我的python中级班学习之路(全程笔记第一模块) (第二章)(第2部分:字符串)
第二章 数据类型 字符编码 文件操作
第二部分
第五节 :数据类型—字符串讲解
一、定义:
字符串是一个有序的字符的字符集合,用于存储和表示基本的文本信息,一对单、双或三个引号中间包含的内容称之为字符。
二、特点:
1.有序 :字符串的生成,都是有顺序排列的!
2.不可变 :字符串一旦声明,不能修改!
三、示例讲解
例: >>> a = 'longyang' >>> a 'longyang' >>> id(a) 1772547998576 # 第一个 a 的内存地址! >>> a = 'peiqi' >>> a 'peiqi' >>> id(a) 1772547996000 # 更改后的内存地址, ***这就证明,两个 a 是完全不同的,第二个 a 只是又重新开辟了一个内存地址,之前的 a 会被python解释器定时清理掉!
四、字符串的应用与方法:
字符串的用法有很多,打开 pycharm ,输入一个变量,再次输入变量名加 . 就会出来很多的方法。
如图 :

****不需要看下划线的,只需要看 m 开头的
1.大写变小写,小写变大写。
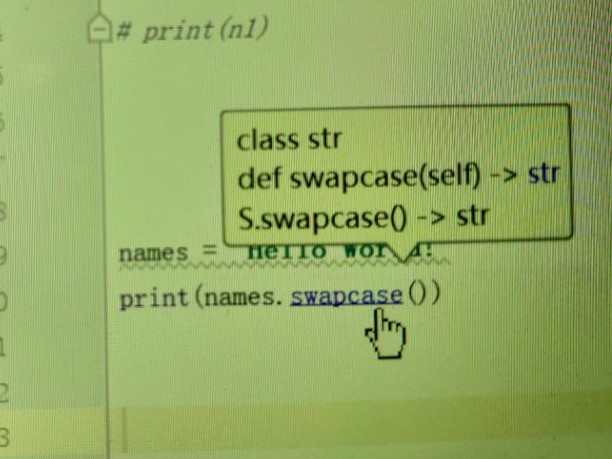
例: >>> s = 'Hello World!' >>> s 'Hello World!' >>> s.swapcase() 'hELLO wORLD!' ***发现首字母大写已经变小写,小写已变大写!
注意:这个修改也是生成的新的地址,不是原值。
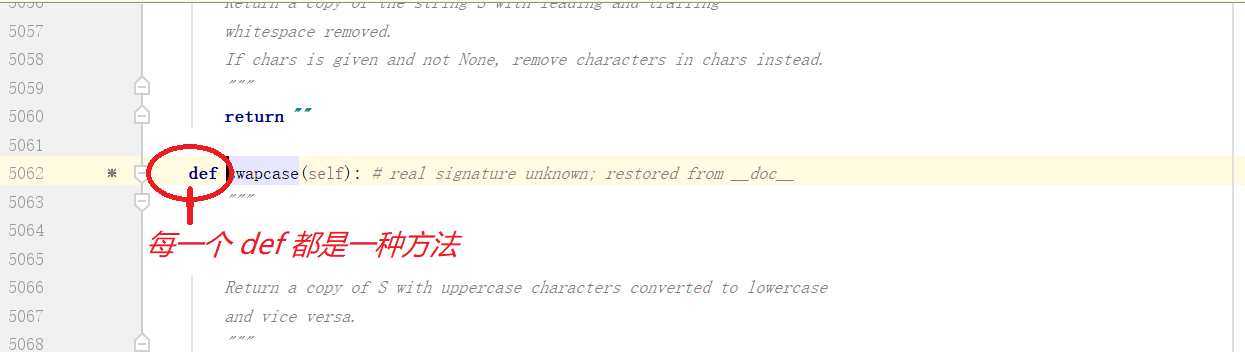
2.进入源码看方法:
在pycharm编译器里,鼠标移到语法上,Windows系统按住 Ctrl 键,语法会变成蓝色的,点击进入源码,每个方法的用途,都可以在这地方看到相对的解释!
如图:
点进去可以见到,每一个 def 都是的一个功能,(这叫函数,后面会讲)
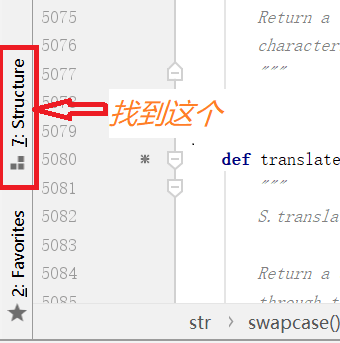
在pycharm左下角找到 structure 如图1,再找到 str (因为我的字符串类型就是 str )如图 2,所有的红标m(不看加锁的)就是方法:
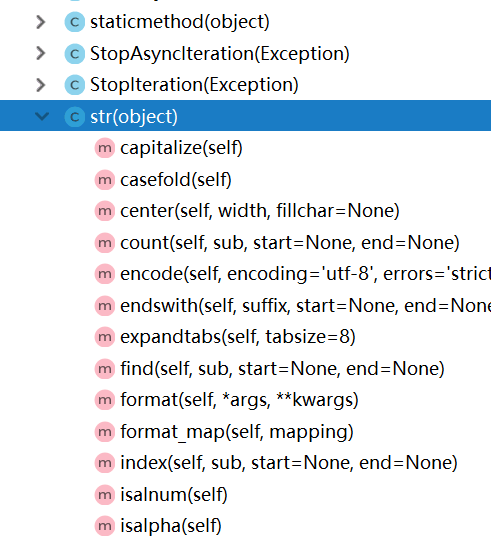
**重点 常用的语法:
必须会的
- 3 . centre (商品列表格式化横线)
- 4 . count(统计)
- 7 . find (查找索引)
- 8 . format (格式化占位)
- 13 .isdigit(.判断是否为整数)
- 19 . join(列表转字符串指定连接分隔号)
- 22 . strip (脱掉)
- 25 . replace(替换)
- 28 . split (字符变列表)
下面一一列举
1.首字母大写:
例: >>> s = 'hello world!' >>> s 'hello world!' >>> s.capitalize() #首字母大写 'Hello world!'
2.把大小写全部统一小写:
例: >>> s = 'HELLO WORLD!' >>> s.casefold() 'hello world!' >>>
3.商品列表格式化横线:
例: >>> s 'hello world!' >>> s.center(50,'*') #50为长度,他会自动中分,两侧对称。 '*******************hello world!*******************' >>> s.center(50,'-') #也可换一种符号 '-------------------hello world!-------------------' >>>
4.统计:跟列表的方法一样,统计字符串内有几个重复的值。
例: >>> s 'hello world!' >>> s.count('o') #统计有几个o 2 #返回2个
****还可切片统计:
>>> s 'hello world!' >>> s.count('o',0,5) #统计索引0至5有几个o 1 #返回一个
5.判断以什么结尾:
例: >>> s 'hello world!' >>> s.endswith('!') #判断是否以 !结尾 True #返回对的 >>> s.endswith('a') #判断其他 False #返回错的
6.扩展:把默认长度变长!
例: >>> s2 = 'a\t b' #\t 是换行, >>> >>> print(s2) a b #默认8个空格 >>> s2.expandtabs(12) #可以指定增加长度 'a b' #变成12个空格 >>>
7.查找:找到返回索引,找不到就返回 -1
例: >>> s 'hello world!' >>> s.find('w') 6 # 找到返回索引 >>> s.find('qbf') -1 # 找不到返回 -1
***也可切片查找:找到返回索引,找不到就返回 -1
例: >>> s 'hello world!' >>> s.find('w',0,7) 6 >>> s.find('w',0,3) -1
8.格式化占位:替代占位符方法。
例: >>> s3 = "hello my names is {0},im {1} years old!" >>> s3 'hello my names is {0},im {1} years old!' #其中{0,1}属于索引值 >>> s3.format('yilong',22) #其中(‘longyang’,22)默认索引为0,1 'hello my names is yilong,im 22 years old!' 还有另一种方法: >>> s3 = "hello my names is {0},im {1} years old!" >>> s3 'hello my names is {name},im {age} years old!' >>> s3.format(name = 'yilong', age = 22) 'hello my names is yilong,im 22 years old!'
9.返回指定索引(可切片)
例: >>> s = 'Hello World!' >>> s 'Hello World!' >>> s.index('o') #指定查找 4 >>> s.index('o',5,9) #指定索引查找(切片查找) 7
10. 判断是否是阿拉伯数字或字母
例: >>> '22'.isalnum() True >>> 'tt'.isalnum() True >>> '..'.isalnum() False >>> '!'.isalnum() False >>>
11.判断是否为字符
例: >>> '22'.isalpha() False >>> 'rr'.isalpha() True
12.判断是否为数字:
例: >>> '22'.isdecimal() True >>> 'we'.isdecimal() False
13.判断是否为整数:
例: >>> 'we'.isdigit() False >>> '22'.isdigit() True >>> '22.84'.isdigit() False
14.判断变量是否合格(是否为标准的变量名)
例: 例: >>> '333'.isidentifier() False >>> 'a333'.isidentifier() #只有这一个正切的变量名 True >>> '333ddd'.isidentifier() False >>>
15. 判断是否为小写
例: >>> '333ddd'.islower() True >>> 'D333ddd'.islower() False >>>
16. 判断是否都是数字
例: >>> 'D333ddd'.isnumeric() False >>> '333'.isnumeric() True >>>
17 . 判断是否为可打印文件(文本文件或字节码)
例: >>> '333'.isprintable() True >>> #除了二进制流,和二进制类的其他都可打印
18 . 判断单词的首字母是否为大写
例: >>> s 'Hello World!' >>> s.istitle() True >>> 'eewww'.istitle() False >>>
19 . 把列表变成字符换(以什么连接)(也可称为连接符)
例: >>> names ['old_driver', 'rain', 'jack', '姗姗', 'peiqi', 'alex', 'black_girl'] >>> ' _ '.join(names) 'old_driver _ rain _ jack _ 姗姗 _ peiqi _ alex _ black_girl' >>> #列表的每一个元素,都以下划线连接
20 . 从左至右开始把字符变成固定长度(不够的,指定字符代替)
例:>>> s 'Hello World!' #需要指定长度,和填充字符 >>> s.ljust(50,'-') 'Hello World!--------------------------------------' >>> s.ljust(50,'*') 'Hello World!**************************************' >>> s.ljust(50,'5') #可以更换其他字符填充 'Hello World!55555555555555555555555555555555555555' >>> s.ljust(50,'r') 'Hello World!rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr'
21 . 全变小写 和 全变大写
例: *全变小写 >>> s 'Hello World!' >>> s.lower() #语法,全变小写 'hello world!' **全变大写 >>> s 'Hello World!' >>> s.upper() #语法,全变大写 'HELLO WORLD!'
22 . 脱掉:去掉空格或去掉换行和 Tab 键:
例: >>> s = '\n Hello World!' >>> print(s) Hello World! >>> s.strip() 'Hello World!' #脱掉换行和空格 ***脱掉还有两个小语法:lstrip() 脱掉左边,rstrip() 脱掉右边
23 . 密码关系映射表 (按照ASCII码表)
例: >>> n = 'abcdef' >>> n2 = '!@#$%^' >>> s = 'Hello World!' #设定关系映射变量 >>> n 'abcdef' >>> n2 #两个变量索引需要相同 '!@#$%^' >>> str.maketrans(n,n2) #生成对应关系映射表 {97: 33, 98: 64, 99: 35, 100: 36, 101: 37, 102: 94} >>> n3 = str.maketrans(n,n2) >>> s.translate(n3) #按照映射关系翻译普通句子 '\n H%llo Worl$!' ***一定要先生成映射关系,再翻译
24 . 字符串转元祖:指定以某一个字母区分成三个值!
例: >>> s 'Hello World!' >>> s.partition('o') #设定分裂字符串的元素 ('Hell', 'o', ' World!') >>> s.partition('w') #如果指定元素找不到,会自动生成 ('Hello World!', '', '') >>> s.partition('d') ('Hello Worl', 'd', '!')
25 . 替换:
例: >>> s 'Hello World!' >>> s.replace('H','h') #替换小写 'hello World!' >>> s.replace('o','-') #重复默认全换 'Hell- W-rld!' >>> s.replace('o','-',1) #还可设置替换几个 'Hell- World!'9
26 . 反向查找:从右至左查找
例: >>> s 'Hello World!' >>> s.rfind('o') #从右至左查找 o 的索引 7 #返回重复的第二个索引
27 . 把字符串生成列表,可指定分区
例: >>> s 'Hello World!' >>> s.split() ['Hello', 'World!'] #把字符串分2个生成了列表 >>> s.split('o') #可指定元素分,被指定的元素会消失,生成列表元素分割符号 ['Hell', ' W', 'rld!'] >>> s.split('o',1) #还可设定重复分割次数 ['Hell’,‘World!'] >>>s.rsplit(‘o’,1) #也可反向获取分割符 ['Hello W', 'rld!']
28 . 按行的字符串生成列表
例: >>> n = 'a\nb\nc\nd\nalex' >>> n.splitlines() ['a', 'b', 'c', 'd', 'alex'] >>>
29 . 判断以什么开始和以什么结束:
例: 判断以什么开头: >>> s = 'hello world!' >>> s.startswith('he') True >>> s.startswith('w') 判断以什么结尾: False >>> s.endswith('ld') False >>> s.endswith('!') True
——————————————第二部分结束线——————————————2018-11-01
