
HDFS 机架感知
互联网公司的 Hadoop 集群一般都会比较大,几百台服务器会分布在不同的机架上,甚至在不同的机房。出于保证数据安全性和数据传输的高效性的平衡考虑,HDFS希望不同节点之间的通信能够尽量发生在同一个机架之内,而不是跨机架和跨机房。同时,NameNode 在分配 Block 的存储位置的时候,会尽可能把数据块的副本放到多个机架甚至机房中,防止机架出现事故或者机房出现事故时候的数据丢失问题发生。
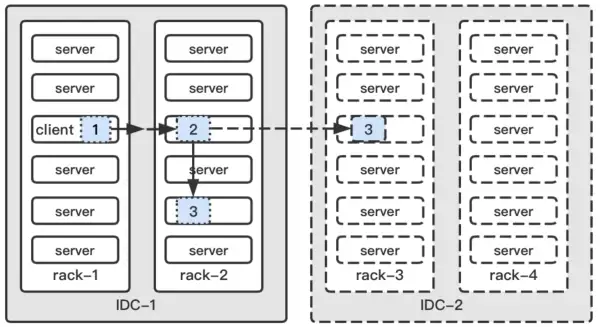
这就是 HDFS 的机架感知,首先机房和机架的信息是需要用户自己配置的,HDFS 没法做到自动感知,然后根据配置的信息,NameNode 会有如下的副本放置策略。
- 第一个 block 副本放在 Client 所在的服务器,如果 client 不在集群服务器中,则这第一个 DataNode 会随机选择。
- 第二个副本放置在与第一个节点不同的机架中的节点中,保证机架间的高可用。
- 第三个有不同机房则跨机房随机放置在某个节点上;只有一个机房则和第二副本在同一个机架,随机放在不同的节点中。
- 更多的副本,则继续随机放置,需要注意的是一个节点最多放置一个副本。HDFS 读流程中如何找到最佳节点? 这个放置策略其实也就是上一篇中提到的 HDFS 读流程中如何找到最佳节点的答案。读的过程,会首先找离 Client 最近的 DataNode,保证读的高效避免资源浪费,先后顺序依次是:
1. 与 Client 在同一服务器
2. 在同一机架
3. 在同一个机房
4. 跨机房

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2019-12-11 kafka保证精确一次消费
2019-12-11 Flume源码更改
2019-12-11 Flume拦截器、监控器