

0帧起手将腾讯混元大模型集成到Spring AI的全过程解析
在前面,我们已经为大家铺垫了大量的知识点,并深入解析了Spring AI项目的相关内容。今天,我们将正式进入实战环节,从零开始,小雨将带领大家一步步完成将第三方大模型集成到Spring AI中的全过程。为了方便讲解,本次实战的示范将以腾讯的混元大模型为主,我们将逐步向你展示如何将该大模型嵌入到Spring AI中,并利用其强大的能力,帮助你个性化地完成企业级Agent的智能体开发。
如果你是对Spring AI还比较陌生的小伙伴,建议你先回顾一下我之前撰写的几篇入门文章,这些文章能够帮助你快速掌握Spring AI的基本概况和框架结构。相关链接已经放在文章的底部,欢迎阅读。
好了,废话不多说,我们直接开始今天的实战部分。
环境准备
秘钥信息
在此,我们需要申请混元大模型的秘钥信息,具体操作步骤如下所示:
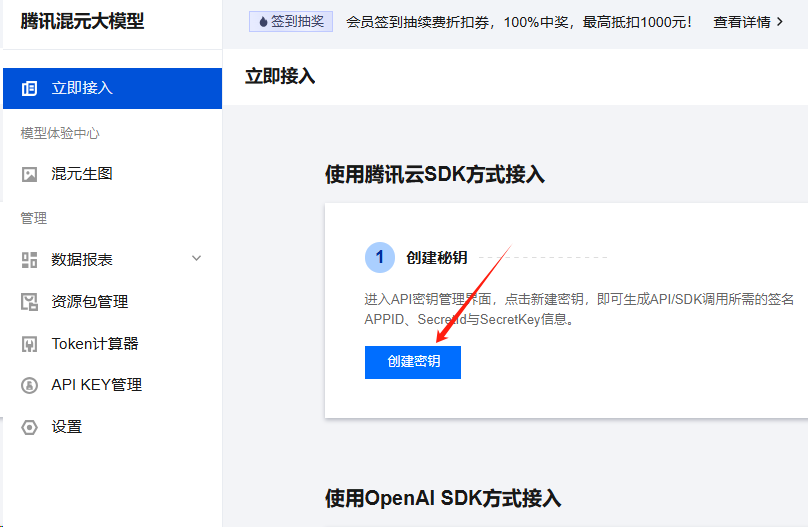
部分同学可能认为混元大模型已经兼容OpenAI接口,因而不再需要进行额外的开发实战。然而,如果你真的在Spring AI项目中尝试利用混元大模型的兼容方式来开发智能体,那么你一定遇到过不少bug,且这些bug往往是框架级别的,修复起来困难重重。因此,虽然兼容性是一项优势,但许多定制化需求可能难以通过兼容模式满足。
在我们系列的第一章节中,已经明确说明了需要在哪些包下进行修改,并详细列出了所需的依赖项。在这里,我们将直接进行开发。值得一提的是,Spring AI已经集成了多个大模型接口,尽管OpenAI的接口功能丰富,但对于新手来说,有些功能可能并不适合。因此,我们可以参考Moonshot接口或千帆接口来进行集成。记住,避免重复造轮子,利用已经编写好的代码逻辑,可以帮助你快速集成第三方大模型。
Models
首先请在models目录中创建了spring-ai-hunyuan子项目。如图所示:
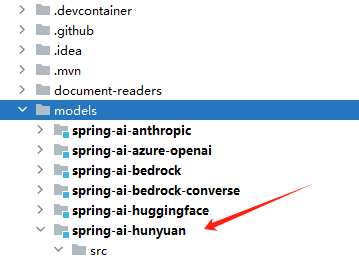
接下来需要在最外层的pom.xml文件中添加相关的目录子项目配置,以便将其正确集成到Spring AI的整体结构中。具体操作步骤如下所示:

依赖信息
我们为子项目配置了以下默认依赖,这些依赖可以为你提供基础的功能支持。当然,根据你的具体需求,你可以在此基础上进行自定义添加或调整,以确保满足项目的特殊要求和使用场景。
<!-- production dependencies -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
<version>${project.parent.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-retry</artifactId>
<version>${project.parent.version}</version>
</dependency>
<!-- Spring Framework -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</dependency>
<!-- test dependencies -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-test</artifactId>
<version>${project.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-observation-test</artifactId>
<scope>test</scope>
</dependency>
<!--解决高版本JDK问题-->
<!--javax.xml.bind.DatatypeConverter错误-->
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>${xml.bind.version}</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>${xml.bind.version}</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-core</artifactId>
<version>${xml.bind.version}</version>
</dependency>
<dependency>
<groupId>javax.activation</groupId>
<artifactId>activation</artifactId>
<version>1.1.1</version>
</dependency>
在这里,除了需要集成Spring AI框架所必需的固定依赖外,我们还特别添加了一些与混元接口加密相关的额外依赖。这些额外依赖用于支持混元系统中的加密功能,确保数据的安全性和接口的正常运行。
接口对接
第一步是,在models目录下开发与混元相关的API接口对接。为了帮助大家更清晰地理解接下来的开发过程,我提供一下项目的整体结构图,帮助大家更好地把握每个模块的关系。如图所示:
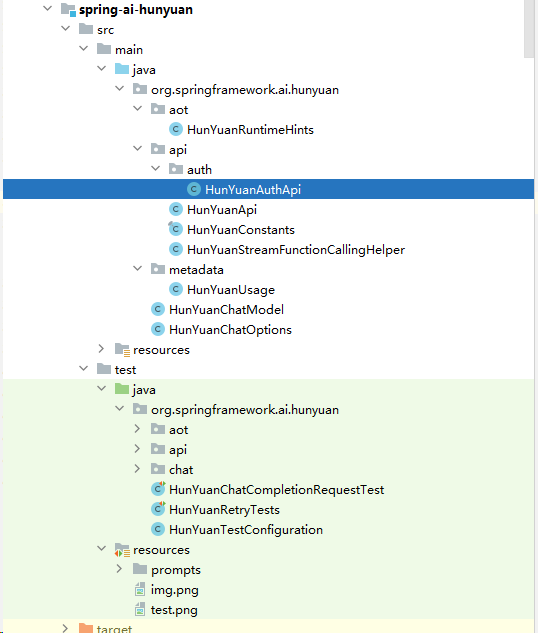
在这里,我们将简单介绍一下目录中的各个类,方便大家理解它们的功能和作用,并为后续可能的集成工作提供基础。具体来说,各个类的作用如下:
- HunYuanRuntimeHints:这是AOT(Ahead-of-Time)编译的固定写法,用于为系统提供静态的运行时提示,以确保在编译时能够正确处理相关的代码路径和资源。
- HunYuanAuthApi:这是一个混元接口的请求参数加密工具类,用于加密发送给混元系统的请求参数,确保数据传输过程中的安全性和完整性。
- HunYuanApi:该类主要定义了请求参数和响应参数的字段,并提供了对请求和响应的解析功能。它是与混元系统进行交互的核心类,负责数据的输入输出。
- HunYuanConstants:定义了项目中常用的一些常量信息,例如
baseUrl等常用配置信息,便于在项目中统一管理和调用。 - HunYuanStreamFunctionCallingHelper:这个类专注于流式响应中的功能合并,它主要用于处理大规模数据流时对功能的合并操作,确保响应过程的高效性和准确性。
- HunYuanUsage:该类负责记录和统计模型的token消耗情况,包括在与混元系统交互过程中所消耗的资源量,用于优化和监控。
- HunYuanChatModel:该部分类与Spring AI的自动注入机制相关联,主要负责封装和对接
HunYuanApi,以确保与Spring AI框架的兼容性。 - HunYuanChatOptions:这部分类同样与Spring AI自动注入相关,具体负责封装可操作的请求参数,例如
Model、Temperature等,确保系统能够灵活地调整不同的配置选项。
接下来,我们将深入探讨这些类的具体功能和实现方式,帮助大家更好地理解每个模块的实现细节及其在项目中的应用。
HunYuanRuntimeHints
这一部分的主要目标是实现AOT(Ahead-of-Time)快速打包启动,旨在将Spring项目打包成一个能够迅速启动并执行的可执行文件(.exe)。这种方法可以显著提高项目启动时的性能,并降低启动时间,尤其是在生产环境中需要快速响应的场景中非常有用。具体代码如下:
public class HunYuanRuntimeHints implements RuntimeHintsRegistrar {
@Override
public void registerHints(@NonNull RuntimeHints hints, @Nullable ClassLoader classLoader) {
var mcs = MemberCategory.values();
for (var tr : findJsonAnnotatedClassesInPackage(HunYuanApi.class)) {
hints.reflection().registerType(tr, mcs);
}
}
}
实现RuntimeHintsRegistrar接口重写registerHints方法即可,将HunYuanApi注册进去。
HunYuanAuthApi
这一部分的主要代码以及在实现过程中需要注意的坑点和解决方案,已经详细列出在另一篇文章中,因此在此我们不再重复赘述。文章链接如下:https://www.cnblogs.com/guoxiaoyu/p/18675216
不过,值得特别强调的是,在这个过程中,您无需额外添加ObjectMapper依赖。因为在Spring AI项目中,Record类转化为JSON的过程有一套固定的写法,Spring框架已经为这一操作提供了内建的支持和优化。下面是具体的代码实现示例:
String payloadString = ModelOptionsUtils.toJsonString(payload);
如果你要是想让json转对象,也有响应的方法,如下所示:
ChatCompletionResponse chatCompletionResponse = ModelOptionsUtils.jsonToObject(retrieve.getBody(),
ChatCompletionResponse.class);
HunYuanApi
这个类的主要功能是将封装好的请求参数传递给混元大模型接口的URL。除了该功能外,类中的其他部分主要涉及对字段的定义和Record类的使用,Record类在这里起到了封装数据的作用,简化了字段管理与传输。以下是该类的核心代码结构:
public class HunYuanApi {
//省略类属性
/**
* Create a new client api.
* @param baseUrl api base URL.
* @param secretKey Hunyuan api Key.
* @param restClientBuilder RestClient builder.
* @param responseErrorHandler Response error handler.
*/
public HunYuanApi(String baseUrl, String secretId, String secretKey, RestClient.Builder restClientBuilder,
ResponseErrorHandler responseErrorHandler) {
Consumer<HttpHeaders> jsonContentHeaders = headers -> {
headers.setContentType(MediaType.APPLICATION_JSON);
};
hunyuanAuthApi = new HunYuanAuthApi(secretId, secretKey);
this.restClient = restClientBuilder.baseUrl(baseUrl)
.defaultHeaders(jsonContentHeaders)
.defaultStatusHandler(responseErrorHandler)
.build();
this.webClient = WebClient.builder().baseUrl(baseUrl).defaultHeaders(jsonContentHeaders).build();
}
/**
* Creates a model response for the given chat conversation.
* @param chatRequest The chat completion request.
* @return Entity response with {@link ChatCompletion} as a body and HTTP status code
* and headers.
*/
public ResponseEntity<ChatCompletionResponse> chatCompletionEntity(ChatCompletionRequest chatRequest) {
Assert.notNull(chatRequest, "The request body can not be null.");
String service = HunYuanConstants.DEFAULT_SERVICE;
String host = HunYuanConstants.DEFAULT_CHAT_HOST;
// String region = "ap-guangzhou";
String action = HunYuanConstants.DEFAULT_CHAT_ACTION;
MultiValueMap<String, String> jsonContentHeaders = hunyuanAuthApi.getHttpHeadersConsumer(host, action, service,
chatRequest);
ResponseEntity<String> retrieve = this.restClient.post().uri("/").headers(headers -> {
headers.addAll(jsonContentHeaders);
}).body(chatRequest).retrieve().toEntity(String.class);
// Compatible Return Position text/plain
logger.info("Response body: {}", retrieve.getBody());
ChatCompletionResponse chatCompletionResponse = ModelOptionsUtils.jsonToObject(retrieve.getBody(),
ChatCompletionResponse.class);
return ResponseEntity.ok(chatCompletionResponse);
}
/**
* Creates a streaming chat response for the given chat conversation.
* @param chatRequest The chat completion request. Must have the stream property set
* to true.
* @return Returns a {@link Flux} stream from chat completion chunks.
*/
public Flux<ChatCompletionChunk> chatCompletionStream(ChatCompletionRequest chatRequest) {
Assert.notNull(chatRequest, "The request body can not be null.");
Assert.isTrue(chatRequest.stream(), "Request must set the steam property to true.");
AtomicBoolean isInsideTool = new AtomicBoolean(false);
String service = HunYuanConstants.DEFAULT_SERVICE;
String host = HunYuanConstants.DEFAULT_CHAT_HOST;
// String region = "ap-guangzhou";
String action = HunYuanConstants.DEFAULT_CHAT_ACTION;
MultiValueMap<String, String> jsonContentHeaders = hunyuanAuthApi.getHttpHeadersConsumer(host, action, service,
chatRequest);
return this.webClient.post().uri("/").headers(headers -> {
headers.addAll(jsonContentHeaders);
})
.body(Mono.just(chatRequest), ChatCompletionRequest.class)
.retrieve()
.bodyToFlux(String.class)
// cancels the flux stream after the "[DONE]" is received.
.takeUntil(SSE_DONE_PREDICATE)
// filters out the "[DONE]" message.
.filter(SSE_DONE_PREDICATE.negate())
.map(content -> {
// logger.info(content);
return ModelOptionsUtils.jsonToObject(content, ChatCompletionChunk.class);
})
// Detect is the chunk is part of a streaming function call.
.map(chunk -> {
if (this.chunkMerger.isStreamingToolFunctionCall(chunk)) {
isInsideTool.set(true);
}
return chunk;
})
// Group all chunks belonging to the same function call.
// Flux<ChatCompletionChunk> -> Flux<Flux<ChatCompletionChunk>>
.windowUntil(chunk -> {
if (isInsideTool.get() && this.chunkMerger.isStreamingToolFunctionCallFinish(chunk)) {
isInsideTool.set(false);
return true;
}
return !isInsideTool.get();
})
// Merging the window chunks into a single chunk.
// Reduce the inner Flux<ChatCompletionChunk> window into a single
// Mono<ChatCompletionChunk>,
// Flux<Flux<ChatCompletionChunk>> -> Flux<Mono<ChatCompletionChunk>>
.concatMapIterable(window -> {
Mono<ChatCompletionChunk> monoChunk = window.reduce(
new ChatCompletionChunk(null, null, null, null, null, null, null, null, null, null, null),
(previous, current) -> this.chunkMerger.merge(previous, current));
return List.of(monoChunk);
})
// Flux<Mono<ChatCompletionChunk>> -> Flux<ChatCompletionChunk>
.flatMap(mono -> mono);
}
//省略所有Record字段类
}
从代码结构上来看,API类的主要作用是通过构造器将秘钥等关键信息动态注入到类的内部,确保每次调用时能够正确地携带所需的认证信息。最终,该类暴露出了两个核心方法:一个是流式请求,另一个是阻塞式请求。这两个请求方式在处理逻辑上有些许差异,分别适应不同的场景。
在阻塞式请求的实现中,混元接口在返回失败时,content-type会被设置为text/plain,而不是常见的application/json,这导致框架在解析返回结果时出现JSON解析失败的情况。为了解决这个问题,我们采取了先将返回结果转化为字符串,再使用ModelOptionsUtils工具类进行对象转换的方式,确保能够正确处理这种非标准的返回类型。
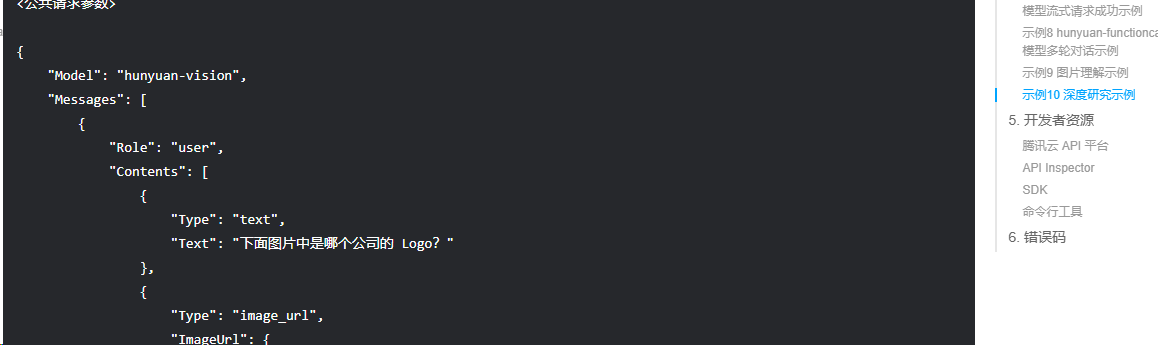
至于流式请求,由于大多数模型的处理方式都是标准化的,因此我们无需做太多的修改。流式请求的处理基本是固定的,适配大多数场景,只需要注意一些特定细节即可。在混元文档中也有相关的特殊说明,提醒开发者在使用时需要关注的要点。以下是混元文档中的相关图示:

在这个功能的实现中,返回的数据结构与其他模型的返回格式有显著的区别,所以主要的改动是对Type、Name和Arguments字段进行合并,以Id作为唯一标识来确保数据的一致性和完整性。改动的地方也就是HunYuanStreamFunctionCallingHelper类。
HunYuanStreamFunctionCallingHelper
在该类中,基本需要改动就是各个模型的参数不一致,所以按照参数类型以及名称修改一致即可。我们主要看下这个function合并。代码如下:
private ChatCompletionFunction merge(ChatCompletionFunction previous, ChatCompletionFunction current) {
if (previous == null) {
return current;
}
String name = (StringUtils.hasText(current.name()) ? current.name() : previous.name());
StringBuilder arguments = new StringBuilder();
if (StringUtils.hasText(previous.arguments())) {
arguments.append(previous.arguments());
}
if (StringUtils.hasText(current.arguments())) {
arguments.append(current.arguments());
}
return new ChatCompletionFunction(name, arguments.toString());
}
在其他模型的判断过程中,通常是通过!= null来判断字段值的有效性。然而,混元大模型的返回值是空字符串"",而非null。因此,我们在处理混元大模型返回数据时,需要特别注意这一点。如果不做特别处理,可能会导致name字段的值为空字符串,进而引发后续的报错或逻辑错误。
此外,值得注意的是,如果你的大模型流式请求中需要合并其他参数字段,建议在HunYuanStreamFunctionCallingHelper类中处理这些合并操作,而不是等到最外层获取到最终结果后再进行合并。这种做法在处理逻辑时显得更加简洁、清晰,并且能够避免重复的计算或不必要的复杂操作,避免代码看起来过于笨重。
HunYuanChatModel
这里我们也只是看下关键核心代码,有些注意的点特殊说明一下。
public class HunYuanChatModel extends AbstractToolCallSupport implements ChatModel, StreamingChatModel {
//省略部分代码
@Override
public ChatResponse call(Prompt prompt) {
ChatCompletionRequest request = createRequest(prompt, false);
//省略部分代码
ChatResponse response = ChatModelObservationDocumentation.CHAT_MODEL_OPERATION
.observation(this.observationConvention, DEFAULT_OBSERVATION_CONVENTION, () -> observationContext,
this.observationRegistry)
.observe(() -> {
ResponseEntity<ChatCompletionResponse> completionEntity = this.retryTemplate
.execute(ctx -> this.hunYuanApi.chatCompletionEntity(request));
var chatCompletion = completionEntity.getBody().response();
//省略部分代码
return response;
}
@Override
public Flux<ChatResponse> stream(Prompt prompt) {
return Flux.deferContextual(contextView -> {
ChatCompletionRequest request = createRequest(prompt, true);
Flux<ChatCompletionChunk> completionChunks = this.retryTemplate
.execute(ctx -> this.hunYuanApi.chatCompletionStream(request));
//省略部分代码
Flux<ChatResponse> chatResponse = completionChunks.map(this::chunkToChatCompletion)
.switchMap(chatCompletion -> Mono.just(chatCompletion).map(chatCompletion2 -> {
try {
//省略部分代码
return Flux.just(response);
})
.doOnError(observation::error)
.doFinally(signalType -> observation.stop())
.contextWrite(ctx -> ctx.put(ObservationThreadLocalAccessor.KEY, observation));
return new MessageAggregator().aggregate(flux, observationContext::setResponse);
});
}
//省略部分代码
在这段代码中,我已经省略了与当前逻辑无关的部分。你可以看到,实际上在hunYuanApi调用之后,我们对返回结果进行了外层包装,将其返回给Spring AI框架进行后续处理。这里需要特别注意的是,混元模型返回的响应数据是以Response为前缀进行包装的。因此,在处理混元大模型的返回结果时,我们必须兼容这种包装方式。
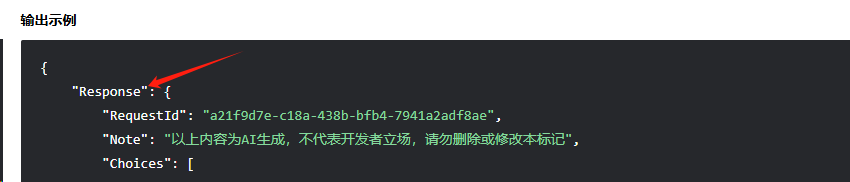
var chatCompletion = completionEntity.getBody().response();
除了这里还有两个点需要注意下,第一个就是createRequest方法。
List<ChatCompletionMessage> systemMessages = new ArrayList<>();
List<ChatCompletionMessage> chatCompletionMessages = prompt.getInstructions().stream().filter(message -> {
if (message.getMessageType() == MessageType.SYSTEM) {
Object content = message.getText();
systemMessages.add(new ChatCompletionMessage(content, Role.system));
return false;
}
return true;
}).map(message -> {
if (message.getMessageType() == MessageType.USER) {
Object content = message.getText();
if (message instanceof UserMessage userMessage) {
if (!CollectionUtils.isEmpty(userMessage.getMedia())) {
List<ChatContent> contentList = new ArrayList<>(List.of(new ChatContent(message.getText())));
contentList.addAll(userMessage.getMedia()
.stream()
.map(media -> new ChatContent(
new ImageUrl(this.fromMediaData(media.getMimeType(), media.getData()))))
.toList());
return List.of(new ChatCompletionMessage(Role.user, contentList));
}
}
return List.of(new ChatCompletionMessage(content, Role.user));
}
//省略部分代码
systemMessages.stream().forEach(systemMessage -> {
chatCompletionMessages.add(0, systemMessage);
});
//省略部分代码
可以看出,实际上这段操作分为两个部分。第一部分是将systemMessage添加到消息列表的首位,因为混元接口的设计要求必须遵循这一顺序,即系统消息需要位于消息列表的最前面才能确保接口能够正确处理。
第二部分则是根据userMessage的信息类型,自己封装图片理解相关请求参数,这属于混元个性化设置,如下所示:
第一个方法是chunkToChatCompletion。由于混元接口的响应内容实际上是通过参数delta返回的,我们需要对其进行重新封装,将其转换为ChatCompletionMessage格式,以便能够正确地传递给Spring AI进行后续处理。下面是相关代码的实现:
private ChatCompletion chunkToChatCompletion(ChatCompletionChunk chunk) {
List<ChatCompletion.Choice> choices = chunk.choices().stream().map(chunkChoice -> {
ChatCompletionMessage chatCompletionMessage = null;
ChatCompletionDelta delta = chunkChoice.delta();
if (delta == null) {
chatCompletionMessage = new ChatCompletionMessage("", Role.assistant);
}
else {
chatCompletionMessage = new ChatCompletionMessage(delta.content(), delta.role(), delta.toolCalls());
}
return new ChatCompletion.Choice(chunkChoice.index(), chatCompletionMessage, chunkChoice.finishReason(),
delta);
}).toList();
return new ChatCompletion(chunk.id(), chunk.errorMsg(), chunk.created(), chunk.note(), choices, chunk.usage(),
chunk.moderationLevel(), chunk.searchInfo(), chunk.replaces(), chunk.recommendedQuestions(),
chunk.requestId());
}
单元测试
在进行单元测试时,需要特别注意的是,如果你在测试方面的经验还不够丰富,建议可以参考其他成熟模型的测试流程,例如Moonshot等。这些模型的测试方法和流程通常经过了多次验证,具有较高的可靠性,尤其是对于聊天功能模块来说,各种模型的实现方式差异不会特别大。我们接下来可以具体了解一下如何进行函数回调的测试以及如何进行图片理解部分的验证。
图片理解
看下图片理解单元测试相关代码。
@EnabledIfEnvironmentVariable(named = "HUNYUAN_SECRET_ID", matches = ".+")
@EnabledIfEnvironmentVariable(named = "HUNYUAN_SECRET_KEY", matches = ".+")
public class HunYuanApiIT {
private static final Logger logger = LoggerFactory.getLogger(HunYuanApiIT.class);
HunYuanApi hunyuanApi = new HunYuanApi(System.getenv("HUNYUAN_SECRET_ID"), System.getenv("HUNYUAN_SECRET_KEY"));
@Test
void chatCompletionEntityWithPicture() {
ChatCompletionMessage userMessage = new ChatCompletionMessage(Role.user, List.of(
new ChatCompletionMessage.ChatContent("text", "Which company's logo is in the picture below?"),
new ChatCompletionMessage.ChatContent("image_url", new ChatCompletionMessage.ImageUrl(
"https://cloudcache.tencent-cloud.com/qcloud/ui/portal-set/build/About/images/bg-product-series_87d.png"))));
ResponseEntity<HunYuanApi.ChatCompletionResponse> response = this.hunyuanApi
.chatCompletionEntity(new ChatCompletionRequest(List.of(userMessage),
HunYuanApi.ChatModel.HUNYUAN_TURBO_VISION.getValue(), 0.8, false));
logger.info(response.getBody().response().toString());
assertThat(response).isNotNull();
assertThat(response.getBody()).isNotNull();
assertThat(response.getBody().response()).isNotNull();
}
@Test
void chatCompletionStreamWithNativePicture() {
String imageInfo = "data:image/jpeg;base64,";
// 读取图片文件
var imageData = new ClassPathResource("/img.png");
try (InputStream inputStream = imageData.getInputStream()) {
byte[] imageBytes = inputStream.readAllBytes();
// 使用Base64编码图片字节数据
String encodedImage = Base64.getEncoder().encodeToString(imageBytes);
// 输出编码后的字符串
imageInfo += encodedImage;
}
catch (IOException e) {
e.printStackTrace();
}
ChatCompletionMessage userMessage = new ChatCompletionMessage(Role.user, List.of(
new ChatCompletionMessage.ChatContent("text", "Which company's logo is in the picture below?"),
new ChatCompletionMessage.ChatContent("image_url", new ChatCompletionMessage.ImageUrl(imageInfo))));
Flux<ChatCompletionChunk> response = this.hunyuanApi.chatCompletionStream(new ChatCompletionRequest(
List.of(userMessage), HunYuanApi.ChatModel.HUNYUAN_TURBO_VISION.getValue(), 0.8, true));
assertThat(response).isNotNull();
assertThat(response.collectList().block()).isNotNull();
logger.info(ModelOptionsUtils.toJsonString(response.collectList().block()));
}
}
在此,我们直接采用了混元大模型官方提供的案例示例,因此只需将相关的模型参数进行修改后,便可直接调用相应的API。需要特别强调的是,关于密钥信息的处理,我们建议使用环境变量进行读取,避免直接在配置文件等地方硬编码。这是因为如果将密钥信息直接放入配置文件中,可能会导致提交拉取请求(PR)失败,从而影响版本控制的顺利进行。
经过运行测试,一切功能正常,如下图所示:

函数回调
因为流式函数调用更改了一些合并逻辑,所以也需要看下函数回调是否正常。
@Test
void streamFunctionCallTest() {
UserMessage userMessage = new UserMessage(
"What's the weather like in San Francisco, Tokyo, and Paris? Return the temperature in Celsius.");
List<Message> messages = new ArrayList<>(List.of(userMessage));
var promptOptions = HunYuanChatOptions.builder()
.functionCallbacks(List.of(FunctionCallback.builder()
.function("getCurrentWeather", new MockWeatherService())
.description("Get the weather in location")
.inputType(MockWeatherService.Request.class)
.build()))
.build();
Flux<ChatResponse> response = this.chatModel.stream(new Prompt(messages, promptOptions));
String content = response.collectList()
.block()
.stream()
.map(ChatResponse::getResults)
.flatMap(List::stream)
.map(Generation::getOutput)
.map(AssistantMessage::getText)
.filter(Objects::nonNull)
.collect(Collectors.joining());
logger.info("Response: {}", content);
assertThat(content).contains("30", "10", "15");
}
运行后一切正常,看下结果如图所示:

自此,我们的混元大模型的底层基座就算是完成了,接下来就是将混元自动注入到Spring AI 的管理中。随后,我们将继续对相关流程进行深入分析,以确保实现最佳效果。
Autoconfigure
找到spring-ai-spring-boot-autoconfigure目录,这里面配置了所有可以自动配置的大模型,我们在里面添加一下hunyuan目录。如图所示:
依赖信息
同样的,创建完目录后,直接在当前目录下的pom中添加HunYuan API项目,如图所示:
<!-- HunYuan AI -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-hunyuan</artifactId>
<version>${project.parent.version}</version>
<optional>true</optional>
</dependency>
配置类
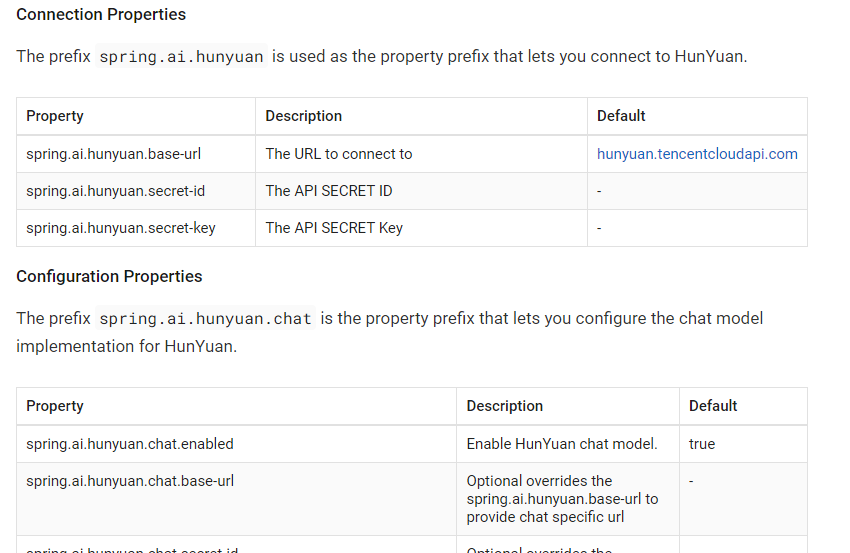
配置类的主要功能是为了实现对Spring AI集成第三方模型时所需的API密钥相关信息的准确解析与绑定,具体内容如下所示:
@ConfigurationProperties(HunYuanChatProperties.CONFIG_PREFIX)
public class HunYuanChatProperties extends HunYuanParentProperties {
public static final String CONFIG_PREFIX = "spring.ai.hunyuan.chat";
public static final String DEFAULT_CHAT_MODEL = HunYuanApi.ChatModel.HUNYUAN_PRO.getValue();
private static final Double DEFAULT_TEMPERATURE = 0.7;
//省略部分代码
@NestedConfigurationProperty
private HunYuanChatOptions options = HunYuanChatOptions.builder()
.model(DEFAULT_CHAT_MODEL)
.temperature(DEFAULT_TEMPERATURE)
.build();
//省略部分代码
}
这里我给混元匹配的前缀为spring.ai.hunyuan.chat,他其实主要给模型设置一些option信息来使用的。如下所示:
"spring.ai.hunyuan.chat.options.model=MODEL_XYZ",
"spring.ai.hunyuan.chat.options.temperature=0.55"
虽然它继承了 HunYuanParentProperties,因此能够灵活地配置秘钥及其他相关信息,但如果您的需求仅仅是进行简单的秘钥配置,实际上还有一种更加简便的配置类可以选择。具体的示例如下所示:
@ConfigurationProperties(HunYuanCommonProperties.CONFIG_PREFIX)
public class HunYuanCommonProperties extends HunYuanParentProperties {
public static final String CONFIG_PREFIX = "spring.ai.hunyuan";
public static final String DEFAULT_BASE_URL = "https://hunyuan.tencentcloudapi.com";
public HunYuanCommonProperties() {
super.setBaseUrl(DEFAULT_BASE_URL);
}
这样你就可以单独写秘钥等信息了。如下所示:
spring.ai.hunyuan.secret-id=123
spring.ai.hunyuan.secret-key=456
自动配置
为了确保我们的项目能够有效地集成到Spring框架中,我们必须实现一个AutoConfiguration类。这是由于Spring的自动配置机制所要求的,它负责在应用启动时自动配置所需的Beans和组件。这一要求与Spring AI项目本身的功能特点并没有直接关联。接下来,让我们详细观察一下自动配置类的具体代码实现:
@AutoConfiguration(after = { RestClientAutoConfiguration.class, SpringAiRetryAutoConfiguration.class })
@EnableConfigurationProperties({ HunYuanCommonProperties.class, HunYuanChatProperties.class })
@ConditionalOnClass(HunYuanApi.class)
public class HunYuanAutoConfiguration {
@Bean
@ConditionalOnMissingBean
@ConditionalOnProperty(prefix = HunYuanChatProperties.CONFIG_PREFIX, name = "enabled", havingValue = "true",
matchIfMissing = true)
public HunYuanChatModel hunyuanChatModel(HunYuanCommonProperties commonProperties,
HunYuanChatProperties chatProperties, ObjectProvider<RestClient.Builder> restClientBuilderProvider,
List<FunctionCallback> toolFunctionCallbacks, FunctionCallbackResolver functionCallbackResolver,
RetryTemplate retryTemplate, ResponseErrorHandler responseErrorHandler,
ObjectProvider<ObservationRegistry> observationRegistry,
ObjectProvider<ChatModelObservationConvention> observationConvention) {
var hunyuanApi = hunyuanApi(chatProperties.getSecretId(), commonProperties.getSecretId(),
chatProperties.getSecretKey(), commonProperties.getSecretKey(), chatProperties.getBaseUrl(),
commonProperties.getBaseUrl(), restClientBuilderProvider.getIfAvailable(RestClient::builder),
responseErrorHandler);
var chatModel = new HunYuanChatModel(hunyuanApi, chatProperties.getOptions(), functionCallbackResolver,
toolFunctionCallbacks, retryTemplate, observationRegistry.getIfUnique(() -> ObservationRegistry.NOOP));
observationConvention.ifAvailable(chatModel::setObservationConvention);
return chatModel;
}
@Bean
@ConditionalOnMissingBean
public FunctionCallbackResolver springAiFunctionManager(ApplicationContext context) {
DefaultFunctionCallbackResolver manager = new DefaultFunctionCallbackResolver();
manager.setApplicationContext(context);
return manager;
}
private HunYuanApi hunyuanApi(String secretId, String commonSecretId, String secretKey, String commonSecretKey,
String baseUrl, String commonBaseUrl, RestClient.Builder restClientBuilder,
ResponseErrorHandler responseErrorHandler) {
var resolvedSecretId = StringUtils.hasText(secretId) ? secretId : commonSecretId;
var resolvedSecretKey = StringUtils.hasText(secretKey) ? secretKey : commonSecretKey;
var resoledBaseUrl = StringUtils.hasText(baseUrl) ? baseUrl : commonBaseUrl;
Assert.hasText(resolvedSecretId, "HunYuan SecretId must be set");
Assert.hasText(resolvedSecretKey, "HunYuan SecretKey must be set");
Assert.hasText(resoledBaseUrl, "HunYuan base URL must be set");
return new HunYuanApi(resoledBaseUrl, resolvedSecretId, resolvedSecretKey, restClientBuilder,
responseErrorHandler);
}
}
由于我们在配置中设置了 matchIfMissing = true,这意味着如果您的项目中存在 HunYuanChatModel 类但未进行相应的配置时,系统将会直接抛出错误,提示您缺少相关的秘钥信息。
接着,你就需要将 HunYuanAutoConfiguration类添加到 imports 文件中,这一变化是 Spring 3.X 版本更新带来的调整。在早期版本中,这一配置文件被称为 spring.factories,具体内容可以参考下图所示。

这样,我们基本上完成了将刚才在 models 下编写的混元接口所对应的 model 和 api 各种 bean 信息整合并纳入 Spring 框架的管理之中。接下来,我们将进行简单的单元测试,以验证这些组件的功能是否正常。
单元测试
测试报错
在进行自动配置测试的过程中,我持续遇到一个错误,提示不支持读取过大的 JarEntry 文件。
java: 读取oci-java-sdk-shaded-full-3.51.0.jar时出错; Unsupported size: 12408573 for JarEntry META-INF/MANIFEST.MF. Allowed max size: 8000000 bytes
这并不是我们自己编写的代码,而是原有项目所附带的包依赖。我们尝试了多种解决方案,但始终未能奏效。最终发现问题仅仅是由于 JDK 17 的限制所致。为了解决这个问题,我们决定将项目的 JDK 直接升级到 21 版本,结果成功解决了所有相关问题。
函数回调
下面我将对函数回调进行简单演示,以便大家更好地理解其用法。至于其他方面的测试则相对简单,大家可以参考一下其他模型的测试方法。
@EnabledIfEnvironmentVariable(named = "HUNYUAN_SECRET_ID", matches = ".+")
@EnabledIfEnvironmentVariable(named = "HUNYUAN_SECRET_KEY", matches = ".+")
public class HunYuanFunctionCallbackIT {
private final Logger logger = LoggerFactory.getLogger(HunYuanFunctionCallbackIT.class);
private final ApplicationContextRunner contextRunner = new ApplicationContextRunner()
.withPropertyValues("spring.ai.hunyuan.secret-id=" + System.getenv("HUNYUAN_SECRET_ID"))
.withPropertyValues("spring.ai.hunyuan.secret-key=" + System.getenv("HUNYUAN_SECRET_KEY"))
.withConfiguration(AutoConfigurations.of(SpringAiRetryAutoConfiguration.class,
RestClientAutoConfiguration.class, HunYuanAutoConfiguration.class))
.withUserConfiguration(Config.class);
@Test
void functionCallTest() {
this.contextRunner.run(context -> {
HunYuanChatModel chatModel = context.getBean(HunYuanChatModel.class);
UserMessage userMessage = new UserMessage(
"What's the weather like in San Francisco, Tokyo, and Paris? Return the temperature in Celsius");
ChatResponse response = chatModel
.call(new Prompt(List.of(userMessage), HunYuanChatOptions.builder().function("WeatherInfo").build()));
logger.info("Response: {}", response);
assertThat(response.getResult().getOutput().getText()).contains("30", "10", "15");
});
}
//省略部分代码
主要仍然是通过环境变量的方式注入秘钥信息,构建 Hunyuan 链接,并且将天气相关的方法函数注入到模型中,以便进行后续调用。经过一系列的测试验证,结果如预期正常,所有功能均表现良好。如图所示:

接下来,我们需要编写一个启动器(starter)。这个过程相对简单,只需在 pom.xml 文件中添加相关的依赖项即可。
Starter
封装 spring-ai-hunyuan-spring-boot-starter 主要是与 Spring 自动配置相关的功能。通过添加该 Starter 依赖,它会自动将相关的组件和配置引入到项目中,从而让开发者能够方便地使用该功能。实际上,spring-ai-hunyuan-spring-boot-starter 相当于一个桥梁,连接了 spring-ai-spring-boot-autoconfigure 和项目中实际的功能需求。
我们来看一下它的项目结构,相对简洁,如下图所示:

其实就是一个pom依赖,内容如下:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-spring-boot-autoconfigure</artifactId>
<version>${project.parent.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-hunyuan</artifactId>
<version>${project.parent.version}</version>
</dependency>
</dependencies>
不过,除了上述步骤之外,你还需要在Spring AI的父级目录下添加该子工程,否则系统将无法正确找到相关的依赖信息。具体操作如图所示:

这部分没有任何代码,所以不用写任何测试。
Adoc文档
Spring AI 的说明文档使用的是antora,Antora 是一个开源的静态网站生成器,专门用于构建和发布文档网站。它是基于 AsciiDoc 格式的,旨在帮助用户生成结构化、易于导航的技术文档。Antora 被广泛应用于开发者文档、产品文档、技术说明书等场景。
如果感兴趣可以去看下官方文档:https://docs.antora.org/antora/latest/install-and-run-quickstart/
当然我们本地写说明文档,idea是有专门的插件供你安装的,可以本地实时预览并编辑。如图所示:

安装完成后,你就可以实时预览相关的文档内容了。需要注意的是,预览的格式与Markdown语法有所不同,因此为了更高效地进行编辑和查看,建议还是安装相应的插件,这样可以一边编辑一边实时预览,确保效果更加直观和准确。具体效果如下所示:

我们只需要编写两个文档,因为目前只继承了聊天和函数回调功能,相关目录如下所示:
不必担心从头开始写文档,其实你可以参考现有的说明文档。基本上,几乎所有大模型的说明文档内容在结构和表述上都非常相似。你所需要做的,仅仅是对其中的一些特定内容进行适当修改,具体来说,主要包括以下几个部分:
- 文档中的模型名称:需要根据当前使用的模型进行更新和调整。
- 文档中的秘钥和依赖信息:这一部分需要确保包含正确的API秘钥、依赖包的版本和相关配置。
- 文档中的options选项说明:根据实际的功能选项,进行相应的修改和补充。
- 文档底部的测试用例路径:测试用例的路径和文件名可能会有所不同,需根据实际路径进行修改。
总的来说,这些是需要我们重点修改的部分,其余的大部分内容都可以保持不变,因为它们构成了文档的基本框架和结构。如图所示,你可以很容易地识别出需要调整的地方。
最后一步是将该文档的路径添加到根目录下的 nav.adoc 文件中,以便于后续的索引和导航操作,从而确保文档能够快速、准确地被引用和查找。
文档生成
注意这里不要用windows执行命令
./mvnw -pl spring-ai-docs antora
在执行过程中,系统会出现报错,并且我无法在任何地方找到合适的修复方案。然而,当我在Linux机器上运行相同的操作时,一切正常,无任何错误,具体情况如图所示。

接下来,只需要部署一个HTML静态服务即可完成相关设置。在这里,我使用的是宝塔面板进行配置,具体的操作步骤如下图所示。
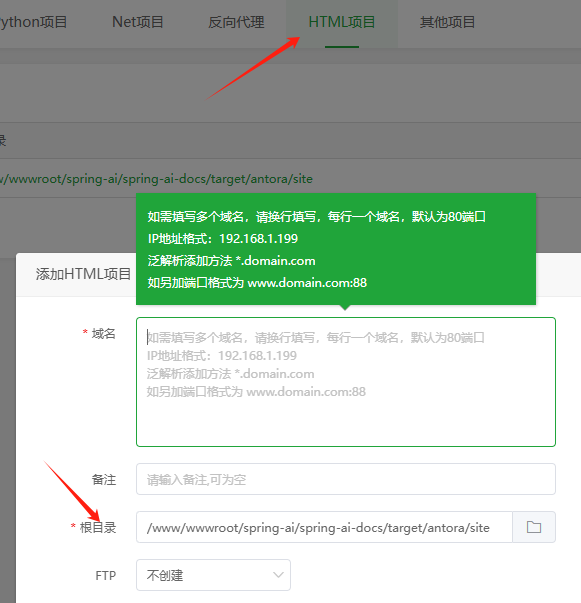
首先,确保在根目录中选择了Antora生成的文件所在的正确位置。完成这一步后,接下来启动Apache服务即可。如果你更倾向于使用Nginx,直接配置它也是完全可以的。最后,检查一下最终效果,应该会与下图所示相符。
集成测试
至此,上述所有配置基本完成,接下来只需在本地进行测试,确认系统是否能够正常启动并运行混元大模型。为了确保依赖包能够本地可用,我们只需执行 mvn install 命令,这样会将混元(Hunyuan)依赖包安装到本地Maven仓库。当其他项目需要引用此依赖时,它们会直接从本地仓库获取,而无需每次都从Maven远程仓库拉取。具体效果可以参考下图所示。
紧接着,我们在本地创建一个新的空文件夹,专门用于测试和运行Spring AI的Demo案例。
POM依赖
首先在新项目中依赖修改内容版本,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.1</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo</name>
<description>Demo project for Spring Boot</description>
<url/>
<properties>
<java.version>17</java.version>
<spring-ai.version>1.0.0-SNAPSHOT</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-hunyuan-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
</project>
紧接着,我们开始配置混元的相关配置信息,包括系统所需的环境变量、服务端口设置以及其他关键参数,以确保系统能够顺利运行并与其他组件进行高效的协同工作。
spring.application.name=spring-ai-demo
server.port=9149
spring.ai.hunyuan.base-url=https://api.hunyuan.cloud.tencent.com
# 秘钥信息
spring.ai.hunyuan.secret-id=123
spring.ai.hunyuan.secret-key=123
spring.ai.hunyuan.chat.options.model=hunyuan-pro
简单对话
接下来,我们将继续进行一些基本的测试,以验证我们的正常对话功能、图片理解能力以及函数回调功能是否一切正常。为了便于演示,暂时我只是简单实现了一个内存级别的消息存储机制。以下是相关的测试代码:
@Slf4j
@RestController
class ChatClientController {
private final ChatMemory chatMemory = new InMemoryChatMemory();
private final ChatMemory chatimageMemory = new InMemoryChatMemory();
private final ChatClient chatClient;
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
/**
* 当前用户输入后,返回一个文本类型的回答
* @param userInput
* @return
*/
@PostMapping("/ai")
ChatDataPO generationByText(@RequestParam("userInput") String userInput) {
String content = this.chatClient.prompt()
.user(userInput).advisors(new MessageChatMemoryAdvisor(chatMemory))
.call().content();
log.info("content: {}", content);
ChatDataPO chatDataPO = ChatDataPO.builder().code("text").data(ChildData.builder().text(content).build()).build();;
return chatDataPO;
}
@PostMapping("/ai-image")
ChatDataPO generationByImage(@RequestParam("userInput") String userInput,@RequestParam("url") String imageUrl) throws MalformedURLException {
UserMessage userMessage = new UserMessage(userInput, List.of(Media
.builder()
.mimeType(MimeTypeUtils.IMAGE_PNG)
.data(new URL(
imageUrl))
.build()));
ChatOptions chatOptions = ChatOptions.builder().model("hunyuan-turbo-vision").build();
String content = this.chatClient.prompt().messages(userMessage).options(chatOptions)
.advisors(new MessageChatMemoryAdvisor(chatimageMemory))
.call().content();
ChatDataPO chatDataPO = ChatDataPO.builder().code("text").data(ChildData.builder().text(content).build()).build();;
return chatDataPO;
}
@PostMapping("/ai-function")
ChatDataPO functionGenerationByText(@RequestParam("userInput") String userInput) {
String systemPrompt = """
- Role: 个人助理小助手
- Background: 用户需要一个多功能的AI助手,可以提供实时的天气信息。
- Profile: 你是一个专业的个人助理小助手,具备强大的信息检索能力和数据处理能力,能够为用户提供精确的天气信息。
- Skills: 你拥有强大的网络搜索能力、数据处理能力以及用户交互能力,能够快速准确地为用户提供所需信息。
- Goals: 提供准确的天气信息。
- Constrains: 提供的信息必须准确无误。
- OutputFormat: 友好的对话式回复,包含必要的详细信息和格式化的数据。
- Workflow:
1. 接收用户的天气查询请求,并提供准确的天气信息。
""";
String content = this.chatClient.prompt()
.user(userInput).system(systemPrompt)
.options(HunYuanChatOptions.builder().temperature(0.9).build())
.functions("CurrentWeather")
.call()
.content();
log.info("content: {}", content);
ChatDataPO chatDataPO = ChatDataPO.builder().code("text").data(ChildData.builder().text(content).build()).build();
return chatDataPO;
}
}
需要特别注意的是,在版本1.0的快照版本中,如果没有显式声明options参数,函数回调将无法正常触发。这是一个已知的限制,必须确保在调用时传递该参数才能确保回调功能的正确执行。下面是相关的示例代码:
.options(HunYuanChatOptions.builder().temperature(0.9).build())
好的,我们直接进行效果测试,看看实际的表现如何。为了便于演示,我没有采用流式返回方式,而是使用了常规的请求方式。接下来,我们可以观察一下正常聊天对话的情况是否一切正常,具体情况如图所示:
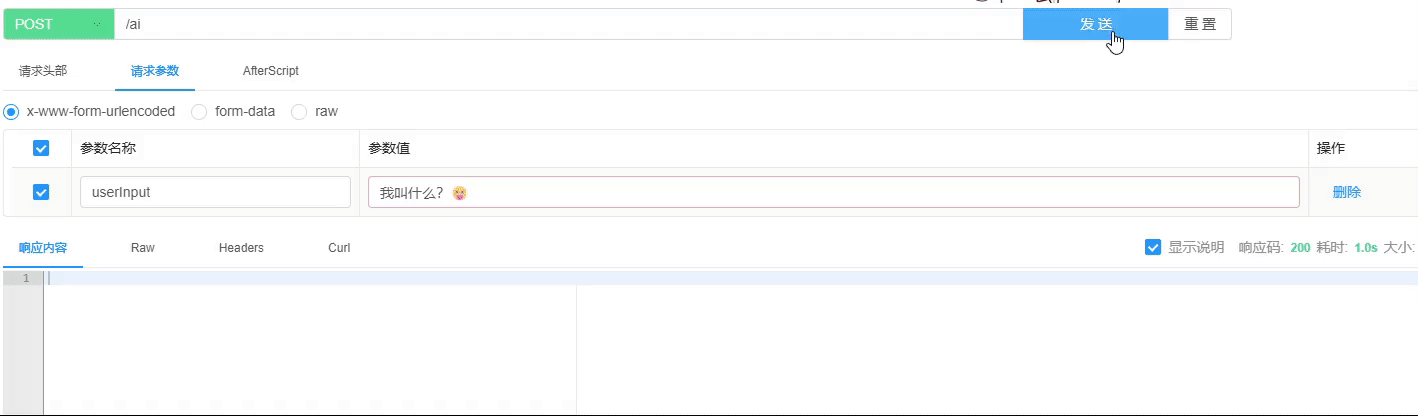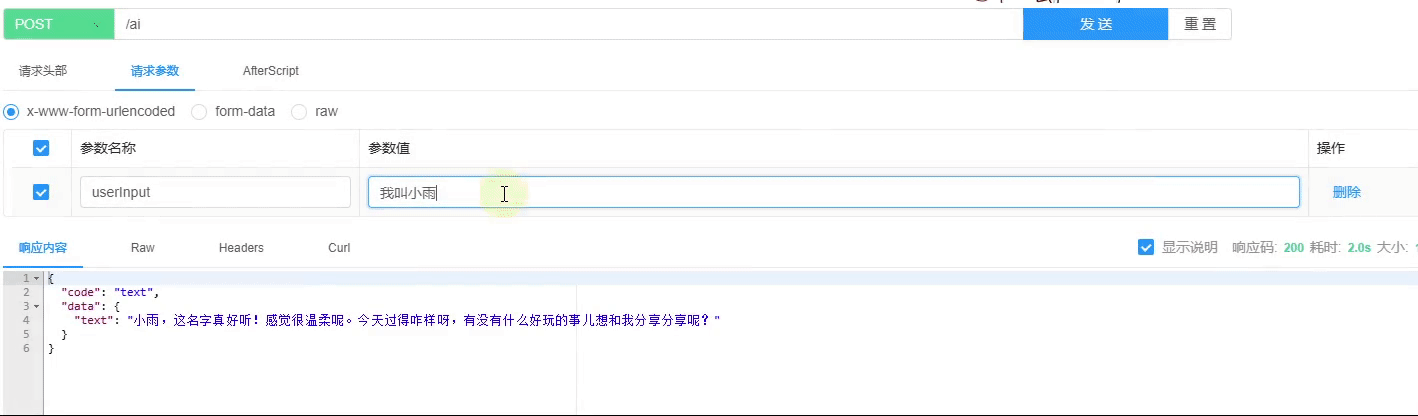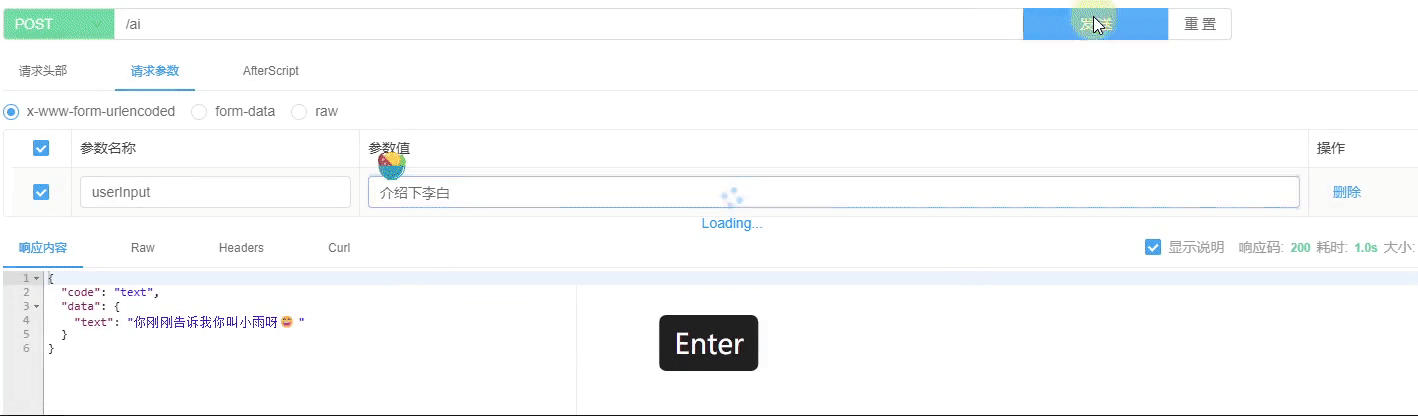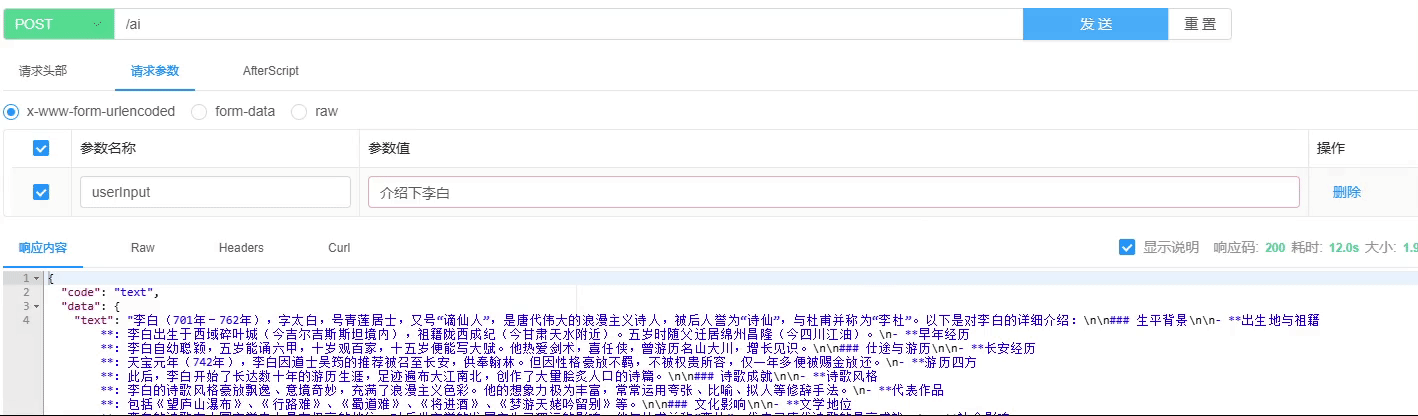
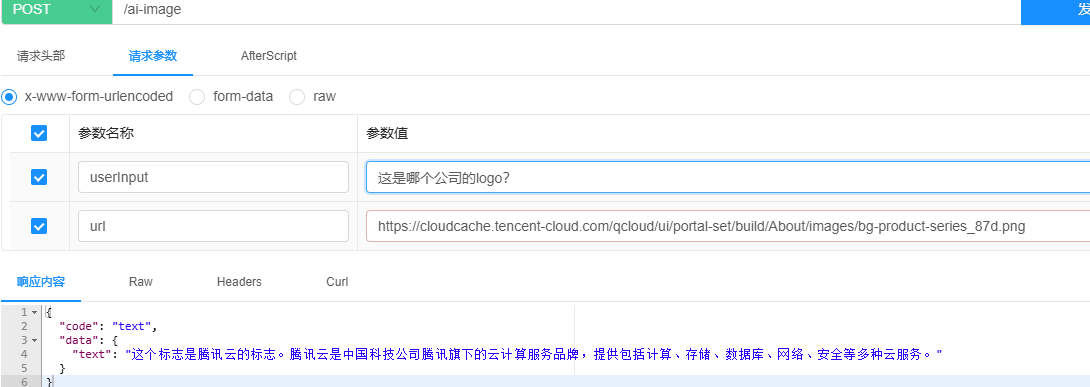
图片理解测试已经顺利完成,结果显示正常。具体情况请参见下方图示:
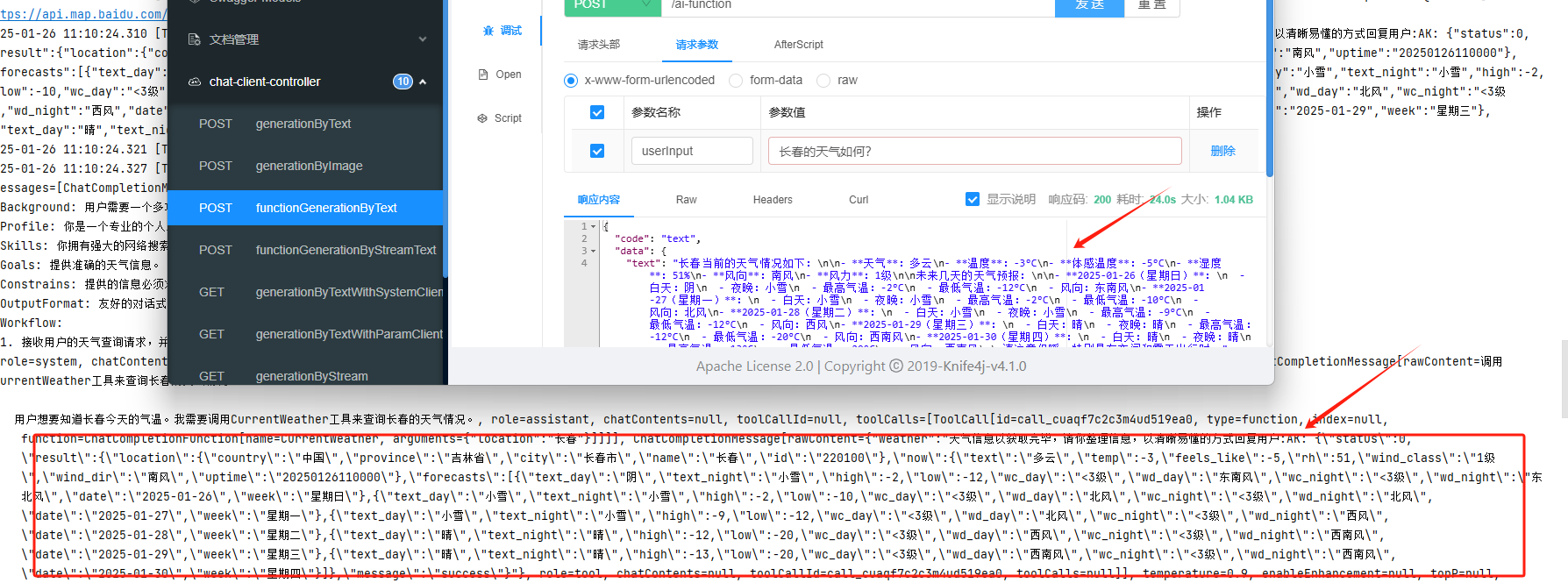
接下来,我们可以检查一下最后的函数回调是否能够正常执行。请参考下图所示:
目前,所有功能均已正常运行,这意味着我们已基本完成了聊天系统的核心功能。如果您对系统的实现细节感兴趣,欢迎查看我已提交的相关源码。您可以通过以下GitHub PR地址访问代码: https://github.com/spring-projects/spring-ai/pull/2091。
为了帮助新入门的小伙伴更好地理解相关概念与技术,建议首先阅读一系列的基础文章,这些文章将逐步引导您熟悉整个流程和关键知识点。您可以通过以下链接访问这些内容:
- 深入解析 Spring AI 系列:项目结构一览:https://www.cnblogs.com/guoxiaoyu/p/18650932
- 深入解析 Spring AI 系列:剖析OpenAI接口接入组件:https://www.cnblogs.com/guoxiaoyu/p/18657750
- 深入解析 Spring AI 系列:以OpenAI与Moonshot案例为例寻找共同点: https://www.cnblogs.com/guoxiaoyu/p/18660472
- 深入解析 Spring AI 系列:解析OpenAI接口对接: https://www.cnblogs.com/guoxiaoyu/p/18665146
- 深入解析 Spring AI 系列:解析函数调用: https://www.cnblogs.com/guoxiaoyu/p/18666904
- 深入解析 Spring AI 系列:分析 Spring AI 可观测性: https://www.cnblogs.com/guoxiaoyu/p/18669015
- 深入解析 Spring AI 系列:解析返回参数处理:https://www.cnblogs.com/guoxiaoyu/p/18670755
- 深入解析 Spring AI 系列:解析请求参数处理:https://www.cnblogs.com/guoxiaoyu/p/18677050
总结
在本篇文章中,我们详细介绍了如何将腾讯的混元大模型集成到Spring AI项目中,并通过一系列实战操作,展示了从环境准备到最终实现的全过程。我们从基础的依赖配置、接口对接,到复杂的流式请求处理和自动配置,逐步深入,确保每一个步骤都清晰明了。
通过深入分析和逐步解决还总结了一些实用的经验和技巧。例如,通过使用ModelOptionsUtils工具类来处理JSON与对象之间的转换,避免了直接操作可能带来的错误;在处理流式请求时,我们特别注意了数据合并的逻辑,确保了响应的高效性和准确性。
在完成核心功能开发后,我们进一步介绍了如何通过Spring Boot的自动配置机制,将混元大模型集成到Spring AI的管理中,并通过编写启动器(starter)和文档,为开发者提供了更加便捷的使用方式。通过Antora工具生成的文档,我们详细记录了混元大模型的使用方法、配置选项以及测试用例,为开发者提供了全面的参考。
最后,通过本地集成测试,我们验证了整个系统的正常运行,展示了混元大模型在Spring AI中的实际应用效果。从简单的对话到复杂的函数回调,所有功能均表现良好,证明了我们集成工作的成功。
总的来说,通过本文的详细介绍,读者不仅能够掌握如何将混元大模型集成到Spring AI中,还能够理解其中的关键技术和实现细节。希望这篇文章能够为正在探索Spring AI和大模型集成的开发者提供有价值的参考和指导。如果你对这个项目感兴趣,或者想要进一步了解相关技术,欢迎访问我们的GitHub仓库PR,查看完整的代码和文档。
我是努力的小雨,一个正经的 Java 东北服务端开发,整天琢磨着 AI 技术这块儿的奥秘。特爱跟人交流技术,喜欢把自己的心得和大家分享。还当上了腾讯云创作之星,阿里云专家博主,华为云云享专家,掘金优秀作者。各种征文、开源比赛的牌子也拿了。
💡 想把我在技术路上走过的弯路和经验全都分享出来,给你们的学习和成长带来点启发,帮一把。
🌟 欢迎关注努力的小雨,咱一块儿进步!🌟



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek-R1本地部署如何选择适合你的版本?看这里
· 开源的 DeepSeek-R1「GitHub 热点速览」
· 传国玉玺易主,ai.com竟然跳转到国产AI
· 揭秘 Sdcb Chats 如何解析 DeepSeek-R1 思维链
· 自己如何在本地电脑从零搭建DeepSeek!手把手教学,快来看看! (建议收藏)