
Scrapy 增量式爬虫
Scrapy 增量式爬虫
https://blog.csdn.net/mygodit/article/details/83931009
https://blog.csdn.net/mygodit/article/details/83896412
https://blog.csdn.net/qq_39965716/article/details/81073015
一、定义
二、原理
spider构造的第一个Request请求经由引擎交给了Scheduler,Scheduler中构造一个request对象,并将这个对象存入一个Scheduler的队列中,入队之前会生成一个对应的,唯一的指纹,下一个request对象入队之前,会先比对指纹是否已经存在,以此来达到request对象去重的目的。
Scheduler中Request对象的初始化属性,其中dont_filter表示不去重,默认是False。所以scrapy框架默认是去重的。


1 class Request(object_ref): 2 def __init__(self, url, callback=None, method='GET', headers=None, body=None, 3 cookies=None, meta=None, encoding='utf-8', priority=0, 4 dont_filter=False, errback=None, flags=None):
爬虫组件Spider中,负责构造request对象是 start_requests(self) 函数。Spider构造的request对象修改了dont_filter属性。
源码如下:
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Scrapy去重的原理
Scrapy去重原理是通过sha1()加密request对象的url,method,body属性生成一个十六进制的40位随机字符串,称为指纹。将每个request对象对应的唯一指纹保存到Scheduler队列中,下次请求时,通过对比指纹,来达到request对象去重的目的。
生成指纹集合的源码如下:
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
存储在Scheduler中的reqeust队列,是放在内存上的,如果服务器关闭,或者重启,内存中的缓存就会清空,下次请求就会继续访问原来发送过的请求。
增量式爬虫的意义就是将reques队列持久化存储,以此来达到永久性的缓存。
对此需要用到scrapy_redis(需要pip install scarpy_redis),将request对象的队列和指纹集合存储的位置替换成redis。如下图所示:
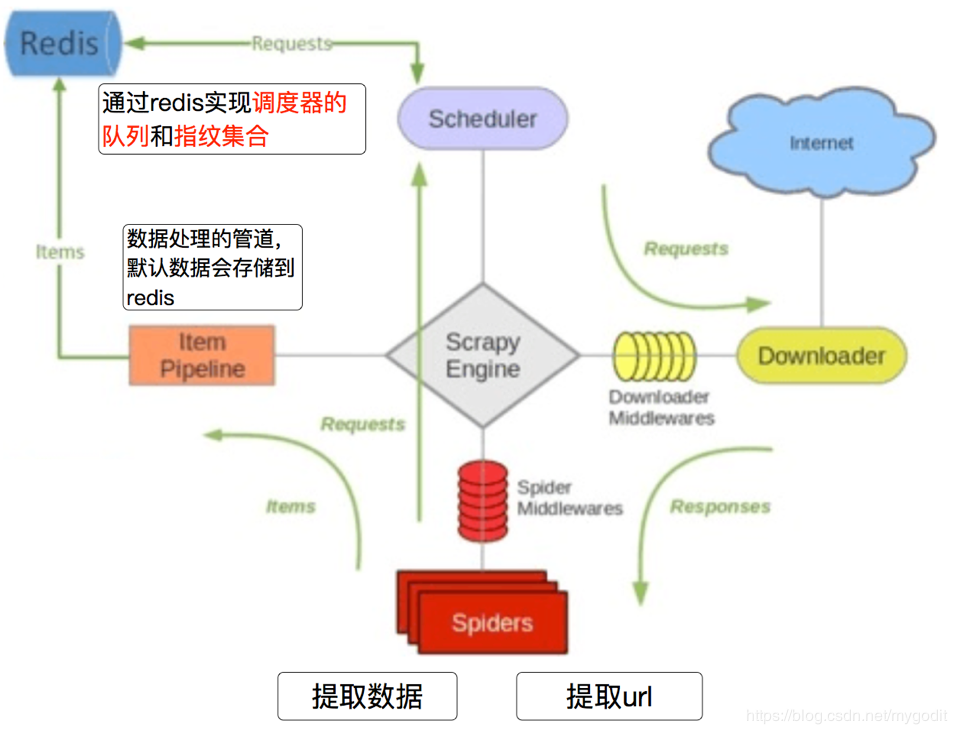
只需要在settings.py文件中添加一些配置,就能实现持久化去重的效果:
1 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" 2 SCHEDULER = "scrapy_redis.scheduler.Scheduler" 3 SCHEDULER_PERSIST = True 4 5 # 添加redis链接 6 REDIS_URL = "redis://127.0.0.1:6379" 7 8 # 或者使用下面的方式 9 # REDIS_HOST = "127.0.0.1" 10 # REDIS_PORT = 6379 11 12 # 在pipeline中添加存储信息的scrapy_redis管道 13 ITEM_PIPELINES = { 14 'scrapy_redis.pipelines.RedisPipeline': 400, 15 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号