从零开始学机器学习——入门NLP
首先给大家介绍一个很好用的学习地址:https://cloudstudio.net/columns
今天我们将深入探讨自然语言处理(Natural Language Processing, NLP)这一领域。自然语言处理是人工智能的一个重要子领域,主要关注如何使机器理解和处理人类的语言,从而能够执行诸如拼写检查、机器翻译等多种任务。
目前,自然语言处理的应用场景相当广泛,大家熟悉的智能助手如Siri和Alexa就是典型的例子。接下来的课程中,我们将首先实现一个基础版的聊天机器人,随后逐步分析如何优化和提升机器人的智能表现,使其更加接近于人类的思考方式。
那么,我们就从这里开始吧!
聊天机器人
在我们学习自然语言处理(NLP)的过程中,掌握以下技能将是非常重要的:
- Python 3:作为一种功能强大且易于学习的编程语言,Python 3 是进行自然语言处理的首选语言,它拥有丰富的库和框架,能够有效支持各类 NLP 任务。
- 您喜欢的 Python IDE:选择一个适合自己的集成开发环境(IDE)可以大大提高编程效率,无论是 PyCharm、Jupyter Notebook 还是 VS Code,找到最适合自己的工具是至关重要的。
- TextBlob:这是一个建立在两个广受欢迎的库——自然语言工具包(NLTK)和 Pattern 之上的库。TextBlob 利用这两个库的强大功能,使文本分析和处理变得更加简单直观。它提供了一个用户友好的 API,适用于各种自然语言处理任务,包括情感分析、文本分类、翻译等。TextBlob 是一个非常适合快速开发和原型制作的工具,特别适合需要处理文本数据的项目。
无脑版聊天
一开始就试图实现一个功能完美的聊天机器人,对我们这些初学者来说显然是不现实的。因此,我们将采取逐步推进的方法,先实现一个基础版本的聊天机器人,看看能否在此基础上进行不断优化,最终朝着我们理想中的智能机器人的目标前进。
现在,我们将着手实现一个最简单的聊天机器人。这个机器人将通过随机回应来与用户进行互动,直到用户选择结束对话为止。
代码实现
import random
# This list contains the random responses (you can add your own or translate them into your own language too)
random_responses = ["That is quite interesting, please tell me more.",
"I see. Do go on.",
"Why do you say that?",
"Funny weather we've been having, isn't it?",
"Let's change the subject.",
"Did you catch the game last night?"]
print("Hello, I am Marvin, the simple robot.")
print("You can end this conversation at any time by typing 'bye'")
print("After typing each answer, press 'enter'")
print("How are you today?")
while True:
# wait for the user to enter some text
user_input = input("> ")
if user_input.lower() == "bye":
# if they typed in 'bye' (or even BYE, ByE, byE etc.), break out of the loop
break
else:
response = random.choices(random_responses)[0]
print(response)
print("It was nice talking to you, goodbye!")
Hello, I am Marvin, the simple robot.
You can end this conversation at any time by typing 'bye'
After typing each answer, press 'enter'
How are you today?I am good thanks
That is quite interesting, please tell me more.ok, lets talk about music
Why do you say that?because I like music!
Why do you say that?bye
It was nice talking to you, goodbye!
其实,这个过程还是相对简单的,因此在这里就不需要过多解释了。不过,我们可以从中发现一些有趣的问题。
首先,你认为这些随机回应能够“欺骗”人类,让人类误以为机器人实际上理解了他们的意思吗?这是一个引人深思的问题,涉及到人机交互的本质。
其次,为了让机器人更有效地回应用户,它需要具备哪些功能呢?例如,机器人是否需要具备上下文理解能力,以便更好地跟踪对话的主题和方向?
此外,如果机器人真的能够“理解”一个句子的意思,那么它是否也需要“记住”前面句子的意思,以便在对话中保持一致性和连贯性?
对于大多数自然语言处理(NLP)任务,程序必须将文本进行分解、检查,并存储处理结果或与相关规则和数据集进行交叉引用。这些任务使程序员能够提取文本中术语和单词的含义、意图或频率等信息。
接下来,我们将看看NLP专家们所面临的一些问题。虽然我们目前可能不需要深入了解这些底层知识,但对这些挑战有一个大概的印象是有益的。毕竟,掌握工具的使用才是我们当前的首要目标。通过实践,我们将逐步积累经验,深入探索更复杂的概念和技术。
NLP 常见的任务
其实,我们的主要目标仅仅是对文本进行有效的分析和处理。通过理解这些自然语言处理任务,我们希望能够提取出有价值的信息,并得出我们所追求的结论。
- 标记化
- 将文本拆分为标记或单词,需考虑标点符号和语言特性。例如:将句子“猫在窗台上睡觉。”拆分为标记:["猫", "在", "窗台", "上", "睡觉", "。"]。
- 嵌入
- 将文本数据转换为数字形式,使相似含义的单词聚集在一起。例如:将单词“王子”和“国王”转换为数字向量,使它们在高维空间中更接近,因为它们有相似的含义。
- 解析和词性标注
- 为每个标记化的单词标注词性(如名词、动词、形容词等)。例如:这一句话:“聪明的学生回答了问题。”,标注“学生=名词”,“回答=动词”。
- 单词和短语频率
- 统计文本中每个单词或短语的出现频率。例如:在文本中统计“猫”的频率,如果出现了5次,则记录为“猫: 5”。
- N 元语法
- 将文本分割成固定长度的单词序列(unigram、bigrams、trigrams等)。例如:在句子“我爱吃苹果。”中,生成的二元语法(bigrams)为:["我爱", "爱吃", "吃苹果"]。
- 名词短语提取
- 识别句子中的名词短语,通常作为主语或宾语。例如:在句子“美丽的花朵盛开。”中,提取名词短语“美丽的花朵”。
- 情感分析
- 分析文本的情绪倾向,评估其积极或消极程度。例如:分析句子“这个电影太棒了!”得出积极的情绪评分,例如0.8(积极)。
- 词形变化
- 获取单词的单数或复数形式。这一块在英文中其实更好理解因为他们有专门的写法,如果中文的话,例如:将单词“狗”的复数形式转换为“狗狗们”。
- 词形还原
- 找出单词的词根或中心词。例如:将单词“飞”、“飞翔”、“飞行”都还原为词根“飞”。
- WordNet(词网)
- 一个包含同义词、反义词和详细信息的数据库,对语言工具的构建非常有用。例如:查询“快乐”这个词,得到其同义词如“高兴”、“愉快”,以及反义词如“悲伤”。
这么一看,即使是一句简短的话,我们也需要进行大量的处理才能得出有效的结论,这样才能让机器做出像人类一样的回答。然而,幸运的是,Python提供了众多自然语言处理(NLP)库和依赖包,供我们自由选择。这些工具的存在使得我们无需深入复杂的底层实现,只需通过简单的API调用,就能快速分析文本并获取结果,真正省去了重复造轮子的麻烦。
接下来,我们可以以刚才基础的无脑版聊天机器人为起点,进一步增加情感分析和名词提取的功能。情感分析将使机器人能够识别用户的情绪状态,而名词提取则可以帮助它抓住对话中的关键内容。这样一来,我们就能更有效地回应用户的问题,使得交流变得更加流畅和自然。
情感分析版聊天
我们刚才介绍过了TextBlob库,这里不再赘述了,如果你希望深入学习这个强大的自然语言处理库,这里也有入门链接,帮助你更好地理解它的用法。
现在,我们可以简单实现一个聊天机器人的代码。这个机器人的主要目的是首先分析输入的这句话,判断其情绪是积极还是消极。如果用户的输入中提到了某些名词,我们将把这些名词融入到机器人的回复中,并主动向用户询问相关内容,以营造出更自然、富有情感的交流氛围。
代码实现
接下来,让我们来看看具体的代码实现:
import random
from textblob import TextBlob
from textblob.np_extractors import ConllExtractor
import nltk
# 下载 NLTK 资源
nltk.download("punkt_tab")
nltk.download('conll2000')
extractor = ConllExtractor()
def main():
print("Hello, I am Marvin, the friendly robot.")
print("You can end this conversation at any time by typing 'bye'")
print("After typing each answer, press 'enter'")
print("How are you today?")
while True:
# wait for the user to enter some text
user_input = input("> ")
if user_input.lower() == "bye":
# if they typed in 'bye' (or even BYE, ByE, byE etc.), break out of the loop
break
else:
# Create a TextBlob based on the user input. Then extract the noun phrases
user_input_blob = TextBlob(user_input, np_extractor=extractor)
np = user_input_blob.noun_phrases
response = ""
if user_input_blob.polarity <= -0.5:
response = "Oh dear, that sounds bad. "
elif user_input_blob.polarity <= 0:
response = "Hmm, that's not great. "
elif user_input_blob.polarity <= 0.5:
response = "Well, that sounds positive. "
elif user_input_blob.polarity <= 1:
response = "Wow, that sounds great. "
if len(np) != 0:
# There was at least one noun phrase detected, so ask about that and pluralise it
# e.g. cat -> cats or mouse -> mice
response = response + "Can you tell me more about " + np[0].pluralize() + "?"
else:
response = response + "Can you tell me more?"
print(response)
print("It was nice talking to you, goodbye!")
# Start the program
main()
这段代码的功能可以大致分为以下几个部分:
- 初始化提取器:创建一个名词短语提取器实例
extractor。这个提取器将用于识别用户输入中的重要名词短语。 - 主函数:
- 启动与用户的对话,欢迎信息和提示。
- 进入一个循环,等待用户输入。
- 如果用户输入“bye”,程序结束对话。
- 否则,使用
TextBlob创建一个对象来分析用户输入:- 提取名词短语。
- 根据文本的情感极性生成不同的回应(从负面到正面)。
- 如果检测到名词短语,询问用户关于这些名词短语的更多信息,并将名词短语变为复数形式。
- 如果没有检测到名词短语,则询问用户更多信息。
- 结束对话:当用户输入“bye”后,程序打印告别信息并结束。
通过情感分析和名词短语提取,机器人能够提供更为针对性的回应,相比于之前的无脑机器人,显然会显得更具互动性和响应性。让我们来看看它的实际效果:
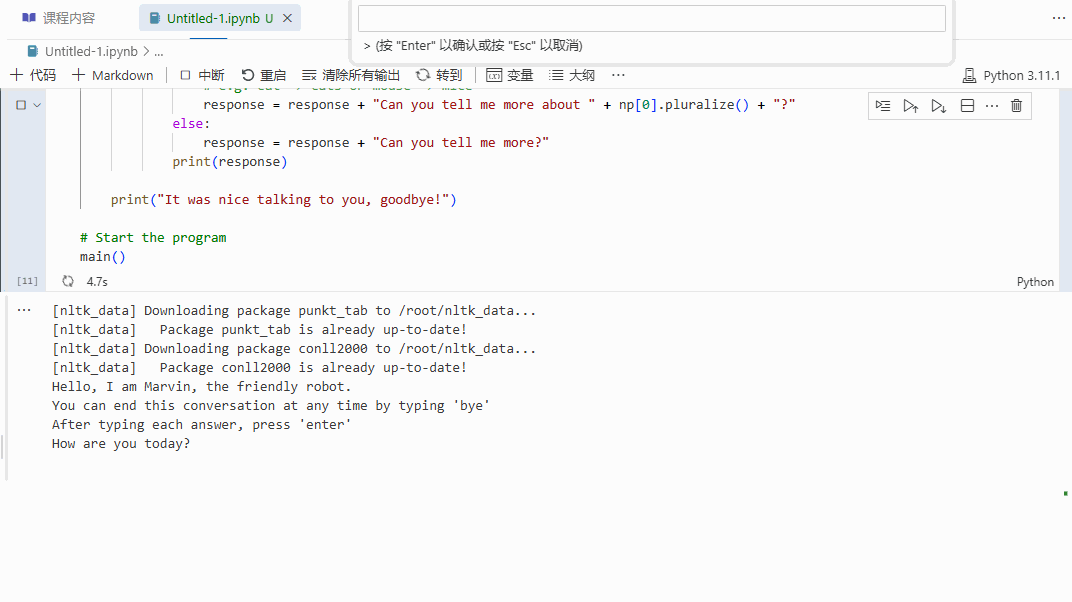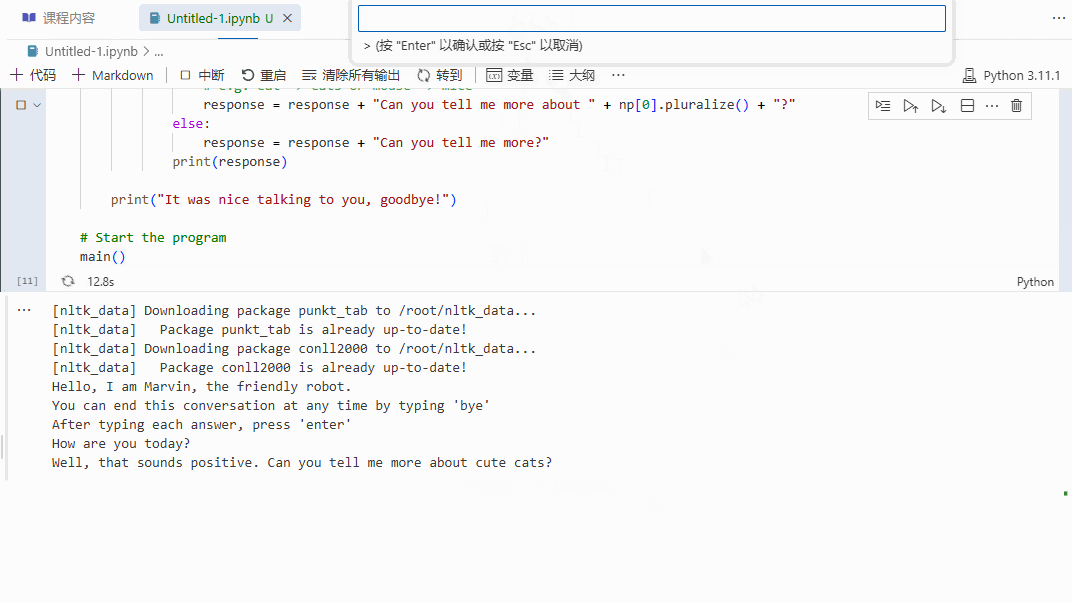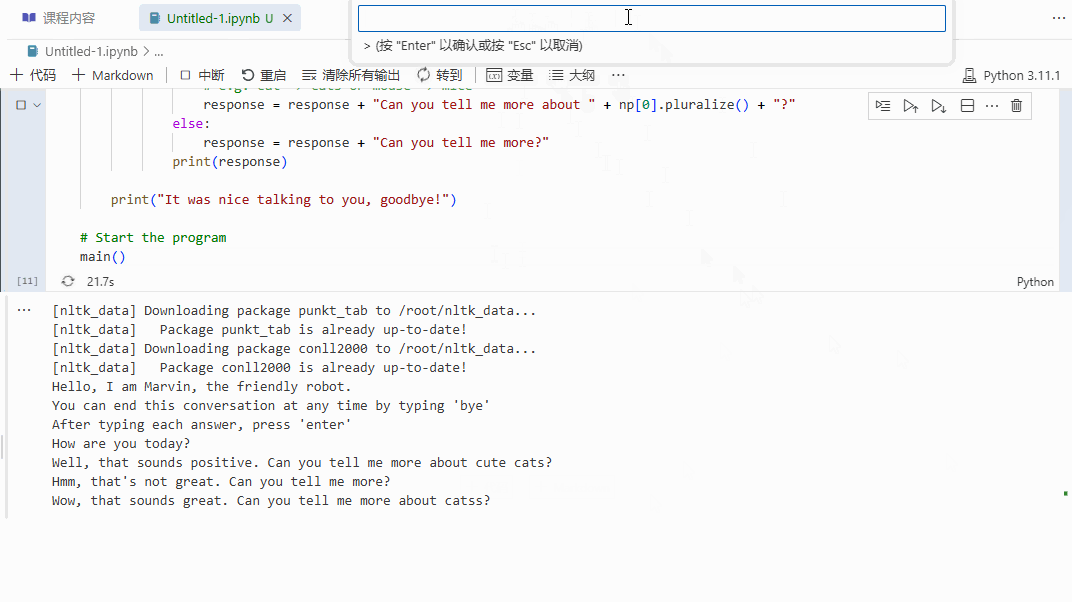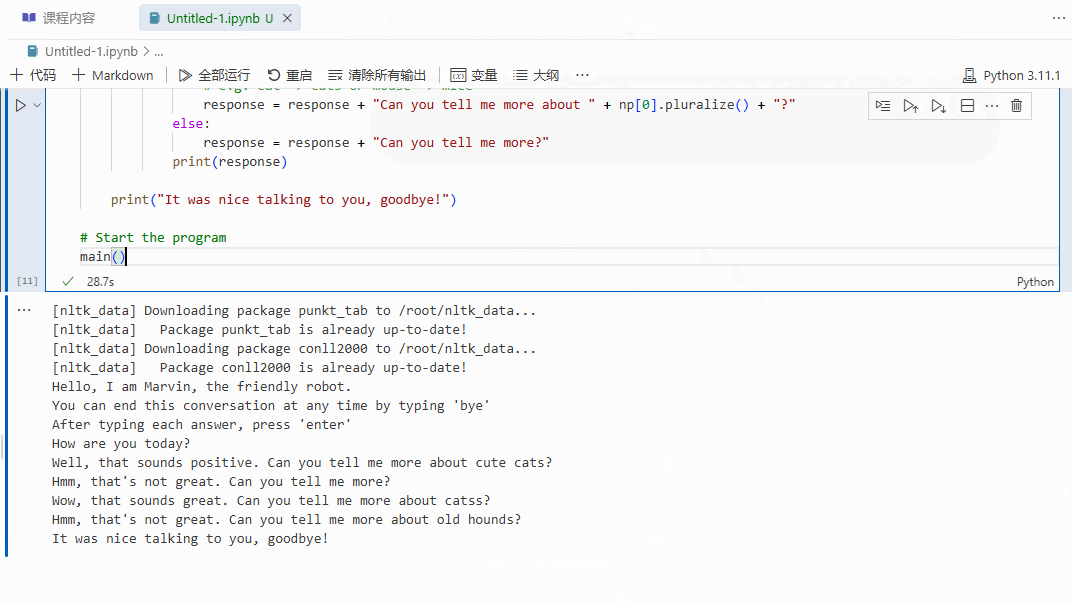
总结
在探索自然语言处理(NLP)的过程中,我们学习了如何构建一个基本的聊天机器人,从随机回应到情感分析,实现了逐步优化的过程。通过使用Python及其强大的库,如TextBlob,我们能够轻松处理文本数据并提取有价值的信息。
今天,我们介绍了NLP的基本概念和常见任务,涵盖了标记化、情感分析、名词短语提取等内容。这些技能不仅能帮助我们构建简单的聊天机器人,还为日后深入研究更复杂的NLP问题奠定了基础。
今后,我们将继续探索更高级的NLP技术,进一步提升机器人的智能和互动能力。让我们一起期待下一次的学习旅程吧!
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟

 浙公网安备 33010602011771号
浙公网安备 33010602011771号