
机器学习数学基础总结
线性代数
一、基本知识
- 本文中所有的向量都是列向量的形式:
\mathbf{\vec x}=(x_1,x_2,\cdots,x_n)^T=\begin{bmatrix}x_1\\x_2\\ \vdots \\x_n\end{bmatrix}$$ 本书中所有的矩 $\mathbf X\in \mathbb R^{m\times n}$ 都表示为:
$$\mathbf X = \begin{bmatrix}
x_{1,1}&x_{1,2}&\cdots&x_{1,n}\\
x_{2,1}&x_{2,2}&\cdots&x_{2,n}\\
\vdots&\vdots&\ddots&\vdots\\
x_{m,1}&x_{m,2}&\cdots&x_{m,n}\\
\end{bmatrix}$$ 简写为 $(x_{i,j})_{m\times n}$ 或 $[x_{i,j}]_{m\times n}$ 。
2. 矩阵的`F`范数:设矩 $\mathbf A=(a_{i,j})_{m\times n}$ ,则其`F`范数为 $||\mathbf A||_F=\sqrt{\sum_{i,j}a_{i,j}^{2}}$ 。
它是向量 $L_2$ 范数的推广。
3. 矩阵的迹:设矩 $\mathbf A=(a_{i,j})_{m\times n}$ , $ \mathbf A$ 的迹为 $tr(\mathbf A)=\sum_{i}a_{i,i}$ 。
迹的性质有:
- $\mathbf A$ 的`F` 范数等 $\mathbf A\mathbf A^T$ 的迹的平方根 $||\mathbf A||_F=\sqrt{tr(\mathbf A \mathbf A^{T})}$ 。
- $\mathbf A$ 的迹等 $\mathbf A^T$ 的迹 $tr(\mathbf A)=tr(\mathbf A^{T})$ 。
- 交换律:假设 $\mathbf A\in \mathbb R^{m\times n},\mathbf B\in \mathbb R^{n\times m}$ ,则有 $tr(\mathbf A\mathbf B)=tr(\mathbf B\mathbf A)$ 。
- 结合律 $tr(\mathbf A\mathbf B\mathbf C)=tr(\mathbf C\mathbf A\mathbf B)=tr(\mathbf B\mathbf C\mathbf A)$ 。
## 二、向量操作
1. 一组向 $\mathbf{\vec v}_1,\mathbf{\vec v}_2,\cdots,\mathbf{\vec v}_n$ 是线性相关的:指存在一组不全为零的实 $a_1,a_2,\cdots,a_n$ ,使得 $\sum_{i=1}^{n}a_i\mathbf{\vec v}_i=\mathbf{\vec 0}$ 。
一组向 $\mathbf{\vec v}_1,\mathbf{\vec v}_2,\cdots,\mathbf{\vec v}_n$ 是线性无关的,当且仅 $a_i=0,i=1,2,\cdots,n$ 时,才有 $\sum_{i=1}^{n}a_i\mathbf{\vec v}_i=\mathbf{\vec 0}$ 。
2. 一个向量空间所包含的最大线性无关向量的数目,称作该向量空间的维数。
3. 三维向量的点积 $\mathbf{\vec u}\cdot\mathbf{\vec v} =u _xv_x+u_yv_y+u_zv_z = |\mathbf{\vec u}| | \mathbf{\vec v}| \cos(\mathbf{\vec u},\mathbf{\vec v})$ 。
<center>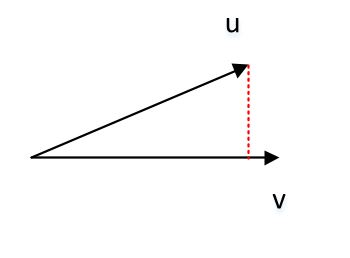</center>
4. 三维向量的叉积:
$$\mathbf{\vec w}=\mathbf{\vec u}\times \mathbf{\vec v}=\begin{bmatrix}\mathbf{\vec i}& \mathbf{\vec j}&\mathbf{\vec k}\\ u_x&u_y&u_z\\ v_x&v_y&v_z\\ \end{bmatrix}$$ 其 $\mathbf{\vec i}, \mathbf{\vec j},\mathbf{\vec k}$ 分别 $x,y,z$ 轴的单位向量。
$$\mathbf{\vec u}=u_x\mathbf{\vec i}+u_y\mathbf{\vec j}+u_z\mathbf{\vec k},\quad \mathbf{\vec v}=v_x\mathbf{\vec i}+v_y\mathbf{\vec j}+v_z\mathbf{\vec k}$$
- $\mathbf{\vec u} $ 和 $\mathbf{\vec v}$ 的叉积垂直于 $\mathbf{\vec u},\mathbf{\vec v}$ 构成的平面,其方向符合右手规则。
- 叉积的模等于 $\mathbf{\vec u},\mathbf{\vec v}$ 构成的平行四边形的面积
- $\mathbf{\vec u}\times \mathbf{\vec v}=-\mathbf{\vec v}\times \mathbf{\vec u}$
- $\mathbf{\vec u}\times( \mathbf{\vec v} \times \mathbf{\vec w})=(\mathbf{\vec u}\cdot \mathbf{\vec w})\mathbf{\vec v}-(\mathbf{\vec u}\cdot \mathbf{\vec v})\mathbf{\vec w} $
<center>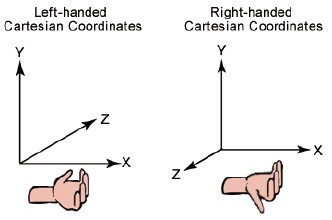</center>
5. 三维向量的混合积:
$$[\mathbf{\vec u} \;\mathbf{\vec v} \;\mathbf{\vec w}]=(\mathbf{\vec u}\times \mathbf{\vec v})\cdot \mathbf{\vec w}= \mathbf{\vec u}\cdot (\mathbf{\vec v} \times \mathbf{\vec w})\\ =\begin{vmatrix} u_x&u_y&u_z\\ v_x&v_y&v_z\\ w_x&w_y&w_z \end{vmatrix} =\begin{vmatrix} u_x&v_x&w_x\\ u_y&v_y&w_y\\ u_z&v_z&w_z\end{vmatrix} $$ 其物理意义为: $\mathbf{\vec u} ,\mathbf{\vec v} ,\mathbf{\vec w}$ 为三个棱边所围成的平行六面体的体积。 $\mathbf{\vec u} ,\mathbf{\vec v} ,\mathbf{\vec w}$ 构成右手系时,该平行六面体的体积为正号。
6. 两个向量的并矢:给定两个向 $\mathbf {\vec x}=(x_1,x_2,\cdots,x_n)^{T}, \mathbf {\vec y}= (y_1,y_2,\cdots,y_m)^{T}$ ,则向量的并矢记作:
$$\mathbf {\vec x}\mathbf {\vec y} =\begin{bmatrix}x_1y_1&x_1y_2&\cdots&x_1y_m\\ x_2y_1&x_2y_2&\cdots&x_2y_m\\ \vdots&\vdots&\ddots&\vdots\\ x_ny_1&x_ny_2&\cdots&x_ny_m\\ \end{bmatrix}$$ 也记 $\mathbf {\vec x}\otimes\mathbf {\vec y}$ 或 $\mathbf {\vec x} \mathbf {\vec y}^{T}$ 。
## 三、矩阵运算
1. 给定两个矩 $\mathbf A=(a_{i,j}) \in \mathbb R^{m\times n},\mathbf B=(b_{i,j}) \in \mathbb R^{m\times n}$ ,定义:
- 阿达马积`Hadamard product`(又称作逐元素积):
$$\mathbf A \circ \mathbf B =\begin{bmatrix} a_{1,1}b_{1,1}&a_{1,2}b_{1,2}&\cdots&a_{1,n}b_{1,n}\\ a_{2,1}b_{2,1}&a_{2,2}b_{2,2}&\cdots&a_{2,n}b_{2,n}\\ \vdots&\vdots&\ddots&\vdots\\ a_{m,1}b_{m,1}&a_{m,2}b_{m,2}&\cdots&a_{m,n}b_{m,n}\end{bmatrix}
$$\mathbf X = \begin{bmatrix}
x_{1,1}&x_{1,2}&\cdots&x_{1,n}\\
x_{2,1}&x_{2,2}&\cdots&x_{2,n}\\
\vdots&\vdots&\ddots&\vdots\\
x_{m,1}&x_{m,2}&\cdots&x_{m,n}\\
\end{bmatrix}$$ 简写为 $(x_{i,j})_{m\times n}$ 或 $[x_{i,j}]_{m\times n}$ 。
2. 矩阵的`F`范数:设矩 $\mathbf A=(a_{i,j})_{m\times n}$ ,则其`F`范数为 $||\mathbf A||_F=\sqrt{\sum_{i,j}a_{i,j}^{2}}$ 。
它是向量 $L_2$ 范数的推广。
3. 矩阵的迹:设矩 $\mathbf A=(a_{i,j})_{m\times n}$ , $ \mathbf A$ 的迹为 $tr(\mathbf A)=\sum_{i}a_{i,i}$ 。
迹的性质有:
- $\mathbf A$ 的`F` 范数等 $\mathbf A\mathbf A^T$ 的迹的平方根 $||\mathbf A||_F=\sqrt{tr(\mathbf A \mathbf A^{T})}$ 。
- $\mathbf A$ 的迹等 $\mathbf A^T$ 的迹 $tr(\mathbf A)=tr(\mathbf A^{T})$ 。
- 交换律:假设 $\mathbf A\in \mathbb R^{m\times n},\mathbf B\in \mathbb R^{n\times m}$ ,则有 $tr(\mathbf A\mathbf B)=tr(\mathbf B\mathbf A)$ 。
- 结合律 $tr(\mathbf A\mathbf B\mathbf C)=tr(\mathbf C\mathbf A\mathbf B)=tr(\mathbf B\mathbf C\mathbf A)$ 。
## 二、向量操作
1. 一组向 $\mathbf{\vec v}_1,\mathbf{\vec v}_2,\cdots,\mathbf{\vec v}_n$ 是线性相关的:指存在一组不全为零的实 $a_1,a_2,\cdots,a_n$ ,使得 $\sum_{i=1}^{n}a_i\mathbf{\vec v}_i=\mathbf{\vec 0}$ 。
一组向 $\mathbf{\vec v}_1,\mathbf{\vec v}_2,\cdots,\mathbf{\vec v}_n$ 是线性无关的,当且仅 $a_i=0,i=1,2,\cdots,n$ 时,才有 $\sum_{i=1}^{n}a_i\mathbf{\vec v}_i=\mathbf{\vec 0}$ 。
2. 一个向量空间所包含的最大线性无关向量的数目,称作该向量空间的维数。
3. 三维向量的点积 $\mathbf{\vec u}\cdot\mathbf{\vec v} =u _xv_x+u_yv_y+u_zv_z = |\mathbf{\vec u}| | \mathbf{\vec v}| \cos(\mathbf{\vec u},\mathbf{\vec v})$ 。
<center></center>
4. 三维向量的叉积:
$$\mathbf{\vec w}=\mathbf{\vec u}\times \mathbf{\vec v}=\begin{bmatrix}\mathbf{\vec i}& \mathbf{\vec j}&\mathbf{\vec k}\\ u_x&u_y&u_z\\ v_x&v_y&v_z\\ \end{bmatrix}$$ 其 $\mathbf{\vec i}, \mathbf{\vec j},\mathbf{\vec k}$ 分别 $x,y,z$ 轴的单位向量。
$$\mathbf{\vec u}=u_x\mathbf{\vec i}+u_y\mathbf{\vec j}+u_z\mathbf{\vec k},\quad \mathbf{\vec v}=v_x\mathbf{\vec i}+v_y\mathbf{\vec j}+v_z\mathbf{\vec k}$$
- $\mathbf{\vec u} $ 和 $\mathbf{\vec v}$ 的叉积垂直于 $\mathbf{\vec u},\mathbf{\vec v}$ 构成的平面,其方向符合右手规则。
- 叉积的模等于 $\mathbf{\vec u},\mathbf{\vec v}$ 构成的平行四边形的面积
- $\mathbf{\vec u}\times \mathbf{\vec v}=-\mathbf{\vec v}\times \mathbf{\vec u}$
- $\mathbf{\vec u}\times( \mathbf{\vec v} \times \mathbf{\vec w})=(\mathbf{\vec u}\cdot \mathbf{\vec w})\mathbf{\vec v}-(\mathbf{\vec u}\cdot \mathbf{\vec v})\mathbf{\vec w} $
<center></center>
5. 三维向量的混合积:
$$[\mathbf{\vec u} \;\mathbf{\vec v} \;\mathbf{\vec w}]=(\mathbf{\vec u}\times \mathbf{\vec v})\cdot \mathbf{\vec w}= \mathbf{\vec u}\cdot (\mathbf{\vec v} \times \mathbf{\vec w})\\ =\begin{vmatrix} u_x&u_y&u_z\\ v_x&v_y&v_z\\ w_x&w_y&w_z \end{vmatrix} =\begin{vmatrix} u_x&v_x&w_x\\ u_y&v_y&w_y\\ u_z&v_z&w_z\end{vmatrix} $$ 其物理意义为: $\mathbf{\vec u} ,\mathbf{\vec v} ,\mathbf{\vec w}$ 为三个棱边所围成的平行六面体的体积。 $\mathbf{\vec u} ,\mathbf{\vec v} ,\mathbf{\vec w}$ 构成右手系时,该平行六面体的体积为正号。
6. 两个向量的并矢:给定两个向 $\mathbf {\vec x}=(x_1,x_2,\cdots,x_n)^{T}, \mathbf {\vec y}= (y_1,y_2,\cdots,y_m)^{T}$ ,则向量的并矢记作:
$$\mathbf {\vec x}\mathbf {\vec y} =\begin{bmatrix}x_1y_1&x_1y_2&\cdots&x_1y_m\\ x_2y_1&x_2y_2&\cdots&x_2y_m\\ \vdots&\vdots&\ddots&\vdots\\ x_ny_1&x_ny_2&\cdots&x_ny_m\\ \end{bmatrix}$$ 也记 $\mathbf {\vec x}\otimes\mathbf {\vec y}$ 或 $\mathbf {\vec x} \mathbf {\vec y}^{T}$ 。
## 三、矩阵运算
1. 给定两个矩 $\mathbf A=(a_{i,j}) \in \mathbb R^{m\times n},\mathbf B=(b_{i,j}) \in \mathbb R^{m\times n}$ ,定义:
- 阿达马积`Hadamard product`(又称作逐元素积):
$$\mathbf A \circ \mathbf B =\begin{bmatrix} a_{1,1}b_{1,1}&a_{1,2}b_{1,2}&\cdots&a_{1,n}b_{1,n}\\ a_{2,1}b_{2,1}&a_{2,2}b_{2,2}&\cdots&a_{2,n}b_{2,n}\\ \vdots&\vdots&\ddots&\vdots\\ a_{m,1}b_{m,1}&a_{m,2}b_{m,2}&\cdots&a_{m,n}b_{m,n}\end{bmatrix}
- 克罗内积`Kronnecker product`:
A⊗B=[a1,1Ba1,2B⋯a1,nBa2,1Ba2,2B⋯a2,nB⋮⋮⋱⋮am,1Bam,2B⋯am,nB]
- →x,→a,→b,→c n 阶向量 A,B,C,X n 阶方阵,则有:
∂(→aT→x)∂→x=∂(→xT→a)∂→x=→a$$$$∂(→aTX→b)∂X=→a→bT=→a⊗→b∈Rn×n$$$$∂(→aTXT→b)∂X=→b→aT=→b⊗→a∈Rn×n$$$$∂(→aTX→a)∂X=∂(→aTXT→a)∂X=→a⊗→a$$$$∂(→aTXTX→b)∂X=X(→a⊗→b+→b⊗→a)$$$$∂[(A→x+→a)TC(B→x+→b)]∂→x=ATC(B→x+→b)+BTC(A→x+→a)$$$$∂(→xTA→x)∂→x=(A+AT)→x$$$$∂[(X→b+→c)TA(X→b+→c)]∂X=(A+AT)(X→b+→c)→bT$$$$∂(→bTXTAX→c)∂X=ATX→b→cT+AX→c→bT
- 如 f 是一元函数,则:
- 其逐元向量函数为 f(→x)=(f(x1),f(x2),⋯,f(xn))T 。
- 其逐矩阵函数为:
f(X)=[f(x1,1)f(x1,2)⋯f(x1,n)f(x2,1)f(x2,2)⋯f(x2,n)⋮⋮⋱⋮f(xm,1)f(xm,2)⋯f(xm,n)]
- 其逐元导数分别为:
f′(→x)=(f′(x1),f′(x2),⋯,f′(xn))Tf′(X)=[f′(x1,1)f′(x1,2)⋯f′(x1,n)f′(x2,1)f′(x2,2)⋯f′(x2,n)⋮⋮⋱⋮f′(xm,1)f′(xm,2)⋯f′(xm,n)]
- 各种类型的偏导数:
- 标量对标量的偏导数 ∂u∂v 。
- 标量对向量 n 维向量)的偏导数 ∂u∂→v=(∂u∂v1,∂u∂v2,⋯,∂u∂vn)T 。
- 标量对矩阵 m×n 阶矩阵)的偏导数:
∂u∂V=[∂u∂V1,1∂u∂V1,2⋯∂u∂V1,n∂u∂V2,1∂u∂V2,2⋯∂u∂V2,n⋮⋮⋱⋮∂u∂Vm,1∂u∂Vm,2⋯∂u∂Vm,n]
- 向量 $m$ 维向量)对标量的偏导数 $\frac{\partial \mathbf {\vec u}}{\partial v}=(\frac{\partial u_1}{\partial v},\frac{\partial u_2}{\partial v},\cdots,\frac{\partial u_m}{\partial v})^{T}$ 。
- 向量 $m$ 维向量)对向量 $n$ 维向量)的偏导数(雅可比矩阵,行优先)
∂→u∂→v=[∂u1∂v1∂u1∂v2⋯∂u1∂vn∂u2∂v1∂u2∂v2⋯∂u2∂vn⋮⋮⋱⋮∂um∂v1∂um∂v2⋯∂um∂vn]$$如果为列优先,则为上面矩阵的转置。−矩阵$m×n$阶矩阵)对标量的偏导数$$∂U∂v=[∂U1,1∂v∂U1,2∂v⋯∂U1,n∂v∂U2,1∂v∂U2,2∂v⋯∂U2,n∂v⋮⋮⋱⋮∂Um,1∂v∂Um,2∂v⋯∂Um,n∂v]
- 对于矩阵的迹,有下列偏导数成立:
∂[tr(f(X))]∂X=(f′(X))T$$$$∂[tr(AXB)]∂X=ATBT$$$$∂[tr(AXTB)]∂X=BA$$$$∂[tr(A⊗X)]∂X=tr(A)I$$$$∂[tr(AXBX)]∂X=ATXTBT+BTXAT$$$$∂[tr(XTBXC)]∂X=(BT+B)XCCT$$$$∂[tr(CTXTBXC)]∂X=BXC+BTXCT$$$$∂[tr(AXBXTC)]∂X=ATCTXBT+CAXB$$$$∂[tr((AXB+C)(AXB+C))]∂X=2AT(AXB+C)BT
- 假 U=f(X) 是关 X 的矩阵值函数 f:Rm×n→Rm×n ), g(U) 是关 U 的实值函数 g:Rm×n→R ),则下面链式法则成立:
∂g(U)∂X=(∂g(U)∂xi,j)m×n=[∂g(U)∂x1,1∂g(U)∂x1,2⋯∂g(U)∂x1,n∂g(U)∂x2,1∂g(U)∂x2,2⋯∂g(U)∂x2,n⋮⋮⋱⋮∂g(U)∂xm,1∂g(U)∂xm,2⋯∂g(U)∂xm,n]=(∑k∑l∂g(U)∂uk,l∂uk,l∂xi,j)m×n=(tr[(∂g(U)∂U)T∂U∂xi,j])m×n
概率论与随机过程
一、概率与分布
1.1 条件概率与独立事件
- 条件概率:已 A 事件发生的条件 B 发生的概率,记 P(B∣A) ,它等于事 AB 的概率相对于事 A 的概率,即:
P(B∣A)=P(AB)P(A)$$其中必须$P(A)>0$2.条件概率分布的链式法则:对$n$个随机变$x1,x2,⋯,xn$,有:$$P(x1,x2,⋯,xn)=P(x1)n∏i=2P(xi∣x1,⋯,xi−1)
- 两个随机变 x,y 相互独立的数学描述:
\forall x\in \mathcal X,\forall y\in \mathcal Y, P(\mathbf x=x,\mathbf y=y)=P(\mathbf x=x)P(\mathbf y=y)$$ 记作 $\mathbf x \bot \mathbf y$
4. 两个随机变 $\mathbf x,\mathbf y$ 关于随机变 $\mathbf z$ 条件独立的数学描述:
$$\forall x\in \mathcal X,\forall y\in \mathcal Y,\forall z \in\mathcal Z\\
P(\mathbf x=x,\mathbf y=y\mid \mathbf z=z)=P(\mathbf x=x\mid \mathbf z=z)P(\mathbf y=y\mid \mathbf z=z)$$ 记作 $\mathbf x \bot \mathbf y \mid \mathbf z$
### 1.2 联合概率分布
1. 定 ${\mathbf x}$ ${\mathbf y}$ 的联合分布为:
$$P(a,b)=P\{{\mathbf x} \le a, {\mathbf y} \le b\}, - \infty \lt a,b \lt + \infty
4. 两个随机变 $\mathbf x,\mathbf y$ 关于随机变 $\mathbf z$ 条件独立的数学描述:
$$\forall x\in \mathcal X,\forall y\in \mathcal Y,\forall z \in\mathcal Z\\
P(\mathbf x=x,\mathbf y=y\mid \mathbf z=z)=P(\mathbf x=x\mid \mathbf z=z)P(\mathbf y=y\mid \mathbf z=z)$$ 记作 $\mathbf x \bot \mathbf y \mid \mathbf z$
### 1.2 联合概率分布
1. 定 ${\mathbf x}$ ${\mathbf y}$ 的联合分布为:
$$P(a,b)=P\{{\mathbf x} \le a, {\mathbf y} \le b\}, - \infty \lt a,b \lt + \infty
- x 的分布可以从联合分布中得到:
Px(a)=P{x≤a}=P{x≤a,y≤∞}=P(a,∞),−∞<a<+∞$$类似的$y$的分布可以从联合分布中得到:$$Py(b)=P{y≤b}=P{x≤∞,y≤b}=P(∞,b),−∞<b<+∞
- x y 都是离散随机变量时,定 x y 的联合概率质量函数为 p(x,y)=P{x=x,y=y}
x y 的概率质量函数分布为:
px(x)=∑y:p(x,y)>0p(x,y)py(y)=∑x:p(x,y)>0p(x,y)
- x y 联合地连续时,即存在函 p(x,y) ,使得对于所有的实数集 A B 满足:
P{x∈A,y∈B}=∫B∫Ap(x,y)dxdy$$则函$p(x,y)$称$x$$y$的概率密度函数。−联合分布为$$P(a,b)=P{x≤a,y≤b}=∫a−∞∫b−∞p(x,y)dxdy
- ${\mathbf x}$ ${\mathbf y}$ 的概率密度函数以及分布函数分别为:
Px(a)=∫a−∞∫∞−∞p(x,y)dxdy=∫a−∞px(x)dxPy(b)=∫∞−∞∫b−∞p(x,y)dxdy=∫b−∞py(y)dypx(x)=∫∞−∞p(x,y)dypy(y)=∫∞−∞p(x,y)dx
二、期望
- 期望:(是概率分布的泛函,函数的函数)
- 离散型随机变 x 的期望:
E[x]=∞∑i=1xipi
- 若级数不收敛,则期望不存在
- 连续性随机变 ${\mathbf x}$ 的期望:
E[x]=∫∞−∞xp(x)dx
- 若极限不收敛,则期望不存在
- 期望描述了随机变量的平均情况,衡量了随机变 x 的均值
- 定理: y=g(x) 均为随机变量 g(⋅) 是连续函数
- x 为离散型随机变量, y 的期望存在,则:
E[y]=E[g(x)]=∞∑i=1g(xi)pi
- ${\mathbf x}$ 为连续型随机变量, ${\mathbf y}$ 的期望存在,则:
E[y]=E[g(x)]=∫∞−∞g(x)p(x)dx$$该定理的意义在于:当$E(y)$时,不必计算$y$的分布,只需要利$x$的分布即可。该定理可以推广至两个或者两个以上随机变量的情况。此时:$$E[Z]=E[g(x,y)]=∫∞−∞∫∞−∞g(x,y)p(x,y)dxdy
上述公式也记做:
Ex∼P[g(x)]=∑xg(x)p(x)Ex∼P[g(x)]=∫g(x)p(x)dxEx,y∼P[g(x)]∫g(x,y)p(x,y)dxdy
- 期望性质:
- 常数的期望就是常数本身
- 对常 C 有:
E[Cx]=CE[x]
- 对两个随机变 ${\mathbf x},{\mathbf y}$ ,有:
E[x+y]=E[x]+E[y]
- 该结论可以推广到任意有限个随机变量之和的情况
- 对两个相互独立的随机变量,有:
E[xy]=E[x]E[y]
- 该结论可以推广到任意有限个相互独立的随机变量之积的情况
三、方差
3.1 方差
- 对随机变 x , E[(x−E[x])2] 存在,则称它 x 的方差,记 Var[x] x 的标准差为方差的开平方。即:
Var[x]=E[(x−E[x])2]σ=√Var[x]
- 方差度量了随机变量 ${\mathbf x}$ 与期望值偏离的程度,衡量了 ${\mathbf x}$ 取值分散程度的一个尺度。
- 由于绝对值 $|{\mathbf x}-\mathbb E[{\mathbf x}] |$ 带有绝对值,不方便运算,因此采用平方来计算。又因为 $|{\mathbf x}-\mathbb E[{\mathbf x}]|^2$ 是一个随机变量,因此对它取期望,即得 ${\mathbf x}$ 与期望值偏离的均值
- 根据定义可知:
Var[x]=E[(x−E[x])2]=E[x2]−(E[x])2Var[f(x)]=E[(f(x)−E[f(x)])2]
- 对于一个期望 μ ,方差 σ2,σ≠0 的随机变 x ,随机变 x∗=x−μσ 的数学期望为0,方差为1。 x∗ x 的标准化变量
- 方差的性质:
- 常数的方差恒为0
- 对常 C Var[Cx]=C2Var[x]
- 对两个随机变 x,y ,有 Var[x+y]=Var[x]+Var[y]+2E[(x−E[x])(y−E[y])]
- 当 x 和 y 相互独立时,有 Var[x+y]=Var[x]+Var[y] 。可以推广至任意有限多个相互独立的随机变量之和的情况
- Var[x]=0 的充要条件 x 以概率1取常数
3.2 协方差与相关系数
- 对于二维随机变 (x,y) ,可以讨论描 x y 之间相互关系的数字特征。
- 定义 E[(x−E[x])(y−E[y])] 为随机变量 x 与 y 的协方差,记作 Cov[x,y]=E[(x−E[x])(y−E[y])] 。
- 定义 ρxy=Cov[x,y]√Var[x]√Var[y] 为随机变量 x 与 y 的相关系数,它是协方差的归一化。
- 由定义可知:
Cov[ {\mathbf x},{\mathbf y}] =Cov[ {\mathbf y},{\mathbf x}] \\
Cov [{\mathbf x},{\mathbf x}] =Var [{\mathbf x}] \\
Var [{\mathbf x}+{\mathbf y}] =Var [{\mathbf x}] +Var [{\mathbf y}] +2Cov [{\mathbf x},{\mathbf y}] $$
3. 协方差的性质:
- $Cov [a{\mathbf x},b{\mathbf y}] =abCov [{\mathbf x},{\mathbf y}] $ , $a,b$ 为常数
- $Cov[ {\mathbf x}_1+{\mathbf x}_2,{\mathbf y} ]=Cov [{\mathbf x}_1,{\mathbf y}] +Cov [{\mathbf x}_2,{\mathbf y}] $
- $Cov [f(\mathbf x),g(\mathbf y)]=\mathbb E[(f(\mathbf x)-\mathbb E[f(\mathbf x)])(g(\mathbf y)-\mathbb E[g(\mathbf y)])]$
- $\rho[f(\mathbf x),g(\mathbf y)]=\frac {Cov[f(\mathbf x),g(\mathbf y)]}{\sqrt{Var[f(\mathbf x)] }\sqrt{Var[g(\mathbf y)]}}$
4. 协方差的物理意义:
- 协方差的绝对值越大,说明两个随机变量都远离它们的均值。
- 协方差如果为正,则说明两个随机变量同时趋向于取较大的值;如果为负,则说明一个随变量趋向于取较大的值,另一个随机变量趋向于取较小的值
- 两个随机变量的独立性可以导出协方差为零。但是两个随机变量的协方差为零无法导出独立性
- 因为独立性也包括:没有非线性关系。有可能两个随机变量是非独立的,但是协方差为零
- 假设随机变 $\mathbf x\sim U[-1,1]$ 。定义随机变 $\mathbf s$ 的概率分布函数为:
$$P(\mathbf s=1)= \frac 12P(\mathbf s=-1)= \frac 12 $$ 定义随机变 $\mathbf y=\mathbf {sx}$ ,则随机变 $\mathbf x,\mathbf y$ 是非独立的,但是有 $Cov[\mathbf x,\mathbf y]=0$
5. 相关系数的物理意义:考虑以随机变 ${\mathbf x}$ 的线性函 $a+b{\mathbf x}$ 来近似表 ${\mathbf y}$ 。以均方误差
$$e=\mathbb E[({\mathbf y}-(a+b{\mathbf x}))^{2}]=\mathbb E[{\mathbf y}^{2}] +b^{2}\mathbb E[{\mathbf x}^{2}] +a^{2}-2b\mathbb E[{\mathbf x}{\mathbf y}] +2ab\mathbb E[{\mathbf x}] -2a\mathbb E [{\mathbf y}] $$ 来衡量 $a+b{\mathbf x}$ 近似表 ${\mathbf y}$ 的好坏程度 $e$ 越小表示近似程度越高。为求得
最好的近似,则 $a,b$ 分别取偏导数,得到:
$$a_0=\mathbb E[{\mathbf y}] -b_0\mathbb E[{\mathbf x}] =\mathbb E[{\mathbf y}] -\mathbb E[{\mathbf x}] \frac{Cov [{\mathbf x},{\mathbf y}]}{Var [{\mathbf x}] }\\
b_0=\frac{Cov[ {\mathbf x},{\mathbf y}] }{Var[ {\mathbf x}] }\\
\min(e)=\mathbb E[({\mathbf y}-(a_0+b_0{\mathbf x}))^{2}]=(1-\rho^{2}_{{\mathbf x}{\mathbf y}})Var [{\mathbf y}] $$ 因此有以下定理:
- $|\rho_{{\mathbf x}{\mathbf y}}| \le 1$ $|...|$ 是绝对值)
- $|\rho_{{\mathbf x}{\mathbf y}}| = 1$ 的充要条件是,存在常数 $a,b$ 使得 $P\{{\mathbf y}=a+b{\mathbf x}\}=1$
> $|\rho_{{\mathbf x}{\mathbf y}}|$ 较大时 $e$ 较小,表明随机变 ${\mathbf x}$ ${\mathbf y}$ 联系较紧密,于 $\rho_{{\mathbf x}{\mathbf y}}$ 是一个表 ${\mathbf x}$ ${\mathbf y}$ 之间线性关系紧密程度的量。
6. $\rho_{{\mathbf x}{\mathbf y}}=0$ 时, ${\mathbf x}$ ${\mathbf y}$ 不相关。
- 不相关是就线性关系来讲的,而相互独立是一般关系而言的。
- 相互独立一定不相关;不相关则未必独立。
### 3.3 协方差矩阵
1. 矩: ${\mathbf x}$ ${\mathbf y}$ 是随机变量
- 若 $\mathbb E[{\mathbf x}^{k}] ,k=1,2,\cdots$ 存在,则称它为 ${\mathbf x}$ 的 $k$ 阶原点矩,简称 $k$ 阶矩
- 若 $\mathbb E[({\mathbf x}-\mathbb E[{\mathbf x}])^{k}] ,k=2,3,\cdots$ 存在,则称它为 ${\mathbf x}$ 的 $k$ 阶中心矩
- 若 $\mathbb E[{\mathbf x}^{k}{\mathbf y}^{l}] ,k,l=1,2,\cdots$ 存在,则称它为 ${\mathbf x}$ 和 ${\mathbf y}$ 的 $ k+l$ 阶混合矩
- 若 $\mathbb E[({\mathbf x}-\mathbb E[{\mathbf x}])^{k}({\mathbf y}-\mathbb E[{\mathbf y}])^{l}] ,k,l=1,2,\cdots$ 存在,则称它为 ${\mathbf x}$ 和 ${\mathbf y}$ 的 $k+l$ 阶混合中心矩
因此期望是一阶原点矩,方差是二阶中心矩,协方差是二阶混合中心矩
2. 协方差矩阵:二维随机变 $({\mathbf x}_1,{\mathbf x}_2)$ 有四个二阶中心矩(设他们都存在),记作:
$$\begin{align}
c_{11}&=\mathbb E[({\mathbf x}_1-\mathbb E[{\mathbf x}_1])^{2}] \\
c_{12}&=\mathbb E[({\mathbf x}_1-\mathbb E[{\mathbf x}_1])( {\mathbf x}_2-\mathbb E[{\mathbf x}_2]) ] \\
c_{21}&=\mathbb E[( {\mathbf x}_2-\mathbb E[{\mathbf x}_2])({\mathbf x}_1-\mathbb E[{\mathbf x}_1] ) ] \\
c_{22}&=\mathbb E[({\mathbf x}_2-\mathbb E[{\mathbf x}_2])^{2}] \\
\end{align}$$ 这个矩阵称作随机变 $({\mathbf x}_1,{\mathbf x}_2)$ 的协方差矩阵。
$n$ 维随机变 $({\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n)$ 的二阶混合中心 $c_{ij}=Cov [{\mathbf x}_i,{\mathbf x}_j] =\mathbb E[({\mathbf x}_i-\mathbb E[{\mathbf x}_i] )( {\mathbf x}_j-\mathbb E[{\mathbf x}_j] ) ] ,i,j=1,2,\cdots,n$ ,都存在,则称矩阵
$$\mathbf C=
\begin{bmatrix}
c_{11} & c_{12} & \cdots & c_{1n} \\
c_{21} & c_{22} & \cdots & c_{2n} \\
\vdots &\vdots &\ddots &\vdots \\
c_{n1} & c_{n2} & \cdots & c_{nn} \\
\end{bmatrix}$$ $n$ 维随机变 $({\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n)$ 的协方差矩阵。
- 由于 $c_{ij}=c_{ji}, i\ne j, i,j=1,2,\cdots,n$ 因此协方差矩阵是个对称阵
> 通 $n$ 维随机变量的分布是不知道的,或者太复杂以致数学上不容易处理。因此实际中协方差矩阵非常重要。
## 四、大数定律及中心极限定理
### 4.1 切比雪夫不等式
1. 切比雪夫不等式:随机变 ${\mathbf x}$ 具有期 $\mathbb E[{\mathbf x}] =\mu$ ,方 $Var({\mathbf x})=\sigma^{2}$ ,对于任意正 $\varepsilon$ ,不等式
$$P\{|{\mathbf x}-\mu| \ge \varepsilon\} \le \frac {\sigma^{2}}{\varepsilon^{2}}$$ 成立
> 其意义是:对于距 $\mathbb E[{\mathbf x}] $ 足够远的地方(距离大于等 $\varepsilon$ ),事件出现的概率是小于等 $ \frac {\sigma^{2}}{\varepsilon^{2}}$ ;即事件出现在区 $[\mu-\varepsilon , \mu+\varepsilon]$ 的概率大 $1- \frac {\sigma^{2}}{\varepsilon^{2}}$
> 该不等式给出了随机变 ${\mathbf x}$ 在分布未知的情况下,事 $\{|{\mathbf x}-\mu| \le \varepsilon\}$ 的下限估计( $P\{|{\mathbf x}-\mu| \lt 3\sigma\} \ge 0.8889$
证明:
$$P\{|{\mathbf x}-\mu| \ge \varepsilon\}=\int_{|x-\mu| \ge \varepsilon}p(x)dx \le \int_{|x-\mu| \ge \varepsilon} \frac{|x-\mu|^{2}}{\varepsilon^{2}}p(x)dx \\
\le \frac {1}{\varepsilon^{2}}\int_{-\infty}^{\infty}(x-\mu)^{2}p(x)dx=\frac{\sigma^{2}}{\varepsilon^{2}}
Cov [{\mathbf x},{\mathbf x}] =Var [{\mathbf x}] \\
Var [{\mathbf x}+{\mathbf y}] =Var [{\mathbf x}] +Var [{\mathbf y}] +2Cov [{\mathbf x},{\mathbf y}] $$
3. 协方差的性质:
- $Cov [a{\mathbf x},b{\mathbf y}] =abCov [{\mathbf x},{\mathbf y}] $ , $a,b$ 为常数
- $Cov[ {\mathbf x}_1+{\mathbf x}_2,{\mathbf y} ]=Cov [{\mathbf x}_1,{\mathbf y}] +Cov [{\mathbf x}_2,{\mathbf y}] $
- $Cov [f(\mathbf x),g(\mathbf y)]=\mathbb E[(f(\mathbf x)-\mathbb E[f(\mathbf x)])(g(\mathbf y)-\mathbb E[g(\mathbf y)])]$
- $\rho[f(\mathbf x),g(\mathbf y)]=\frac {Cov[f(\mathbf x),g(\mathbf y)]}{\sqrt{Var[f(\mathbf x)] }\sqrt{Var[g(\mathbf y)]}}$
4. 协方差的物理意义:
- 协方差的绝对值越大,说明两个随机变量都远离它们的均值。
- 协方差如果为正,则说明两个随机变量同时趋向于取较大的值;如果为负,则说明一个随变量趋向于取较大的值,另一个随机变量趋向于取较小的值
- 两个随机变量的独立性可以导出协方差为零。但是两个随机变量的协方差为零无法导出独立性
- 因为独立性也包括:没有非线性关系。有可能两个随机变量是非独立的,但是协方差为零
- 假设随机变 $\mathbf x\sim U[-1,1]$ 。定义随机变 $\mathbf s$ 的概率分布函数为:
$$P(\mathbf s=1)= \frac 12P(\mathbf s=-1)= \frac 12 $$ 定义随机变 $\mathbf y=\mathbf {sx}$ ,则随机变 $\mathbf x,\mathbf y$ 是非独立的,但是有 $Cov[\mathbf x,\mathbf y]=0$
5. 相关系数的物理意义:考虑以随机变 ${\mathbf x}$ 的线性函 $a+b{\mathbf x}$ 来近似表 ${\mathbf y}$ 。以均方误差
$$e=\mathbb E[({\mathbf y}-(a+b{\mathbf x}))^{2}]=\mathbb E[{\mathbf y}^{2}] +b^{2}\mathbb E[{\mathbf x}^{2}] +a^{2}-2b\mathbb E[{\mathbf x}{\mathbf y}] +2ab\mathbb E[{\mathbf x}] -2a\mathbb E [{\mathbf y}] $$ 来衡量 $a+b{\mathbf x}$ 近似表 ${\mathbf y}$ 的好坏程度 $e$ 越小表示近似程度越高。为求得
最好的近似,则 $a,b$ 分别取偏导数,得到:
$$a_0=\mathbb E[{\mathbf y}] -b_0\mathbb E[{\mathbf x}] =\mathbb E[{\mathbf y}] -\mathbb E[{\mathbf x}] \frac{Cov [{\mathbf x},{\mathbf y}]}{Var [{\mathbf x}] }\\
b_0=\frac{Cov[ {\mathbf x},{\mathbf y}] }{Var[ {\mathbf x}] }\\
\min(e)=\mathbb E[({\mathbf y}-(a_0+b_0{\mathbf x}))^{2}]=(1-\rho^{2}_{{\mathbf x}{\mathbf y}})Var [{\mathbf y}] $$ 因此有以下定理:
- $|\rho_{{\mathbf x}{\mathbf y}}| \le 1$ $|...|$ 是绝对值)
- $|\rho_{{\mathbf x}{\mathbf y}}| = 1$ 的充要条件是,存在常数 $a,b$ 使得 $P\{{\mathbf y}=a+b{\mathbf x}\}=1$
> $|\rho_{{\mathbf x}{\mathbf y}}|$ 较大时 $e$ 较小,表明随机变 ${\mathbf x}$ ${\mathbf y}$ 联系较紧密,于 $\rho_{{\mathbf x}{\mathbf y}}$ 是一个表 ${\mathbf x}$ ${\mathbf y}$ 之间线性关系紧密程度的量。
6. $\rho_{{\mathbf x}{\mathbf y}}=0$ 时, ${\mathbf x}$ ${\mathbf y}$ 不相关。
- 不相关是就线性关系来讲的,而相互独立是一般关系而言的。
- 相互独立一定不相关;不相关则未必独立。
### 3.3 协方差矩阵
1. 矩: ${\mathbf x}$ ${\mathbf y}$ 是随机变量
- 若 $\mathbb E[{\mathbf x}^{k}] ,k=1,2,\cdots$ 存在,则称它为 ${\mathbf x}$ 的 $k$ 阶原点矩,简称 $k$ 阶矩
- 若 $\mathbb E[({\mathbf x}-\mathbb E[{\mathbf x}])^{k}] ,k=2,3,\cdots$ 存在,则称它为 ${\mathbf x}$ 的 $k$ 阶中心矩
- 若 $\mathbb E[{\mathbf x}^{k}{\mathbf y}^{l}] ,k,l=1,2,\cdots$ 存在,则称它为 ${\mathbf x}$ 和 ${\mathbf y}$ 的 $ k+l$ 阶混合矩
- 若 $\mathbb E[({\mathbf x}-\mathbb E[{\mathbf x}])^{k}({\mathbf y}-\mathbb E[{\mathbf y}])^{l}] ,k,l=1,2,\cdots$ 存在,则称它为 ${\mathbf x}$ 和 ${\mathbf y}$ 的 $k+l$ 阶混合中心矩
因此期望是一阶原点矩,方差是二阶中心矩,协方差是二阶混合中心矩
2. 协方差矩阵:二维随机变 $({\mathbf x}_1,{\mathbf x}_2)$ 有四个二阶中心矩(设他们都存在),记作:
$$\begin{align}
c_{11}&=\mathbb E[({\mathbf x}_1-\mathbb E[{\mathbf x}_1])^{2}] \\
c_{12}&=\mathbb E[({\mathbf x}_1-\mathbb E[{\mathbf x}_1])( {\mathbf x}_2-\mathbb E[{\mathbf x}_2]) ] \\
c_{21}&=\mathbb E[( {\mathbf x}_2-\mathbb E[{\mathbf x}_2])({\mathbf x}_1-\mathbb E[{\mathbf x}_1] ) ] \\
c_{22}&=\mathbb E[({\mathbf x}_2-\mathbb E[{\mathbf x}_2])^{2}] \\
\end{align}$$ 这个矩阵称作随机变 $({\mathbf x}_1,{\mathbf x}_2)$ 的协方差矩阵。
$n$ 维随机变 $({\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n)$ 的二阶混合中心 $c_{ij}=Cov [{\mathbf x}_i,{\mathbf x}_j] =\mathbb E[({\mathbf x}_i-\mathbb E[{\mathbf x}_i] )( {\mathbf x}_j-\mathbb E[{\mathbf x}_j] ) ] ,i,j=1,2,\cdots,n$ ,都存在,则称矩阵
$$\mathbf C=
\begin{bmatrix}
c_{11} & c_{12} & \cdots & c_{1n} \\
c_{21} & c_{22} & \cdots & c_{2n} \\
\vdots &\vdots &\ddots &\vdots \\
c_{n1} & c_{n2} & \cdots & c_{nn} \\
\end{bmatrix}$$ $n$ 维随机变 $({\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n)$ 的协方差矩阵。
- 由于 $c_{ij}=c_{ji}, i\ne j, i,j=1,2,\cdots,n$ 因此协方差矩阵是个对称阵
> 通 $n$ 维随机变量的分布是不知道的,或者太复杂以致数学上不容易处理。因此实际中协方差矩阵非常重要。
## 四、大数定律及中心极限定理
### 4.1 切比雪夫不等式
1. 切比雪夫不等式:随机变 ${\mathbf x}$ 具有期 $\mathbb E[{\mathbf x}] =\mu$ ,方 $Var({\mathbf x})=\sigma^{2}$ ,对于任意正 $\varepsilon$ ,不等式
$$P\{|{\mathbf x}-\mu| \ge \varepsilon\} \le \frac {\sigma^{2}}{\varepsilon^{2}}$$ 成立
> 其意义是:对于距 $\mathbb E[{\mathbf x}] $ 足够远的地方(距离大于等 $\varepsilon$ ),事件出现的概率是小于等 $ \frac {\sigma^{2}}{\varepsilon^{2}}$ ;即事件出现在区 $[\mu-\varepsilon , \mu+\varepsilon]$ 的概率大 $1- \frac {\sigma^{2}}{\varepsilon^{2}}$
> 该不等式给出了随机变 ${\mathbf x}$ 在分布未知的情况下,事 $\{|{\mathbf x}-\mu| \le \varepsilon\}$ 的下限估计( $P\{|{\mathbf x}-\mu| \lt 3\sigma\} \ge 0.8889$
证明:
$$P\{|{\mathbf x}-\mu| \ge \varepsilon\}=\int_{|x-\mu| \ge \varepsilon}p(x)dx \le \int_{|x-\mu| \ge \varepsilon} \frac{|x-\mu|^{2}}{\varepsilon^{2}}p(x)dx \\
\le \frac {1}{\varepsilon^{2}}\int_{-\infty}^{\infty}(x-\mu)^{2}p(x)dx=\frac{\sigma^{2}}{\varepsilon^{2}}
- 切比雪夫不等式的特殊情况:设随机变 x1,x2,⋯,xn,⋯ 相互独立,且具有相同的数学期望和方差 E[xk]=μ,Var[xk]=σ2,k=1,2,⋯ 。作 n 个随机变量的算术平均 ¯x=1n∑nk=1xk ,则对于任意正 ε 有:
\lim_{n\rightarrow \infty}P\{|\overline {\mathbf x}-\mu| \lt \varepsilon\}=\lim_{n\rightarrow \infty}P\{|\frac{1}{n}\sum_{k=1}^{n}{\mathbf x}_k-\mu| \lt \varepsilon\} =1$$ 证明:
$$\mathbb E[\frac{1}{n}\sum_{k=1}^{n}{\mathbf x}_k]=\mu\\
Var[\frac{1}{n}\sum_{k=1}^{n}{\mathbf x}_k]=\frac{\sigma^{2}}{n}$$ 有切比雪夫不等式,以 $n$ 趋于无穷时,可以证明。详细过程省略
### 4.2 大数定理
1. 依概率收敛: ${\mathbf y}_1,{\mathbf y}_2,\cdots,{\mathbf y}_n,\cdots$ 是一个随机变量序列 $a$ 是一个常数。若对于任意正 $ \varepsilon$ 有 $\lim_{n\rightarrow \infty}P\{|{\mathbf y}_{n}-a| \le \varepsilon \}=1$ ,则称序 ${\mathbf y}_1,{\mathbf y}_2,\cdots,{\mathbf y}_n,\cdots$ 依概率收敛 $a$ 。记作 ${\mathbf y}_{n} \stackrel{P}{\rightarrow} a$
2. 依概率收敛的两个含义:
- 收敛:表明这是一个随机变量序列,而不是某个随机变量;且序列是无限长,而不是有限长
- 依概率:表明序列无穷远处的随机变量 ${\mathbf y}_{\infty}$ 的分布规律为:绝大部分分布于点 $a$ ,极少数位于 $a$ 之外。且分布于 $a$ 之外的事件发生的概率之和为0
3. 大数定理一:设随机变 ${\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n,\cdots$ 相互独立,且具有相同的数学期望和方差 $ \mathbb E[{\mathbf x}_k] =\mu, Var[{\mathbf x}_k] =\sigma^{2},k=1,2,\cdots$ 。则序列 $ \overline {\mathbf x} =\frac {1}{n} \sum _{k=1}^{n}{\mathbf x}_k$ 依概率收敛 $\mu$ , $\overline {\mathbf x} \stackrel{P}{\rightarrow} \mu$
- 这里并没有要求随机变量 ${\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n,\cdots$ 同分布
4. 伯努利大数定理: $n_A$ $n$ 次独立重复实验中事 $A$ 发生的次数 $p$ 是事 $A$ 在每次试验中发生的概率。则对于任意正 $ \varepsilon$ 有:
$$\lim_{n \rightarrow \infty}P\{|\frac{n_{A}}{n}-p| \lt \varepsilon\}=1 \\
or: \quad \lim_{n \rightarrow \infty}P\{|\frac{n_{A}}{n}-p| \ge \varepsilon\}=0
$$\mathbb E[\frac{1}{n}\sum_{k=1}^{n}{\mathbf x}_k]=\mu\\
Var[\frac{1}{n}\sum_{k=1}^{n}{\mathbf x}_k]=\frac{\sigma^{2}}{n}$$ 有切比雪夫不等式,以 $n$ 趋于无穷时,可以证明。详细过程省略
### 4.2 大数定理
1. 依概率收敛: ${\mathbf y}_1,{\mathbf y}_2,\cdots,{\mathbf y}_n,\cdots$ 是一个随机变量序列 $a$ 是一个常数。若对于任意正 $ \varepsilon$ 有 $\lim_{n\rightarrow \infty}P\{|{\mathbf y}_{n}-a| \le \varepsilon \}=1$ ,则称序 ${\mathbf y}_1,{\mathbf y}_2,\cdots,{\mathbf y}_n,\cdots$ 依概率收敛 $a$ 。记作 ${\mathbf y}_{n} \stackrel{P}{\rightarrow} a$
2. 依概率收敛的两个含义:
- 收敛:表明这是一个随机变量序列,而不是某个随机变量;且序列是无限长,而不是有限长
- 依概率:表明序列无穷远处的随机变量 ${\mathbf y}_{\infty}$ 的分布规律为:绝大部分分布于点 $a$ ,极少数位于 $a$ 之外。且分布于 $a$ 之外的事件发生的概率之和为0
3. 大数定理一:设随机变 ${\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n,\cdots$ 相互独立,且具有相同的数学期望和方差 $ \mathbb E[{\mathbf x}_k] =\mu, Var[{\mathbf x}_k] =\sigma^{2},k=1,2,\cdots$ 。则序列 $ \overline {\mathbf x} =\frac {1}{n} \sum _{k=1}^{n}{\mathbf x}_k$ 依概率收敛 $\mu$ , $\overline {\mathbf x} \stackrel{P}{\rightarrow} \mu$
- 这里并没有要求随机变量 ${\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n,\cdots$ 同分布
4. 伯努利大数定理: $n_A$ $n$ 次独立重复实验中事 $A$ 发生的次数 $p$ 是事 $A$ 在每次试验中发生的概率。则对于任意正 $ \varepsilon$ 有:
$$\lim_{n \rightarrow \infty}P\{|\frac{n_{A}}{n}-p| \lt \varepsilon\}=1 \\
or: \quad \lim_{n \rightarrow \infty}P\{|\frac{n_{A}}{n}-p| \ge \varepsilon\}=0
- 即:当独立重复实验执行非常大的次数时,事件 $A$ 发生的频率逼近于它的概率
- 辛钦定理:设随机变 x1,x2,⋯,xn,⋯ 相互独立,服从同一分布,且具有相同的数学期望 E[xk]=μ,k=1,2,⋯ 。则对于任意正 ε 有:
limn→∞P{|1nn∑k=1xk−μ|<ε}=1
- 这里并没有要求随机变量 ${\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n,\cdots$ 的方差存在
- 伯努利大数定理是亲钦定理的特殊情况。
4.3 中心极限定理
- 独立同分布的中心极限定理:设随机变 x1,x2,⋯,xn 独立同分布,且具有数学期望和方差 E[xk]=μ,Var[xk]=σ2>0,k=1,2,⋯ ,则随机变量之 ¯Sxn=∑nk=1xk 的标准变化量:
yn=¯Sxn−E[¯Sxn]√Var[¯Sxn]=¯Sxn−nμ√nσ$$的概率分布函$Fn(x)$对于任$x$满足:$$limn→∞Fn(x)=limn→∞P{yn≤x}=limn→∞P{∑nk=1xk−nμ√nσ≤x}=∫x−∞1√2πe−t2/2dt=Φ(x)
- 其物理意义为:均值方差为 $\mu,\sigma^{2}$ 的独立同分布的随机变量 ${\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n$ 之和 $\overline {S{\mathbf x}_n}=\sum_{k=1}^{n} {\mathbf x}_k$ 的标准变化量 ${\mathbf y}_n$ ,当 $n$ 充分大时,其分布近似与标准正态分布。即 $\overline {S{\mathbf x}_n}=\sum_{k=1}^{n} {\mathbf x}_k$ 在 $n$ 充分大时,其分布近似于 $N(n\mu,n\sigma^{2})$
- 一般情况下,很难求出 $n$ 个随机变量之和的分布函数。因此当 $n$ 充分大时,可以通过正态分布来做理论上的分析或者计算。
- Liapunov定理:设随机变 x1,x2,⋯,xn,⋯ 相互独立,具有数学期望和方差 E[xk]=μk,Var[xk]=σ2k>0,k=1,2,⋯ ,记 B2n=∑nk=1σ2k 。
若存在正 δ ,使得 n→∞ 时,
1B2+δnn∑k=1E[|xk−μk|2+δ]→0$$则随机变量之$¯Sxn=n∑k=1xk$的标准变化量:$$Zn=¯Sxn−E[¯Sxn]√Var[¯Sxn]=¯Sxn−∑nk=1μkBn$$的概率分布函$Fn(x)$对于任$x$满足:$$limn→∞Fn(x)=limn→∞P{Zn≤x}=limn→∞P{∑nk=1xk−∑nk=1μkBn≤x}=∫x−∞1√2πe−t2/2dt=Φ(x)
- 其物理意义为:相互独立的随机变量 ${\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n,\cdots$ 之和 $\overline {S{\mathbf x}_n}=\sum_{k=1}^{n} {\mathbf x}_k$ 的衍生随机变量序 $Z_n=\frac{\overline {S{\mathbf x}_n}-\sum_{k=1}^{n}\mu_k}{B_n}$ ,当 $n$ 充分大时,其分布近似与标准正态分布。
- 这里并不要求 ${\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n,\cdots$ 同分布
- Demoiver-Laplace定理:设随机变量序 ηn,n=1,2,... 服从参数 n,p(0<p<1) 的二项分布,则对于任 x ,有:
limn→∞P{ηn−np√np(1−p)≤x}=∫x−∞1√2πe−t2∣2dt=Φ(x)
- 该定理表明,正态分布是二项分布的极限分布。当 $n$ 充分大时,可以利用正态分布来计算二项分布的概率。
五、不确定性来源
- 机器学习中不确定性有三个来源:
- 模型本身固有的随机性。如量子力学中的粒子动力学方程。
- 不完全的观测。即使是确定性系统,当无法观测所有驱动变量时,结果也是随机的。
- 不完全建模。有时必须放弃一些观测信息。
- 如机器人建模中:虽然可以精确观察机器人周围每个对象的位置;但在预测这些对象将来的位置时,对空间进行了离散化。则位置预测将带有不确定性。
六、常见概率分布
6.1 均匀分布
- 离散随机变量的均匀分布:假 x k 个取值 x1,x2,⋯,xk ,则均匀分布的概率密度函数(
probability mass function:PMF)为:
P(x=xi)=1k,i=1,2,⋯,k
- 连续随机变量的均匀分布:假 x 在
[a,b]上均匀分布,则其概率密度函数(probability density function:PDF)为:
p(x=x)={0,x∉[a,b]1b−a,x∈[a,b]
6.2 二项分布
- 伯努利分布(二项分布):参数 ϕ∈[0,1] 。随机变 x∈{0,1}
- 概率分布函数为:
P(x=x)=ϕx(1−ϕ)1−x,x∈{0,1}
- 期望: $\mathbb E_{\mathbf x}[x]=\phi$
- 方差: $Var_{\mathbf x}[x]=\phi(1-\phi)$
categorical分布:它是二项分布的推广,也称作multinoulli分布。假设随机变 x∈{1,2,⋯,K} ,其概率分布函数为:
P(\mathbf x=1)=\theta_1\\
P(\mathbf x=2)=\theta_2\\
\vdots\\
P(\mathbf x=K-1)=\theta_{K-1}\\
P(\mathbf x=K)=1-\sum_{i=1}^{K-1}\theta_i \\$$ 其 $\theta_i$ 为参数,它满 $\theta_i \in [0,1]$ , $\sum_{i=1}^{K-1}\theta_i \in [0,1]$ 。
### 6.3 高斯分布
#### 6.3.1 一维正态分布
1. 正态分布的概率密度函数为:
$$p(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-(x-\mu)^{2}/ (2\sigma^{2})}, -\infty \lt x \lt \infty$$ 其 $\mu,\sigma(\sigma \gt 0) $ 为常数。
- 若随机变量 ${\mathbf x}$ 的概率密度函数如上所述,则称 ${\mathbf x}$ 服从参数为 $\mu,\sigma$ 的正态分布或者高斯分布,记作 ${\mathbf x} \sim N(\mu,\sigma^{2})$ 。
- 特别的,当 $\mu=0,\sigma=1$ 时,称为标准正态分布,其概率密度函数记作 $\varphi(x)$ , 分布函数记作 $\Phi(x)$
2. 为了计算方便,有时也记作:
$$\mathcal N(x;\mu,\beta^{-1}) =\sqrt{\frac{\beta}{2\pi}}\exp\left(-\frac{1}{2}\beta(x-\mu)^{2}\right)$$ 其 $\beta \in (0,\infty)$
- 正态分布是很多应用中的合理选择。如果某个随机变量取值范围是实数,且对它的概率分布一无所知,通常会假设它服从正态分布。有两个原因支持这一选择:
- 建模的任务的真实分布通常都确实接近正态分布。中心极限定理表明,多个独立随机变量的和近似正态分布。
- 在具有相同方差的所有可能的概率分布中,正态分布的熵最大(即不确定性最大)。
3. 正态分布的概率密度函数性质:
- 曲线关于 $x=\mu$ 对称
- 曲线在 $x=\mu$ 时取最大值
- 曲线在 $x=\mu \pm \sigma $ 处有拐点
> 参 $\mu$ 决定曲线的位置 $\sigma$ 决定图形的胖瘦
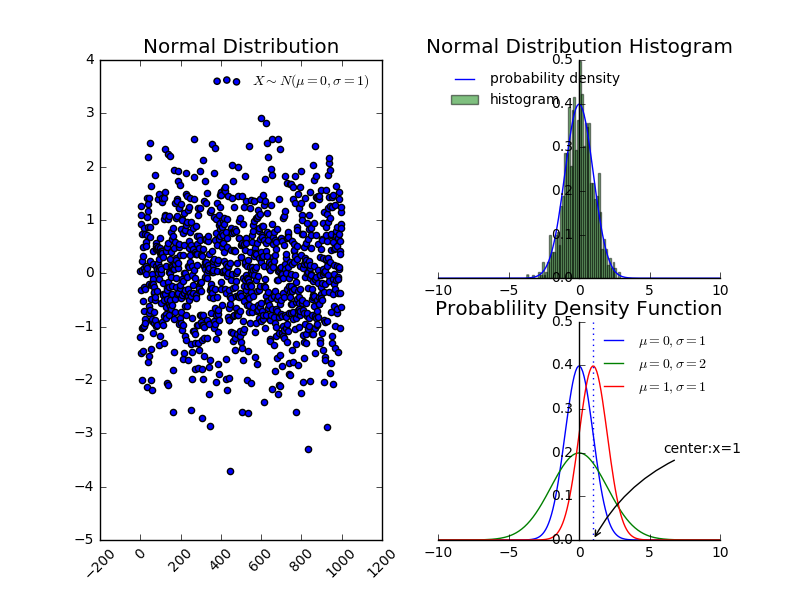
4. ${\mathbf x} \sim N(\mu,\sigma^{2})$ 则 $\frac{{\mathbf x}-\mu}{\sigma} \sim N(0,1)$
5. 有限个相互独立的正态随机变量的线性组合仍然服从正态分布。
6. 正态分布的期望就 $\mu$ ,方差就 $\sigma^{2}$
7. 若随机变 ${\mathbf x}_i \sim N(\mu_i,\sigma_i^{2}),i=1,2,\cdots,n$ 且它们相互独立,则它们的线性组合:
$C_1{\mathbf x}_1+C_2{\mathbf x}_2+\cdots+C_n{\mathbf x}_n$ 其中 $C_1,C_2,\cdots,C_n$ 不全是为0的常数)仍然服从正态分布,且:
$$C_1{\mathbf x}_1+C_2{\mathbf x}_2+\cdots+C_n{\mathbf x}_n \sim N(\sum_{i=1}^{n}C_i\mu_i,\sum_{i=1}^{n}C_i^{2}\sigma_i^{2})
P(\mathbf x=2)=\theta_2\\
\vdots\\
P(\mathbf x=K-1)=\theta_{K-1}\\
P(\mathbf x=K)=1-\sum_{i=1}^{K-1}\theta_i \\$$ 其 $\theta_i$ 为参数,它满 $\theta_i \in [0,1]$ , $\sum_{i=1}^{K-1}\theta_i \in [0,1]$ 。
### 6.3 高斯分布
#### 6.3.1 一维正态分布
1. 正态分布的概率密度函数为:
$$p(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-(x-\mu)^{2}/ (2\sigma^{2})}, -\infty \lt x \lt \infty$$ 其 $\mu,\sigma(\sigma \gt 0) $ 为常数。
- 若随机变量 ${\mathbf x}$ 的概率密度函数如上所述,则称 ${\mathbf x}$ 服从参数为 $\mu,\sigma$ 的正态分布或者高斯分布,记作 ${\mathbf x} \sim N(\mu,\sigma^{2})$ 。
- 特别的,当 $\mu=0,\sigma=1$ 时,称为标准正态分布,其概率密度函数记作 $\varphi(x)$ , 分布函数记作 $\Phi(x)$
2. 为了计算方便,有时也记作:
$$\mathcal N(x;\mu,\beta^{-1}) =\sqrt{\frac{\beta}{2\pi}}\exp\left(-\frac{1}{2}\beta(x-\mu)^{2}\right)$$ 其 $\beta \in (0,\infty)$
- 正态分布是很多应用中的合理选择。如果某个随机变量取值范围是实数,且对它的概率分布一无所知,通常会假设它服从正态分布。有两个原因支持这一选择:
- 建模的任务的真实分布通常都确实接近正态分布。中心极限定理表明,多个独立随机变量的和近似正态分布。
- 在具有相同方差的所有可能的概率分布中,正态分布的熵最大(即不确定性最大)。
3. 正态分布的概率密度函数性质:
- 曲线关于 $x=\mu$ 对称
- 曲线在 $x=\mu$ 时取最大值
- 曲线在 $x=\mu \pm \sigma $ 处有拐点
> 参 $\mu$ 决定曲线的位置 $\sigma$ 决定图形的胖瘦

4. ${\mathbf x} \sim N(\mu,\sigma^{2})$ 则 $\frac{{\mathbf x}-\mu}{\sigma} \sim N(0,1)$
5. 有限个相互独立的正态随机变量的线性组合仍然服从正态分布。
6. 正态分布的期望就 $\mu$ ,方差就 $\sigma^{2}$
7. 若随机变 ${\mathbf x}_i \sim N(\mu_i,\sigma_i^{2}),i=1,2,\cdots,n$ 且它们相互独立,则它们的线性组合:
$C_1{\mathbf x}_1+C_2{\mathbf x}_2+\cdots+C_n{\mathbf x}_n$ 其中 $C_1,C_2,\cdots,C_n$ 不全是为0的常数)仍然服从正态分布,且:
$$C_1{\mathbf x}_1+C_2{\mathbf x}_2+\cdots+C_n{\mathbf x}_n \sim N(\sum_{i=1}^{n}C_i\mu_i,\sum_{i=1}^{n}C_i^{2}\sigma_i^{2})
6.3.2 多维正态分布
- 二维正态随机变 (x1,x2) 的概率密度为:
p(x1,x2)=12πσ1σ2√1−ρ2exp{−12(1−ρ2)[(x1−μ1)2σ21−2ρ(x1−μ1)(x2−μ2)σ1σ2+(x2−μ2)2σ22]}$$可以计算出:$$px(x)=1√2πσ1e−(x−μ1)2/(2σ21),−∞<x<∞py(y)=1√2πσ2e−(y−μ2)2/(2σ22),−∞<y<∞E[x]=μ1E[y]=μ2Var[x]=σ21Var[y]=σ22Cov[x,y]=∫∞−∞∫∞−∞(x−μ1)(y−μ2)p(x,y)dxdy=ρσ1σ2ρxy=ρ
- 引入矩阵:
\mathbf{\vec {\mathbf x}}=\begin{bmatrix}
x_1 \\
x_2
\end{bmatrix} \quad
\mathbf{\vec \mu}=\begin{bmatrix}
\mu_1 \\
\mu_2
\end{bmatrix}\\
\mathbf{\Sigma}=\begin{bmatrix}
c_{11} &c_{12}\\
c_{21} &c_{22}
\end{bmatrix} =
\begin{bmatrix}
\sigma_1^{2} & \rho \sigma_1 \sigma_2 \\
\rho \sigma_1 \sigma_2 & \sigma_2^{2}
\end{bmatrix}$$ $\mathbf \Sigma$ $({\mathbf x}_1,{\mathbf x}_2)$ 的协方差矩阵。其行列式 $\det \mathbf{\Sigma} =\sigma_1^{2}\sigma_2^{2}(1-\rho^{2})$ ,其逆矩阵为:
$$\mathbf{\Sigma}^{-1}=\frac{1}{\det\mathbf \Sigma}\begin{bmatrix}
\sigma_2^{2} & -\rho \sigma_1 \sigma_2 \\
-\rho \sigma_1 \sigma_2 & \sigma_1^{2}
\end{bmatrix}$$ 于 $({\mathbf x}_1,{\mathbf x}_2)$ 的概率密度函数可以写 $( \mathbf {\vec {\mathbf x}}- \mathbf {\vec \mu})^{T}$ 表示矩阵的转置:
$$p(x_1,x_2)=\frac{1}{(2\pi)(\det \mathbf \Sigma)^{1/ 2}}\exp\{- \frac 12 ( \mathbf {\vec {\mathbf x}}- \mathbf {\vec \mu})^{T} \mathbf \Sigma^{-1}( \mathbf {\vec {\mathbf x}}- \mathbf {\vec \mu})\}$$ 其中均 $\mu_1,\mu_2$ 决定了曲面的位置(本例中均值都为0)。标准 $\sigma_1,\sigma_2$ 决定了曲面的陡峭程度(本例中方差都为1)。 $\rho$ 决定了协方差矩阵的形状,从而决定了曲面的形状
- $\rho=0$ 时,协方差矩阵对角线非零,其他位置均为零。此时表示随机变量之间不相关。此时的联合分布概率函数形状如下图所示,曲面在 $z=0$ 平面的截面是个圆形:
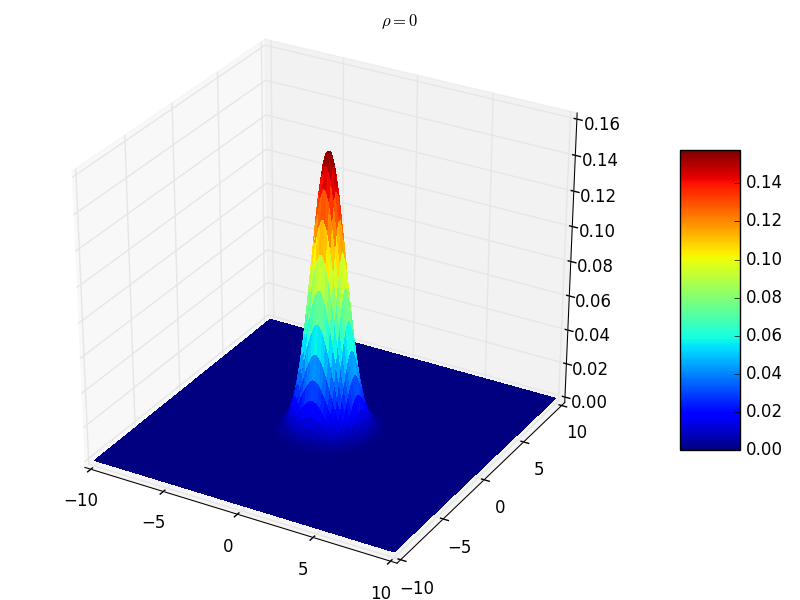
- $\rho=0.5$ 时,协方差矩阵对角线非零,其他位置均为零。此时表示随机变量之间相关。此时的联合分布概率函数形状如下图所示,曲面在 $z=0$ 平面的截面是个椭圆,相当于圆形沿着直线 $y=x$ 方向压缩 :
<center>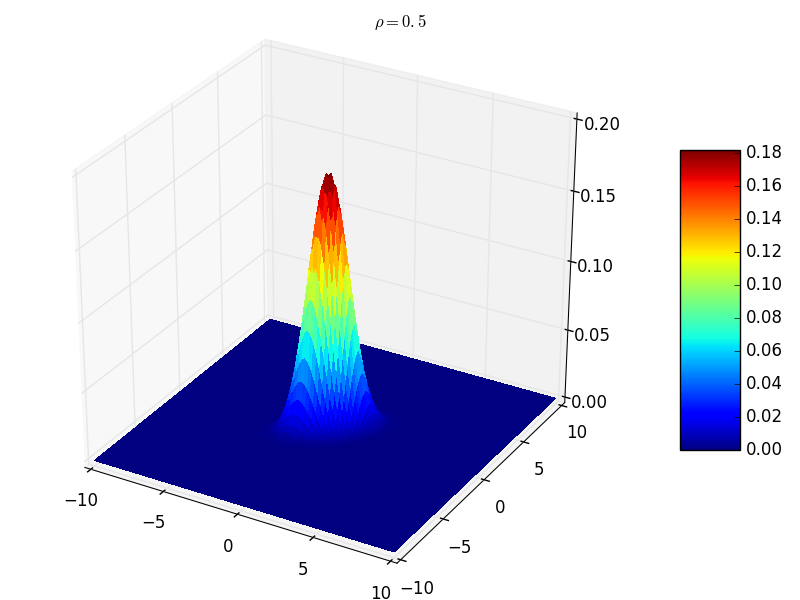</center>
- $\rho=1$ 时,协方差矩阵对角线非零,其他位置均为零。此时表示随机变量之间完全相关。此时的联合分布概率函数形状为:曲面在 $z=0$ 平面的截面是直线 $y=x$ ,相当于圆形沿着直线 $y=x$ 方向压缩成一条直线 。由于 $\rho=1$ 会导致除数为 0,因此这里给出 $\rho=0.9$ :
<center>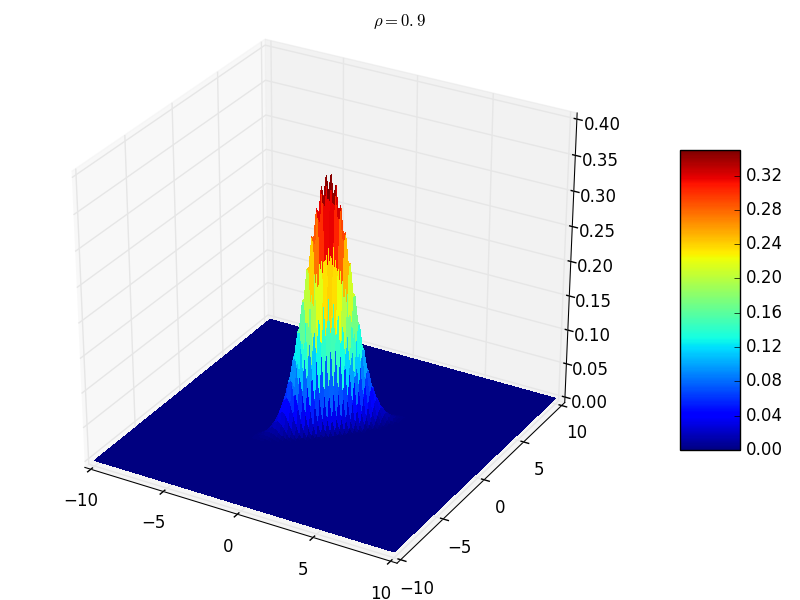</center>
3. 多维正态随机变 $({\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n)$ ,引入列矩阵:
$$\mathbf{\vec {\mathbf x}}=\begin{bmatrix}
x_1 \\
x_2 \\
\vdots\\
x_n
\end{bmatrix} \quad
\mathbf{\vec \mu}=\begin{bmatrix}
\mu_1 \\
\mu_2\\
\vdots\\
\mu_n
\end{bmatrix}=\begin{bmatrix}
\mathbb E[{\mathbf x}_1] \\
\mathbb E[{\mathbf x}_2] \\
\vdots\\
\mathbb E[{\mathbf x}_n]
\end{bmatrix}$$ $\mathbf \Sigma$ $({\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n)$ 的协方差矩阵。则
$$p(x_1,x_2,x_3,\cdots,x_n)=\frac {1}{(2\pi)^{n/2}(\det \mathbf \Sigma)^{1/2}} \exp \{- \frac 12( \mathbf {\vec {\mathbf x}}- \mathbf {\vec \mu})^{T}\mathbf \Sigma^{-1}( \mathbf {\vec {\mathbf x}}- \mathbf {\vec \mu})\}$$ 记做
$$\mathcal N(\mathbf{\vec x};\mathbf{\vec \mu},\mathbf\Sigma) =\sqrt{\frac{1}{(2\pi)^{n}det(\mathbf\Sigma)}}\exp\left(-\frac 12(\mathbf{\vec x-\vec \mu})^{T}\mathbf\Sigma^{-1}(\mathbf{\vec x-\vec \mu})\right)
x_1 \\
x_2
\end{bmatrix} \quad
\mathbf{\vec \mu}=\begin{bmatrix}
\mu_1 \\
\mu_2
\end{bmatrix}\\
\mathbf{\Sigma}=\begin{bmatrix}
c_{11} &c_{12}\\
c_{21} &c_{22}
\end{bmatrix} =
\begin{bmatrix}
\sigma_1^{2} & \rho \sigma_1 \sigma_2 \\
\rho \sigma_1 \sigma_2 & \sigma_2^{2}
\end{bmatrix}$$ $\mathbf \Sigma$ $({\mathbf x}_1,{\mathbf x}_2)$ 的协方差矩阵。其行列式 $\det \mathbf{\Sigma} =\sigma_1^{2}\sigma_2^{2}(1-\rho^{2})$ ,其逆矩阵为:
$$\mathbf{\Sigma}^{-1}=\frac{1}{\det\mathbf \Sigma}\begin{bmatrix}
\sigma_2^{2} & -\rho \sigma_1 \sigma_2 \\
-\rho \sigma_1 \sigma_2 & \sigma_1^{2}
\end{bmatrix}$$ 于 $({\mathbf x}_1,{\mathbf x}_2)$ 的概率密度函数可以写 $( \mathbf {\vec {\mathbf x}}- \mathbf {\vec \mu})^{T}$ 表示矩阵的转置:
$$p(x_1,x_2)=\frac{1}{(2\pi)(\det \mathbf \Sigma)^{1/ 2}}\exp\{- \frac 12 ( \mathbf {\vec {\mathbf x}}- \mathbf {\vec \mu})^{T} \mathbf \Sigma^{-1}( \mathbf {\vec {\mathbf x}}- \mathbf {\vec \mu})\}$$ 其中均 $\mu_1,\mu_2$ 决定了曲面的位置(本例中均值都为0)。标准 $\sigma_1,\sigma_2$ 决定了曲面的陡峭程度(本例中方差都为1)。 $\rho$ 决定了协方差矩阵的形状,从而决定了曲面的形状
- $\rho=0$ 时,协方差矩阵对角线非零,其他位置均为零。此时表示随机变量之间不相关。此时的联合分布概率函数形状如下图所示,曲面在 $z=0$ 平面的截面是个圆形:

- $\rho=0.5$ 时,协方差矩阵对角线非零,其他位置均为零。此时表示随机变量之间相关。此时的联合分布概率函数形状如下图所示,曲面在 $z=0$ 平面的截面是个椭圆,相当于圆形沿着直线 $y=x$ 方向压缩 :
<center></center>
- $\rho=1$ 时,协方差矩阵对角线非零,其他位置均为零。此时表示随机变量之间完全相关。此时的联合分布概率函数形状为:曲面在 $z=0$ 平面的截面是直线 $y=x$ ,相当于圆形沿着直线 $y=x$ 方向压缩成一条直线 。由于 $\rho=1$ 会导致除数为 0,因此这里给出 $\rho=0.9$ :
<center></center>
3. 多维正态随机变 $({\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n)$ ,引入列矩阵:
$$\mathbf{\vec {\mathbf x}}=\begin{bmatrix}
x_1 \\
x_2 \\
\vdots\\
x_n
\end{bmatrix} \quad
\mathbf{\vec \mu}=\begin{bmatrix}
\mu_1 \\
\mu_2\\
\vdots\\
\mu_n
\end{bmatrix}=\begin{bmatrix}
\mathbb E[{\mathbf x}_1] \\
\mathbb E[{\mathbf x}_2] \\
\vdots\\
\mathbb E[{\mathbf x}_n]
\end{bmatrix}$$ $\mathbf \Sigma$ $({\mathbf x}_1,{\mathbf x}_2,\cdots,{\mathbf x}_n)$ 的协方差矩阵。则
$$p(x_1,x_2,x_3,\cdots,x_n)=\frac {1}{(2\pi)^{n/2}(\det \mathbf \Sigma)^{1/2}} \exp \{- \frac 12( \mathbf {\vec {\mathbf x}}- \mathbf {\vec \mu})^{T}\mathbf \Sigma^{-1}( \mathbf {\vec {\mathbf x}}- \mathbf {\vec \mu})\}$$ 记做
$$\mathcal N(\mathbf{\vec x};\mathbf{\vec \mu},\mathbf\Sigma) =\sqrt{\frac{1}{(2\pi)^{n}det(\mathbf\Sigma)}}\exp\left(-\frac 12(\mathbf{\vec x-\vec \mu})^{T}\mathbf\Sigma^{-1}(\mathbf{\vec x-\vec \mu})\right)
- n 维正态变量具有下列四条性质:
- n 维正态变量的每一个分量都是正态变量;反之, x1,x2,⋯,xn 都是正态变量,且相互独立, (x1,x2,⋯,xn) n 维正态变量
- n 维随机变 (x1,x2,⋯,xn) 服 n 维正态分布的充要条件 x1,x2,⋯,xn 的任意线性组合 l1x1+l2x2+⋯+lnxn 服从一维正态分布,其 l1,l2,⋯,ln 不全为0
- (x1,x2,⋯,xn) 服 n 维正态分布, y1,y2,⋯,yk xj,j=1,2,⋯,n 的线性函数, (y1,y2,⋯,yk) 也服从多维正态分布
这一性质称为正态变量的线性变换不变性
- (x1,x2,⋯,xn) 服 n 维正态分布, x1,x2,⋯,xn 相互独 ⟺ x1,x2,⋯,xn 两两不相关
6.4 指数分布
- 指数分布:
- 概率密度函数:
p(x;λ)={0,x<0λexp(λx),x≥0
- 期望: $\mathbb E_{\mathbf x}[x]=\frac{1}{\lambda}$
- 方差: $Var_{\mathbf x}[x]=\frac{1}{\lambda^{2}}$
6.5 拉普拉斯分布
- 拉普拉斯分布:
- 概率密度函数:
p(x;μ,γ)=12γexp(−|x−μ|γ)
- 期望: $\mathbb E_{\mathbf x}[x]=\mu$
- 方差: $Var_{\mathbf x}[x]=2\gamma^{2}$
6.6 狄拉克分布
- 狄拉克分布:假设所有的概率都集中在一 μ 上,则对应的概率密度函数为:
p(x)=δ(x−μ)$$其$δ(⋅)$为狄拉克函数,其性质为:$$δ(x)=0,∀x≠0∫∞−∞δ(x)dx=1
- 狄拉克分布的一个典型用途就是定义连续型随机变量的经验分布函数。假设数据集中有样 →x1,→x2,⋯,→xN ,则定义经验分布函数:
\hat p(\mathbf{\vec x})=\frac 1N\sum_{i=1}^{N}\delta(\mathbf{\vec x}-\mathbf{\vec x}_i)$$ 它就是对每个样本赋予了一个概率质 $\frac 1N$ 。
- 对于离散型随机变量的经验分布,则经验分布函数就是`multinoulli`分布,它简单地等于训练集中的经验频率。
3. 经验分布的两个作用:
- 通过查看训练集样本的经验分布,从而指定该训练集的样本采样的分布(保证采样之后的分布不失真)
- 经验分布就是使得训练数据的可能性最大化的概率密度函数
### 6.7 多项式分布与狄里克雷分布
1. 多项式分布的质量密度函数:
$$Mult(m_1,m_2,\cdots,m_K;\vec\mu,N)=\frac{N!}{m_1!m_2!\cdots m_K!}\prod_{k=1}^{K}\mu_k^{m_k}$$ 它 $(\mu_1+\mu_2+\cdots+\mu_K)^{m_1+m_2+\cdots+m_K}$ 的多项式展开的形式
2. 狄利克雷分布的概率密度函数:
$$Dir(\vec\mu;\vec\alpha)=\frac{\Gamma(\sum_{k=1}^{K}\alpha_k)}{\sum_{k=1}^{K}\Gamma(\alpha_k)}\prod_{k=1}^{K}\mu_k^{\alpha_k-1}
- 对于离散型随机变量的经验分布,则经验分布函数就是`multinoulli`分布,它简单地等于训练集中的经验频率。
3. 经验分布的两个作用:
- 通过查看训练集样本的经验分布,从而指定该训练集的样本采样的分布(保证采样之后的分布不失真)
- 经验分布就是使得训练数据的可能性最大化的概率密度函数
### 6.7 多项式分布与狄里克雷分布
1. 多项式分布的质量密度函数:
$$Mult(m_1,m_2,\cdots,m_K;\vec\mu,N)=\frac{N!}{m_1!m_2!\cdots m_K!}\prod_{k=1}^{K}\mu_k^{m_k}$$ 它 $(\mu_1+\mu_2+\cdots+\mu_K)^{m_1+m_2+\cdots+m_K}$ 的多项式展开的形式
2. 狄利克雷分布的概率密度函数:
$$Dir(\vec\mu;\vec\alpha)=\frac{\Gamma(\sum_{k=1}^{K}\alpha_k)}{\sum_{k=1}^{K}\Gamma(\alpha_k)}\prod_{k=1}^{K}\mu_k^{\alpha_k-1}
- 可以看到,多项式分布与狄里克雷分布的概率密度函数非常相似,区别仅仅在于前面的归一化项
- 多项式分布是针对离散型随机变量,通过求和获取概率
- 狄里克雷分布时针对连续型随机变量,通过求积分来获取概率
6.8 混合概率分布
- 混合概率分布:它组合了其他几个分量的分布来组成。
- 在每次生成样本中,首先通过
multinoulli分布来决定选用哪个分量,然后由该分量的分布函数来生成样本。 - 其概率分布函数为:
- 在每次生成样本中,首先通过
P(\mathbf x)=\sum_{i}P(c=i)P(\mathbf x\mid c=i)$$ 其 $P(c=i)$ 为一个`multinoulli`分布 $c$ 的取值范围就是各分量的编号。
2. 前面介绍的连续型随机变量的经验分布函数就是一个混合概率分布的例子,此 $P(c=i)=\frac 1N$
3. 混合概率分布可以通过简单的概率分布创建更复杂的概率分布
- 一个常见的例子是混合高斯模型,其 $P(\mathbf x\mid c=i)$ 为高斯模型。每个分量都有对应的参 $(\mathbf{\vec \mu}_i,\mathbf \Sigma_i)$
- 有些混合高斯模型有更强的约束,如 $\forall i,\mathbf \Sigma_i=\mathbf\Sigma$ ,更进一步还可以要求 $\mathbf\Sigma$ 为一个对角矩阵。
- 混合高斯模型是一个通用的概率密度函数逼近工具。任何平滑的概率密度函数都可以通过足够多分量的混合高斯模型来逼近。
## 七、先验分布与后验分布
1. 在贝叶斯学派中,`先验分布+数据(似然)= 后验分布`
2. 例如:假设需要识别一大箱苹果中的好苹果、坏苹果的概率。
- 根据你对苹果好、坏的认知,给出先验分布为:50个好苹果和50个坏苹果
- 现在你拿出10个苹果,发现有:8个好苹果,2个坏苹果。
根据数据,你得到后验分布为:58个好苹果,52个坏苹果
- 再拿出10个苹果,发现有:9个好苹果,1个坏苹果。
根据数据,你得到后验分布为:67个好苹果,53个坏苹果
- 这样不断重复下去,不断更新后验分布。当一箱苹果清点完毕,则得到了最终的后验分布。
在这里:
- 如果不使用先验分布,仅仅清点这箱苹果中的好坏,则得到的分布只能代表这一箱苹果。
- 采用了先验分布之后得到的分布,可以认为是所有箱子里的苹果的分布。
- 先验分布时:给出的好、坏苹果的个数(也就是频数)越大,则先验分布越占主导地位。
3. 假设好苹果的概率 $p$ ,则抽 $N$ 个苹果中,好苹果个数 $k$ 个的概率为一个二项分布:
$$Binom(k\mid p;N)=C_N^kp^k(1-p)^{N-k}$$ 其 $C_N^k$ 为组合数。
4. 现在的问题是:好苹果的概 $p$ 不再固定,而是服从一个分布。
假设好苹果的概 $p$ 的先验分布为贝塔分布
$$Beta(p; \alpha,\beta)=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}p^{\alpha-1}(1-p)^{\beta-1}$$
则后验概率为:
$$P(p\mid k; N,\alpha,\beta)=\frac{P(k\mid p; N)\times P(p; \alpha,\beta)}{P(k; N,\alpha,\beta)} \\
\propto P(k\mid p; N)\times P(p; \alpha,\beta)=C_N^kp^k(1-p)^{N-k}\times \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}p^{\alpha-1}(1-p)^{\beta-1}\\
\propto p^{k+\alpha-1}(1-p)^{N-k+\beta-1}$$ 归一化之后,得到后验概率为:
$$P(p\mid k;N,\alpha,\beta)=\frac{\Gamma(\alpha+\beta+N)}{\Gamma(\alpha+k)\Gamma(\beta+N-k)}p^{k+\alpha-1}(1-p)^{N-k+\beta-1}
2. 前面介绍的连续型随机变量的经验分布函数就是一个混合概率分布的例子,此 $P(c=i)=\frac 1N$
3. 混合概率分布可以通过简单的概率分布创建更复杂的概率分布
- 一个常见的例子是混合高斯模型,其 $P(\mathbf x\mid c=i)$ 为高斯模型。每个分量都有对应的参 $(\mathbf{\vec \mu}_i,\mathbf \Sigma_i)$
- 有些混合高斯模型有更强的约束,如 $\forall i,\mathbf \Sigma_i=\mathbf\Sigma$ ,更进一步还可以要求 $\mathbf\Sigma$ 为一个对角矩阵。
- 混合高斯模型是一个通用的概率密度函数逼近工具。任何平滑的概率密度函数都可以通过足够多分量的混合高斯模型来逼近。
## 七、先验分布与后验分布
1. 在贝叶斯学派中,`先验分布+数据(似然)= 后验分布`
2. 例如:假设需要识别一大箱苹果中的好苹果、坏苹果的概率。
- 根据你对苹果好、坏的认知,给出先验分布为:50个好苹果和50个坏苹果
- 现在你拿出10个苹果,发现有:8个好苹果,2个坏苹果。
根据数据,你得到后验分布为:58个好苹果,52个坏苹果
- 再拿出10个苹果,发现有:9个好苹果,1个坏苹果。
根据数据,你得到后验分布为:67个好苹果,53个坏苹果
- 这样不断重复下去,不断更新后验分布。当一箱苹果清点完毕,则得到了最终的后验分布。
在这里:
- 如果不使用先验分布,仅仅清点这箱苹果中的好坏,则得到的分布只能代表这一箱苹果。
- 采用了先验分布之后得到的分布,可以认为是所有箱子里的苹果的分布。
- 先验分布时:给出的好、坏苹果的个数(也就是频数)越大,则先验分布越占主导地位。
3. 假设好苹果的概率 $p$ ,则抽 $N$ 个苹果中,好苹果个数 $k$ 个的概率为一个二项分布:
$$Binom(k\mid p;N)=C_N^kp^k(1-p)^{N-k}$$ 其 $C_N^k$ 为组合数。
4. 现在的问题是:好苹果的概 $p$ 不再固定,而是服从一个分布。
假设好苹果的概 $p$ 的先验分布为贝塔分布
$$Beta(p; \alpha,\beta)=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}p^{\alpha-1}(1-p)^{\beta-1}$$
则后验概率为:
$$P(p\mid k; N,\alpha,\beta)=\frac{P(k\mid p; N)\times P(p; \alpha,\beta)}{P(k; N,\alpha,\beta)} \\
\propto P(k\mid p; N)\times P(p; \alpha,\beta)=C_N^kp^k(1-p)^{N-k}\times \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}p^{\alpha-1}(1-p)^{\beta-1}\\
\propto p^{k+\alpha-1}(1-p)^{N-k+\beta-1}$$ 归一化之后,得到后验概率为:
$$P(p\mid k;N,\alpha,\beta)=\frac{\Gamma(\alpha+\beta+N)}{\Gamma(\alpha+k)\Gamma(\beta+N-k)}p^{k+\alpha-1}(1-p)^{N-k+\beta-1}
- 好苹果概 p 的先验分布的期望为:
E[p]=αα+β$$好苹果概$p$的后验分布的期望为:$$E[p∣k]=α+kα+β+N
- 根据上述例子所述:
- 好苹果的先验概率的期望为 $\frac {50}{50+50}=\frac 12$
- 进行第一轮数据校验之后,好苹果的后验概率的期望为 $\frac {50+8}{50+50+10}=\frac {58}{110}$
- 如果 $\alpha$ 视为先验的好苹果数量 $\beta$ 视为先验的坏苹果数量 $N$ 表示箱子中苹果的数量 $k$ 表示箱子中的好苹果数量(相应的 $N-k$ 就是箱子中坏苹果的数量)。则:好苹果的先验概率分布的期望、后验概率分布的期望符合人们的生活经验。
- 这里使用先验分布和后验分布的期望,因 $p$ 是一个随机变量。若想通过一个数值来刻画好苹果的可能性,则用期望较好。
- 更一般的,如果苹果不仅仅分为好、坏两种,而是分作“尺寸1、尺寸2、...尺 K ”等。 N 个苹果中, m1 个尺寸1的苹果 m2 个尺寸2的苹果... mK 个尺 K 的苹果的概率服从多项式分布:
Mult(m1,m2,⋯,mK;→μ,N)=N!m1!m2!⋯mK!K∏k=1μmkk$$其中苹果为尺寸1的概率$μ1$,尺寸2的概率$μ2$,...尺$K$的概率$μK$$N=K∑k=1mk$−假设苹果尺寸的先验概率分布为狄利克雷分布:$$Dir(→μ;→α)=Γ(∑Kk=1αk)∑Kk=1Γ(αk)K∏k=1μαk−1k$$苹果尺寸的先验概率分布的期望为:$$E[→μ]=(α1∑Kk=1αk,α2∑Kk=1αk,⋯,αK∑Kk=1αk)
- 则苹果尺寸的后验概率分布也为狄里克雷分布:
Dir(→μ;→α+→m)=Γ(N+∑Kk=1αk)∑Kk=1Γ(αk+mk)K∏k=1μαk+mk−1k$$苹果尺寸的后验概率分布的期望为:$$E[→μ]=(α1+m1N+∑Kk=1αk,α2+m2N+∑Kk=1αk,⋯,αK+mKN+∑Kk=1αk)
八、测度论
- 测度为零:非正式化的提法是,如果集合中的点的数量可以忽略不计,则该集合的测度为零。
- 如:二维空间中的直线的测度为零,而正方形的测度非零。
- 几乎处处相等:不满足条件的那些点组成的集合的测度为零。
- 假设随机变 x,y 满 y=g(x) ,且函 g(⋅) 满足:处处连续、可导、且存在反函数。
则有:
px(x)=py(g(x))|∂g(x)∂x|$$或者等价地:$$py(y)=px(g−1(y))|∂x∂y|
- 如果扩展到高维空间,则有:
px(→x)=py(g(→x))|det(∂g(→x)∂→x)|
- 并不 $p_{\mathbf y}(y)=p_{\mathbf x}(g^{-1}(y))$ ,这是因 $g(\cdot)$ 引起了空间扭曲,从而导 $\int p_{\mathbf x}(g(x))dx \neq 1$ 。其实我们有:
|p_{\mathbf y}(g(x))dy|=|p_{\mathbf x}(x)dx|$$ 求解该方程,即得到上述解。
## 九、信息论
1. 信息论背后的原理是:从不太可能发生的事件中能学到更多的有用信息。
- 发生可能性较大的事件包含较少的信息
- 发生可能性较小的事件包含较多的信息
- 独立事件包含额外的信息
对于事 $\mathbf x=x$ ,定义自信息`self-information`为:
$$I(x)=-\log P(x)
## 九、信息论
1. 信息论背后的原理是:从不太可能发生的事件中能学到更多的有用信息。
- 发生可能性较大的事件包含较少的信息
- 发生可能性较小的事件包含较多的信息
- 独立事件包含额外的信息
对于事 $\mathbf x=x$ ,定义自信息`self-information`为:
$$I(x)=-\log P(x)
- 自信息仅仅处理单个输出,但是如果计算自信息的期望,它就是熵:
H(x)=Ex∼P[I(x)]=−Ex∼P[logP(x)]$$记$H(P)$。熵刻画了按照真实分$P$来识别一个样本所需要的编码长度的期望(即平均编码长度)。如:含有4个字母‘(A,B,C,D)‘的样本集中,真实分$P=(12,12,0,0)$,则只需要1位编码即可识别样本。3.‘KL‘散度:对于给定的随机变$x$,它的两个概率分布函$P(x)$$Q(x)$的区别可以用‘KL‘散度来度量:$$DKL(P||Q)=Ex∼P[logP(x)Q(x)]=Ex∼P[logP(x)−logQ(x)]
- `KL`散度非负。当它为0时,当且仅当 `P`和`Q`是同一个分布(对于离散型随机变量),或者两个分布几乎处处相等(对于连续型随机变量)
- $D_{KL}(P||Q) \neq D_{KL}(Q||P)$
- 交叉熵
cross-entropyH(P,Q)=H(P)+DKL(P||Q)=−Ex∼PlogQ(x) 。
交叉熵刻画了使用错误分 Q 来表示真实分 P 中的样本的平均编码长度。
DKL(P||Q) 刻画了错误分 Q 编码真实分 P 带来的平均编码长度的增量。
数值计算
一、数值稳定性
1.1 近似误差
- 在计算机中执行数学运算需要使用有限的比特位来表达实数,这会引入近似误差
- 近似误差可以在多步数值运算中传递、积累,从而导致理论上成功的算法失败
- 数值算法设计时要考虑将累计误差最小化
- 上溢出
overflow和下溢出underflow:- 一种严重的误差是下溢出:当接近零的数字四舍五入为零时,发生下溢出
- 许多函数在参数为零和参数为一个非常小的正数时,行为是不同的。如对数函数要求自变量大于零;除法中要求除数非零。
- 另一种严重的误差是上溢出:当数值非常大,超过了计算机的表示范围时,发生上溢出。
- 一种严重的误差是下溢出:当接近零的数字四舍五入为零时,发生下溢出
1.2 softmax 函数
- 一个数值稳定性的例子是
softmax函数。
→x=(x1,x2,⋯,xn)T ,则softmax函数定义为:
softmax(→x)=(exp(x1)∑nj=1exp(xj),exp(x2)∑nj=1exp(xj),⋯,exp(xn)∑nj=1exp(xj))T$$当所有$xi$都等于常$c$时,‘softmax‘函数的每个分量的理论值都$1n$−考虑$c$是一个非常大的负数(比如趋近负无穷),此时$exp(c)$下溢出。此时$exp(c)∑nj=1exp(c)$分母为零,结果未定义。−考虑$c$是一个非常大的正数(比如趋近正无穷),此时$exp(c)$上溢出。$exp(c)∑nj=1exp(c)$的结果未定义。2.解决的办法是:$→z=→x−maxixi$,则$softmax(→z)$的$i$个分量为:$$softmax(→z)i=exp(zi)∑nj=1exp(zj)=exp(maxkxk)exp(zi)exp(maxkxk)∑nj=1exp(zj)=exp(zi+maxkxk)∑nj=1exp(zj+maxkxk)=exp(xi)∑nj=1exp(xj)=softmax(→x)i
- 当 $\mathbf{\vec x} $ 的分量较小时, $\mathbf{\vec z} $ 的分量至少有一个为零,从而导致 $\text{softmax}(\mathbf{\vec z})_i$ 的分母至少有一项为 1,从而解决了下溢出的问题。
- 当 $\mathbf{\vec x} $ 的分量较大时 $\text{softmax}(\mathbf{\vec z})_i$ 相当于分子分母同时除以一个非常大的数 $\exp(\max_i x_i)$ ,从而解决了上溢出。
- 还有个问题: →x 的分量较小时 softmax(→x)i 的计算结果可能为0。
- 此 logsoftmax(→x) 趋向于负无穷,非数值稳定的。因此需要设计专门的函数来计 logsoftmax ,而不是 softmax 的结果传递 log 函数。
通常 softmax 函数的输出作为模型的输出。由于一般使用样本的交叉熵作为目标函数,因此需要用 softmax 输出的对数。
- 当从头开始实现一个数值算法时,需要考虑数值稳定性。
当使用现有的数值计算库时,不需要考虑数值稳定性。 softmax名字的来源是hardmax。
hardmax把一个向 →x 映射成向 (0,⋯,0,1,0,⋯,0)T 。即 →x 最大元素的位置填充1,其它位置填充0。
softmax会在这些位置填充0.0~1.0之间的值(如:某个概率值)。
二、Conditioning
Conditioning刻画了一个函数的如下特性:当函数的输入发生了微小的变化时,函数的输出的变化有多大。- 对于
Conditioning较大的函数,在数值计算中可能有问题。因为函数输入的舍入误差可能导致函数输出的较大变化。
- 对于
- 对于方 A∈Rn×n ,其条件数
condition number为:
\text{condition number}=\max_{1\le i,j\le n,i\ne j}\left|\frac{\lambda_i}{\lambda_j} \right|$$ 其 $\lambda_i,i=1,2,\cdots,n$ $\mathbf A$ 的特征值。
- 方阵的条件数就是最大的特征值除以最小的特征值。
- 当方阵的条件数很大时,矩阵的求逆将对误差特别敏感(即: $\mathbf A$ 的一个很小的扰动,将导致其逆矩阵一个非常明显的变化)。
- 条件数是矩阵本身的特性,它会放大那些包含矩阵求逆运算过程中的误差。
## 三、梯度下降法
1. 梯度下降法是求解无约束最优化问题的一种常见方法,优点是实现简单
2. 对于函数 $f:\mathbb R^{n} \rightarrow \mathbb R$ ,输入为多维的。假设输 $\mathbf{\vec x}=(x_1,x_2,\cdots,x_n)^{T}$ ,则定义梯度:
$$\nabla _{\mathbf{\vec x}} f(\mathbf{\vec x})=\left(\frac{\partial}{\partial x_1}f(\mathbf{\vec x}),\frac{\partial}{\partial x_2}f(\mathbf{\vec x}),\cdots,\frac{\partial}{\partial x_n}f(\mathbf{\vec x})\right)^{T}
- 方阵的条件数就是最大的特征值除以最小的特征值。
- 当方阵的条件数很大时,矩阵的求逆将对误差特别敏感(即: $\mathbf A$ 的一个很小的扰动,将导致其逆矩阵一个非常明显的变化)。
- 条件数是矩阵本身的特性,它会放大那些包含矩阵求逆运算过程中的误差。
## 三、梯度下降法
1. 梯度下降法是求解无约束最优化问题的一种常见方法,优点是实现简单
2. 对于函数 $f:\mathbb R^{n} \rightarrow \mathbb R$ ,输入为多维的。假设输 $\mathbf{\vec x}=(x_1,x_2,\cdots,x_n)^{T}$ ,则定义梯度:
$$\nabla _{\mathbf{\vec x}} f(\mathbf{\vec x})=\left(\frac{\partial}{\partial x_1}f(\mathbf{\vec x}),\frac{\partial}{\partial x_2}f(\mathbf{\vec x}),\cdots,\frac{\partial}{\partial x_n}f(\mathbf{\vec x})\right)^{T}
- 驻点满足: $\nabla _{\mathbf{\vec x}} f(\mathbf{\vec x})=\mathbf{\vec 0}$
- 沿着方 →u 的方向导数
directional derivative定义为:
limα→0f(→x+α→u)−f(→x)α$$其$→u$为单位向量。−方向导数就是$∂∂αf(→x+α→u)$。根据链式法则,它也等于$→uT∇→xf(→x)$4.为了最小$f$,则寻找一个方向:沿着该方向,函数值减少的速度最快(换句话说,就是增加最慢)。即:$$min→u→uT∇→xf(→x)s.t.||→u||2=1
- 假 $\mathbf{\vec u}$ 与梯度的夹角 $\theta$ ,则目标函数等于:
||→u||2||∇→xf(→x)||2cosθ$$考虑$||→u||2=1$,以及梯度的大小$θ$无关,于是上述问题转化为:$$minθcosθ$$于是$θ∗=π$,$→u$沿着梯度的相反的方向。即:梯度的方向是函数值增加最快的方向,梯度的相反方向是函数值减小的最快的方向。−可以沿着负梯度的方向来降$f$的值,这就是梯度下降法。5.根据梯度下降法,为了寻$f$的最小点,迭代过程为:$$→x′=→x−ϵ∇→xf(→x)$$迭代结束条件为:梯度向$∇→xf(→x)$的每个成分为零或者非常接近零。−$ϵ$为学习率,它是一个正数,决定了迭代的步长。6.选择学习率有多种方法:−一种方法是:选$ϵ$为一个小的、正的常数−另一种方法是:给定多$ϵ$,然后选择使$f(→x−ϵ∇→xf(→x))$最小的那个值作为本次迭代的学习率(即:选择一个使得目标函数下降最大的学习率)。这种做法叫做线性搜索‘linesearch‘−第三种方法是:求得$f(→x−ϵ∇→xf(→x))$取极小值$ϵ$,即求解最优化问题:$$ϵ∗=argminϵ,ϵ>0f(→x−ϵ∇→xf(→x))$$这种方法也称作最速下降法。−在最速下降法中,假设相邻的三个迭代点分别为$→x<k>,→x<k+1>,→x<k+2>$,可以证明$(→x<k+1>−→x<k>)⋅(→x<k+2>−→x<k+1>)=0$。即相邻的两次搜索的方向是正交的!证明:$$→x<k+1>=→x<k>−ϵ<k>∇→xf(→x<k>)→x<k+2>=→x<k+1>−ϵ<k+1>∇→xf(→x<k+1>)$$根据最优化问题,有:$$ϵ<k+1>=argminϵ,ϵ>0f(→x<k+1>−ϵ∇→xf(→x<k+1>))→∂f(→x<k+1>−ϵ∇→xf(→x<k+1>))∂ϵ∣ϵ=ϵ<k+1>=0→∇→xf(→x<k+2>)⋅∇→xf(→x<k+1>)=0→(→x<k+1>−→x<k>)⋅(→x<k+2>−→x<k+1>)=0
- 此时迭代的路线是锯齿形的,因此收敛速度较慢
- 某些情况下如果梯度向 ∇→xf(→x) 的形式比较简单,则可以直接求解方程:
∇→xf(→x)=→0
- 此时不用任何迭代,直接获得解析解。
- 梯度下降算法:
- 输入:
- 目标函数 f(→x)
- 梯度函数 g(→x)=∇f(→x)
- 计算精度 e
- 输出 f(→x) 的极小 →x∗
- 算法步骤:
- 选取初始 →x<0>∈Rn , k=0
- 计 f(→x<k>)
- 计算梯 →gk=g(→x<k>)
- 若梯 |→gk|<e ,则停止迭代 →x∗=→x
- 输入:
即此时导数为0
- 若梯 $|\mathbf {\vec g}_k| \ge e$ ,则 $\mathbf {\vec p}_k=-\mathbf {\vec g}_k$ , $\epsilon_k$ $\epsilon_k =\min_{\epsilon \le 0}f(\mathbf {\vec x}^{<k>}+\epsilon \mathbf {\vec p}_k)$
通常这也是个最小化问题。但是可以给定一系列 ϵk 的值:如
[10,1,0.1,0.01,0.001,0.0001]然后从中挑选
- $\mathbf {\vec x}^{<k+1>} = \mathbf {\vec x}^{<k>}+\epsilon_k \mathbf {\vec p}_k$ ,计 $f(\mathbf {\vec x}^{<k+1>})$
- 若 $|f(\mathbf {\vec x}^{<k+1>})-f(\mathbf {\vec x}^{<k>})| \lt e$ 或者 $|\mathbf {\vec x}^{<k+1>}-\mathbf {\vec x}^{<k>}| \lt e$ 时,停止迭代 $\mathbf {\vec x}^*=\mathbf {\vec x}$
- 否则,令 $k=k+1$ ,计算梯度 $\mathbf {\vec g}_k=g(\mathbf {\vec x}^{<k>})$ 继续迭代
- 当目标函数是凸函数时,梯度下降法的解是全局最优的。
- 通常情况下,梯度下降法的解不保证是全局最优的
- 梯度下降法的收敛速度未必是最快的
四、海森矩阵
4.1 二阶导数
- 二阶导 f′′(x) 刻画了曲率。假设有一个二次函数(实际任务中,很多函数不是二次的,但是在局部可以近似为二次函数):
- 如果函数的二阶导数为零,则它是一条直线。如果梯度为 1,则当沿着负梯度的步长为 ϵ 时,函数值减少 ϵ
- 如果函数的二阶导数为负,则函数向下弯曲。如果梯度为1,则当沿着负梯度的步长为 ϵ 时,函数值减少的量大于 ϵ
- 如果函数的二阶导数为正,则函数向上弯曲。如果梯度为1,则当沿着负梯度的步长为 ϵ 时,函数值减少的量少于 ϵ
4.2 海森矩阵
- 当函数输入为多维时,定义海森矩阵:
H(f)(→x)=[∂2∂x1∂x1f∂2∂x1∂x2f⋯∂2∂x1∂xnf∂2∂x2∂x1f∂2∂x2∂x2f⋯∂2∂x2∂xnf⋮⋮⋱⋮∂2∂xn∂x1f∂2∂xn∂x2f⋯∂2∂xn∂xnf]$$即海森矩阵的$i$$j$列元素为:$$Hi,j=∂2∂xi∂xjf(→x)
- 当二阶偏导是连续时,海森矩阵是对称阵,即有 $\mathbf H=\mathbf H^{T}$
- 在深度学习中大多数海森矩阵都是对称阵
- 对于特定方 →d 上的二阶导数为:
→dTH→d
- 如果 $\mathbf{\vec d}$ 是海森矩阵的特征向量,则该方向的二阶导数就是对应的特征值
- 如果 $\mathbf{\vec d}$ 不是海森矩阵的特征向量,则该方向的二阶导数就是所有特征值的加权平均,权重在 `(0,1)`之间。且与 $\mathbf{\vec d}$ 夹角越小的特征向量对应的特征值具有更大的权重。
- 最大特征值确定了最大二阶导数,最小特征值确定最小二阶导数
4.3 海森矩阵与学习率
- f(→x) →x0 处泰勒展开:
f(→x)≈f(→x0)+(→x−→x0)T→g+12(→x−→x0)TH(→x−→x0)$$其$→g$$→x0$处的梯度$H$$→x0$处的海森矩阵。根据梯度下降法:$$→x′=→x−ϵ∇→xf(→x)$$应用在$→x0$,有:$$f(→x0−ϵ→g)≈f(→x0)−ϵ→gT→g+12ϵ2→gTH→g
- 第一项代表函数在点 $\mathbf{\vec x}_0$ 处的值
- 第二项代表由于斜率的存在,导致函数值的变化
- 第三项代表由于曲率的存在,对于函数值变化的矫正
- 注意:如 12ϵ2→gTH→g 较大,则很有可能导致:沿着负梯度的方向,函数值反而增加!
- 如 →gTH→g≤0 ,则无 ϵ 取多大的值,可以保证函数值是减小的
- 如 →gTH→g>0 ,则学习 ϵ 不能太大。 ϵ 太大则函数值增加
- 根 f(→x0−ϵ→g)−f(→x0)<0 有:
ϵ<2→gT→g→gTH→g
- 考虑最速下降法,选择使 $f$ 下降最快 $\epsilon$ ,则有:
\epsilon^{*}=\arg\min_{\epsilon,\epsilon \gt 0 }f(\mathbf{\vec x}_0-\epsilon\mathbf{\vec g})$$ 求 $\frac{\partial }{\partial \epsilon} f(\mathbf{\vec x}_0-\epsilon\mathbf{\vec g})=0$ 有:
$$\epsilon^{*}=\frac{\mathbf{\vec g}^{T}\mathbf{\vec g}}{\mathbf{\vec g}^{T}\mathbf H\mathbf{\vec g}}$$ > 根 $\mathbf{\vec g}^{T}\mathbf H \mathbf{\vec g} \gt 0$ ,很明显有 $\epsilon^{*} \lt \frac{\mathbf{2\vec g}^{T}\mathbf{\vec g}}{\mathbf{\vec g}^{T}\mathbf H\mathbf{\vec g}} $
3. 由于海森矩阵为实对称阵,因此它可以进行特征值分解。
假设其特征值从大到小排列为:
$$\lambda_1,\lambda_2,\cdots,\lambda_n$$ 其瑞利商 $R(\mathbf{\vec x})=\frac{\mathbf{\vec x}^{T}\mathbf H\mathbf{\vec x}}{\mathbf{\vec x}^{T}\mathbf{\vec x}},\mathbf{\vec x} \ne \mathbf{\vec 0}$ ,可以证明:
$$\lambda_n \le R(\mathbf{\vec x}) \le \lambda_1\\
\lambda_1=\max_{\mathbf{\vec x}\ne \mathbf{\vec 0}} R(\mathbf{\vec x})\\
\lambda_n=\min_{\mathbf{\vec x}\ne \mathbf{\vec 0}} R(\mathbf{\vec x}) $$ 根据:
$$\epsilon^{*}=\frac{\mathbf{\vec g}^{T}\mathbf{\vec g}}{\mathbf{\vec g}^{T}\mathbf H\mathbf{\vec g}}=\frac{1}{R(\mathbf{\vec g})}$$ 可知海森矩阵决定了学习率的取值范围。
- 最坏的情况下,梯度 $\mathbf{\vec g}$ 与海森矩阵最大特征值 $\lambda_1$ 对应的特征向量平行,则此时最优学习率为 $\frac {1}{\lambda_1}$
### 4.4 驻点与全局极小点
1. 满足导数为零的点( $f^{\prime}(x)=0$ )称作驻点。驻点可能为下面三种类型之一:
- 局部极小点:在 $x$ 的一个邻域内,该点的值最小
- 局部极大点:在 $x$ 的一个邻域内,该点的值最大
- 鞍点:既不是局部极小,也不是局部极大
<center>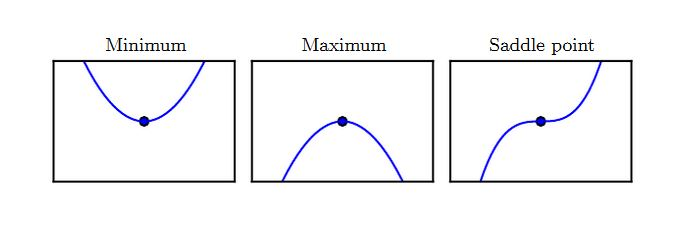</center>
2. 全局极小点 $x^{*}=\arg\min_x f(x)$ 。
- 全局极小点可能有一个或者多个
- 在深度学习中,目标函数很可能具有非常多的局部极小点,以及许多位于平坦区域的鞍点。这使得优化非常不利。因此通常选取一个非常低的目标函数值,而不一定要是全局最小值。
<center>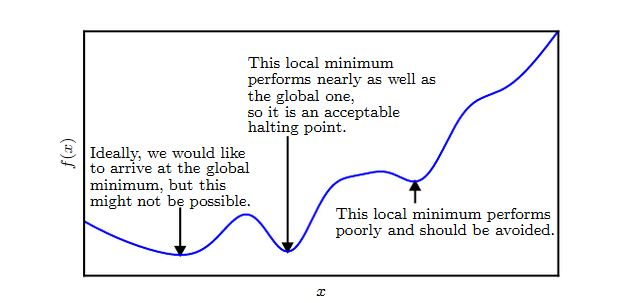</center>
3. 二阶导数可以配合一阶导数来决定驻点的类型:
- 局部极小点 $f^{\prime}(x)=0,f^{\prime\prime}(x)\gt 0$
- 局部极大点 $f^{\prime}(x)=0,f^{\prime\prime}(x)\lt 0$
- $f^{\prime}(x)=0,f^{\prime\prime}(x)= 0$ :驻点的类型可能为任意三者之一。
4. 对于多维的情况类似:
- 局部极小点 $\nabla _{\mathbf{\vec x}} f(\mathbf{\vec x})=0 $ ,且海森矩阵为正定的(即所有的特征值都是正的)。
- 当海森矩阵为正定时,任意方向的二阶偏导数都是正的。
- 局部极大点 $\nabla _{\mathbf{\vec x}} f(\mathbf{\vec x})=0 $ ,且海森矩阵为负定的(即所有的特征值都是负的)。
- 当海森矩阵为负定时,任意方向的二阶偏导数都是负的。
- $\nabla _{\mathbf{\vec x}} f(\mathbf{\vec x})=0 $ ,且海森矩阵的特征值中至少一个正值、至少一个负值时,为鞍点。
- 当海森矩阵非上述情况时,驻点类型无法判断。
下图 $f(\mathbf{\vec x})=x_1^{2}-x_2^{2}$ 在原点附近的等值线。其海森矩阵为一正一负。
- 沿着 $x_1$ 方向,曲线向上;沿着 $x_2$ 方向,曲线向下。
- 鞍点就是在一个横截面内的局部极小值,另一个横截面内的局部极大值。
<center></center>
## 四、牛顿法
1. 梯度下降法有个缺陷:它未能利用海森矩阵的信息
- 当海森矩阵的条件数较大时,不同方向的梯度的变化差异很大。
- 在某些方向上,梯度变化很快;在有些方向上,梯度变化很慢
- 梯度下降法未能利用海森矩阵,也就不知道应该优先搜索导数长期为负的方向。
> 本质上应该沿着负梯度方向搜索。但是沿着该方向的一段区间内,如果导数一直为负,则可以直接跨过该区间。前提是:必须保证该区间内,该方向导数一直为负。
- 当海森矩阵的条件数较大时,也难以选择合适的步长。
- 步长必须足够小,从而能够适应较强曲率的地方(对应着较大的二阶导数,即该区域比较陡峭)
- 但是如果步长太小,对于曲率较小的地方(对应着较小的二阶导数,即该区域比较平缓)则推进太慢。
> 曲率刻画弯曲程度,曲率越大则曲率半径越小
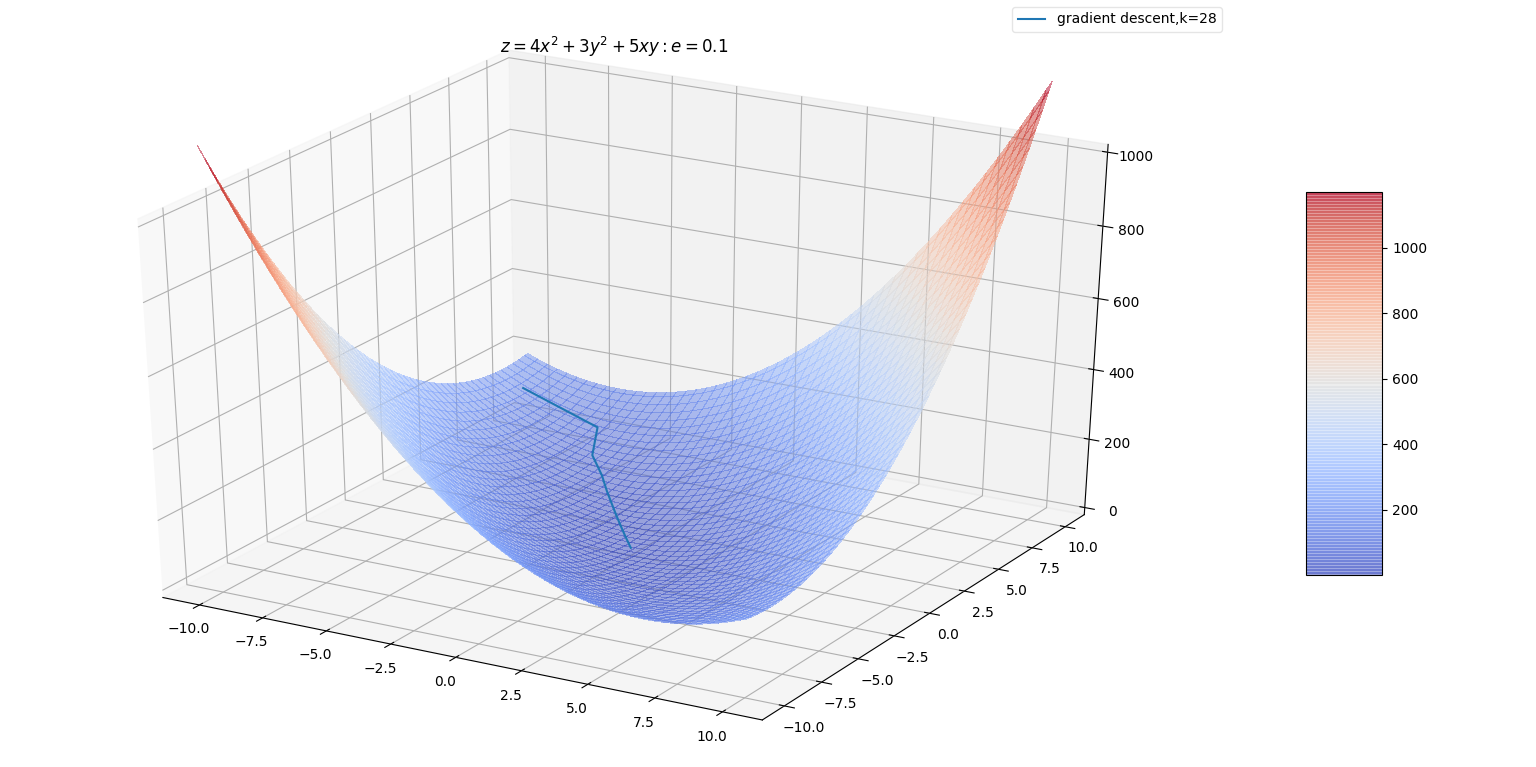
2. 下图是利用梯度下降法寻找函数最小值的路径。
- 该函数是二次函数,海森矩阵条件数为 5,表明最大曲率是最小曲率的5倍。
- 红线为梯度下降的搜索路径。(它没有用最速下降法,而是用到线性搜索。如果是最速下降法,则相邻两次搜索的方向正交)
<center>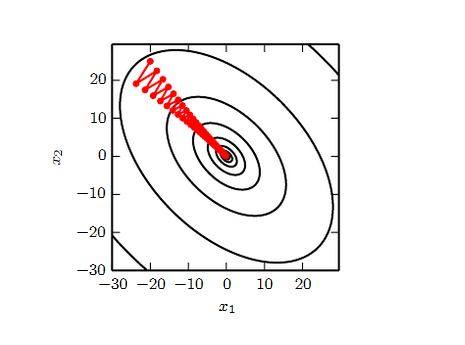</center>
3. 牛顿法结合了海森矩阵。
考虑泰勒展开式:
$$f(\mathbf{\vec x}) \approx f(\mathbf{\vec x}_0)+(\mathbf{\vec x}-\mathbf{\vec x}_0 )^{T}\mathbf{\vec g}+\frac 12(\mathbf{\vec x}-\mathbf{\vec x}_0)^{T}\mathbf H (\mathbf{\vec x}-\mathbf{\vec x}_0)$$ 其 $\mathbf{\vec g}$ $\mathbf{\vec x}_0$ 处的梯度 $\mathbf H$ $\mathbf{\vec x}_0$ 处的海森矩阵。
如 $\mathbf{\vec x}$ 为极值点,则有 $\frac{\partial}{\partial \mathbf{\vec x}}f(\mathbf{\vec x})=\mathbf{\vec 0}$ ,则有:
$$\mathbf{\vec x}^{*}=\mathbf{\vec x}_0 -\mathbf H^{-1}\mathbf{\vec g}
$$\epsilon^{*}=\frac{\mathbf{\vec g}^{T}\mathbf{\vec g}}{\mathbf{\vec g}^{T}\mathbf H\mathbf{\vec g}}$$ > 根 $\mathbf{\vec g}^{T}\mathbf H \mathbf{\vec g} \gt 0$ ,很明显有 $\epsilon^{*} \lt \frac{\mathbf{2\vec g}^{T}\mathbf{\vec g}}{\mathbf{\vec g}^{T}\mathbf H\mathbf{\vec g}} $
3. 由于海森矩阵为实对称阵,因此它可以进行特征值分解。
假设其特征值从大到小排列为:
$$\lambda_1,\lambda_2,\cdots,\lambda_n$$ 其瑞利商 $R(\mathbf{\vec x})=\frac{\mathbf{\vec x}^{T}\mathbf H\mathbf{\vec x}}{\mathbf{\vec x}^{T}\mathbf{\vec x}},\mathbf{\vec x} \ne \mathbf{\vec 0}$ ,可以证明:
$$\lambda_n \le R(\mathbf{\vec x}) \le \lambda_1\\
\lambda_1=\max_{\mathbf{\vec x}\ne \mathbf{\vec 0}} R(\mathbf{\vec x})\\
\lambda_n=\min_{\mathbf{\vec x}\ne \mathbf{\vec 0}} R(\mathbf{\vec x}) $$ 根据:
$$\epsilon^{*}=\frac{\mathbf{\vec g}^{T}\mathbf{\vec g}}{\mathbf{\vec g}^{T}\mathbf H\mathbf{\vec g}}=\frac{1}{R(\mathbf{\vec g})}$$ 可知海森矩阵决定了学习率的取值范围。
- 最坏的情况下,梯度 $\mathbf{\vec g}$ 与海森矩阵最大特征值 $\lambda_1$ 对应的特征向量平行,则此时最优学习率为 $\frac {1}{\lambda_1}$
### 4.4 驻点与全局极小点
1. 满足导数为零的点( $f^{\prime}(x)=0$ )称作驻点。驻点可能为下面三种类型之一:
- 局部极小点:在 $x$ 的一个邻域内,该点的值最小
- 局部极大点:在 $x$ 的一个邻域内,该点的值最大
- 鞍点:既不是局部极小,也不是局部极大
<center></center>
2. 全局极小点 $x^{*}=\arg\min_x f(x)$ 。
- 全局极小点可能有一个或者多个
- 在深度学习中,目标函数很可能具有非常多的局部极小点,以及许多位于平坦区域的鞍点。这使得优化非常不利。因此通常选取一个非常低的目标函数值,而不一定要是全局最小值。
<center></center>
3. 二阶导数可以配合一阶导数来决定驻点的类型:
- 局部极小点 $f^{\prime}(x)=0,f^{\prime\prime}(x)\gt 0$
- 局部极大点 $f^{\prime}(x)=0,f^{\prime\prime}(x)\lt 0$
- $f^{\prime}(x)=0,f^{\prime\prime}(x)= 0$ :驻点的类型可能为任意三者之一。
4. 对于多维的情况类似:
- 局部极小点 $\nabla _{\mathbf{\vec x}} f(\mathbf{\vec x})=0 $ ,且海森矩阵为正定的(即所有的特征值都是正的)。
- 当海森矩阵为正定时,任意方向的二阶偏导数都是正的。
- 局部极大点 $\nabla _{\mathbf{\vec x}} f(\mathbf{\vec x})=0 $ ,且海森矩阵为负定的(即所有的特征值都是负的)。
- 当海森矩阵为负定时,任意方向的二阶偏导数都是负的。
- $\nabla _{\mathbf{\vec x}} f(\mathbf{\vec x})=0 $ ,且海森矩阵的特征值中至少一个正值、至少一个负值时,为鞍点。
- 当海森矩阵非上述情况时,驻点类型无法判断。
下图 $f(\mathbf{\vec x})=x_1^{2}-x_2^{2}$ 在原点附近的等值线。其海森矩阵为一正一负。
- 沿着 $x_1$ 方向,曲线向上;沿着 $x_2$ 方向,曲线向下。
- 鞍点就是在一个横截面内的局部极小值,另一个横截面内的局部极大值。
<center></center>
## 四、牛顿法
1. 梯度下降法有个缺陷:它未能利用海森矩阵的信息
- 当海森矩阵的条件数较大时,不同方向的梯度的变化差异很大。
- 在某些方向上,梯度变化很快;在有些方向上,梯度变化很慢
- 梯度下降法未能利用海森矩阵,也就不知道应该优先搜索导数长期为负的方向。
> 本质上应该沿着负梯度方向搜索。但是沿着该方向的一段区间内,如果导数一直为负,则可以直接跨过该区间。前提是:必须保证该区间内,该方向导数一直为负。
- 当海森矩阵的条件数较大时,也难以选择合适的步长。
- 步长必须足够小,从而能够适应较强曲率的地方(对应着较大的二阶导数,即该区域比较陡峭)
- 但是如果步长太小,对于曲率较小的地方(对应着较小的二阶导数,即该区域比较平缓)则推进太慢。
> 曲率刻画弯曲程度,曲率越大则曲率半径越小
2. 下图是利用梯度下降法寻找函数最小值的路径。
- 该函数是二次函数,海森矩阵条件数为 5,表明最大曲率是最小曲率的5倍。
- 红线为梯度下降的搜索路径。(它没有用最速下降法,而是用到线性搜索。如果是最速下降法,则相邻两次搜索的方向正交)
<center></center>
3. 牛顿法结合了海森矩阵。
考虑泰勒展开式:
$$f(\mathbf{\vec x}) \approx f(\mathbf{\vec x}_0)+(\mathbf{\vec x}-\mathbf{\vec x}_0 )^{T}\mathbf{\vec g}+\frac 12(\mathbf{\vec x}-\mathbf{\vec x}_0)^{T}\mathbf H (\mathbf{\vec x}-\mathbf{\vec x}_0)$$ 其 $\mathbf{\vec g}$ $\mathbf{\vec x}_0$ 处的梯度 $\mathbf H$ $\mathbf{\vec x}_0$ 处的海森矩阵。
如 $\mathbf{\vec x}$ 为极值点,则有 $\frac{\partial}{\partial \mathbf{\vec x}}f(\mathbf{\vec x})=\mathbf{\vec 0}$ ,则有:
$$\mathbf{\vec x}^{*}=\mathbf{\vec x}_0 -\mathbf H^{-1}\mathbf{\vec g}
- 当 $f$ 是个正定的二次型,则牛顿法直接一次就能到达最小值点
- 当 $f$ 不是正定的二次型,则可以在局部近似为正定的二次型,那么则采用多次牛顿法即可到达最小值点。
- 一维情况下,梯度下降法和牛顿法的原理展示:
- 梯度下降法:下一次迭代的 $\mathbf {\vec x}^{<k+1>}=\mathbf {\vec x}^{<k>}-\epsilon_k \nabla f(\mathbf {\vec x})$ 。
- 对于一维的情况,可以固定 $\epsilon_k=\eta$ ,由于随着迭代的推进 $f^{\prime}(x)$ 绝对值是减小的(直到0),因此越靠近极值点 $\Delta(x)$ 越小
- 牛顿法:目标 $\nabla f(\mathbf {\vec x})=0$ 。在一维情况下就是求 $f^\prime (x)=0$ 。牛顿法的方法是: $x=x^{<k>}$ $y=f^{\prime}(x)$ 切线,该切线过 $(x^{<k>},f^{\prime}(x^{<k>}))$ 。该切线 $x$ 轴上的交点就是
x<k+1>=x<k>−f′(x<k>)f′′(x<k>)$$推广到多维情况下就是:$$→x<k+1>=→x<k>−H−1k→gk
- 当位于一个极小值点附近时,牛顿法比梯度下降法能更快地到达极小值点。
- 如果在一个鞍点附近,牛顿法效果很差;而梯度下降法此时效果较好(除非负梯度的方向刚好指向了鞍点)。
- 仅仅利用了梯度的优化算法(如梯度下降法)称作一阶优化算法;同时利用了海森矩阵的优化算法(如牛顿法)称作二阶优化算法
- 牛顿法算法:
- 输入:
- 目标函数 f(→x)
- 梯度 g(→x)=∇f(→x)
- 海森矩阵 H(→x)
- 精度要求 e
- 输出 f(→x) 的极小值 →x∗
- 算法步骤:
- 选取初始 →x<0>∈Rn , k=0
- 计 →gk=g(→x<k>)
- |→gk|<e ,则停止计算,得到近似 →x=→x∗
- |→gk|≥e ,则:
- 计算 Hk=H(→x<k>) ,并求 →pk,Hk→pk=−→gk
- 置 →x<k+1>=→x<k>+→pk
- 置 k=k+1 ,计算 →gk=g(→x<k>) ,迭代
- 输入:
- 梯度下降法中,每一 →x 增加的方向一定是梯度相反的方 −ϵk∇k
- 增加的幅度由 ϵk 决定,若跨度过大容易引发震荡;
而牛顿法中,每一 →x 增加的方向是梯度增速最大的反方 −H−1k∇k (它通常情况下与梯度不共线) - 增加的幅度已经包含在 H−1k 中(也可以乘以学习率作为幅度的系数)
- 增加的幅度由 ϵk 决定,若跨度过大容易引发震荡;
- 深度学习中的目标函数非常复杂,无法保证可以通过上述优化算法进行优化。因此有时会限定目标函数具有
Lipschitz连续,或者其导数Lipschitz连续。Lipschitz连续的定义:对于函数 f ,存在一个Lipschitz常数 L ,使得
∀→x,∀→y,|f(→x)−f(→y)|≤L||→x−→y||2
- `Lipschitz`连续的意义是:输入的一个很小的变化,会引起输出的一个很小的变化。
与之相反的是:输入的一个很小的变化,会引起输出的一个很大的变化
- 凸优化在某些特殊的领域取得了巨大的成功。但是在深度学习中,大多数优化问题都难以用凸优化来描述。
凸优化的重要性在深度学习中大大降低。凸优化仅仅作为一些深度学习算法的子程序。
五、拟牛顿法
5.1 原理
- 在牛顿法的迭代中,需要计算海森矩阵的逆矩 H−1 ,这一计算比较复杂。
- 可以考虑用一个 n 阶矩阵 Gk=G(→x<k>) 来近似代替 H−1k=H−1(→x<k>) 。
- 先看海森矩阵满足的条件 →gk+1−→gk=Hk(→x<k+1>−→x<k>)
- 令 →yk=→gk+1−→gk,→δk=→x<k+1>−→x<k> 则有 →yk=Hk→δk ,或者 H−1k→yk=→δk 。这称为拟牛顿条件
- 根据牛顿法的迭代: →x<k+1>=→x<k>−H−1k→gk ,将 f(→x) 在 →x<k> 的一阶泰勒展开:
f(\mathbf {\vec x}^{<k+1>})=f(\mathbf {\vec x}^{<k>})+f'(\mathbf {\vec x}^{<k>})(\mathbf {\vec x}^{<k+1>}-\mathbf {\vec x}^{<k>})\\
=f(\mathbf {\vec x}^{<k>})+\mathbf {\vec g}_k^{T}(-\mathbf H_k^{-1}\mathbf {\vec g}_k)=f(\mathbf {\vec x}^{<k>})-\mathbf {\vec g}_k^{T}\mathbf H^{-1}_k\mathbf {\vec g}_k$$ $\mathbf H_k$ 是正定矩阵时,总 $f(\mathbf {\vec x}^{<k+1>})<f(\mathbf {\vec x}^{<k>})$ ,因此每次都是沿着函数递减的方向迭代
3. 拟牛顿法如果选 $\mathbf G_k$ 作 $\mathbf H_k^{-1}$ 的近似时 $\mathbf G_k$ 同样要满足两个条件:
- $\mathbf G_k$ 必须是正定的
- $\mathbf G_k$ 满足拟牛顿条件 $\mathbf G_{k+1}\mathbf {\vec y}_k=\vec \delta_k$
> 因 $\mathbf G_0$ 是给定的初始化条件,所以下标 $k+1$ 开始
按照拟牛顿条件,在每次迭代中可以选择更新矩 $\mathbf G_{k+1}=\mathbf G_k+\Delta \mathbf G_k$
4. 正定矩阵定义: $\mathbf M$ $n\times n$ 阶方阵,如果对任何非零向 $\mathbf {\vec x}$ ,都 $\mathbf {\vec x}^{T} \mathbf M \mathbf {\vec x} \gt 0$ ,就 $\mathbf M$ 正定矩阵
- 正定矩阵判定:
- 判定定理1:对称阵 $\mathbf M$ 为正定的充分必要条件是 $\mathbf M$ 的特征值全为正。
- 判定定理2:对称阵 $\mathbf M$ 为正定的充分必要条件是 $\mathbf M$ 的各阶顺序主子式都为正。
- 判定定理3:任意阵 $\mathbf M$ 为正定的充分必要条件是 $\mathbf M$ 合同于单位阵。
- 正定矩阵的性质:
- 正定矩阵一定是非奇异的。奇异矩阵的定义:若 $n\times n$ 阶矩阵 $\mathbf M$ 为奇异阵,则其的行列式为零,即 $|\mathbf M|=0$ 。
- 正定矩阵的任一主子矩阵也是正定矩阵。
- 若 $\mathbf M$ $n\times n$ 阶对称正定矩阵,则存在唯一的主对角线元素都是正数的下三角阵 $\mathbf L$ ,使得 $\mathbf M=\mathbf L\mathbf L^{T}$ ,此分解式称为 正定矩阵的乔列斯基(`Cholesky`)分解。
- 若 $\mathbf M$ 为 $n\times n$ 阶正定矩阵,则 $\mathbf M$ 为 $n\times n$ 阶可逆矩阵。
- 正定矩阵在某个合同变换下可化为标准型,即对角矩阵。
- 所有特征值大于零的对称矩阵也是正定矩阵。
5. 合同矩阵:两个实对称矩 $\mathbf A$ $\mathbf B$ 是合同的,当且仅当存在一个可逆矩 $\mathbf P$ ,使 $\mathbf A=\mathbf P^{T}\mathbf B\mathbf P$
- $\mathbf A$ 的合同变换:对某个可逆矩阵 $\mathbf P$ ,对 $\mathbf A$ 执行 $\mathbf P^{T}\mathbf A\mathbf P$
### 5.2 DFP 算法
1. DFP算法(`Davidon-Fletcher-Powell`)选 $\mathbf G_{k+1}$ 的方法是:
假设每一步迭代 $\mathbf G_{k+1}$ 是 $\mathbf G_k$ 加上两个附加项构成 $\mathbf G_{k+1}=\mathbf G_k+\mathbf P_k+\mathbf Q_k$ ,其 $\mathbf P_k,\mathbf Q_k$ 是待定矩阵。此时有 $\mathbf G_{k+1}\mathbf {\vec y}_k=\mathbf G_k\mathbf {\vec y}_k+\mathbf P_k\mathbf {\vec y}_k+\mathbf Q_k\mathbf {\vec y}_k$ 。
为了满足拟牛顿条件,可以取 $\mathbf P_k\mathbf {\vec y}_k=\vec \delta_k,\quad \mathbf Q_k\mathbf {\vec y}_k =-\mathbf G_k\mathbf {\vec y}_k$ 。
2. 这样 $\mathbf P_k,\mathbf Q_k$ 不止一个。例如取
$$\mathbf P_k=\frac{\vec \delta_k\vec \delta_k^{T}}{\vec \delta_k^{T}\mathbf {\vec y}_k},\quad \mathbf Q_k=-\frac{\mathbf G_k\mathbf {\vec y}_k \mathbf {\vec y}_k^{T} \mathbf G_k}{\mathbf {\vec y}_k^{T}\mathbf G_k \mathbf {\vec y}_k}$$
> 这 $\vec \delta_k,\mathbf {\vec y}_k$ 都是列向量
则迭代公式为:
$$\mathbf G_{k+1}=\mathbf G_k+\frac{\vec \delta_k\vec \delta_k^{T}}{\vec \delta_k^{T}\mathbf {\vec y}_k}-\frac{\mathbf G_k\mathbf {\vec y}_k \mathbf {\vec y}_k^{T} \mathbf G_k}{\mathbf {\vec y}_k^{T} \mathbf G_k \mathbf {\vec y}_k}
=f(\mathbf {\vec x}^{<k>})+\mathbf {\vec g}_k^{T}(-\mathbf H_k^{-1}\mathbf {\vec g}_k)=f(\mathbf {\vec x}^{<k>})-\mathbf {\vec g}_k^{T}\mathbf H^{-1}_k\mathbf {\vec g}_k$$ $\mathbf H_k$ 是正定矩阵时,总 $f(\mathbf {\vec x}^{<k+1>})<f(\mathbf {\vec x}^{<k>})$ ,因此每次都是沿着函数递减的方向迭代
3. 拟牛顿法如果选 $\mathbf G_k$ 作 $\mathbf H_k^{-1}$ 的近似时 $\mathbf G_k$ 同样要满足两个条件:
- $\mathbf G_k$ 必须是正定的
- $\mathbf G_k$ 满足拟牛顿条件 $\mathbf G_{k+1}\mathbf {\vec y}_k=\vec \delta_k$
> 因 $\mathbf G_0$ 是给定的初始化条件,所以下标 $k+1$ 开始
按照拟牛顿条件,在每次迭代中可以选择更新矩 $\mathbf G_{k+1}=\mathbf G_k+\Delta \mathbf G_k$
4. 正定矩阵定义: $\mathbf M$ $n\times n$ 阶方阵,如果对任何非零向 $\mathbf {\vec x}$ ,都 $\mathbf {\vec x}^{T} \mathbf M \mathbf {\vec x} \gt 0$ ,就 $\mathbf M$ 正定矩阵
- 正定矩阵判定:
- 判定定理1:对称阵 $\mathbf M$ 为正定的充分必要条件是 $\mathbf M$ 的特征值全为正。
- 判定定理2:对称阵 $\mathbf M$ 为正定的充分必要条件是 $\mathbf M$ 的各阶顺序主子式都为正。
- 判定定理3:任意阵 $\mathbf M$ 为正定的充分必要条件是 $\mathbf M$ 合同于单位阵。
- 正定矩阵的性质:
- 正定矩阵一定是非奇异的。奇异矩阵的定义:若 $n\times n$ 阶矩阵 $\mathbf M$ 为奇异阵,则其的行列式为零,即 $|\mathbf M|=0$ 。
- 正定矩阵的任一主子矩阵也是正定矩阵。
- 若 $\mathbf M$ $n\times n$ 阶对称正定矩阵,则存在唯一的主对角线元素都是正数的下三角阵 $\mathbf L$ ,使得 $\mathbf M=\mathbf L\mathbf L^{T}$ ,此分解式称为 正定矩阵的乔列斯基(`Cholesky`)分解。
- 若 $\mathbf M$ 为 $n\times n$ 阶正定矩阵,则 $\mathbf M$ 为 $n\times n$ 阶可逆矩阵。
- 正定矩阵在某个合同变换下可化为标准型,即对角矩阵。
- 所有特征值大于零的对称矩阵也是正定矩阵。
5. 合同矩阵:两个实对称矩 $\mathbf A$ $\mathbf B$ 是合同的,当且仅当存在一个可逆矩 $\mathbf P$ ,使 $\mathbf A=\mathbf P^{T}\mathbf B\mathbf P$
- $\mathbf A$ 的合同变换:对某个可逆矩阵 $\mathbf P$ ,对 $\mathbf A$ 执行 $\mathbf P^{T}\mathbf A\mathbf P$
### 5.2 DFP 算法
1. DFP算法(`Davidon-Fletcher-Powell`)选 $\mathbf G_{k+1}$ 的方法是:
假设每一步迭代 $\mathbf G_{k+1}$ 是 $\mathbf G_k$ 加上两个附加项构成 $\mathbf G_{k+1}=\mathbf G_k+\mathbf P_k+\mathbf Q_k$ ,其 $\mathbf P_k,\mathbf Q_k$ 是待定矩阵。此时有 $\mathbf G_{k+1}\mathbf {\vec y}_k=\mathbf G_k\mathbf {\vec y}_k+\mathbf P_k\mathbf {\vec y}_k+\mathbf Q_k\mathbf {\vec y}_k$ 。
为了满足拟牛顿条件,可以取 $\mathbf P_k\mathbf {\vec y}_k=\vec \delta_k,\quad \mathbf Q_k\mathbf {\vec y}_k =-\mathbf G_k\mathbf {\vec y}_k$ 。
2. 这样 $\mathbf P_k,\mathbf Q_k$ 不止一个。例如取
$$\mathbf P_k=\frac{\vec \delta_k\vec \delta_k^{T}}{\vec \delta_k^{T}\mathbf {\vec y}_k},\quad \mathbf Q_k=-\frac{\mathbf G_k\mathbf {\vec y}_k \mathbf {\vec y}_k^{T} \mathbf G_k}{\mathbf {\vec y}_k^{T}\mathbf G_k \mathbf {\vec y}_k}$$
> 这 $\vec \delta_k,\mathbf {\vec y}_k$ 都是列向量
则迭代公式为:
$$\mathbf G_{k+1}=\mathbf G_k+\frac{\vec \delta_k\vec \delta_k^{T}}{\vec \delta_k^{T}\mathbf {\vec y}_k}-\frac{\mathbf G_k\mathbf {\vec y}_k \mathbf {\vec y}_k^{T} \mathbf G_k}{\mathbf {\vec y}_k^{T} \mathbf G_k \mathbf {\vec y}_k}
> 其中的向 $\vec \delta_k,\mathbf {\vec y}_k$ 都是列向量
- 可以证明,如果初始矩 G0 是正定的,则迭代过程中每个矩 Gk 都是正定的
- DFP算法:
- 输入:
- 目标函数 f(→x)
- 梯度 g(→x)=∇f(→x)
- 精度要求 e
- 输出 f(→x) 的极小值 →x∗
- 算法步骤:
- 选取初始 →x<0>∈Rn , G0 为正定对称矩阵, k =0
- 计 →gk=g(→x<k>)
- |→gk|<e ,则停止计算,得到近似 →x=→x∗
- |→gk|≥e ,则:
- 计算 →pk=−Gk→gk
- 一维搜索:求 ϵk : ϵk=minϵ≥0f(→x<k>+ϵ→pk)
- 设置 →x<k+1>=→x<k>+ϵk→pk
- 计算 →gk+1=g(→x<k+1>) 。若 |→gk+1|<ε , 则停止计算,得到近似解 →x=→x∗
- 否则计算 Gk+1 ,置 k=k+1 ,计算 →pk=−Gk→gk 迭代
- 输入:
- DFP算法中,每一 →x 增加的方向 −Gk∇k 的方向。增加的幅度 ϵk 决定,若跨度过大容易引发震荡
5.2 BFGS 算法
- BFGS是最流行的拟牛顿算法。DFP算法中, Gk 逼 H−1 。换个角度可以用矩 Bk 逼近海森矩 H 。此时对应的拟牛顿条件为 Bk+1→δk=→yk 。
因 B0 是给定的初始化条件,所以下标 k+1 开始
- 令 Bk+1=Bk+Pk+Qk ,有 Bk+1→δk=Bk→δk+Pk→δk+Qk→δk
可以 Pk→δk=→yk,Qk→δk=−Bk→δk 。寻找合适 Pk,Qk ,可以得到BFGS算法矩阵 Bk+1 的迭代公式:
Bk+1=Bk+→yk→yTk→yTk→δk−Bk→δk→δTkBk→δTkBk→δk
其中的向 →δk,→yk 都是列向量
- 可以证明, B0 是正定的,则迭代过程中每个矩 Bk 都是正定的。
- BFGS算法:
- 输入:
- 目标函数 f(→x)
- 梯度 g(→x)=∇f(→x)
- 精度要求 e
- 输出 f(→x) 的极小值 →x∗
- 算法步骤:
- 选取初始 →x<0>∈Rn , B0 为正定对称矩阵, k =0
- 计 →gk=g(→x<k>)
-
|→gk|<e ,则停止计算,得到近似 →x=→x∗
-
|→gk|≥e ,则:
- Bk→pk=−→gk 求 →pk
这里表面上看需要对矩阵求逆。但是实际 B−1k 有迭代公式。根据
Sherman-Morrison公式以 Bk 的迭代公式,可以得 B−1k 的迭代公式- 一维搜索: ϵk ϵk=minϵ≥0f(→x<k>+ϵ→pk)
- 设 →x<k+1>=→x<k>+ϵk→pk
- 计 →gk+1=g(→x<k+1>) 。 |→gk+1|<e ,则停止计算,得到近似 →x=→x∗
- 否则计算,置 =k+1 。 Bk→pk=−→gk 求 →pk ,迭代
-
- 输入:
- BFPS算法中,每一 →x 增加的方向 −B−1k∇k 的方向。增加的幅度 ϵk 决定,若跨度过大容易引发震荡
5.3 Broyden 类算法
- 若 Gk=B−1k,Gk+1=B−1k+1 ,则对式子
Bk+1=Bk+→yk→yTk→yTk→δk−Bk→δk→δTkBk→δTkBk→δk$$使用两次‘Sherman−Morrison‘公式可得:$$Gk+1=(I−→δk→yTk→δTk→yk)Gk(I−→δk→yTk→δTk→yk)T+→δk→δTk→δTk→yk$$>其中的向$→δk,→yk$都是列向量2.令DFP算法获得$Gk+1$的迭代公式记作$$GDFP=Gk+→δk→δTk→δTk→yk−Gk→yk→yTkGk→yTkGk→yk$$由BFGS算法获得$Gk+1$的迭代公式记作$$GBFGS=(I−→δk→yTk→δTk→yk)Gk(I−→δk→yTk→δTk→yk)T+→δk→δTk→δTk→yk$$他们都满足拟牛顿条件,所以他们的线性组合$Gk+1=αGDFP+(1−α)GBFGS$也满足拟牛顿条件,而且是正定的。其$0≤α≤1$。这样获得了一族拟牛顿法,称为Broyden类算法3.‘Sherman−Morrison‘公式:假$A$$n$阶可逆矩阵$→u,→v$$n$维列向量,$A+→u→vT$也是可逆矩阵,则:$$(A+→u→vT)−1=A−1−A−1→u→vTA−11+→vTA−1→u
六、 约束优化
6.1 原理
- 在有的最优化问题中,希望输 →x 位于特定的集 S 中,这称作约束优化问题。
- 集 S 内的点 →x 称作可行解
- 集合 S 也称作可行域。
- 约束优化的一个简单方法是:对梯度下降法进行修改。
- 每次迭代后,将得到的新 →x 映射到集 S 中
- 如果使用线性搜索:则每次只搜索那些使得新 →x 位于集 S 中的那 ϵ
- 另一个做法:将线性搜索得到的新的 →x 映射到集合 S 中。
- 或者:在线性搜索之前,将梯度投影到可行域的切空间内
6.2 KKT 方法
- 在约束最优化问题中,常常利用拉格朗日对偶性将原始问题转换为对偶问题,通过求解对偶问题而得到原始问题的解。
- 约束最优化问题的原始问题:
假 f(→x),ci(→x),hj(→x) 是定义 Rn 上的连续可微函数。考虑约束最优化问题:
min→x∈Rnf(→x)s.t.ci(→x)≤0,i=1,2,⋯,k;hj(→x)=0,j=1,2,⋯,l$$可行域由等式和不等式确定$$S={→x∣ci(→x)≤0,i=1,2,⋯,k;hj(→x)=0,j=1,2,⋯,l}
6.2.1 原始问题
- 引入拉格朗日函数:
L(→x,→α,→β)=f(→x)+k∑i=1αici(→x)+l∑j=1βjhj(→x)$$这$→x=(x(1),x(2),⋯,x(n))T∈Rn,αi,βj$是拉格朗日乘子$αi≥0$−$L(→x,→α→β)$是$→x,→α,→β$的多元非线性函数2.定义函数:$$θP(→x)=max→α,→β:αi≥0L(→x,→α,→β)$$其中下$P$表示原始问题。则有:$$θP(→x)={f(→x),if →x statisfy original problem's constraint+∞,or else.
- $\mathbf {\vec x}$ 满足原问题的约束,则很容易证 $L(\mathbf {\vec x},\vec \alpha,\vec\beta)=f(\mathbf {\vec x})+\sum_{i=1}^{k}\alpha_ic_i(\mathbf {\vec x}) \le f(\mathbf {\vec x})$ ,等号 $\alpha_i=0$ 时取到
- $\mathbf {\vec x}$ 不满足原问题的约束:
- 若不满足 $ c_i(\mathbf {\vec x}) \le 0$ :设违反的为 $c_{i0}(\mathbf {\vec x}) \gt 0$ ,则令 $\vec \alpha_{i0} \rightarrow \infty$ , $L(\mathbf {\vec x},\vec \alpha,\vec\beta)=f(\mathbf {\vec x})+\sum_{i=1}^{k}\alpha_ic_i(\mathbf {\vec x}) \rightarrow \infty$
- 若不满足 $ h_j(\mathbf {\vec x}) = 0$ : 设违反的为 $h_{j0}(\mathbf {\vec x}) \ne 0$ ,则令 $\vec\beta_{j0}h_{j0}(\mathbf {\vec x}) \rightarrow \infty$ , $L(\mathbf {\vec x},\vec \alpha,\vec\beta)=f(\mathbf {\vec x})+\sum_{i=1}^{k}\alpha_ic_i(\mathbf {\vec x})+\vec\beta_{j0}h_{j0}(\mathbf {\vec x}) \rightarrow \infty$
- 考虑极小化问题:
\min_{\mathbf {\vec x}} \theta_P(\mathbf {\vec x})=\min_{\mathbf {\vec x}}\max_{\vec \alpha,\vec\beta\;:\;\alpha_i \ge 0}L(\mathbf {\vec x},\vec \alpha, \vec\beta)$$ 则该问题是与原始最优化问题是等价的,即他们有相同的问题。
- $\min_{\mathbf {\vec x}}\max_{\vec \alpha,\vec\beta\;:\;\alpha_i \ge 0}L(\mathbf {\vec x},\vec \alpha, \vec\beta)$ 称为广义拉格朗日函数的极大极小问题。
- 为了方便,定义原始问题的最优值为:
$$p^{*}=\min_{\mathbf {\vec x}}\theta_P(\mathbf {\vec x})$$
#### 6.2.2 对偶问题
1. 对偶问题:定 $\theta_D(\vec \alpha,\vec\beta)=\min_\mathbf {\vec x} L(\mathbf {\vec x},\vec \alpha,\vec\beta)$ 。考虑极大 $\theta_D(\vec \alpha,\vec\beta)$ ,即:
$$\max_{\vec \alpha,\vec\beta\;:\;\alpha_i \ge 0}\theta_D(\vec \alpha,\vec\beta)=\max_{\vec \alpha,\vec\beta\;:\;\alpha_i \ge 0} \min_{\mathbf {\vec x}}L(\mathbf {\vec x},\vec \alpha, \vec\beta)
- $\min_{\mathbf {\vec x}}\max_{\vec \alpha,\vec\beta\;:\;\alpha_i \ge 0}L(\mathbf {\vec x},\vec \alpha, \vec\beta)$ 称为广义拉格朗日函数的极大极小问题。
- 为了方便,定义原始问题的最优值为:
$$p^{*}=\min_{\mathbf {\vec x}}\theta_P(\mathbf {\vec x})$$
#### 6.2.2 对偶问题
1. 对偶问题:定 $\theta_D(\vec \alpha,\vec\beta)=\min_\mathbf {\vec x} L(\mathbf {\vec x},\vec \alpha,\vec\beta)$ 。考虑极大 $\theta_D(\vec \alpha,\vec\beta)$ ,即:
$$\max_{\vec \alpha,\vec\beta\;:\;\alpha_i \ge 0}\theta_D(\vec \alpha,\vec\beta)=\max_{\vec \alpha,\vec\beta\;:\;\alpha_i \ge 0} \min_{\mathbf {\vec x}}L(\mathbf {\vec x},\vec \alpha, \vec\beta)
- 问题 $\max_{\vec \alpha,\vec\beta\;:\;\alpha_i \ge 0} \min_{\mathbf {\vec x}}L(\mathbf {\vec x},\vec \alpha, \vec\beta)$ 称为广义拉格朗日函数的极大极小问题。
- 可以将广义拉格朗日函数的极大极小问题表示为约束最优化问题:
max→α,→β:αi≥0θD(→α,→β)=max→α,→β:αi≥0min→xL(→x,→α,→β)s.t.αi≥0,i=1,2,⋯,k$$称为原始问题的对偶问题。3.定义对偶问题的最优值:$$d∗=max→α,→β:αi≥0θD(→α,→β)
6.2.3 原始问题与对偶问题关系
- 定理一:若原问题和对偶问题具有最优值,则:
d∗=max→α,→β:→αi≥0min→xL(→x,→α,→β)≤min→xmax→α,→β:→αi≥0L(→x,→α,→β)=p∗
- 推论一: →x∗ 为原始问题的可行解, θP(→x∗) 的值 p∗ →α∗,→β∗ 为对偶问题的可行解 θD(→α∗,→β∗) 值 d∗ 。
如果 p∗=d∗ , →x∗,→α∗,→β∗ 分别为原始问题和对偶问题的最优解。 - 定理二:假设函 f(→x) ci(→x) 为凸函数 hj(→x) 是仿射函数;并且假设不等式约 ci(→x) 是严格可行的,即存 →x ,对于所 i ci(x)<0 。
则存 →x∗,→α∗,→β∗ ,使得 →x∗ 是原始问 min→xθP(→x) 的解 →α∗,→β∗ 是对偶问 max→α,→β:αi≥0θD(→α,→β) 的解,并 p∗=d∗=L(→x∗,→α∗,→β∗) - 定理三:假设函 f(→x) ci(→x) 为凸函数 hj(→x) 是仿射函数;并且假设不等式约 ci(→x) 是严格可行的,即存 →x ,对于所 i ci(x)<0 。
则存 →x∗,→α∗,→β∗ ,使 →x∗ 是原始问 min→xθP(→x) 的解 →α∗,→β∗ 是对偶问 max→α,→β:αi≥0θD(→α,→β) 的解的充要条件是 →x∗,→α∗,→β∗ 满足下面的Karush-kuhn-Tucker(KKT)条件:
∇→xL(→x∗,→α∗,→β∗)=0∇→αL(→x∗,→α∗,→β∗)=0∇→βL(→x∗,→α∗,→β∗)=0→α∗ici(→x∗)=0,i=1,2,⋯,kci(→x∗)≤0,i=1,2,⋯,k→α∗i≥0,i=1,2,⋯,khj(→x∗)=0,j=1,2,⋯,l
- 仿射函数:仿射函数即由1阶多项式构成的函数。
一般形式 f(→x)=A→x+b ,这里 A 是一 m×k 矩阵 →x 是一 k 维列向量 b 是一 m 维列向量- 它实际上反映了一种从 k 维到 m 维的空间映射关系。
- 凸函数: f 为定义在区 I 上的函数,若 I 上的任意两 →x1,→x2 和任意的实 λ∈(0,1) ,总 f(λ→x1+(1−λ)→x2)≥λf(→x1)+(1−λ)f(→x2) f 称 I 上的凸函数
本文转载自华校专老师博客,博客地址:http://www.huaxiaozhuan.com/
作者:郭耀华
出处:http://www.guoyaohua.com
微信:guoyaohua167
邮箱:guo.yaohua@foxmail.com
本文版权归作者和博客园所有,欢迎转载,转载请标明出处。
【如果你觉得本文还不错,对你的学习带来了些许帮助,请帮忙点击右下角的推荐】
出处:http://www.guoyaohua.com
微信:guoyaohua167
邮箱:guo.yaohua@foxmail.com
本文版权归作者和博客园所有,欢迎转载,转载请标明出处。
【如果你觉得本文还不错,对你的学习带来了些许帮助,请帮忙点击右下角的推荐】




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· 展开说说关于C#中ORM框架的用法!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?