


如何在Swift3中获取Json包的内容(unwrap Json package)
我想在这个帖子里面总结两个问题:一个是通过ReST获取Json的语句,这个比较简单
另一个是如何将Json包一层一层转存为字典,并最终通过keyword: String获得所需内容的方法
废话不说,来看代码
首先是服务器返回的Json形式,这里以youtube API为例,因为google做的Json包很规范(都是 String: String 或者 String: Int)
youtube API 的 请求 URL 形式(我这里仅获取关键字搜索视频列表)是
https://www.googleapis.com/youtube/v3/search?part=snippet&q=视频关键字&type=video&key=你的API Key
其中,视频关键字比如 minecraft
API Key 形如 AIzaSyDDqTGpVR7jxeozoOEjH6SLaRdw0YY-HPQ
其返回的Json包形式为
{
"kind": "youtube#searchListResponse",
"etag": "\"uQc-MPTsstrHkQcRXL3IWLmeNsM/dJyYeiv8CbvQiayof_7MqRQOSi8\"",
"nextPageToken": "CAUQAA",
"regionCode": "AU",
"pageInfo": {
"totalResults": 1000000,
"resultsPerPage": 5
},
"items": [
{
"kind": "youtube#searchResult",
"etag": "\"uQc-MPTsstrHkQcRXL3IWLmeNsM/ey6kUbVRRdmcLIPpklkbtxDp_-o\"",
"id": {
"kind": "youtube#video",
"videoId": "XgdgO5UzdR4"
},
"snippet": {
"publishedAt": "2016-11-27T12:00:01.000Z",
"channelId": "UCUVa51UA_690sEKyRbHb-5A",
"title": "5 Werewolves Caught on Camera & Spotted In Real Life!",
"description": "5 Werewolves Caught on Tape & Spotted In Real Life! Description: Myths and stories of humans with the ability to transform into animals exist across all human ...",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/XgdgO5UzdR4/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/XgdgO5UzdR4/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/XgdgO5UzdR4/hqdefault.jpg",
"width": 480,
"height": 360
}
},
"channelTitle": "Top 5s Finest",
"liveBroadcastContent": "none"
}
},
{
"kind": "youtube#searchResult",
"etag": "\"uQc-MPTsstrHkQcRXL3IWLmeNsM/LKJrjJEelN2h1v58M533Dwv_fjs\"",
"id": {
"kind": "youtube#video",
"videoId": "KUS0454UUDM"
},
"snippet": {
"publishedAt": "2016-08-03T10:16:33.000Z",
"channelId": "UC0rzsIrAxF4kCsALP6J2EsA",
"title": "MAIN-MAIN: WEREWOLF",
"description": "Yang mau liat tutorial cara mainnya, klik di sini: https://youtu.be/ShGULqRjLMk.",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/KUS0454UUDM/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/KUS0454UUDM/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/KUS0454UUDM/hqdefault.jpg",
"width": 480,
"height": 360
}
},
"channelTitle": "Raditya Dika",
"liveBroadcastContent": "none"
}
},
{
"kind": "youtube#searchResult",
"etag": "\"uQc-MPTsstrHkQcRXL3IWLmeNsM/8qIl76CAeB__wn-Sd_g4pik1XT0\"",
"id": {
"kind": "youtube#video",
"videoId": "fScsIQ8wgNo"
},
"snippet": {
"publishedAt": "2016-10-02T22:21:35.000Z",
"channelId": "UCNUohh38MTkgY4xKpFeVGmQ",
"title": "Werewolf Scenes - My Favorite Transformation HD",
"description": "Werewolf Scenes - My Favorite Transformation HD.",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/fScsIQ8wgNo/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/fScsIQ8wgNo/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/fScsIQ8wgNo/hqdefault.jpg",
"width": 480,
"height": 360
}
},
"channelTitle": "ENJOY PLEASE",
"liveBroadcastContent": "none"
}
},
{
"kind": "youtube#searchResult",
"etag": "\"uQc-MPTsstrHkQcRXL3IWLmeNsM/SByO_v4iInfFZ5GUe2xJUYXIWh4\"",
"id": {
"kind": "youtube#video",
"videoId": "ShGULqRjLMk"
},
"snippet": {
"publishedAt": "2016-08-03T10:13:33.000Z",
"channelId": "UC0rzsIrAxF4kCsALP6J2EsA",
"title": "TUTORIAL: MAIN WEREWOLF",
"description": "Ini adalah video tutorial untuk main werewolf. Untuk melihat video permainannya, bisa klik di sini: https://youtu.be/KUS0454UUDM.",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/ShGULqRjLMk/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/ShGULqRjLMk/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/ShGULqRjLMk/hqdefault.jpg",
"width": 480,
"height": 360
}
},
"channelTitle": "Raditya Dika",
"liveBroadcastContent": "none"
}
},
{
"kind": "youtube#searchResult",
"etag": "\"uQc-MPTsstrHkQcRXL3IWLmeNsM/NjscIZ4D3C-FDPsnBKe-j5tslrE\"",
"id": {
"kind": "youtube#video",
"videoId": "MI1Yi2AUVAc"
},
"snippet": {
"publishedAt": "2016-09-09T07:27:23.000Z",
"channelId": "UCNUohh38MTkgY4xKpFeVGmQ",
"title": "Vampire vs Werewolf Fight Scene HD - Van Helsing - Vampire vs Lycan Wolf",
"description": "Vampire vs Werewolf Fight Scene HD - Van Helsing - Vampire vs Lycan Wolf.",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/MI1Yi2AUVAc/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/MI1Yi2AUVAc/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/MI1Yi2AUVAc/hqdefault.jpg",
"width": 480,
"height": 360
}
},
"channelTitle": "ENJOY PLEASE",
"liveBroadcastContent": "none"
}
}
]
}
---------------------------------------------------------------------------------------------------------------------
第 0 层
{ }
第一层
{
"kind":"youtube#searchListResponse",
"etag":"\"uQc-MPTsstrHkQcRXL3IWLmeNsM/g4lxZZLl2WXJPiISOtol-Vf33d8\"",
"nextPageToken":"CAUQAA",
"regionCode":"US",
"pageInfo":{ },
"items":[ ]
}
第二层
对于 pageInfo
{
"totalResults":1000000,
"resultsPerPage":5
}
对于 items (注意那个中括号)
[ [
{
"kind":"youtube#searchResult",
"etag":"\"uQc-MPTsstrHkQcRXL3IWLmeNsM/ey6kUbVRRdmcLIPpklkbtxDp_-o\"",
"id":{ },
"snippet":{ }
},
{
"kind":"youtube#searchResult",
"etag":"\"uQc-MPTsstrHkQcRXL3IWLmeNsM/LKJrjJEelN2h1v58M533Dwv_fjs\"",
"id":{ },
"snippet":{ }
},
{
"kind":"youtube#searchResult",
"etag":"\"uQc-MPTsstrHkQcRXL3IWLmeNsM/8qIl76CAeB__wn-Sd_g4pik1XT0\"",
"id":{ },
"snippet":{ }
},
{
"kind":"youtube#searchResult",
"etag":"\"uQc-MPTsstrHkQcRXL3IWLmeNsM/SByO_v4iInfFZ5GUe2xJUYXIWh4\"",
"id":{ },
"snippet":{ }
},
{
"kind":"youtube#searchResult",
"etag":"\"uQc-MPTsstrHkQcRXL3IWLmeNsM/NjscIZ4D3C-FDPsnBKe-j5tslrE\"",
"id":{ },
"snippet":{ }
}
]
这就是说,中括号里面的内容实际上是一个数组,这个数组有五个元素。
第三层
以其中一个元素为例
对于 id
{
"kind":"youtube#video",
"videoId":"XgdgO5UzdR4"
}
对于 snippet
{
"publishedAt":"2016-11-27T12:00:01.000Z",
"channelId":"UCUVa51UA_690sEKyRbHb-5A",
"title":"5 Werewolves Caught on Camera & Spotted In Real Life!",
"description":"5 Werewolves Caught on Tape & Spotted In Real Life! Description: Myths and stories of humans with the ability to transform into animals exist across all human ...",
"thumbnails":{ },
"channelTitle":"Top 5s Finest",
"liveBroadcastContent":"none"
}
第四层
对于 thumbnails
{
"default":{ },
"medium":{ },
"high":{ }
}
第五层
对于 default
{
"url":"https://i.ytimg.com/vi/XgdgO5UzdR4/default.jpg",
"width":120,
"height":90
}
其它两个类似
至此Json 包解析完毕。
然后附上代码。首先是ReST请求部分
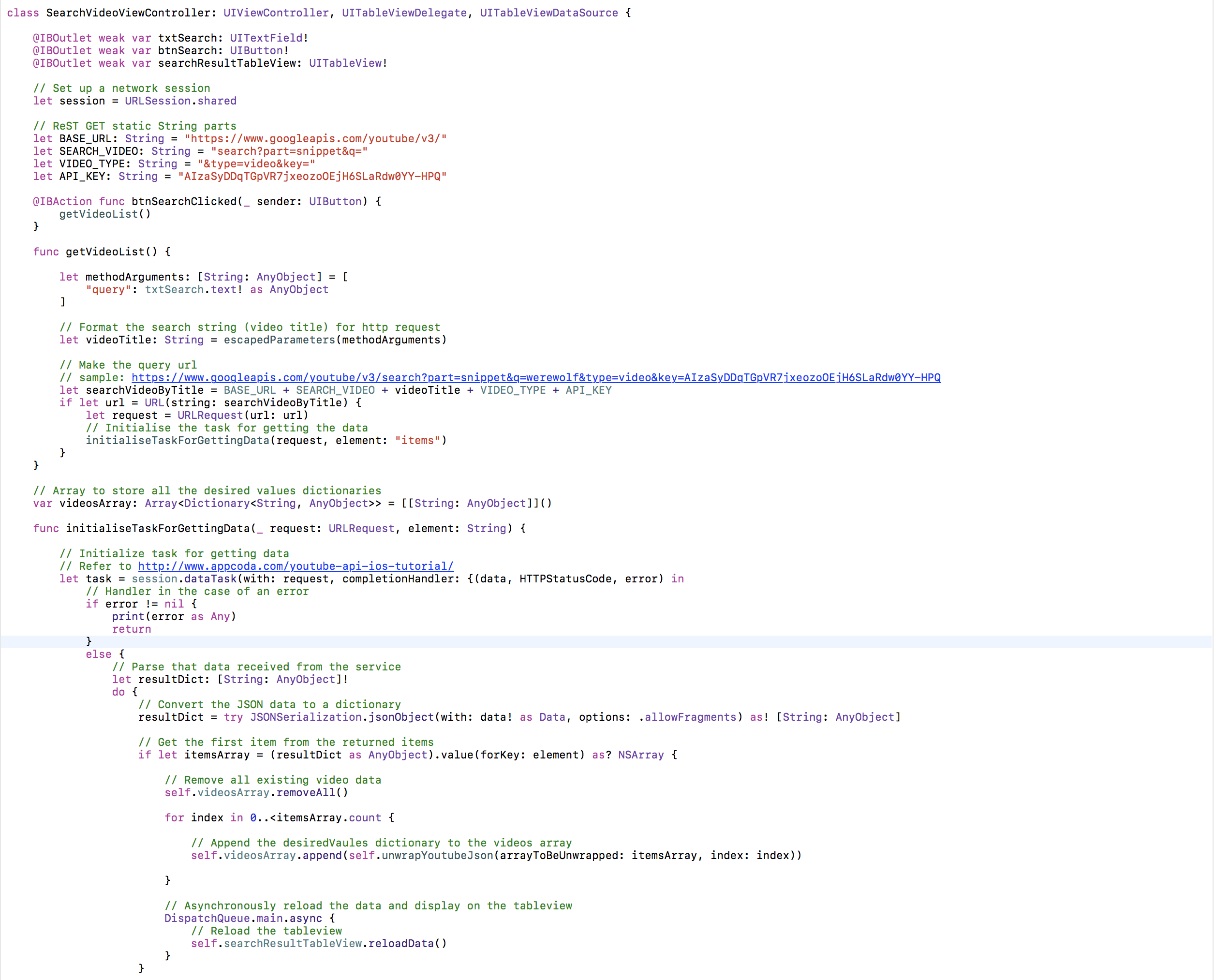
然后是Json解析部分

只解释Json解析部分。
我现在的目的是取出四个key值:视频的title、description、thumbnail default url 还有 videoId
过程是这样:
根据我上面的分析,从第一层开始(第 0 层不算)每层都建立[String: AnyObject]字典或数组(根据Json那一层的结构而定)。在最后一层只有String内容的时候,也可以建立[String: String]字典(也就是idDict也可以建成[String: String]的,别的不可以。)
第一层 - resultDict 这个不能建成[String: String],因为pageInfo和items关键字对应的不是String,而是一个或多个子字典。
第二层 - 因为pageInfo里面的内容我不需要(如需要建字典),所以只有items对应的数组 -- itemsArray (建数组因为items本身是五个元素组成的数组,在前面已经说明。)
第三层 - 对于 id -- idDict字典,这个可以建[String: AnyObject]也可以建[String: String](因为内容只有String,建AnyObject的话,就需要cast一下(as! String)。)
对于 snippet -- snippetDict字典,这个必须[String: AnyObject]
第四层 - thumbnailDict
第五层 - defaultDict,其它两个Key里面的信息不需要,如果需要,也可以建相应字典提取出来。
然后我建了一个每个元素都是[String: AnyObject]字典的Array,形如[[String: AnyObject]],用来储存我提取出来的四个keyword对应的信息。当然,这个数组建成[[String: String]]也是可以的。当时对这个代码理解还不深,属于半迷糊状态。
然后就大功告成。

