Hadoop MapReduce 操作 统计词频
1、 准备文件并设置编码格式为UTF-8并上传Linux
1)设置编码:首先打开文件点击左上角 文件(F) 点击另存为并将编码(E)设置为UTF-8 然后保存(S)替换的原来的文件
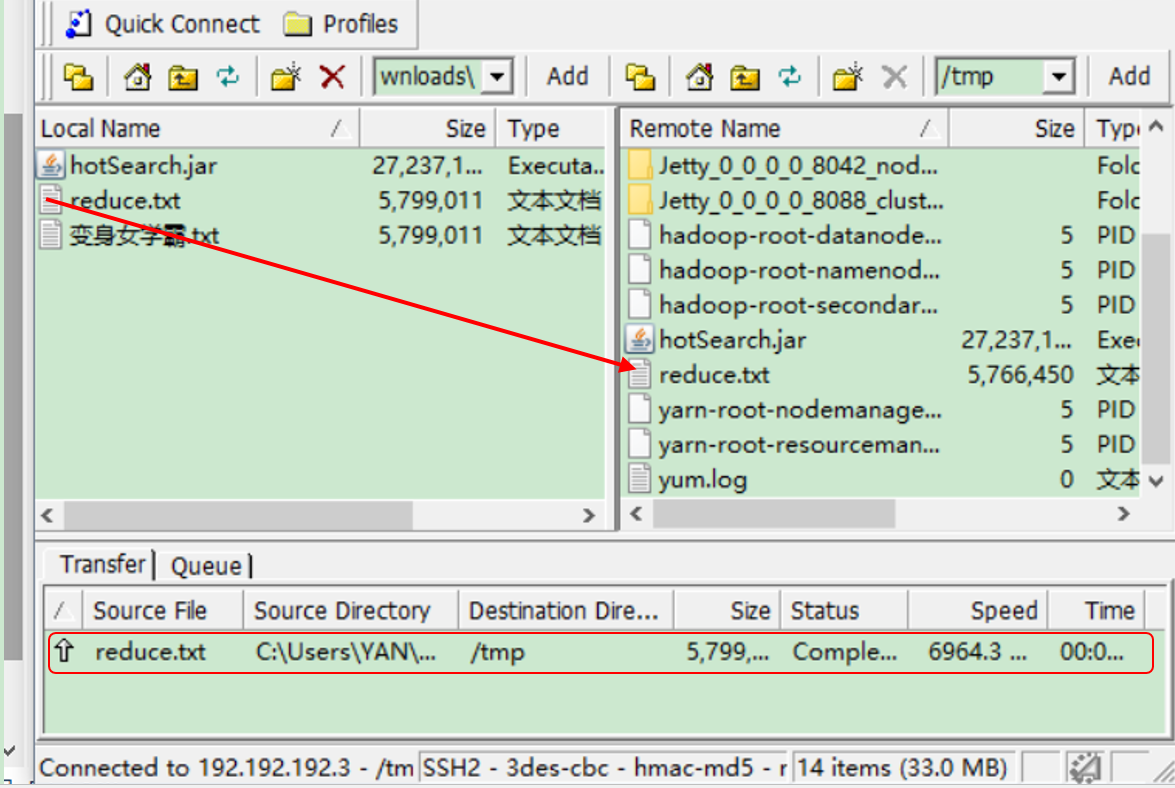
2)用工具将文件上传就Linux
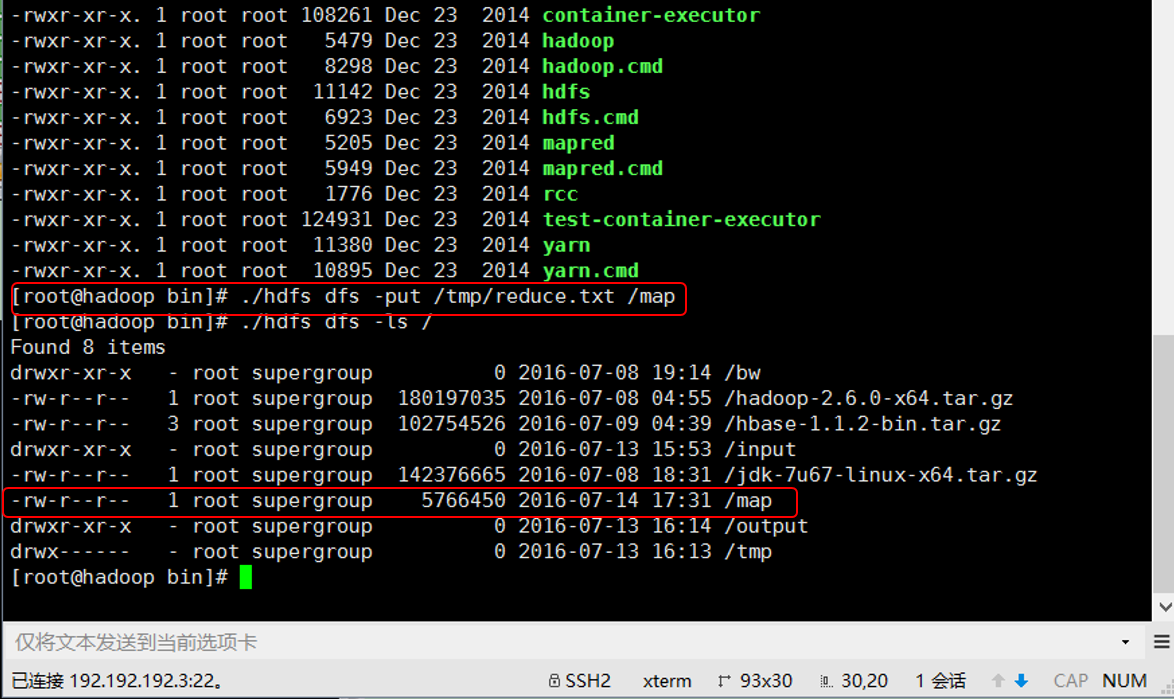
3)将文件上传至HDFS
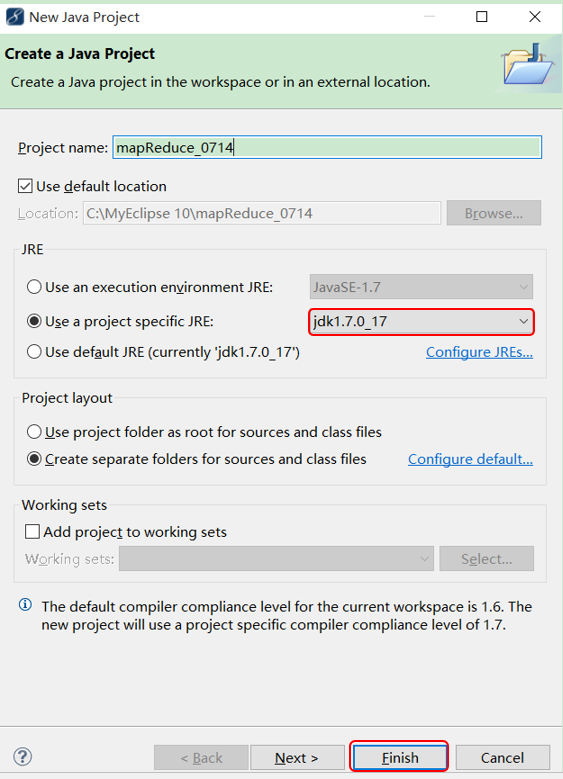
2、 新建一个Java Project
JDK必须是1.7版本以后的否则不支持

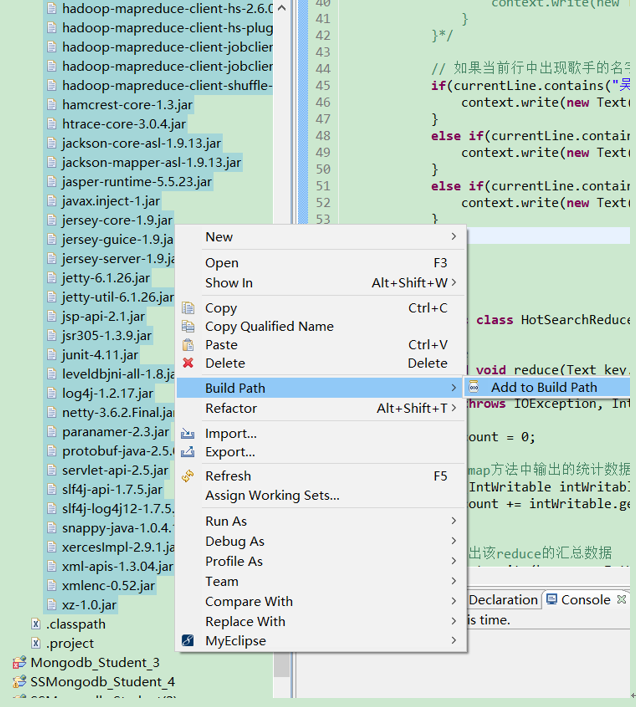
3、 导入jar
导入好多jar包并Add to Build Path

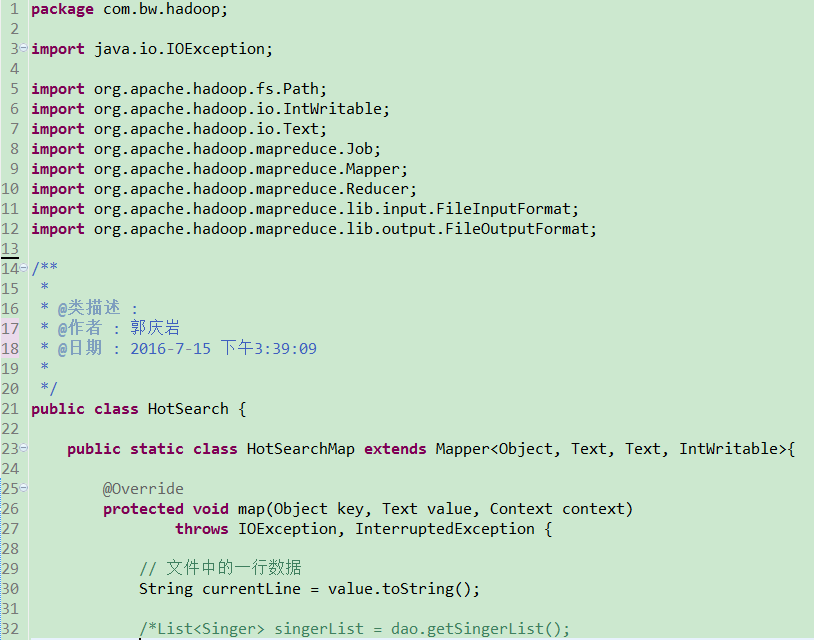
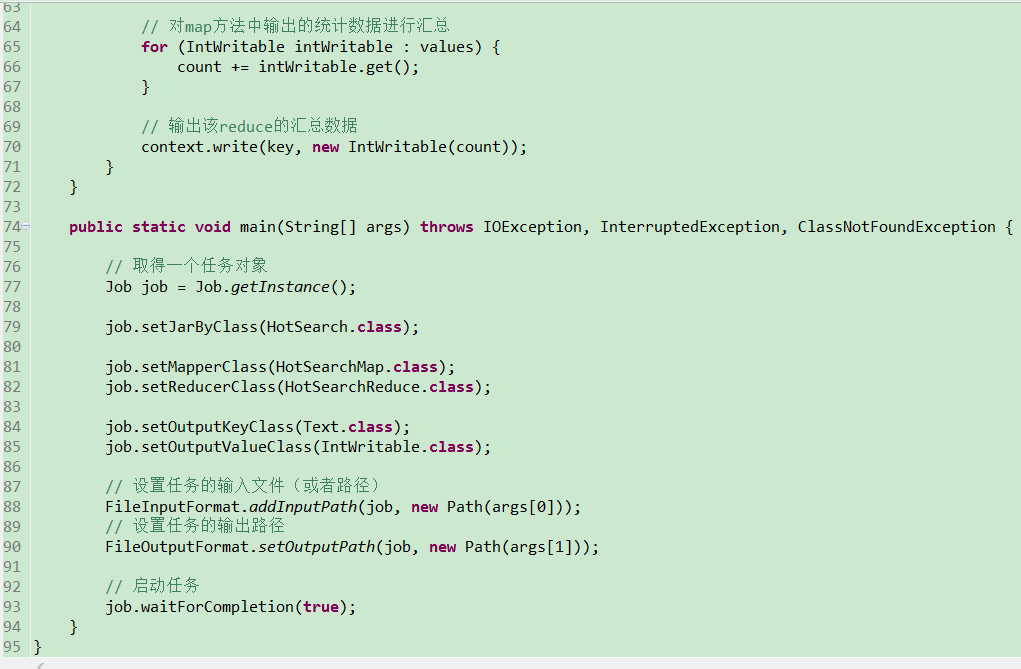
4、 编写Map()和Reduce()

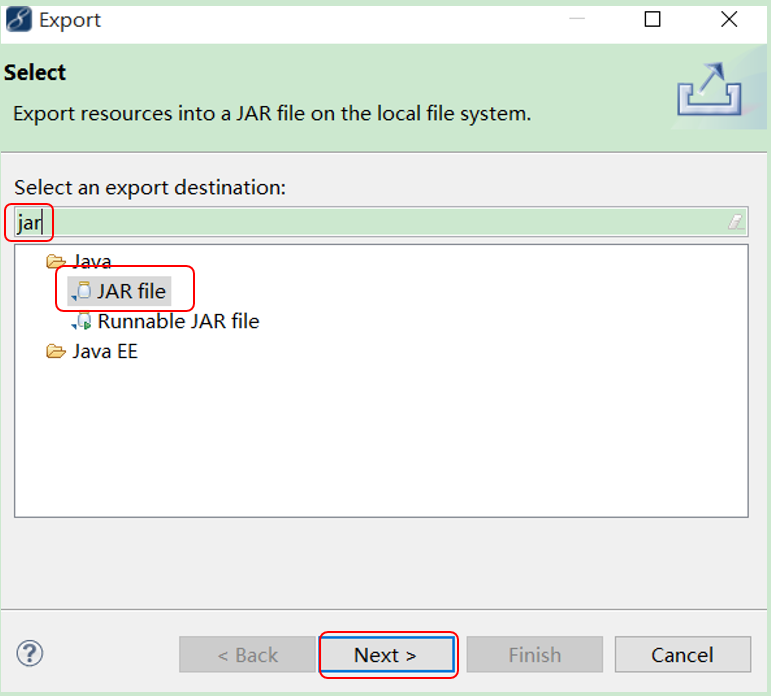
5、将代码输出成jar
1) 将代码输出成jar

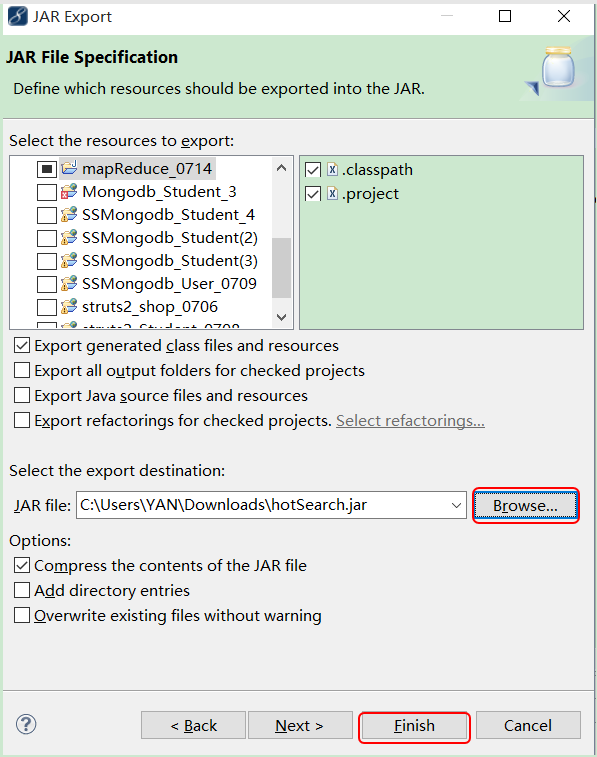
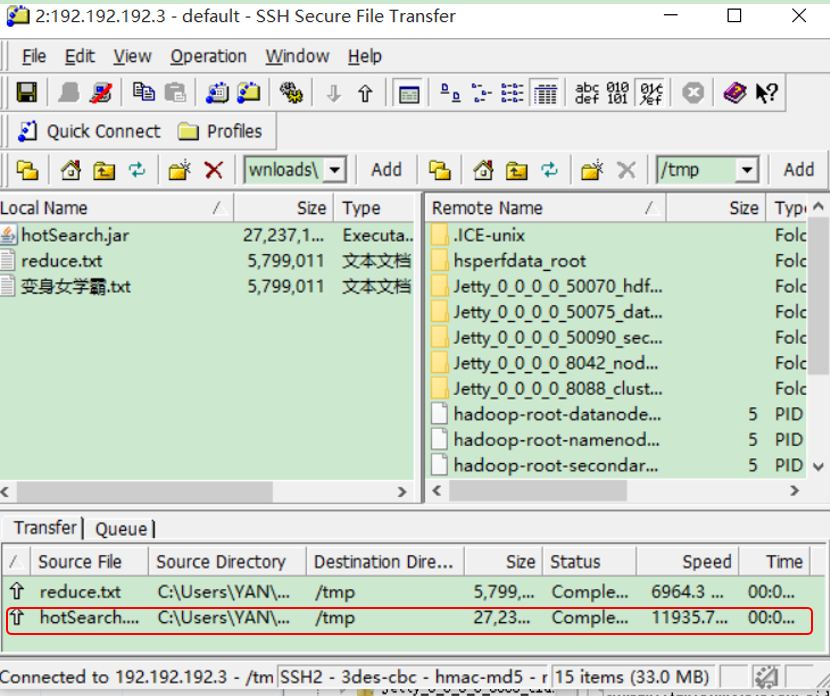
2) 将生成的jar上传至Linux
6、在linux中启动hdfs
1) 启动hdfs

1) 将text文件上传到HDFS

7、修改两个配置文件

在<configuration>配置项中增加以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
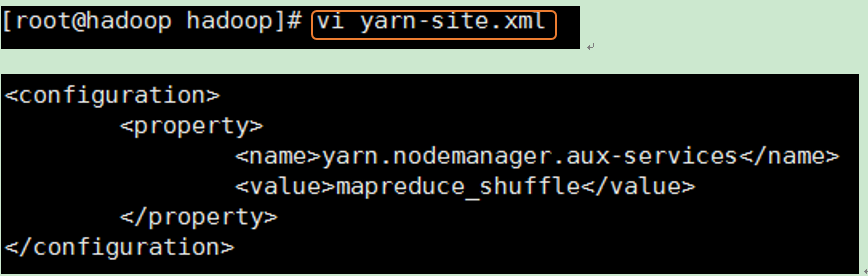
在<configuration>配置项中增加以下内容:
(参数解释:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运MapReduce程序)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8、在linux中启动yarn
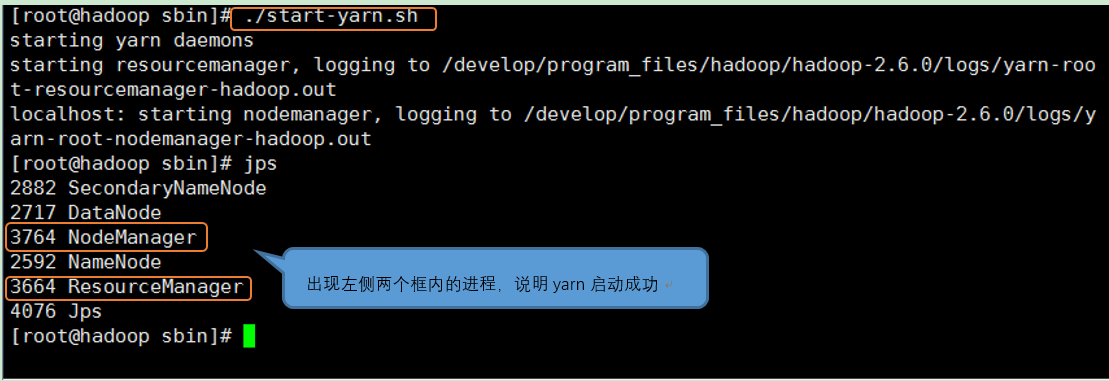
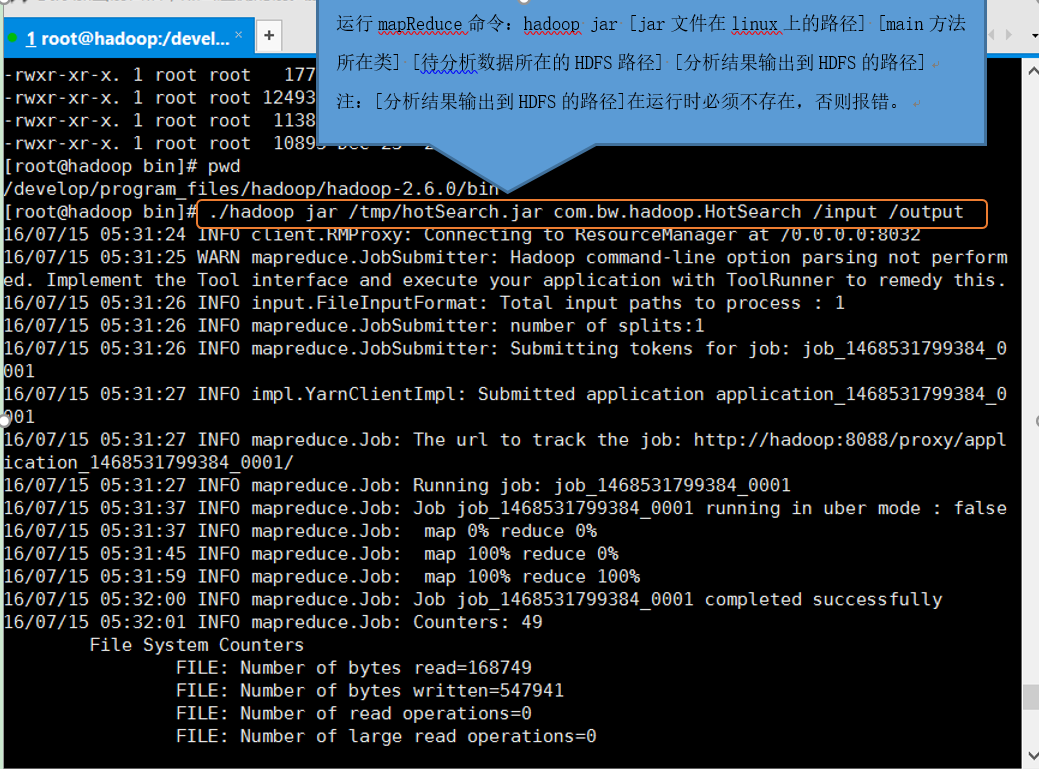
9、运行mapReduce
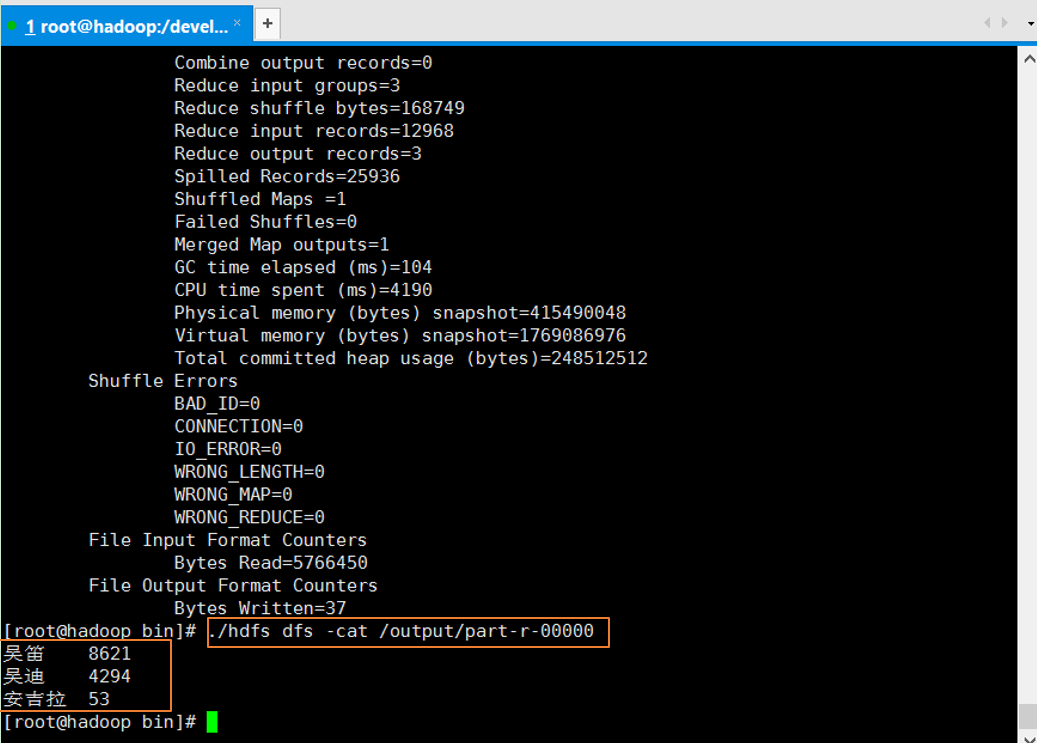
10、查看运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号