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share
所有的配置文件都存放在etc/hadoop/文件夹里面
7.1、添加hadoop目录到环境变量
在/etc/profile文件中增加HADOOP_HOME,如下所示
export JAVA_HOME=/soft/jdk1.7.0_80/export HADOOP_HOME=/soft/hadoop-2.7.1export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
应用环境变量
source /etc/profile
可以用方法测试是否正确
[root@hadoop01 hadoop-2.7.1]# which hadoop/soft/hadoop-2.7.1/bin/hadoop
7.2、配置hadoop-env.sh
vim hadoop-env.sh
修改一个地方就可以,找到JAVA_HOME,改成第4章中jdk的路径就可以了
export JAVA_HOME=/soft/jdk1.7.0_80/
保存即可。
7.3、配置core-site.xml
这一步是配置nameservice,hadoop 文件存储位置和Zookeeper集群来确保多个namenode之间的切换,修改后内容如下:
<configuration><!-- 指定hdfs的nameservice为ns1 --><property><name>fs.defaultFS</name><value>hdfs://ns1</value></property><!-- 指定hadoop临时目录 --><property><name>hadoop.tmp.dir</name><value>/soft/hadoop-2.7.1/tmp</value></property><!-- 指定zookeeper地址 --><property><name>ha.zookeeper.quorum</name><value>hadoop04:2181,hadoop05:2181,hadoop06:2181</value></property></configuration>
7.4、配置hdfs-site.xml
hdfs-site.xml主要配置namenode的高可用;
内容如下:
<configuration><!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 --><property><name>dfs.nameservices</name><value>ns1</value></property><!-- ns1下面有两个NameNode,分别是nn1,nn2 --><property><name>dfs.ha.namenodes.ns1</name><value>nn1,nn2</value></property><!-- nn1的RPC通信地址 --><property><name>dfs.namenode.rpc-address.ns1.nn1</name><value>hadoop01:9000</value></property><!-- nn1的http通信地址 --><property><name>dfs.namenode.http-address.ns1.nn1</name><value>hadoop01:50070</value></property><!-- nn2的RPC通信地址 --><property><name>dfs.namenode.rpc-address.ns1.nn2</name><value>hadoop02:9000</value></property><!-- nn2的http通信地址 --><property><name>dfs.namenode.http-address.ns1.nn2</name><value>hadoop02:50070</value></property><!-- 指定NameNode的元数据在JournalNode上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop04:8485;hadoop05:8485;hadoop06:8485/ns1</value></property><!-- 指定JournalNode在本地磁盘存放数据的位置 --><property><name>dfs.journalnode.edits.dir</name><value>/soft/hadoop-2.7.1/journal</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置失败自动切换实现方式 --><property><name>dfs.client.failover.proxy.provider.ns1</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 使用隔离机制时需要ssh免登陆 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property></configuration>
保存即可。
7.4、配置datanode的配置文件slaves
vi slaves
修改datanode节点如下:
hadoop04hadoop05hadoop06
保存即可。
7.5、配置mapreduce文件mapred-site.xml
默认是没有mapred-site.xml文件的,里面有一个mapred-site.xml.example,重命名为mapred-site.xml
mv mapred-site.xml.example mapred-site.xml
配置内容如下,这里就是指明mapreduce是用在YARN之上来执行的。
<configuration><!-- 指定mr框架为yarn方式 --><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
7.6、配置yarn-site.xml
做规划的时候就是配置hadoop03来运行yarn,配置如下:
<configuration><!-- 指定resourcemanager地址 --><property><name>yarn.resourcemanager.hostname</name><value>hadoop03</value></property><!-- 指定nodemanager启动时加载server的方式为shuffle server --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
到目前为止就已经配置好hadoop01了,要将配置好的hadoop文件拷贝到hadoop02-hadoop06上,cd到soft目录
scp -r hadoop2.7.1 hadoop02:/soft/scp -r hadoop2.7.1 hadoop03:/soft/scp -r hadoop2.7.1 hadoop04:/soft/scp -r hadoop2.7.1 hadoop05:/soft/scp -r hadoop2.7.1 hadoop06:/soft/
7.7、启动Zookeeper服务
在hadoop04、hadoop05、hadoop06上启动Zookeeper,下面以hadoop04为例
[root@hadoop04 zookeeper-3.4.6]# bin/zkServer.sh startJMX enabled by defaultUsing config: /soft/zookeeper-3.4.6/bin/../conf/zoo.cfgStarting zookeeper ... STARTED
确保这三台服务器上有一个leader,两个follower
7.8、在hadoop01上启动journalnode
[root@hadoop01 hadoop-2.7.1]# sbin/hadoop-daemons.sh start journalnode
在7.4中配置了journalnode的节点是hadoop04、hadoop05、hadoop06,这三台机器上会出现JournalNode,以下是hadoop04上的进程
[root@hadoop04 zookeeper-3.4.6]# jps1532 JournalNode1796 Jps1470 QuorumPeerMain
7.9、在hadoop01上格式化hadoop
hadoop namenode -format
格式化后会在根据7.3中core-site.xml中的hadoop.tmp.dir配置生成个文件,在hadoop01中会出现一个tmp文件夹,/soft/hadoop-2.7.1/tmp,现在规划的是hadoop01和hadoop02是NameNode,然后将/soft/hadoop-2.7.1/tmp拷贝到hadoop02:/soft/hadoop-2.7.1/下,这样hadoop02就不用格式化了。
scp -r tmp/ hadoop02:/soft/hadoop-2.7.1/
7.10、在hadoop01上格式化ZK
hdfs zkfc -formatZK
7.11、在hadoop01上 启动HDFS
sbin/start-dfs.sh
7.12 在hadoop01上启动YARN
sbin/start-yarn.sh
如果没有出错,hadoop的高可用就配置完成了;
8、使用hadoop集群测试
在本机中配置hosts文件(不是VMware虚拟机)
文件路径:C:\Windows\System32\drivers\etc\hosts
内容如下:
192.168.8.101 hadoop01192.168.8.102 hadoop02192.168.8.103 hadoop03192.168.8.104 hadoop04192.168.8.105 hadoop05192.168.8.106 hadoop06
在浏览器中输入:http://hadoop01:50070/,就可以看到如下界面

查看hadoop02:http://hadoop02:50070/
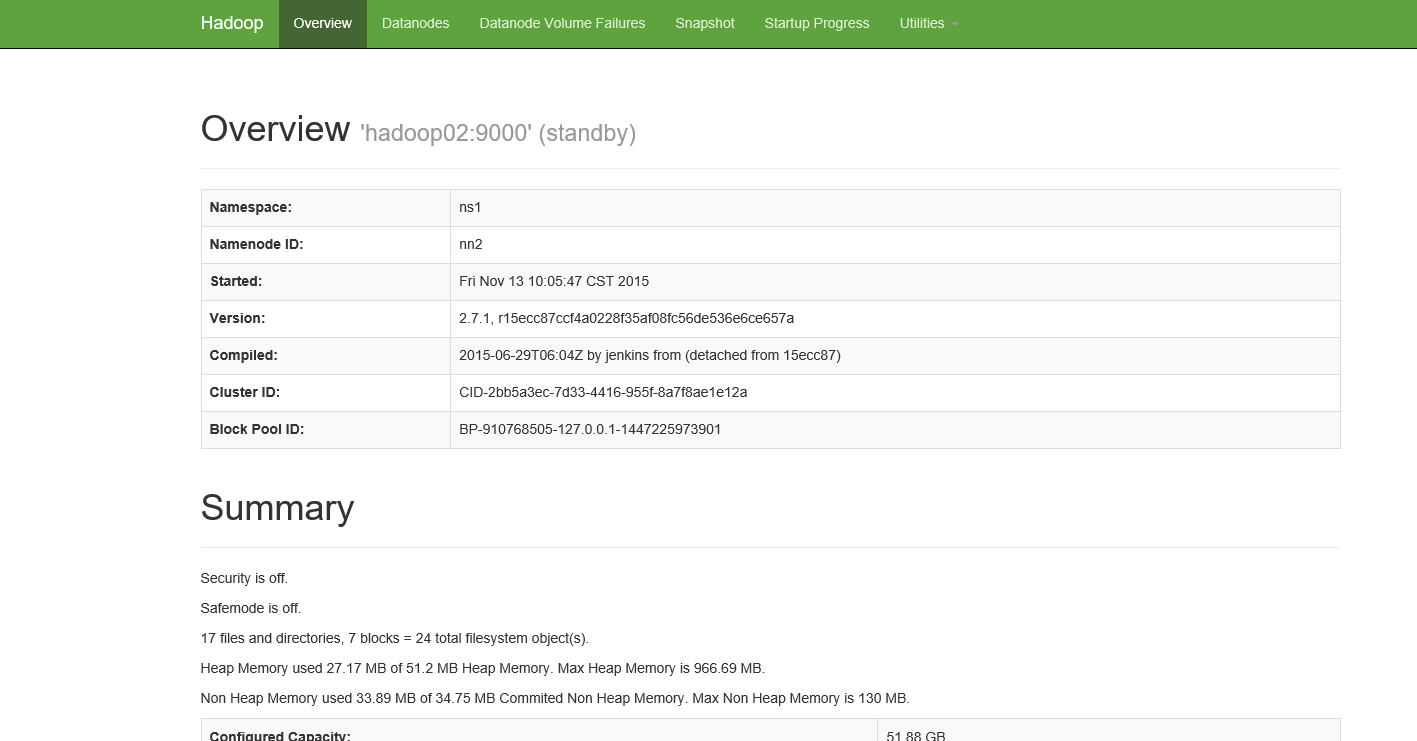
上面可以看到hadoop01是处于active状态,hadoop02是初一standby,接下来测试以下namenode的高可用,当hadoop01挂掉时hadoop02是否能够自动切换;
在hadoop01中kill掉NameNode进程
[root@hadoop01 hadoop-2.7.1]# jps1614 NameNode2500 Jps1929 DFSZKFailoverController[root@hadoop01 hadoop-2.7.1]# kill -9 1614
刷新http://hadoop01:50070/,无法访问,
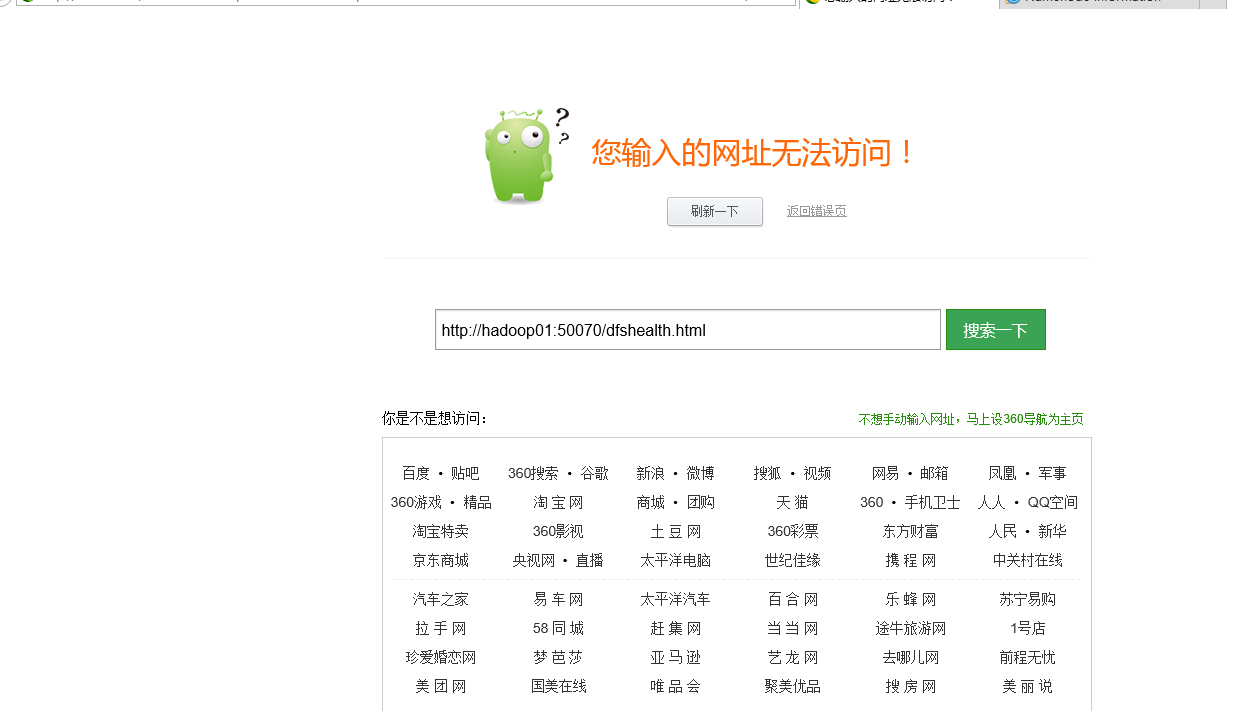
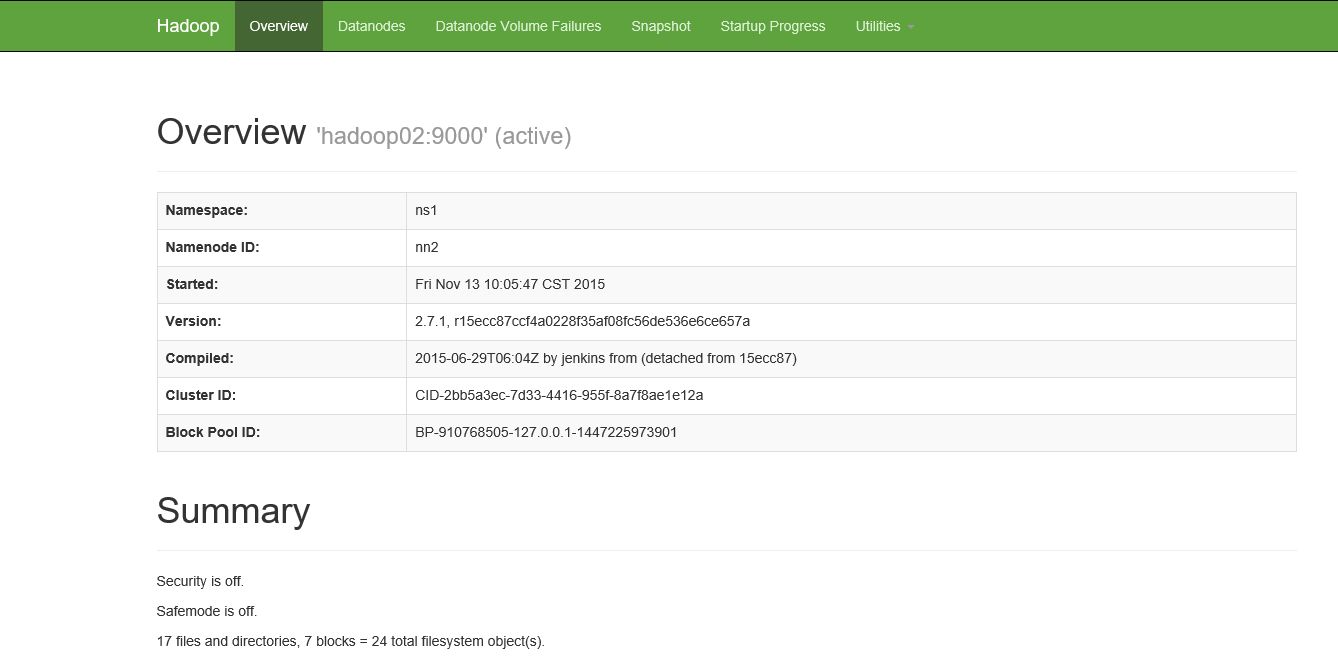
这是hadoop02已经处于active状态了,这说明我们的切换是没有问题的,现在已经完成了hadoop集群的高可用的搭建;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号