
Hadoop(1):Centos 7 安装 Hadoop 3.2.1
最近学习大数据相关的知识,便于对学习知识进行整理记忆,特将学习过程中的一些内容记录于此。
本地环境:
Linux系统:Centos 7(最小安装)
内存:4G
CPU: 2
网卡:2(IP:10.0.2.5、192.168.56.200)
JDK版本:1.8
Hadoop版本:3.2.1
一、虚拟机环境准备
在宿主机中创建符合上述规格的虚拟机一台,并设置IP。
修改主机名:
# hostnamectl set-hostname hadoop200
关闭防火墙:
# systemctl stop firewalld
禁止防火墙开机启动:
# systemctl disable firewalld
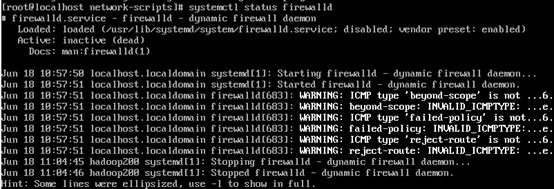
查看防火墙状态:
# systemctl status firewalld
二、安装JDK
参考博文:https://www.cnblogs.com/guoxiangyue/p/9633063.html
三、安装hadoop
下载hadoop 3.2.1 ,
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
下载完成后,将hadoop-3.2.1.tar.gz上传至Linux机器的 /usr/local 目录下:

解压安装包:
# tar -zvxf hadoop-3.2.1.tar.gz
# mv hadoop-3.2.1 hadoop
将hadoop添加环境变量
# vim /etc/profile
将以下内容添加到该文件中:
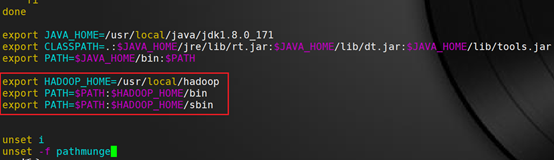
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存退出
使配置生效
# source /etc/profile
测试是否安装成功
# hadoop version

成功回显信息,hadoop配置完成。
四、本地模式运行wordcount 案例
创建input文件夹及wc.input 文件
# cd /usr/local/hadoop
# mkdir wcinput
# cd wcinput
# vim wc.input
将以下内容写入文件中:

hadoop
hadoop HDFS
aiden
guo xiangyue
mapreduce
HDFS guo aiden
回到Hadoop目录
# cd /usr/local/hadoop
执行程序
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount wcinput wcoutput
执行完毕,生成wcoutput 文件夹

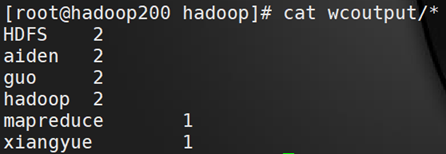
查看执行结果:
# cat wcoutput/*


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?