
【Magi】超智能的AI搜索引擎,绝对比百度还牛逼,不信你试试。
引言
相信大家都知道,每当谈到搜索引擎的时候,所想到的肯定是国内的百度和国外的 Google。
针对国内的一些用户,只能通过百度来进行搜索,如果想要通过 Google 搜索的话,大家也都知道,在这就不多说了。
如今,互联网时代的发展经历了翻天覆地的变化,但唯独国内的搜索引擎除百度以外,最近我还发现了一个搜索引擎是基于 AI 梳理互联网的知识引擎——Magi。
Magi 是什么?
Magi是通过机器学习将互联网上的海量信息构建成可解析、可检索、可溯源的结构化知识体系。
“Peak Labs”公司近日发布了其人工智能系统 Magi 的公众版“ http://magi.com ”。通过这一搜索引擎,用户输入关键词,即可获取 Magi 从互联网文本中自主学习到的结构化知识和网页搜索结果,每个结构化结果后面都会附上来源链接和其可信度评分。
这跟我们使用的传统搜索引擎不同,传统搜索引擎返回的是一系列的链接,要解读问题,还需要自己去点击网页挖掘有用信息。
Magi 是由 Peak Labs(https://www.peak-labs.com/) 研发的基于机器学习的信息抽取和检索系统,它能将任何领域的自然语言文本中的知识提取成结构化的数据,通过终身学习持续聚合和纠错,进而为人类用户和其他人工智能提供可解析、可检索、可溯源的知识体系。
Magi 能做什么?
如果您是从 magi.com(https://magi.com/) 来到这里的话,那么恭喜您发现了 Magi 的一半!这个长得很像搜索引擎的网站就是 Magi 的公众版本,但与搜索引擎不同,magi.com 不仅收录互联网上的海量文本,还会去尝试理解并学习这些文本中蕴含的知识和数据。
不妨在 magi.com(使用帮助(https://www.peak-labs.com/docs/zh/magi/help))尝试搜索一些您关心的事物,或者直接提出问题,magi.com 都将竭力为您提供高度聚合的结构化知识结果:
网址:https://magi.com/
这一引擎发布后,引来大批网友围观,把它的服务器玩挂了。Magi 作者发微博做了回应:“突然很多人关注到了我们,真的很感谢大家,其实搜索引擎真的不是我们的主业,我们自己没做任何推广,更没来得及准备应对这恐怖的流量……Magi 单次搜索的计算量比一般的网页搜索要重很多,请大家手下留情,同时再次表示抱歉!”
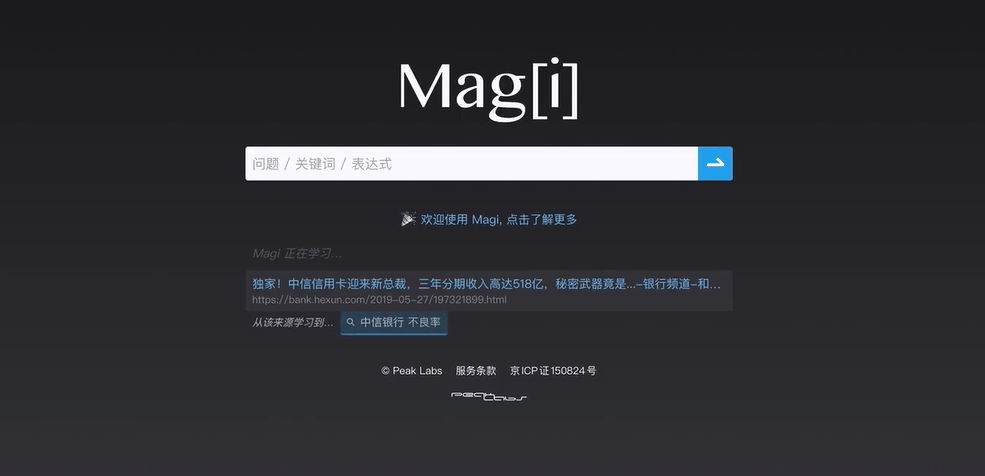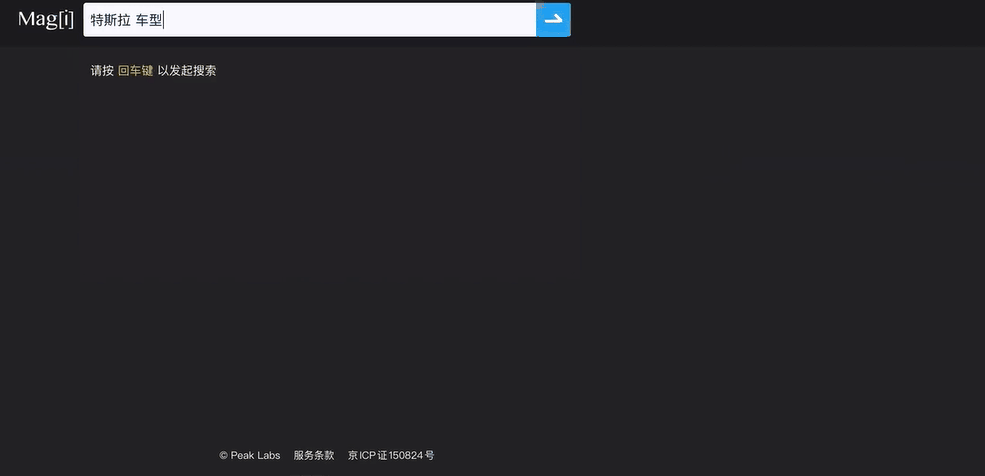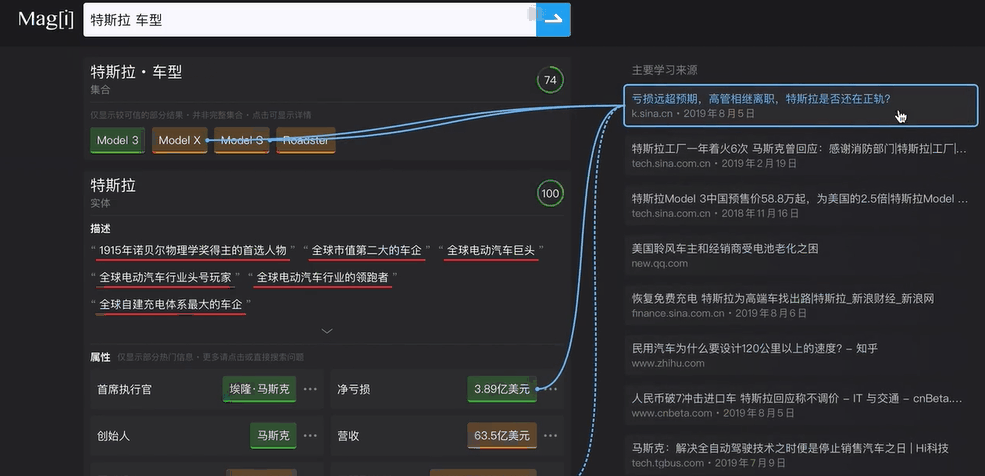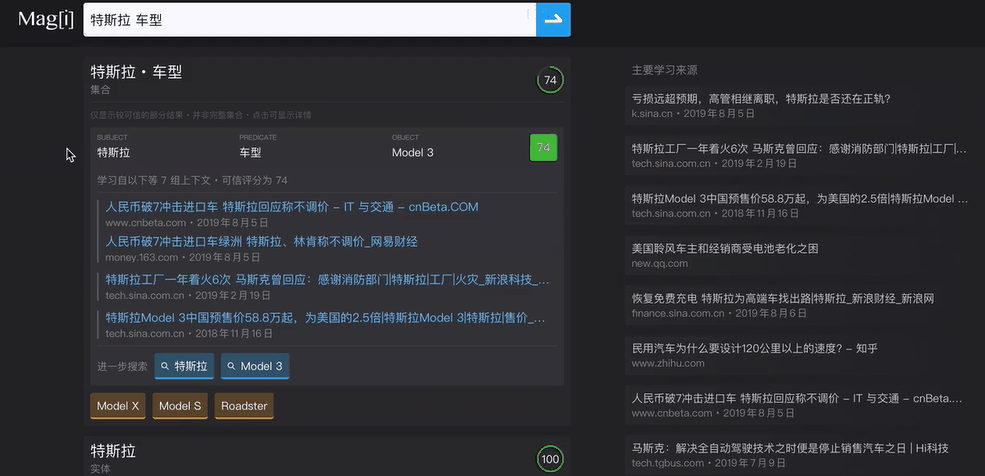
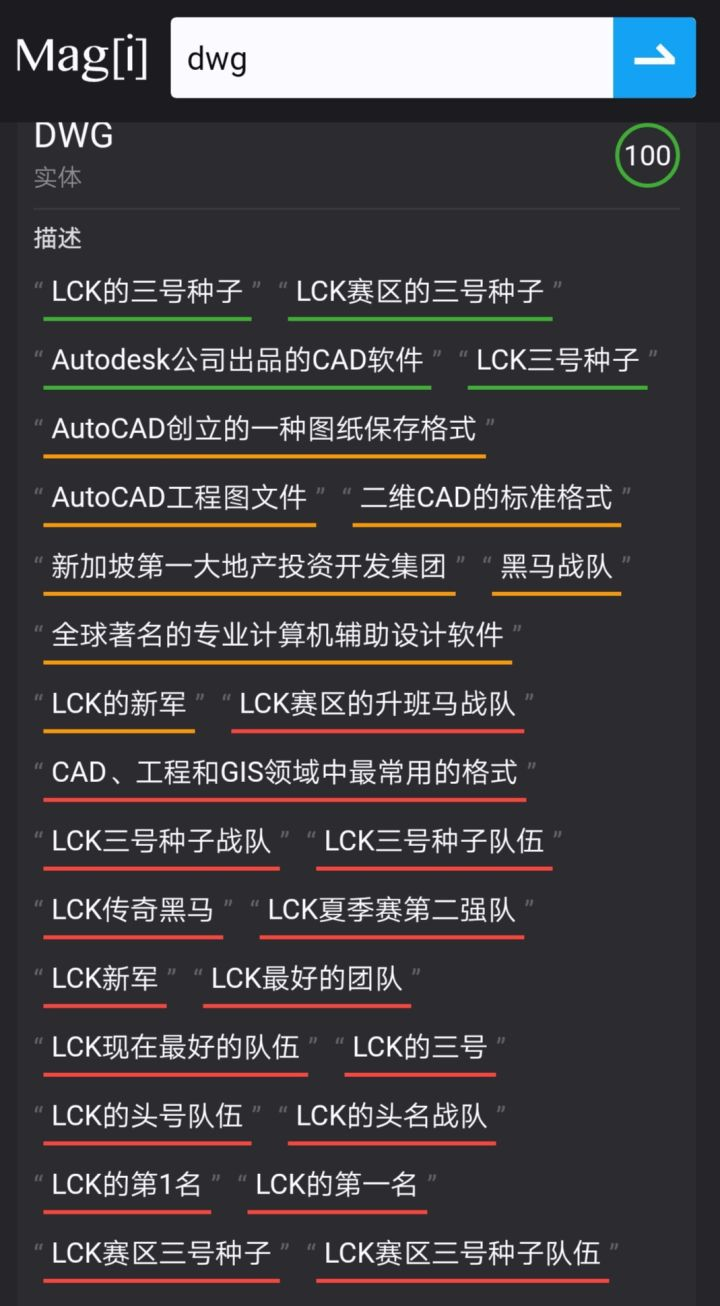
http://magi.com 的结果中,答案在搜索框的正下方,链接则在页面右边,跟主流搜索引擎的用户界面相反。如在 http://magi.com 里搜索“编程语言”,出来的首先是各种主流编程语言的合集:C#、Python、Java、JavaScript…同时给予“编程语言”这个词以“描述”和“属性”解释。红黄绿的颜色代表 Magi 给出的可信评分级别。(最绿的就是100分,完全相关,大大节约了用户的浏览时间)
在答案的右侧提供了一些链接,用鼠标划过它们即可看到,答案是从哪个具体的来源学习到的:
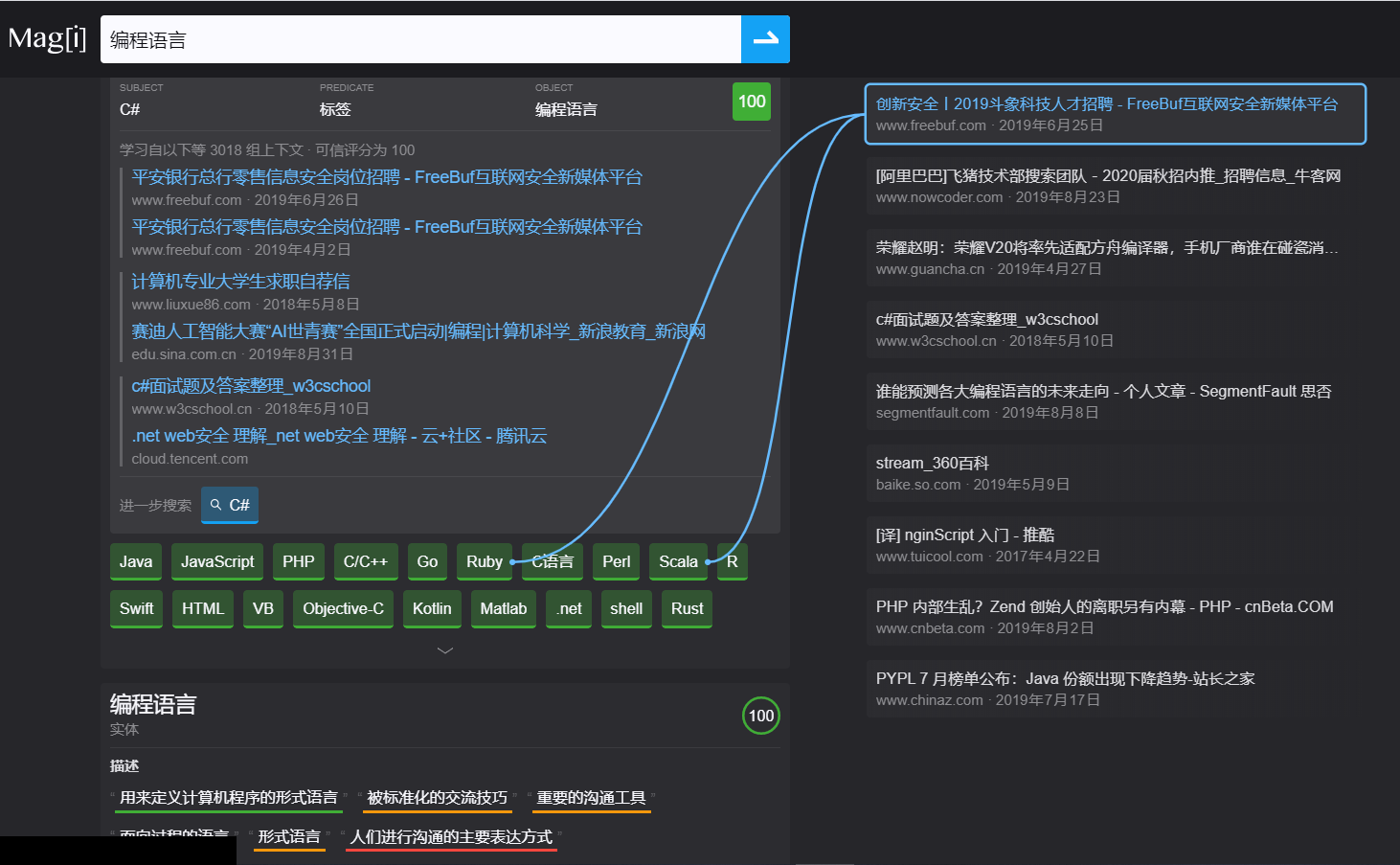
Magi搜索引擎的特点
- 网站页面简洁;
- 关键词详细、信息覆盖范围广泛、准确度高、自带信息关联等;
- 搜索的东西,将按不同的颜色表示其可信度从高到低进行评分指数;
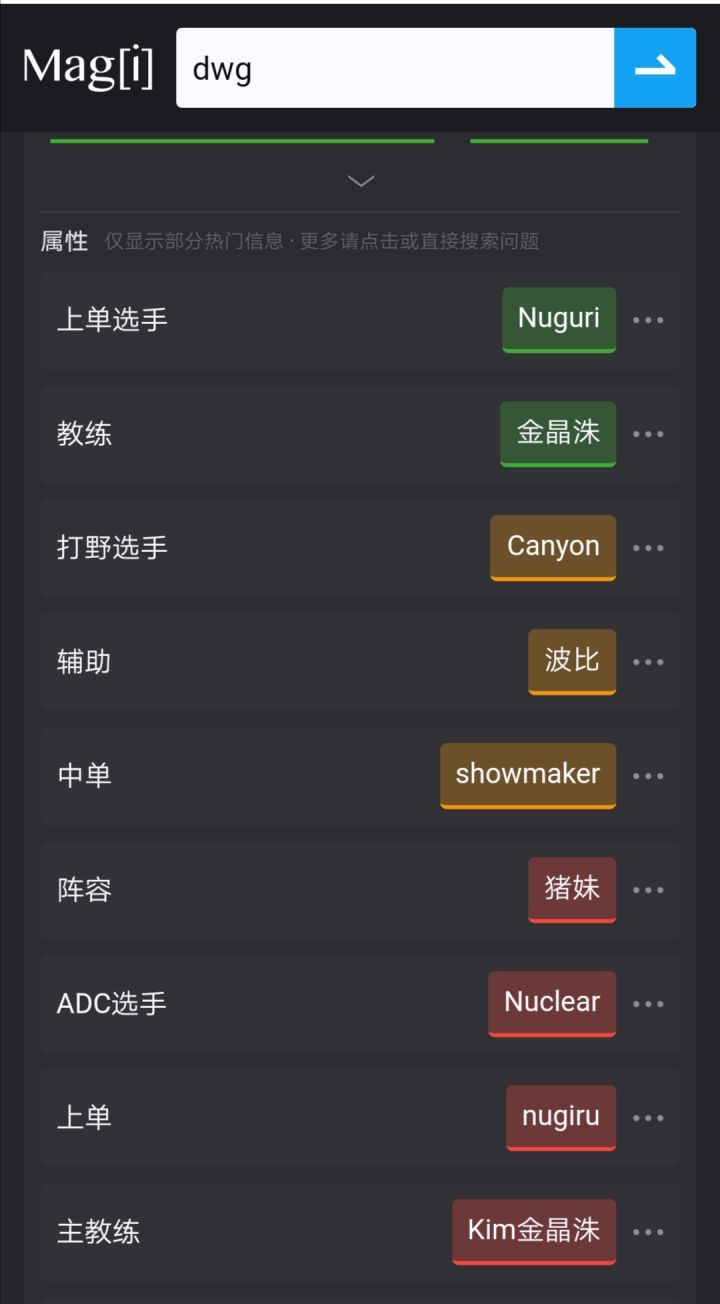
- 输出后的页面将会以结构化的呈现出来并在右侧显示,划过右侧的主要学习来源,可呈现到左侧的描述、属性、标签等;
- 基于 AI 技术,每一次的搜索都会不断学习,使得搜索结果更加精准;
感谢大家的关注,请允许创始人季逸超CEO补充说明三点常见误区:
- Magi 不依赖任何“知识库”,它是一种从纯文本自动构建尽量可信的知识图谱的技术。我们希望 Magi 能帮助知识工程的规模化,让各种知识图谱不用过于依赖百科维基等手动维护的数据库;
- 我们的本意不是做一个供日常使用的网页搜索引擎,magi.com 在互联网公开文本中应用 Magi 的提取技术学习知识,通过引入交叉验证和来源质量机制获得额外的统计量,从而进一步完善提取技术本身。甚至可以说这个表面上的搜索引擎只是 semi-supervision 循环的副产物... 更忙不过来做天气、日历、股票等锦上添花的小工具...
3.恳请各位爬虫大佬们别无节制抓我们网页了,网页的结果展示数量是限制了的,数据合作可以直接联系我们啊... 而且 Magi 是持续自动学习的,你今天抓到的明天也许就过时了;
4.另外我要实名反对下面某个回答,请起码搞明白别人在做什么再下评论,“中间结果”、“聚合搜索”、“无监督=聚类”、“为下游提供迁移学习=用了预训练模型”等言论从技术角度明显是不负责任的误导。
几年来 Magi 的产品形态改变了很多(请分开看待 Magi 系统和 magi.com 这个搜索引擎),技术上的进步主要体现在以下几点:
- 能够 exhaustively 提取重叠交错的知识,且不利用 HTML 特征;
- 不预设 predicate / verb,实现真正意义上的 “Open” Information Extraction;
- 配合自家 web 搜索引擎以评估来源质量,信息源和领域不设白名单;
- 大幅提升实时性,热点新闻发布后几分钟内,就可以搜到结构化知识了;
- 没有前置 NER 和 dependency parsing 等环节,减少母文本信息的损失;
- 技术栈完全 language-independent,可以实现低资源和跨语言 transfer。
- 买下了 magi.com 这么骚气的域名。
How it works (灵魂手绘凑合看吧...)
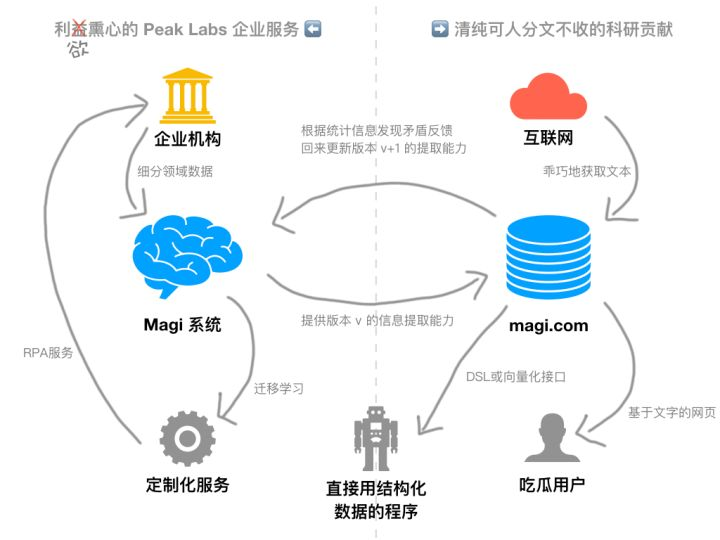
本文仅引用一小段,更多关于技术内容请看👇
如何评价 Peak Labs 出品的 2019 版 Magi 搜索引擎? - 季逸超的回答 - 知乎
https://www.zhihu.com/question/354059866/answer/881655371
真实使用效果
众所周知,http://magi.com 是一个可自我学习的,严肃,真实,可靠的搜索引擎
因此,我们也可以很简单地推导出一个结论:
mgai上面的内容,都是对的
据此,笔者在浏览magi,并进行合理推导的时候,学到了很多真实,有趣的信息
增长了知识,开拓了眼界。
如想了解什么是:电竞三丑,一般我们会百度“电竞三丑是什么梗”,但magi一查电竞三丑确有此人。
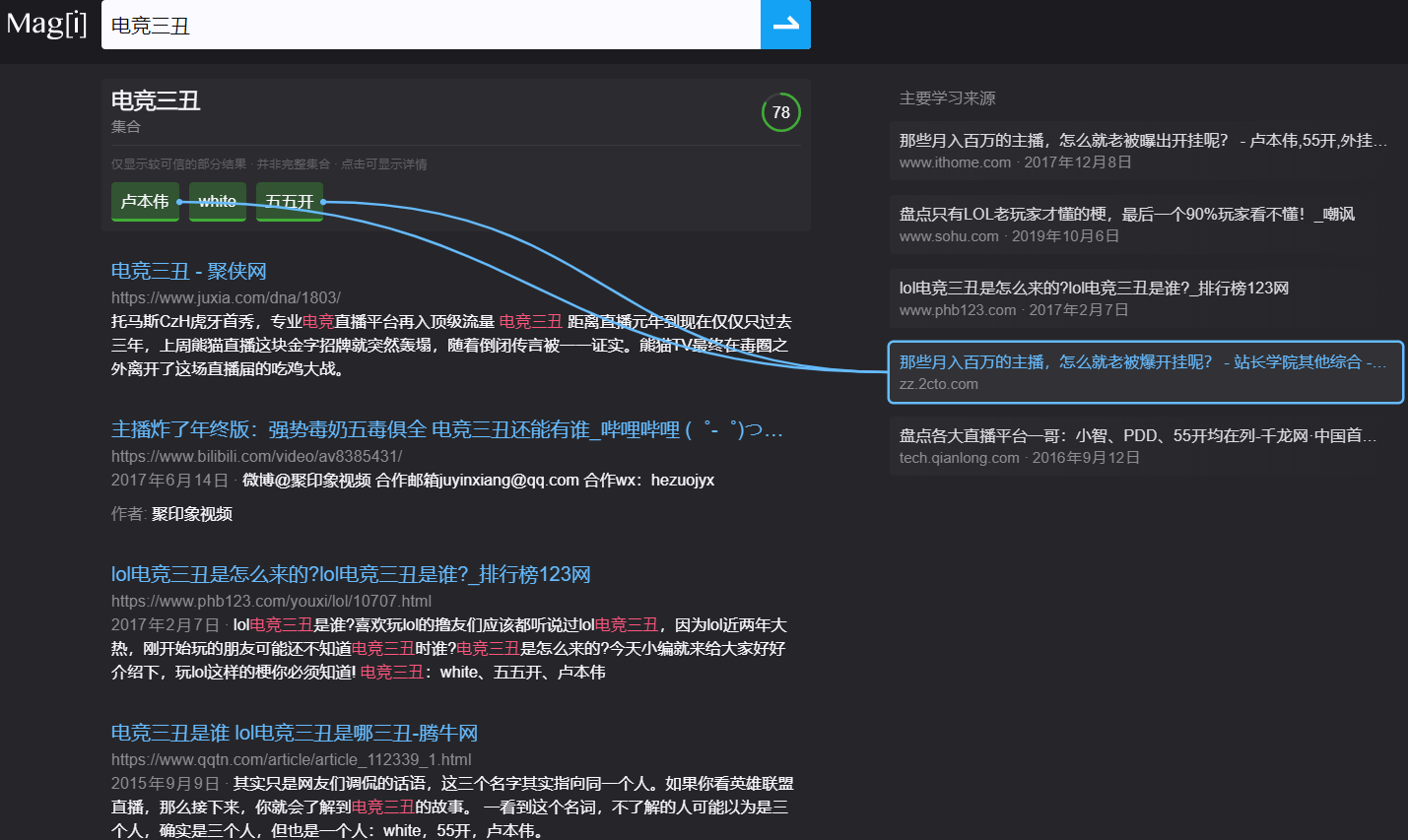
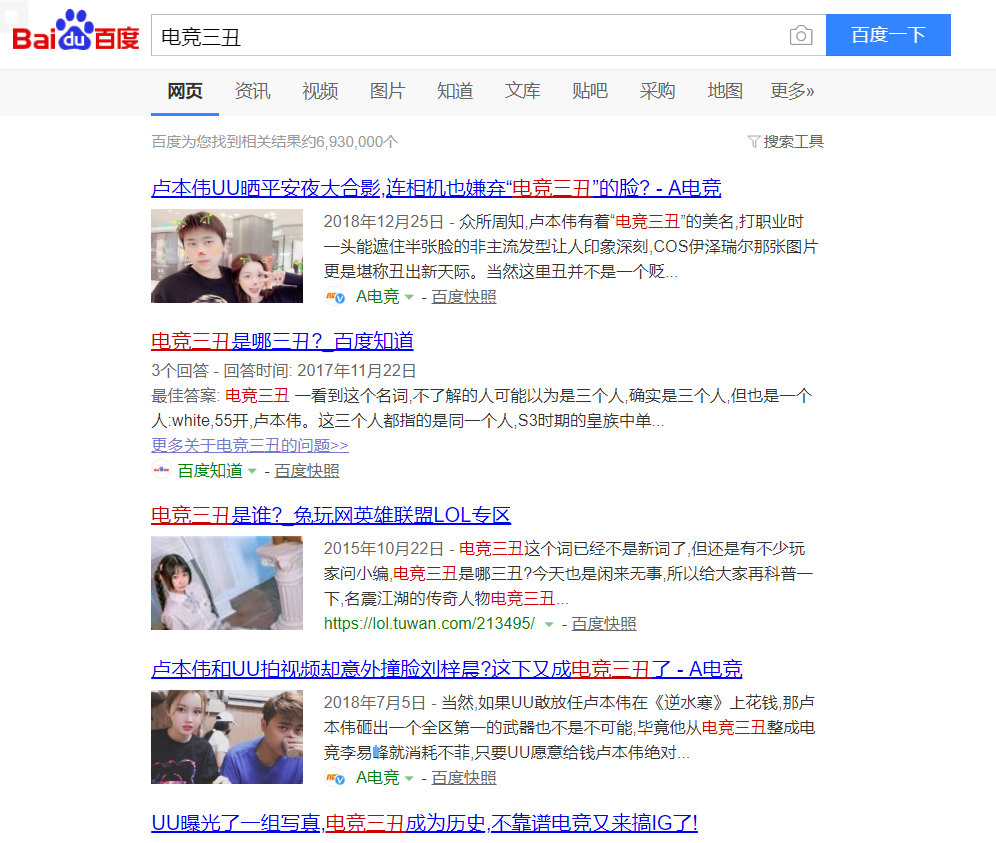
如果不是有人正好在“百度知道”这个百度亲儿子底下解释了一番。 怕是想知道“什么是电竞三丑”都有些费劲
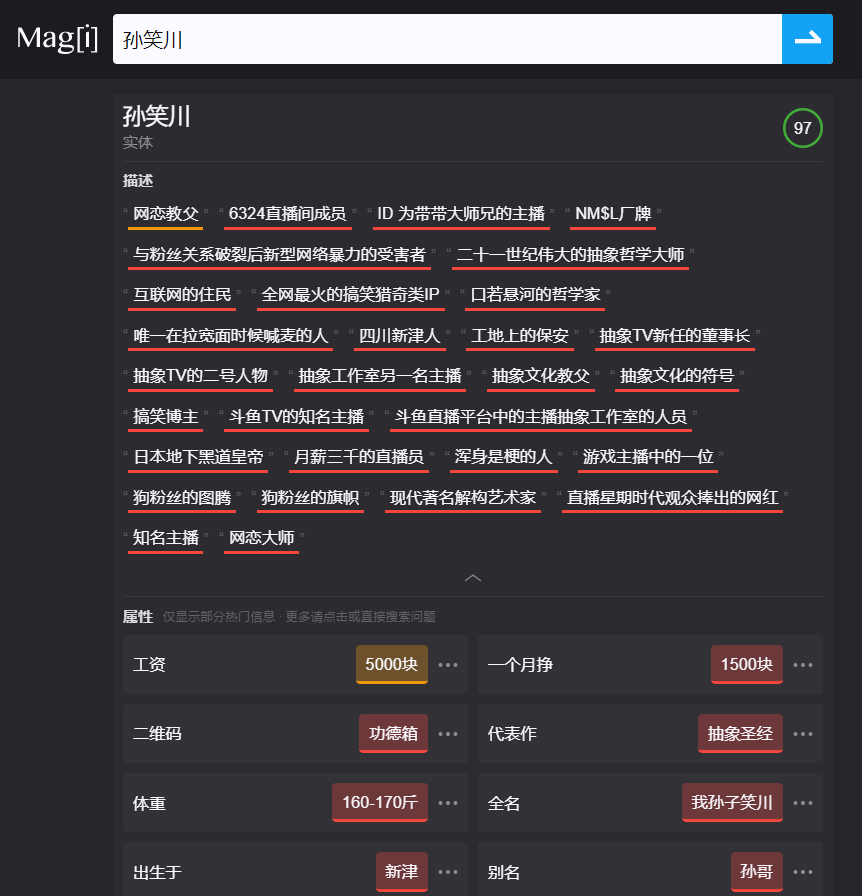
搜索“孙笑川”,想查询"孙笑川是什么梗",在百度就只能等人解释。但在Magi就可以根据一系列词条联想出来
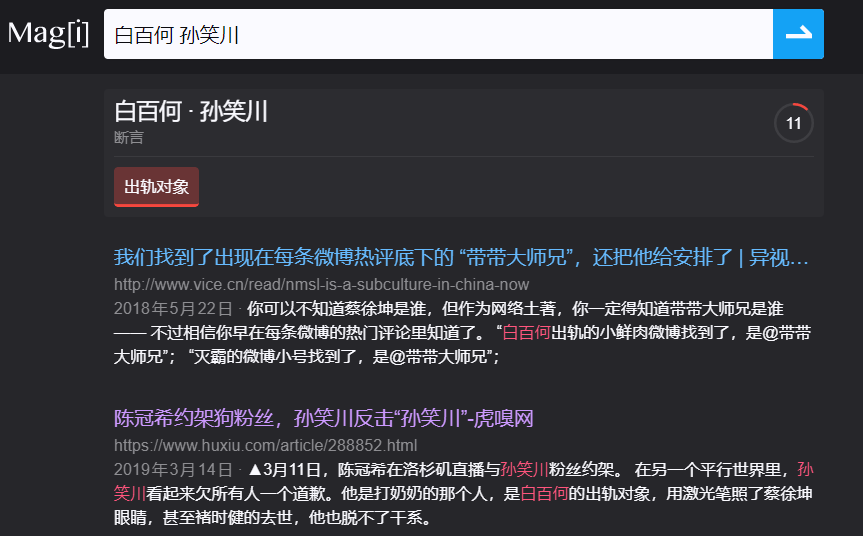
因为:孙笑川=白百何的出轨对象
且因为:人人都是孙笑川
所以:人人都是白百何的出轨对象
所以:人人都混娱乐圈
所以:世界上最发达的产业=娱乐产业
在目前主流搜索引擎都在养自家文章平台的时候,这种相对正经的搜索引擎,我觉得倒是不错的pick。
而且,有一说一,在查lol战队这种“具有大量二级分支”的数据时,magi的体验简直是完美:dwg战队

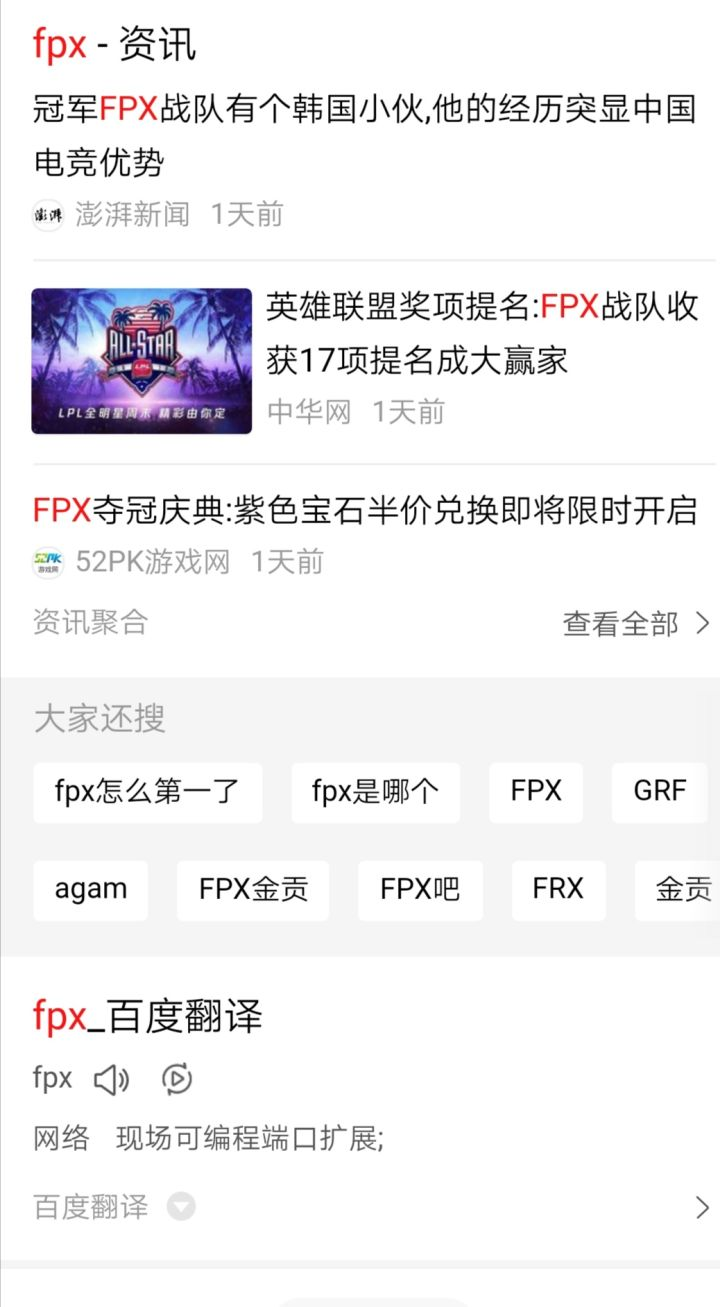
至于百度,他只会带着他的资讯聚合来吸引你的流量。看完毛都不懂什么的FPX
我真的不需要fpx的翻译,你可以带着你的百家号恰饭去了。
Magi 的使命
目前,互联网上只有极少数知识被人类手工整理成了机器可以解析的格式,如各种百科栏目和垂直领域数据库,然而这些信息仅仅是沧海之一粟,无论是覆盖范围、更新频率、可靠程度都无法满足日益增长的自动化和智能化需求。
其根本矛盾在于:读懂自然语言对人类来说不难,但人的精力有限,无法跟上有价值信息的产生速度,也不能保证稳定和客观;机器虽然不知疲倦且速度超群,但面对纷繁复杂的自由文本却难以利用,使得不可估量的价值被埋没于字里行间。
试想一下,假如有一个不断自动更新的数据库,包含着互联网各处的文本信息提取而成的便于程序和算法处理的数据结构,那么也许:
各种语音助手不会再对您说:“对不起,我不清楚。”;
商业智能可获得广泛的背景知识来做出更好的判断;
金融信息服务的数据收集与验证的效率将显著提升;
… …
作为公众版本的 magi.com 为人类用户提供了与互联网数据交互的新方式,而 Magi 系统背后的技术平台则承载着另一半重要的意义:让机器像人一样能理解并充分利用互联网中无穷无尽的知识。
Magi 的技术
在目前相关领域的尝试中,机器问答终究还是面向人类的服务,依照文本问题给出的文本回答并不能供下游任务直接利用。同时,问答模型本身无论从容量还是更新效率都无法满足规模化的需求,更致命的是模型中的知识存在于由浮点数组成的“黑箱”中,在我们看来将这些无法解读和溯源的信息直接呈现给用户并不是最负责任的做法。另外,基于文档检索的方案同样无法满足结构化的需求,在实时线上服务中效率限制会导致其难以评估全部文档来获得全局最优,而且其对用户输入的查询要求较高。
综上所述,我们认为知识提取的重要性远高于单纯地回答问题,主动发现潜在知识并持续提炼修正则显著强于被动地根据输入的问题去匹配结果。让机器去理解语言已经十分困难,而 Magi 更是选择面对其中最复杂的目标:开放领域的互联网文本,去直面规模化和准确度这一组知识工程中的核心矛盾点。

一个简单的句子就包含大量交错重叠的信息,而 Magi 要以整篇文章为单位处理语法松散又充满错误的互联网文本,其难度可想而知。
为了提升信息的利用率,Magi 必须尽可能彻底地从每一段质量参差不齐且主题各异的文本中提取出全部知识。这决定了一切现有的技术方案都不可用:这不再是一个清晰的序列标注问题,交错叠加的关系使得搜索空间爆炸式增长,不受限制的领域还意味着根本没有可用的训练数据。
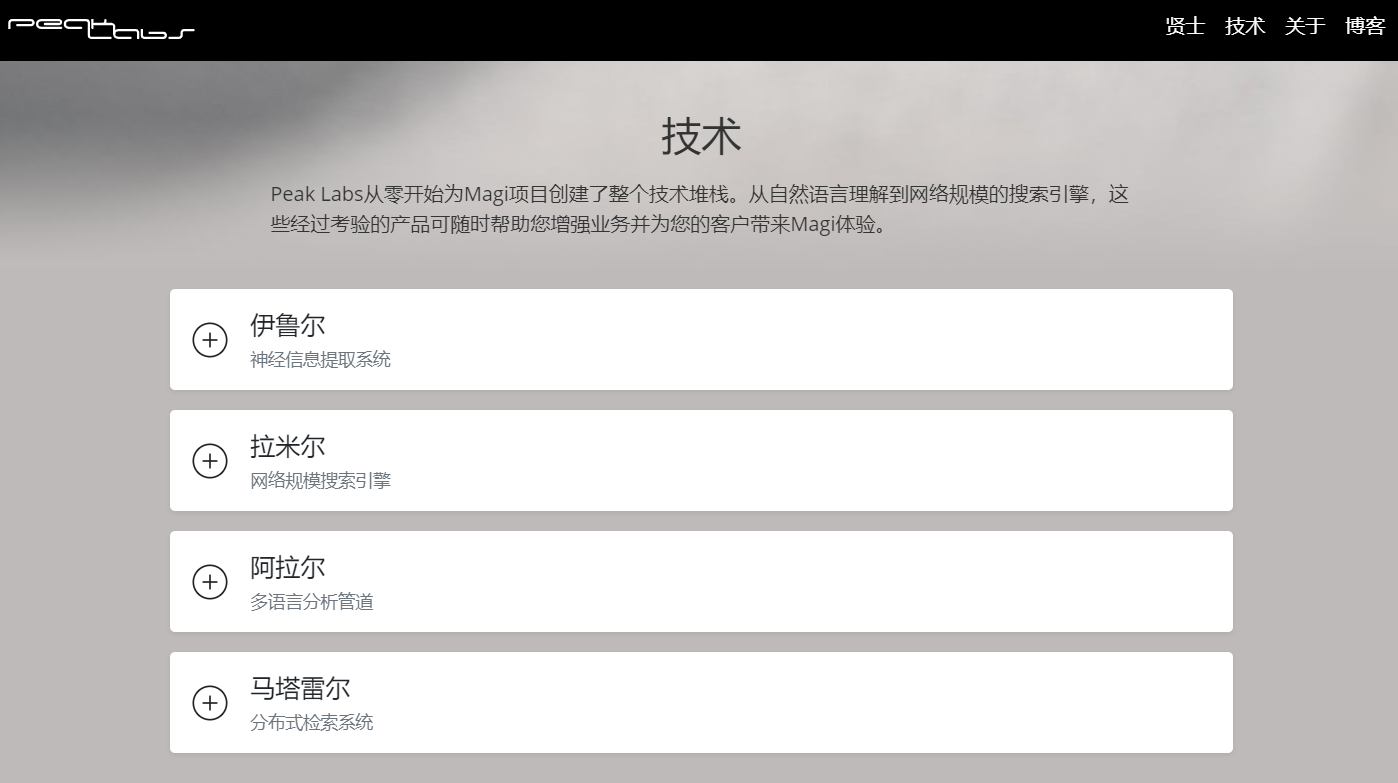
我们用了多年时间从零设计研发了整个技术堆栈:采用原创 succinct 索引结构的分布式搜索引擎(https://www.peak-labs.com/#Ramiel)、使用专门设计的 Attention 网络的神经提取系统(https://www.peak-labs.com/#Ireul)、不依赖 Headless 浏览器的流式抓取系统(https://www.peak-labs.com/#Matarael)、支持混合处理 170 余种语言的自然语言处理管线(https://www.peak-labs.com/#Arael)、… 。与此同时,我们默默耕耘并收获了独一无二的训练/预训练数据。
这个系统通过引入传统搜索中的 query-independent 质量因素,使得优质可靠的消息源会更被重视;其基于多级迁移学习的提取模型则完全摒弃了人工规则、角色标注、依存分析等限制泛化能力的环节,并且可在 zero-resource 的前提下直接应用到各种外语文本上并取得令人满意的效果;而随着数据的积累以及来源多样性的扩充,这个系统还能够持续学习与调整,自动消除学习到的噪音和错误结果;…
这些努力共同作用将 Magi 呈现于此。作为独特且具有前瞻性的项目,Magi 的部分数据与相关研究成果将定期公开于 Zenodo(https://zenodo.org/) 和 arXiv(https://arxiv.org/) 等平台。
Magi 的愿景
Magi 现在还远算不上成熟,但其特性决定了它无穷的可能性和成长空间。
从最棘手的互联网开放领域信息入手,Magi 证明了其作为 the One system to rule them all(https://en.wikipedia.org/wiki/One_Ring) 的可能性。面对各种领域的文本信息,Magi 的技术方案则从逐项击破跃进到了大一统,这代表着有限到无限的区别。
随着数据量和可信度的不断增长,Magi 将作为知识的 ImageNet(http://image-net.org/index) 来赋能各行各业。各个专业细分领域的信息提取任务,都可以通过利用少量数据对 Magi 模型进行 fine-tuning 来实现更优的方案。
也许在不远的未来,伴随着整个行业的进步,Magi 所构建的包容万事万物的结构化网络将成为通向可解释人工智能的基石。
最后
如果你还在用百度的话,可以体验一下 Magi 的搜索引擎,相信会给你带来不一样的体验。
已经体验过了的朋友,欢迎留言说说哈。
PS:在安利一款多吉搜索:https://www.dogedoge.com/

