python处理excel文件
一、简介
用python来自动生成excel数据文件。python处理excel文件主要是第三方模块库xlrd、xlwt、xluntils和pyExcelerator,除此之外,python处理excel还可以用win32com和openpyxl模块。
安装:
pip install xlutils
二、使用xlrd读取文件:

import xlrd #打开一个workbook workbook = xlrd.open_workbook('E:\\Code\\Python\\testdata.xls') #抓取所有sheet页的名称 worksheets = workbook.sheet_names() print('worksheets is %s' %worksheets) #定位到sheet1 worksheet1 = workbook.sheet_by_name(u'Sheet1') """ #通过索引顺序获取 worksheet1 = workbook.sheets()[0] #或 worksheet1 = workbook.sheet_by_index(0) """ """ #遍历所有sheet对象 for worksheet_name in worksheets: worksheet = workbook.sheet_by_name(worksheet_name) """ #遍历sheet1中所有行row num_rows = worksheet1.nrows for curr_row in range(num_rows): row = worksheet1.row_values(curr_row) print('row%s is %s' %(curr_row,row)) #遍历sheet1中所有列col num_cols = worksheet1.ncols for curr_col in range(num_cols): col = worksheet1.col_values(curr_col) print('col%s is %s' %(curr_col,col)) #遍历sheet1中所有单元格cell for rown in range(num_rows): for coln in range(num_cols): cell = worksheet1.cell_value(rown,coln) print cell """ #其他写法: cell = worksheet1.cell(rown,coln).value print cell #或 cell = worksheet1.row(rown)[coln].value print cell #或 cell = worksheet1.col(coln)[rown].value print cell #获取单元格中值的类型,类型 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error cell_type = worksheet1.cell_type(rown,coln) print cell_type """
示例:
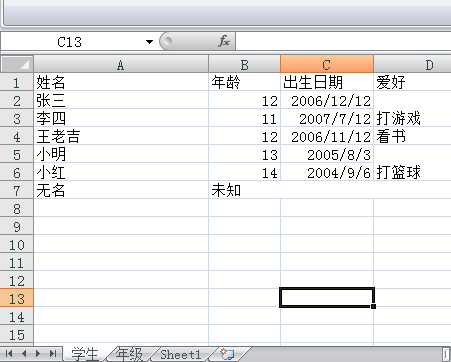
整体思路为,打开文件,选定表格,读取行列内容,读取表格内数据
import xlrd from datetime import date,datetime file = 'test3.xlsx' def read_excel(): wb = xlrd.open_workbook(filename=file)#打开文件 print(wb.sheet_names())#获取所有表格名字 sheet1 = wb.sheet_by_index(0)#通过索引获取表格 sheet2 = wb.sheet_by_name('年级')#通过名字获取表格 print(sheet1,sheet2) print(sheet1.name,sheet1.nrows,sheet1.ncols) rows = sheet1.row_values(2)#获取行内容 cols = sheet1.col_values(3)#获取列内容 print(rows) print(cols) print(sheet1.cell(1,0).value)#获取表格里的内容,三种方式 print(sheet1.cell_value(1,0)) print(sheet1.row(1)[0].value)
运行结果如下:

那么问题来了,上面的运行结果中红框框中的字段明明是出生日期,可显示的确实浮点数;同时合并单元格里面应该是有内容的,结果不能为空。
别急,我们来一一解决这两个问题:
1.Python读取Excel中单元格内容为日期的方式
Python读取Excel中单元格的内容返回的有5种类型,即上面例子中的ctype:
ctype : 0 empty,1 string,2 number, 3 date,4 boolean,5 error
即date的ctype=3,这时需要使用xlrd的xldate_as_tuple来处理为date格式,先判断表格的ctype=3时xldate才能开始操作。
详细代码如下:
import xlrd from datetime import date,datetime print(sheet1.cell(1,2).ctype) date_value = xlrd.xldate_as_tuple(sheet1.cell_value(1,2),wb.datemode) print(date_value) print(date(*date_value[:3])) print(date(*date_value[:3]).strftime('%Y/%m/%d'))
运行结果如下:

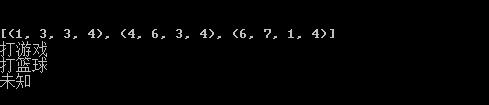
2.获取合并单元格的内容
在操作之前,先介绍一下merged_cells()用法,merged_cells返回的这四个参数的含义是:(row,row_range,col,col_range),其中[row,row_range)包括row,不包括row_range,col也是一样,即(1, 3, 4, 5)的含义是:第1到2行(不包括3)合并,(7, 8, 2, 5)的含义是:第2到4列合并。
详细代码如下:
print(sheet1.merged_cells) print(sheet1.cell_value(1,3)) print(sheet1.cell_value(4,3)) print(sheet1.cell_value(6,1))
运行结果如下:
发现规律了没?是的,获取merge_cells返回的row和col低位的索引即可! 于是可以这样批量获取:
详细代码如下:
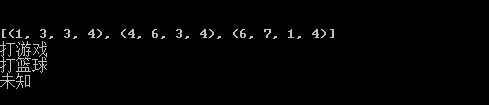
merge = [] print(sheet1.merged_cells) for (rlow,rhigh,clow,chigh) in sheet1.merged_cells: merge.append([rlow,clow]) for index in merge: print(sheet1.cell_value(index[0],index[1]))
运行结果跟上图一样,如下:
三、使用xlwt生成Excel文件(可以控制Excel中单元格的格式):
import xlwt #创建workbook和sheet对象 workbook = xlwt.Workbook() #注意Workbook的开头W要大写 sheet1 = workbook.add_sheet('sheet1',cell_overwrite_ok=True) sheet2 = workbook.add_sheet('sheet2',cell_overwrite_ok=True) #向sheet页中写入数据 sheet1.write(0,0,'this should overwrite1') sheet1.write(0,1,'aaaaaaaaaaaa') sheet2.write(0,0,'this should overwrite2') sheet2.write(1,2,'bbbbbbbbbbbbb') """ #-----------使用样式----------------------------------- #初始化样式 style = xlwt.XFStyle() #为样式创建字体 font = xlwt.Font() font.name = 'Times New Roman' font.bold = True #设置样式的字体 style.font = font #使用样式 sheet.write(0,1,'some bold Times text',style) """ #保存该excel文件,有同名文件时直接覆盖 workbook.save('E:\\Code\\Python\\test2.xls') print '创建excel文件完成!'
示例:
import xlwt #设置表格样式 def set_style(name,height,bold=False): style = xlwt.XFStyle() font = xlwt.Font() font.name = name font.bold = bold font.color_index = 4 font.height = height style.font = font return style #写Excel def write_excel(): f = xlwt.Workbook() sheet1 = f.add_sheet('学生',cell_overwrite_ok=True) row0 = ["姓名","年龄","出生日期","爱好"] colum0 = ["张三","李四","恋习Python","小明","小红","无名"] #写第一行 for i in range(0,len(row0)): sheet1.write(0,i,row0[i],set_style('Times New Roman',220,True)) #写第一列 for i in range(0,len(colum0)): sheet1.write(i+1,0,colum0[i],set_style('Times New Roman',220,True)) sheet1.write(1,3,'2006/12/12') sheet1.write_merge(6,6,1,3,'未知')#合并行单元格 sheet1.write_merge(1,2,3,3,'打游戏')#合并列单元格 sheet1.write_merge(4,5,3,3,'打篮球') f.save('test.xls') if __name__ == '__main__': write_excel()
结果图:
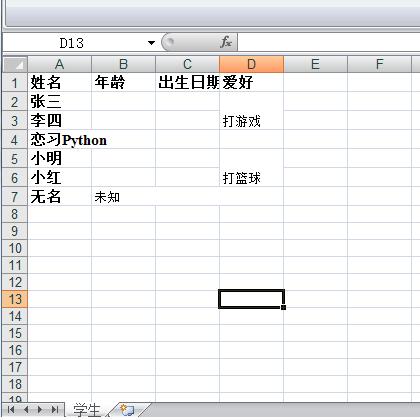
在此,对write_merge()的用法稍作解释,如上述:sheet1.write_merge(1,2,3,3,'打游戏'),即在四列合并第2,3列,合并后的单元格内容为"合计",并设置了style。其中,里面所有的参数都是以0开始计算的。
四、使用xluntils模块修改文件:
import xlrd import xlutils.copy #打开一个workbook rb = xlrd.open_workbook('E:\\Code\\Python\\test1.xls')
#复制的Excel是没有格式的,要保留原格式需要使用:rb = xlrd.open_workbook('E:\\Code\\Python\\test1.xls',formatting_info=True) wb = xlutils.copy.copy(rb) #获取sheet对象,通过sheet_by_index()获取的sheet对象没有write()方法 ws = wb.get_sheet(0) #写入数据 ws.write(1, 1, 'changed!') #添加sheet页 wb.add_sheet('sheetnnn2',cell_overwrite_ok=True) #利用保存时同名覆盖达到修改excel文件的目的,注意未被修改的内容保持不变 wb.save('E:\\Code\\Python\\test1.xls')
在修改的过程中,使用ws.write()被修改的单元格会清空格式,若要保留原格式,需要使用以下函数:
#本文重点,该函数中定义:对于没有任何修改的单元格,保持原有格式。 def setOutCell(outSheet, col, row, value): """ Change cell value without changing formatting. """ def _getOutCell(outSheet, colIndex, rowIndex): """ HACK: Extract the internal xlwt cell representation. """ row = outSheet._Worksheet__rows.get(rowIndex) if not row: return None cell = row._Row__cells.get(colIndex) return cell # HACK to retain cell style. previousCell = _getOutCell(outSheet, col, row) # END HACK, PART I outSheet.write(row, col, value) # HACK, PART II if previousCell: newCell = _getOutCell(outSheet, col, row) if newCell: newCell.xf_idx = previousCell.xf_idx # 使用函数setOutCell代替ws.write() setOutCell(ws,col,row,"写入内容")
五、pyExcelerator模块与xlwt类似,也可以用来生成excel文件
读:
import pyExcelerator #parse_xls返回一个列表,每项都是一个sheet页的数据。 #每项是一个二元组(表名,单元格数据)。其中单元格数据为一个字典,键值就是单元格的索引(i,j)。如果某个单元格无数据,那么就不存在这个值 sheets = pyExcelerator.parse_xls('E:\\Code\\Python\\testdata.xls') print sheets
写:
import pyExcelerator #创建workbook和sheet对象 wb = pyExcelerator.Workbook() ws = wb.add_sheet(u'第一页') #设置样式 myfont = pyExcelerator.Font() myfont.name = u'Times New Roman' myfont.bold = True mystyle = pyExcelerator.XFStyle() mystyle.font = myfont #写入数据,使用样式 ws.write(0,0,u'ni hao 帕索!',mystyle) #保存该excel文件,有同名文件时直接覆盖 wb.save('E:\\Code\\Python\\mini.xls') print '创建excel文件完成!'
六、报错:
但是我们会发现在读取xlsx格式的Excel时,传入formatting_info会直接抛出异常,而读取xls类型的文件时不存在此问题。
raise NotImplementedError("formatting_info=True not yet implemented")
不难推断,抛异常的原因是formatting_info还没有对新版本的xlsx的格式完成兼容。
那么如果我们要操作的文件刚好是xlsx格式,又想保存其原有的格式该怎么办呢?
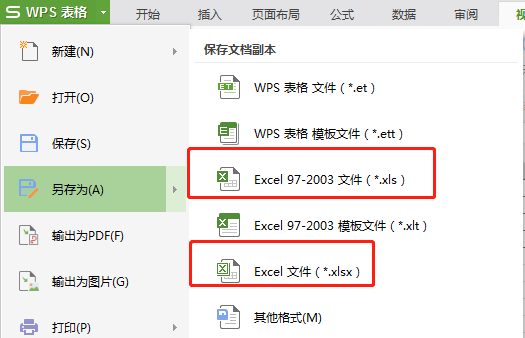
1、修改为xlsx为xls(推荐)
将xlsx另存为xls,然后再进行后续操作,亲测有效,能正常保存Excel原有格式, 不用修改代码。
2、改用 openpyxl
coding尝试读取文件,处理速度真的很慢...而且规则和宏全部丢失。
3、使用pywin32
这是用于Win32 (pywin32)扩展的Python扩展库,它提供了对许多来自Python的Windows api的访问。
4、使用老旧的版本 xlrd-0.6.1
使用xlrd-0.6.1可以读取,没有异常抛出。直到我传入其他几个xls文件,出现Expected BOF record; found 0x4b50 错误,原因是xlrd-0.6.1不支持office2007
参考:
https://www.cnblogs.com/Detector/p/8709362.html
https://www.cnblogs.com/songdanqi0724/p/8145455.html
https://blog.csdn.net/qq_33683032/article/details/79027811
https://blog.csdn.net/csdnnews/article/details/80878945


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?